
3 月 10 日,Together发布了开源(Apache-2.0 许可)基础模型项目 OpenChatKit。OpenChatKit 的聊天模型支持推理、多轮讨论、知识和生成答案,该模型拥有 200 亿个参数并接受了 4300 万条指令的训练。这被认为是 ChatGPT 的开源平替。
资料显示,Together 正在创建第一个专门为处理大型基础模型而设计的分布式云。该公司提供了一个结合数据、模型和计算的直观平台,以帮助 AI 研究人员、开发人员和企业更好地利用和推进 AI。Together 团队认为,大型开放模型应该像开源一样易于使用。
OpenChatKit 提供强大的开源基础,能够为各类应用创建专用及通用型聊天机器人。Together 团队与 LAION 与 Ontocord 合作创建了训练数据集。
Together 团队认为开源基础模型将带来更好的包容性、透明性、稳健性和技术能力。Together 在 Apache 2.0 许可下发布了 OpenChatKit 0.15,源代码、模型权重和训练数据集可以全面访问。
优秀的聊天机器人必须能够执行自然语言指令、在对话中保持上下文,同时做出适度回应。OpenChatKit 提供一个基础机器人,并可根据此基础派生出专用的聊天机器人构建块。
据介绍,套件中共包含四大关键组件:
一套根据指令微调的大语言模型,利用 4300 万指令在 100%负碳排放算力上对 EleutherAI 的 GPT-NeoX-20B 模型做出微调;
自定义 recipes,可通过模型微调提高任务执行精度;
可扩展的检索系统,使您能够在推理时使用来自文档仓库、API 或其他实时更新信息源的信息来增加机器人响应;
由 GPT-JT-6B 微调而成的审核模型,用于过滤用户对机器人提出的问题。OpenChatKit 中的工具还允许用户提交反馈,以供社区成员添加新的数据集;社区可以为不断增长的开放训练数据集做出贡献,这些素材将随时间推移不断改进 LLM 的实际表现。
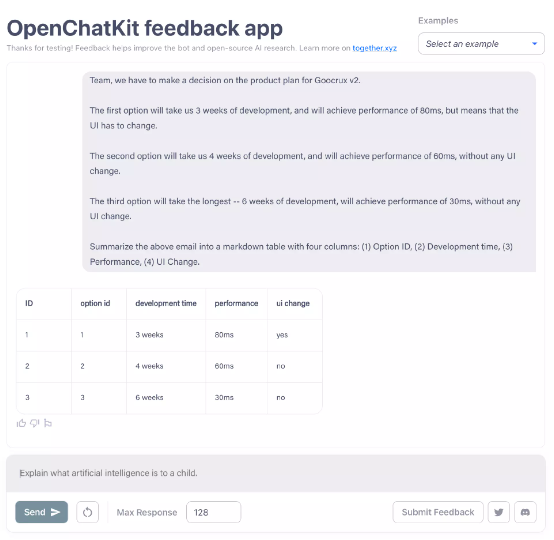
Hugging Face 上的 OpenChatKit 反馈应用,允许社区成员测试聊天机器人的表现并提交反馈。
指令微调的大语言模型
构成 OpenChatKit 基础的是 GPT-NeoXT-Chat-Base-20B 大语言模型,这套模型基于 EleutherAI 的 GPT-NeoX,并利用涉及对话交互的数据进行了微调。我们将调整重点放在了多轮对话、问答、分类、提取和摘要等几个核心任务上。我们已经使用 4300 万条高质量指令集对模型进行了微调,并与 LAION 和 Ontocord 合作创建了供模型训练使用的 OIG-43M 数据集。
GPT-NeoXT-Chat-Base-20B 能够开箱即用,为广泛的自然语言任务集提供了强大基础。总结来讲,它在 HELM 基准测试中的得分高于其基础模型 GPT-NeoX,在问答、提取和分类等任务上的表现尤其突出。
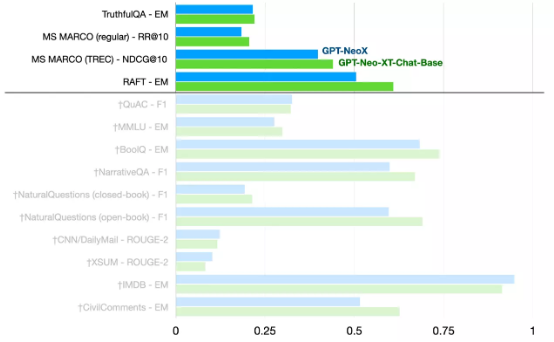
在 HELM 上评估 GPT-NeoXT-Chat-Base-20B 并与 GPT-NeoX 进行比较。†表示测试所使用的数据,在我们的微调语料库中也有收录。
模型优势
OpenChatKit 能够以开箱即用的方式出色处理多种任务,包括:
语境总结与答疑;
信息提取;
文本分类。
此外,该模型在 few-shot 少样本提示中表现良好。与大多数 HELM 任务一样,对于文本分类和信息提取工作,该模型能在提示较少的情况下表现良好。
模型劣势
Together 团队表示,目前团队还有一些尚未攻克的难关待克服,其中包括:
基于知识的封闭式问答:聊天机器人可能产生“幻觉”,给出不正确的结果。请务必进行事实核查,并在可能的情况下提花包含更正信息的反馈。
编码任务:聊天机器人没有经过足够大的源代码语料库训练,因此并不擅长编写代码。
重复:有时聊天机器人会重复自己给出的回应。
上下文切换:如果您在对话过程中改变话题,聊天机器人往往难以自动切换,而是会继续按照先前的话题给出答案。
创意性写作和长回答:聊天机器人无法生成较长的创意文案,例如文章或故事。
自定义 recipes 以微调模型
大语言模型在通用问答方面表现出了令人印象深刻的能力,而且在针对特定应用场景进行微调后,往往能够实现更高的准确率。例如,谷歌 PaLM 在医学回答方面的准确率已经在 50%左右,而通过添加指令支持和医疗信息微调之后,派生出的 Med-PaLM 一举拿下 92.6%的准确率。对于其他应用任务,也可以采用相同的微调方法。
OpenChatKit 提供多种工具,能够针对各类应用场景进行聊天机器人微调。目前 Together 团队正在与研究小组和企业合作,帮助他们根据自己的任务需求建立自定义模型:
教育助手——对开放教科书数据集进行微调,创建的聊天机器人有望帮助全年龄段学生通过自然对话学习各种主题。
金融问答——利用金融数据进行微调和检索(例如证券交易委员会文件),以实现金融领域的问答能力。
客服代表——利用知识库数据进行微调以创建聊天机器人,帮助最终用户诊断问题并快速给出答案。
如何微调
微调的具体步骤为:
准备相应的数据集,其中的交互示例应符合指定格式。
将您的数据集保存为 jsonl 文件,并按照此处(https://github.com/togethercomputer/OpenChatKit)说明进行聊天模型微调。
别忘了审核模式。在开始使用微调模型之前,请注意审核模型可能会过滤掉域外问题。如有必要,请再准备一些审核数据并对审核模型做微调。Together 在 GitHub 仓库(https://github.com/togethercomputer/OpenChatKit)中提供了整个操作过程的说明文档和源代码。OpenChatKit 是基于 Apache 2.0 许可的完全开源项目,因此用户可以深入调整、修改或审查您自己的应用方案或权重设置。
可提供实时更新答案的可扩展检索系统
OpenChatKit 还包含一个可扩展的检索系统。借助检索系统,聊天机器人能够合并定期更新或自定义内容,例如来自维基百科的知识、新闻提要或者体育赛事比分,将其纳入响应当中。

检索增强系统的工作流程示例。
通过检索系统,聊天机器人能够检索给定问题的相关信息,收集最新的资讯内容。这也为模型的答案提供了“上下文”。举例来说,检索系统能够支持维基百科索引,也可以在检索期间调用 Web 搜索 API 以获取示例代码。只要按照说明文档的指示操作,就能利用检索系统在推理过程中让聊天机器人接入任何数据集或 API,并将实时更新数据合并到响应当中。
如何在检索模式下使用聊天机器人
Together 直接提供一个将检索模型与聊天模型结合起来的一体化脚本,具体请参阅自述文件(https://github.com/togethercomputer/OpenChatKit#retrieval-augmented-models)中的完整信息。
在文档中的维基百科示例中,系统会针对特定用户查询执行以下步骤:
服务器根据用户查询,从维基百科索引中检索相关语句。
服务器将步骤 1 的输出添加到查询内,并使用聊天机器人模型生成响应结果。用户可以更改代码和提示以匹配自己的特定用例。
审核模型将在必要时适度干预
OpenChatKit 的最后一个组件,是由 GPT-JT 微调而成的 60 亿参数审核模型。在聊天应用中,审核模型将和主聊天模型协同运行,负责检查用户话语中是否存在不当内容。基于审核模型的评估,聊天机器人可以将输入内容限制为审核主题。对于指向性更强的任务,审核模型还可检测哪些问题属于域外问题,并在与主题无关时将其覆盖。
在推理过程中,Together 团队进行了小样本分类并将用户问题划分为五类。只有当问题属于允许的分类时,聊天机器人才会给出响应:
审核是一项难度颇高且相当主观的任务,而且很大程度上由上下文决定。Together 提供的审核模型只作为基准,可以根据各种需求进行调整和定制。Together 希望社区能够继续改进这套基础审核模型,并开发出适合不同文化和组织背景的特定数据集。
Together 与 LAION 和 Ontocord 合作,共同为审核模型提供训练数据集,并针对一系列不当问题对 GPT-JT 做了微调。
参考链接:




