
我们推出 Meta AI 的目的是让人们以新的方式提高工作效率,并通过生成式人工智能(GenAI) 释放创造力。但 GenAI 也面临着规模化方面的挑战。在 Meta 部署新的 GenAI 技术时,我们还在努力尽可能快速高效地向人们提供这些服务。
Meta AI 的动画制作功能让人们可以用一幅 AI 生成的图像来生成一段简短的动画,这一功能就在规模化方面带来了独特的挑战。为了大规模部署和运行,我们用来从图片生成动画的模型必须既能为使用我们产品和服务的数十亿用户提供服务,同时还要快速完成任务——生成时间短、错误最少,同时保持高效的资源利用率。
本文介绍了我们如何使用延迟优化、流量管理和其他新技术结合在一起来部署 Meta AI 的动画功能。
优化图像生成动画任务的延迟
在我们的应用阵容和 Meta AI 网站上推出动画功能之前,快速制作动画模型是我们的首要任务之一。我们希望人们能够神奇地看到他们的制作请求在几秒内就变成一段动画。这不仅对用户来说是很重要,而且我们模型的速度越快,越高效,我们就能用更少的 GPU 做更多的事情,帮助我们以可持续的方式扩大规模。我们之前的相关工作包括了使用视频 Diffusion 技术制作动画表情、使用 Imagine Flash 加速图像生成,以及通过块缓存加速 Diffusion 模型等,这些工作都为我们开发用于大幅缩减延迟的新技术提供了帮助。
减半浮点精度
第一项优化技术是将浮点精度减半。我们将模型从 float32 转换为 float16,从而加快了推理速度,原因有二。首先,模型的内存占用减少了一半。其次,16 位浮点运算的执行速度比 32 位浮点运算更快。为了让所有模型都获得这些好处,我们使用了 bfloat16,这是一种具有较小尾数的 float16 变体,用于训练和推理工作。
改进时间注意力扩展
第二个优化改进了时间注意力扩展(temporal-attention expansion)。时间注意层位于时间轴和文本条件之间,需要复制上下文张量以匹配时间维度或帧数。以前,这些工作会在传递到交叉注意层之前完成,然而这会导致性能提升不够理想。我们采用的优化实现利用了重复张量都是一样的事实减少了计算和内存需求,这样就能在通过交叉注意的线性投影层后进行扩展。
利用 DPM-Solver 减少采样步骤
第三个优化利用了 DPM-Solver。扩散概率模型(DPM)是强大且有影响力的模型,可以产生极高质量的生成结果,但速度可能很慢。其他可能的解决方案,例如去噪扩散隐式模型或去噪扩散概率模型可以提供高质量的生成,但需要更多采样步骤,带来更大计算成本。我们利用 DPM-Solver 和一个线性对数信噪比时间将采样步骤数减少到了 15。
结合使用指导蒸馏与逐步蒸馏
我们的第四个优化结合了指导蒸馏和逐步蒸馏。我们用相同的权重初始化教师和学生来完成逐步蒸馏,然后训练学生在单个步骤中匹配多个教师步骤。相比之下,指导蒸馏是指扩散模型利用无分类器指导进行条件图像生成。这需要每个求解器步骤都有一个有条件和一个无条件的前向传递。
但在我们的例子中,每个步骤有三次前向传递:无条件、图像条件和一个全条件文本和图像步骤。指导蒸馏将这三次前向传递减少为一次,将推理需求减少了 2/3。然而,这里真正的魔力在于结合这两种优化方法。通过训练学生同时模仿无分类器指导和多个步骤,并通过 U-Net 进行一次前向传递,我们的最终模型只需要八个求解器步骤,每个步骤只需通过 U-Net 做一次前向传递。最后,在训练期间,我们将 32 个教师步骤蒸馏为八个学生步骤。
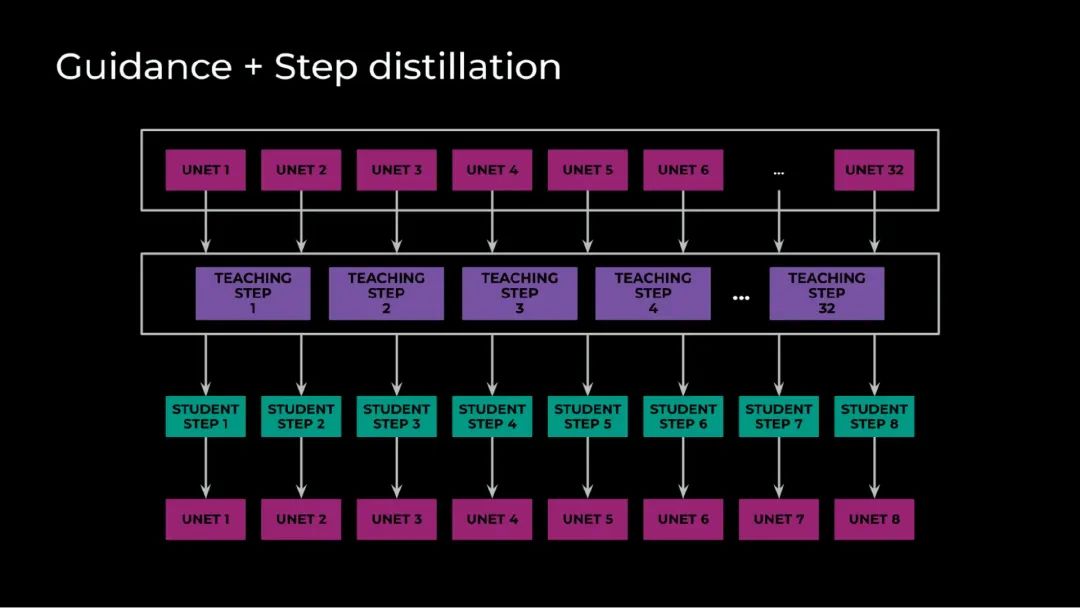
通过结合指导蒸馏和逐步蒸馏,我们能够蒸馏 32 个步骤,每个步骤针对每种条件类型通过 U-Net 多次传递,最终通过 U-Net 架构仅需八个步骤。
PyTorch 优化
最后这块优化工作与部署和架构有关,涉及两个转换。第一个转换利用了 Torch 脚本和冻结。通过将模型转换为 TorchScript,我们实现了许多自动优化,包括连续折叠、融合多个操作以及降低计算图的复杂性。这三个优化有助于提高推理速度,而冻结操作通过将图中动态计算的值转换为常量来实现进一步优化,从而减少总操作数。
这些优化对我们发布的初始版本来说非常重要,并且我们仍在继续寻求突破。例如,我们已经将所有媒体推理任务从 TorchScript 迁移到了基于 PyTorch 2.0 的解决方案上,这为我们带来了多重收益。我们能够使用 pytorch.compile 在组件级别更精细地优化模型组件,并在新架构中启用高级优化技术,例如上下文并行和序列并行。这还带来了额外的好处,例如缩短高级功能的开发时间、改进跟踪,以及支持多 GPU 推理。
大规模部署和运行图像生成动画功能
在完全优化模型后,我们面临一系列新的挑战。我们如何大规模运行这一模型以支持来自世界各地的流量,同时保持较快的生成速度,尽量减少故障,并确保 GPU 资源可用于公司其他所有重要用例?
我们首先查看了之前 AI 生成的媒体在发布时和一段时间内的流量数据。我们使用这些信息粗略估计了可以预期的请求数量,然后使用模型速度基准测试来确定需要多少 GPU 来容纳这么多需求。在扩大规模后,我们开始运行负载测试,看看在不同的流量水平上我们能否应付,解决各种瓶颈,直到我们能够处理预计发布时会遇到的流量需求为止。
在这次测试中,我们注意到动画请求的端到端延迟高于预期,也高于我们在实施上述所有优化后所看到的延迟。我们的调查表明,流量被路由到了全球,导致了巨大的网络和通信开销,并使端到端生成时间增加了几秒。为了解决这个问题,我们使用了一个流量管理系统,该系统获取服务的流量或负载数据,并利用这些数据来计算路由表。路由表的主要目标是将尽可能多的请求保留在与请求者相同的区域中,以避免像我们之前看到的那样出现跨区域流量。路由表还利用我们预定义的负载阈值和路由环,在接近区域的最大容量时将流量卸载到其他区域来防止过载。通过这些更改,大多数请求仍保留在区域内,延迟下降到了大致符合我们预期的水平。
要让这项服务正常运行需要很多活动组件。首先,它需要获取我们为层级定义的每一个指标,从该层的机器中获取每个指标的值,并按区域进行汇总。然后,它收集每个区域每秒发送到其他每个区域的请求数,并使用这个数来计算每秒请求的负载成本。这会告诉系统,一般来说,每秒每增加一个请求,负载就会增加 X。完成后,算法开始生效,首先将所有流量带到源区域。我们还没有检查该区域是否有足够的容量。
下一步是进入一个循环,在每次迭代中,我们都会查看哪个区域的运行情况最接近最大容量。服务会尝试获取该区域的一部分请求,并将其卸载到附近的区域,后者得能处理这些请求而不会变得更加过载。
不同的过载程度决定了我们在查看附近区域时考虑的距离。例如,如果主区域刚刚开始过热,则可能只会使用最近的区域。如果该区域几乎以最大容量运行,则可能会解锁较远的区域以进行卸载。如果没有更多可以在区域之间移动的请求,我们将退出循环,这种情况发生在每个区域都低于定义的“过载”阈值时,或者由于所有附近区域也都高于阈值,因此没有更多服务可以卸载到的附近区域。此时,服务将计算每个区域每秒的最佳请求数,并使用它来创建上面提到的路由表,以便我们的服务可以合理判断在请求时将流量发送到何处。
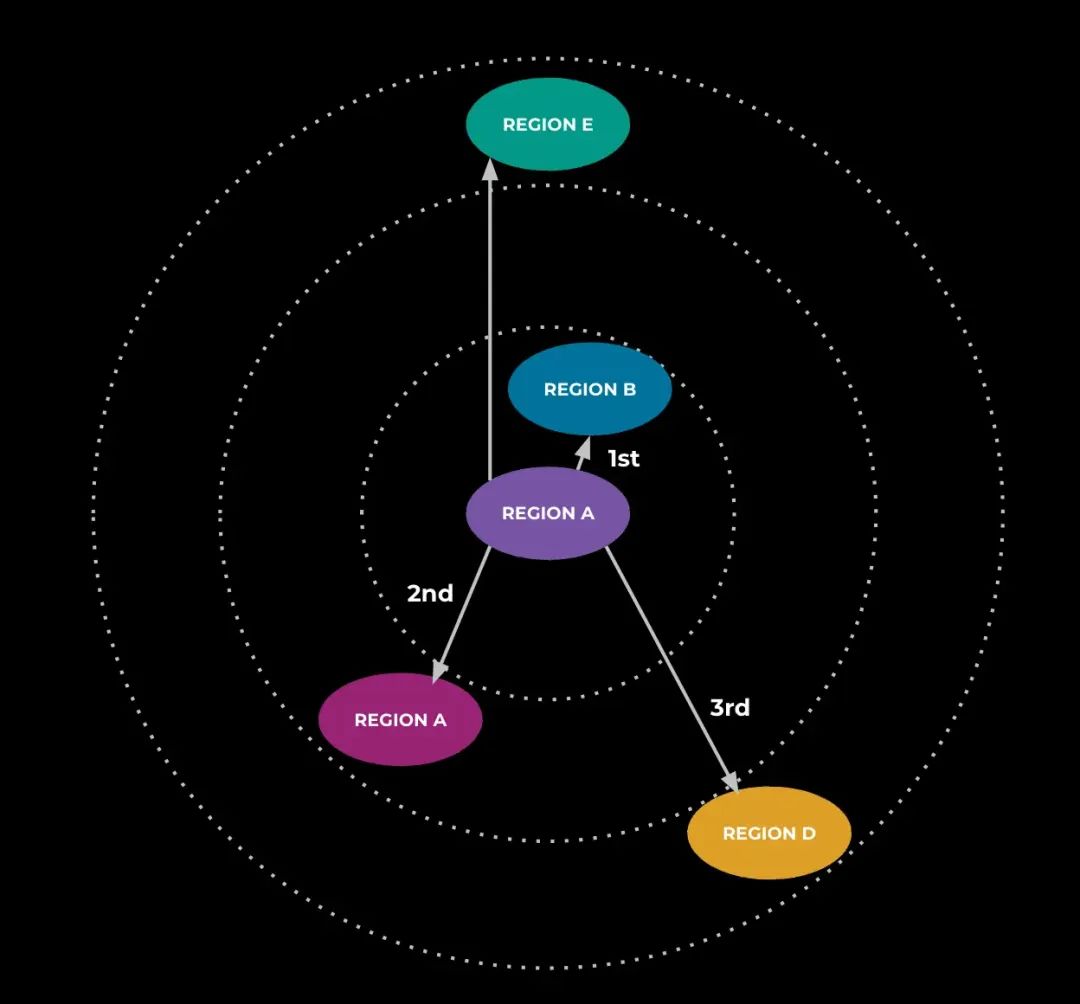
为了确保动画请求尽快交付,我们的一部分工作是实现了一个流量管理系统,以尽可能将请求与请求者保持在同一个区域。
实施这些优化后,延迟恢复到了我们满意的水平,但成功率有所下降。从高层次来看,每个 GPU 一次只能处理一个请求,因为每个请求都会让 GPU 完全饱和运行。为了保持较低的延迟,我们必须不允许请求排队——否则,它们将有很长的等待时间。为了实现这一点,我们确保了服务器负载(排队请求加上正在进行的请求)最多为一个,并且服务器会拒绝其他新请求。然而,正因为如此,当我们的运行接近容量极限时将遇到许多故障。这个问题的简单解决方案是使用队列,但由于必须在全球范围内进行负载平衡,这本身就带来了一系列复杂的挑战,不利于提高效率和速度。我们采用的方法差不多是利用重试轮询来创建一个探测系统,该系统可以非常快速地检查空闲的 GPU 并防止故障。
在我们实现流量管理系统之前,这种方法效果很好。该系统虽然可以有效地减少延迟,但由于现在我们不再用全局路由了,而它又让每个请求可用的主机数量变少,于是引入了更多复杂性。我们注意到,重试轮询不起作用了,并且如果出现任何峰值,它实际上往往会出现级联。进一步的调查让我们发现,我们的路由器需要有更优化的重试设置。它既没有延迟也没有退避。因此,如果我们有一个区域,其中有很多任务正在尝试运行,那么它就会陷入超载状态,直到它开始让请求失败。为了避免级联错误,我们修改了这些重试设置,在调度时为一定比例的作业添加边际执行延迟——使它们可以逐渐执行而不是一次性执行——以及指数退避。
完成所有这些操作后,我们就有了一个高效、大规模运行的部署模型,能够以高可用性、最低故障率处理全球流量。
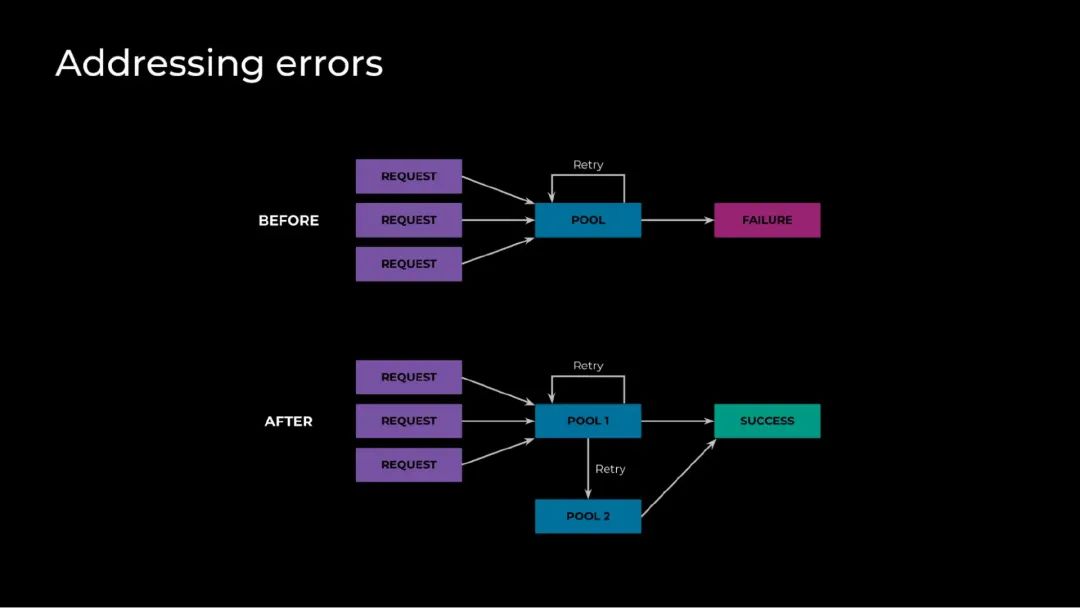
通过增加边际执行延迟、优化重试和指数退避,我们减少了系统中的错误数量。
原文链接:




