数据竞争与顺序一致性保证
当程序未正确同步时,就会存在数据竞争。java 内存模型规范对数据竞争的定义如下:
- 在一个线程中写一个变量,
- 在另一个线程读同一个变量,
- 而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果(前一章的示例正是如此)。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。
JMM 对正确同步的多线程程序的内存一致性做了如下保证:
- 如果程序是正确同步的,程序的执行将具有顺序一致性(sequentially consistent)–即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同(马上我们将会看到,这对于程序员来说是一个极强的保证)。这里的同步是指广义上的同步,包括对常用同步原语(lock,volatile 和 final)的正确使用。
顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
顺序一致性内存模型为程序员提供的视图如下:
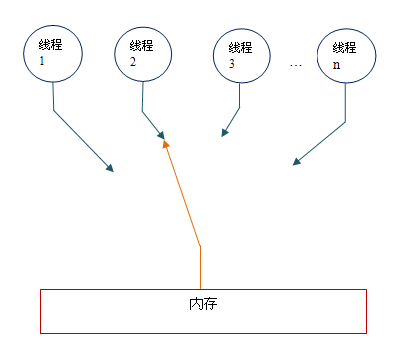
在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程。同时,每一个线程必须按程序的顺序来执行内存读 / 写操作。从上图我们可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读 / 写操作串行化。
为了更好的理解,下面我们通过两个示意图来对顺序一致性模型的特性做进一步的说明。
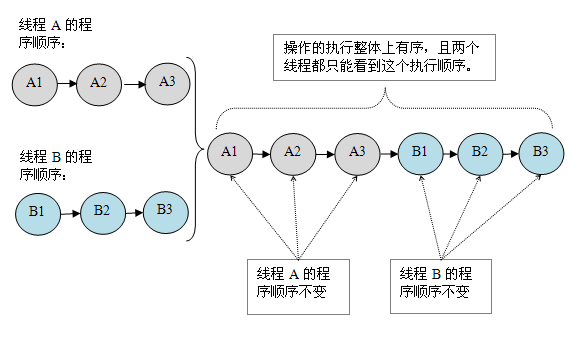
假设有两个线程 A 和 B 并发执行。其中 A 线程有三个操作,它们在程序中的顺序是:A1->A2->A3。B 线程也有三个操作,它们在程序中的顺序是:B1->B2->B3。
假设这两个线程使用监视器来正确同步:A 线程的三个操作执行后释放监视器,随后 B 线程获取同一个监视器。那么程序在顺序一致性模型中的执行效果将如下图所示:
现在我们再假设这两个线程没有做同步,下面是这个未同步程序在顺序一致性模型中的执行示意图:
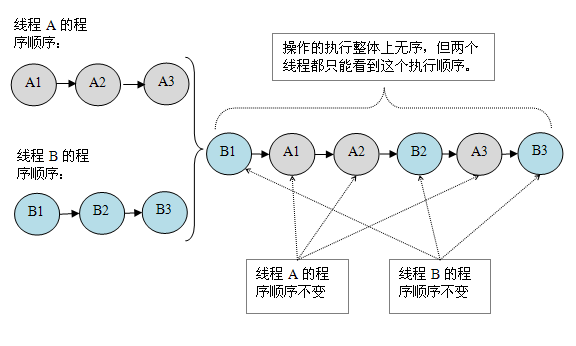
未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。以上图为例,线程 A 和 B 看到的执行顺序都是:B1->A1->A2->B2->A3->B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操作必须立即对任意线程可见。
但是,在 JMM 中就没有这个保证。未同步程序在 JMM 中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,且还没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本还没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其它线程看到的操作执行顺序将不一致。
同步程序的顺序一致性效果
下面我们对前面的示例程序 ReorderExample 用监视器来同步,看看正确同步的程序如何具有顺序一致性。
请看下面的示例代码:
class SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a;
……
}
}
}
上面示例代码中,假设 A 线程执行 writer() 方法后,B 线程执行 reader() 方法。这是一个正确同步的多线程程序。根据 JMM 规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。下面是该程序在两个内存模型中的执行时序对比图:
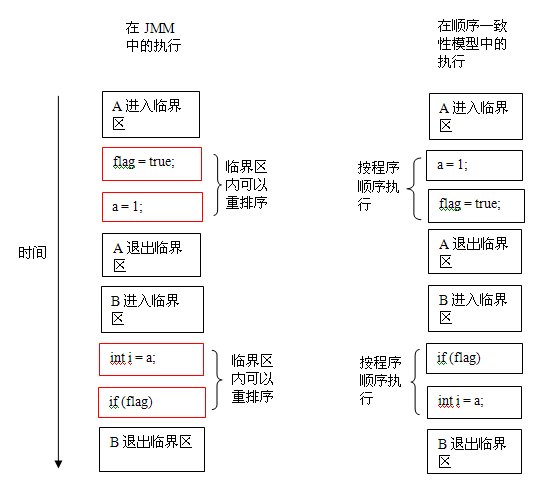
在顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在 JMM 中,临界区内的代码可以重排序(但 JMM 不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM 会在退出监视器和进入监视器这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图(具体细节后文会说明)。虽然线程 A 在临界区内做了重排序,但由于监视器的互斥执行的特性,这里的线程 B 根本无法“观察”到线程 A 在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
从这里我们可以看到 JMM 在具体实现上的基本方针:在不改变(正确同步的)程序执行结果的前提下,尽可能的为编译器和处理器的优化打开方便之门。
未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM 只提供最小安全性:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false),JMM 保证线程读操作读取到的值不会无中生有(out of thin air)的冒出来。为了实现最小安全性,JVM 在堆上分配对象时,首先会清零内存空间,然后才会在上面分配对象(JVM 内部会同步这两个操作)。因此,在以清零的内存空间(pre-zeroed memory)分配对象时,域的默认初始化已经完成了。
JMM 不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为未同步程序在顺序一致性模型中执行时,整体上是无序的,其执行结果无法预知。保证未同步程序在两个模型中的执行结果一致毫无意义。
和顺序一致性模型一样,未同步程序在 JMM 中的执行时,整体上也是无序的,其执行结果也无法预知。同时,未同步程序在这两个模型中的执行特性有下面几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而 JMM 不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。这一点前面已经讲过了,这里就不再赘述。
- 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而 JMM 不保证所有线程能看到一致的操作执行顺序。这一点前面也已经讲过,这里就不再赘述。
- JMM 不保证对 64 位的 long 型和 double 型变量的读 / 写操作具有原子性,而顺序一致性模型保证对所有的内存读 / 写操作都具有原子性。
第 3 个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(bus transaction)。总线事务包括读事务(read transaction)和写事务(write transaction)。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读 / 写内存中一个或多个物理上连续的字。这里的关键是,总线会同步试图并发使用总线的事务。在一个处理器执行总线事务期间,总线会禁止其它所有的处理器和 I/O 设备执行内存的读 / 写。下面让我们通过一个示意图来说明总线的工作机制:
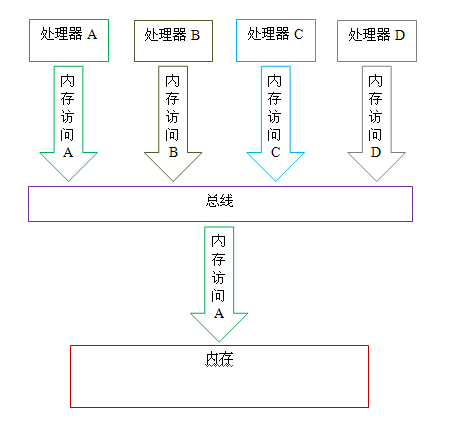
如上图所示,假设处理器 A,B 和 C 同时向总线发起总线事务,这时总线仲裁(bus arbitration)会对竞争作出裁决,这里我们假设总线在仲裁后判定处理器 A 在竞争中获胜(总线仲裁会确保所有处理器都能公平的访问内存)。此时处理器 A 继续它的总线事务,而其它两个处理器则要等待处理器 A 的总线事务完成后才能开始再次执行内存访问。假设在处理器 A 执行总线事务期间(不管这个总线事务是读事务还是写事务),处理器 D 向总线发起了总线事务,此时处理器 D 的这个请求会被总线禁止。
总线的这些工作机制可以把所有处理器对内存的访问以串行化的方式来执行;在任意时间点,最多只能有一个处理器能访问内存。这个特性确保了单个总线事务之中的内存读 / 写操作具有原子性。
在一些 32 位的处理器上,如果要求对 64 位数据的读 / 写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java 语言规范鼓励但不强求 JVM 对 64 位的 long 型变量和 double 型变量的读 / 写具有原子性。当 JVM 在这种处理器上运行时,会把一个 64 位 long/ double 型变量的读 / 写操作拆分为两个 32 位的读 / 写操作来执行。这两个 32 位的读 / 写操作可能会被分配到不同的总线事务中执行,此时对这个 64 位变量的读 / 写将不具有原子性。
当单个内存操作不具有原子性,将可能会产生意想不到后果。请看下面示意图:
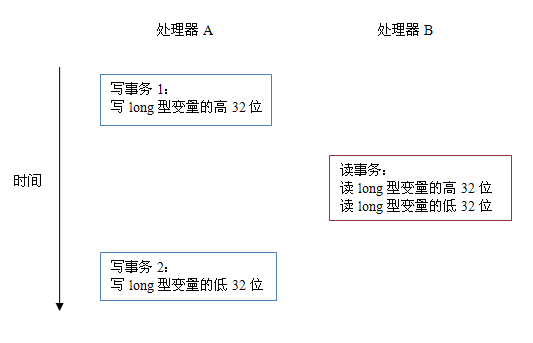
如上图所示,假设处理器 A 写一个 long 型变量,同时处理器 B 要读这个 long 型变量。处理器 A 中 64 位的写操作被拆分为两个 32 位的写操作,且这两个 32 位的写操作被分配到不同的写事务中执行。同时处理器 B 中 64 位的读操作被拆分为两个 32 位的读操作,且这两个 32 位的读操作被分配到同一个的读事务中执行。当处理器 A 和 B 按上图的时序来执行时,处理器 B 将看到仅仅被处理器 A“写了一半“的无效值。
参考文献
- JSR-133: Java Memory Model and Thread Specification
- Shared memory consistency models: A tutorial
- The JSR-133 Cookbook for Compiler Writers
- 深入理解计算机系统(原书第 2 版)
- UNIX Systems for Modern Architectures: Symmetric Multiprocessing and Caching for Kernel Programmers
- The Java Language Specification, Third Edition
作者简介
程晓明,Java 软件工程师,国家认证的系统分析师、信息项目管理师。专注于并发编程,就职于富士通南大。个人邮箱: asst2003@163.com 。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




