
在现代数据库系统中,执行引擎在数据库体系结构中起着承上启下的作用,与查询优化器和存储引擎共同组成了数据库的三大模块。我们以 SQL 语句在数据库系统中的完整执行过程为例,来介绍执行引擎在其中发挥的作用:
在接收到一条 SQL 查询语句之后,查询优化器会对 SQL 进行语法/词法分析,基于代价模型和规则生成最优执行计划;
执行引擎会将生成的执行计划调度到计算节点,按照最优执行计划对底层存储引擎中的数据进行操作并返回查询结果;
在整个查询过程中,查询执行是至关重要的环节,往往需要通过数据读取、过滤、排序、聚合等操作,才能提交给执行引擎进行下一步查询,这几个步骤的设计是否合理直接影响到查询的性能及资源的利用率。而这些能力均由执行模型来提供,而不同的执行模型在数据处理、查询优化和并发控制等方面存在较大差异,因此,一个合适的执行模型对于提高查询效率和系统性能至关重要。
目前业界常见的执行模型有迭代模型/火山模型(Iterator Model)、物化模型(Materialization Model)、向量化/批处理模型(Vectorized / Batch Model)。其中火山模型(Volcano Model)是数据库查询优化和执行中最为常用的执行模型。每一种操作抽象为一个 Operator,整个 SQL 查询被构建成一个 Operator 树。查询执行时,树自顶向下调用 next() 接口,数据则自底向上被拉取处理,因此这种处理方式也被称为拉取执行模型(Pull Based)。火山模型因其具有很高灵活性高、可扩展性好、易于实现和优化等特性,被广泛应用于数据库查询优化和执行中。
作为典型的 MPP 数据库,过去版本中 Apache Doris 亦采取的也是火山模型。当用户发起 SQL 查询时,Apache Doris 会将查询解析成分布式执行计划并分发到执行节点执行,分发到节点的单个执行任务被称为 Instance,在此我们一条简单的 SQL 查询来了解 Instance 在火山模型下的执行过程:
select age, sex from employees where age > 30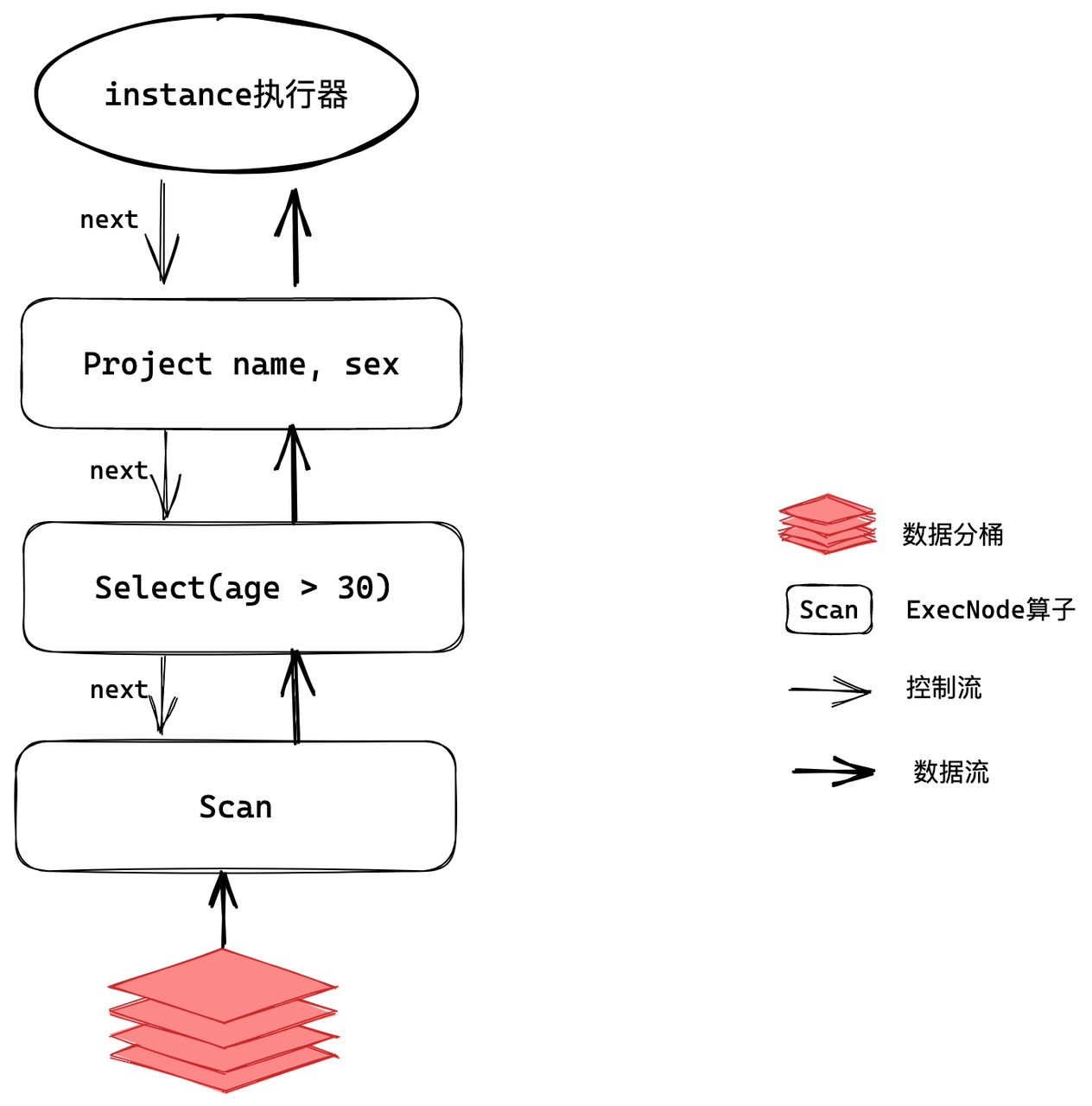
如上图可知,Instance 是一个算子(ExecNode)树,算子之间通过数据重分布(Exchange)算子连接起来,从而实现数据流的传递和处理,每个算子实现 next() 方法。当对算子的 next() 方法进行调用时,该算子将调用其孩子算子的 next() 方法来获取输入的数据,然后对数据进行逻辑加工并输出。而因为算子的 next() 方法是同步方法,在没有数据产生时, next() 方法将会持续阻塞。这时候需要循环调用根节点算子的 next() 方法,直到全部数据处理完毕,即可得到整个 Instance 的计算结果。
从上述执行过程可以看出,火山模型是一种简单易用、灵活性高的执行模型,但在单机多核的场景下,存在一些问题需要进一步解决和优化,具体体现在以下几方面:
线程阻塞执行:在线程池大小固定的情况下,当一个 Instance 占用一个线程阻塞执行时,如果存在大量的 Instance 同时请求,执行线程池将被占满,从而导致查询引擎出现假死状态,无法响应后续请求。特别是在存在 Instance 之间相互依赖的情况下,还可能会出现逻辑死锁的情况,比如当前线程中正在执行的 Instance 依赖于其他的 Instance,而这些 Instance 正处于等待队列中,无法得到执行,从而加剧系统的负载和压力。当一个执行节点同时运行的 Instance 线程数远大于 CPU 核数时,Instance 间的调度将依赖于系统调度机制,这就可能产生 Context 切换开销,尤其是在系统混部的场景中,线程切换的开销会更加显著。
CPU 资源抢占:Instance 线程之间出现争抢 CPU 资源的问题,可能导致不同大小的查询、不同租户之间互相影响。
无法充分利用多核计算能力:执行计划的并行度取决于数据分布,当一台执行节点上存在 N 个数据分桶时,该节点上运行的 Instance 数量不能超过 N,因此分桶的设置显得尤为重要。如果分桶设置过少,难以充分利用多核计算能力,反之,则会带来碎片化问题。多数场景下进行性能调优时需要手动设置并行度,而在生产环境中,预估数据分桶数是一项极具挑战性的任务,不合理的分桶使得 Doris 的性能优势无法得到充分发挥,无法充分利用多核计算能力。
Pipeline 执行模型的引入
为了解决过去版本所存在的问题,Apache Doris 自 2.0 版本起引入了 Pipeline 执行模型以替换过去的火山模型,并在 2.1 版本对 Pipeline 执行模型进行了进一步的升级。
设计文档:
以 Join 场景为例,下图展示了 Pipeline 执行模型下两个 Instance 组成查询计划的效果。
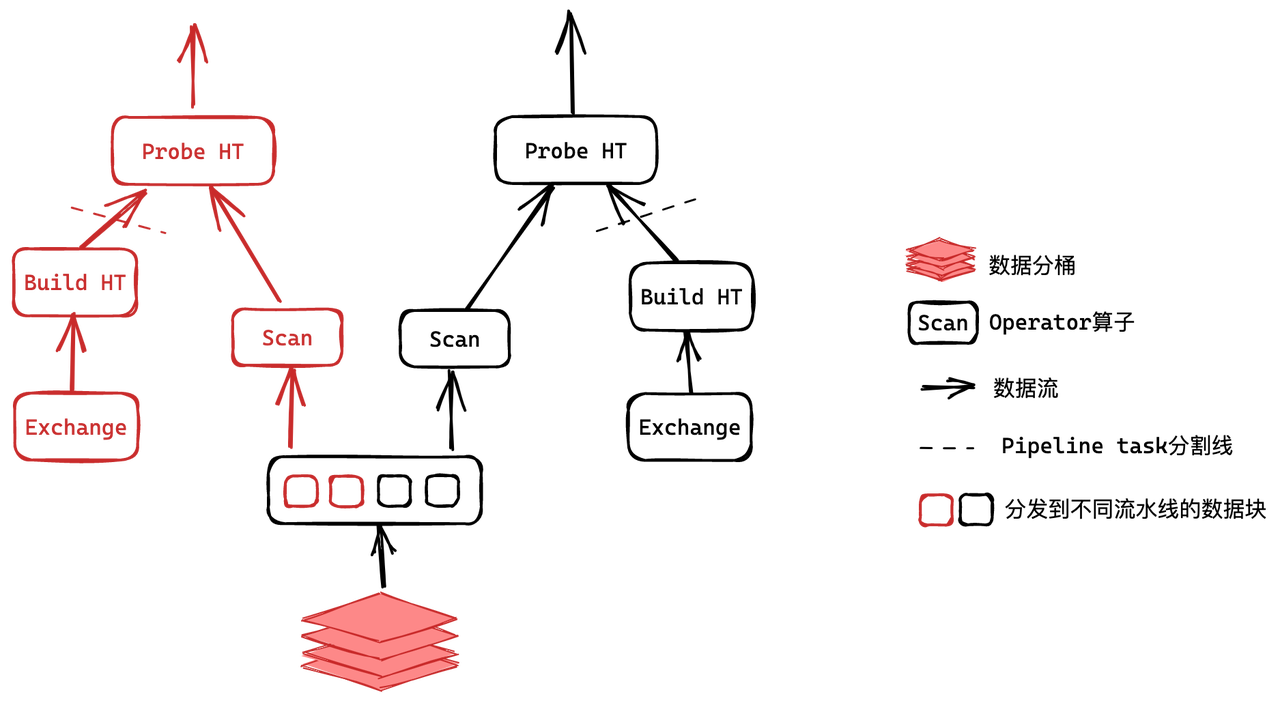
在这个计划中,Join 的 Probe 操作依赖于哈希表的构建操作(Build),因此 Build 操作必须在 Exchange 获取的数据全部处理完成并构建完哈希表之后才能启动,这种依赖关系导致每个 Instance 被拆分成两个 Pipeline Task。Pipeline 调度器将 Pipeline Task 放置于工作线程池的 Ready 队列,工作线程根据不同的策略获取 Pipeline Task,Pipeline Task 计算完成一个数据块后是否让出线程取决于其前置数据是否 Ready 以及运行时间是否超过上限。
Pipeline 执行模型的设计实现
Pipeline 执行模型通过阻塞逻辑将执行计划拆解成 Pipeline Task,将 Pipeline Task 分时调度到线程池中,实现了阻塞操作的异步化,解决了 Instance 长期占用单一线程的问题。同时,我们可以采用不同的调度策略,实现 CPU 资源在大小查询间、不同租户间的分配,从而更加灵活地管理系统资源。Pipeline 执行模型还采用了数据池化技术,将单个数据分桶中的数据进行池化,从而解除分桶数对 Instance 数量的限制,提高 Apache Doris 对多核系统的利用能力,同时避免了线程频繁创建和销毁的问题,提高了系统的并发性能和稳定性。
去阻塞化改造
从上文介绍可知,在之前版本的火山模型下,执行引擎存在阻塞操作,这会带来两个核心问题:一是阻塞线程过多会导致线程池打满,无法响应后续查询;二是执行线程调度完全依赖操作系统,无法根据查询优先级进行调度,性能有待提升。为了解决这两个问题,我们重新设计了去阻塞化的执行逻辑。
针对第一个问题,我们固定一个大小与 CPU 核数相同的执行线程池,并保证执行线程中不会存在阻塞操作。为了避免线程阻塞导致操作系统级别的线程调度,我们在所有发生阻塞的算子中拆分了 Pipeline Task,比如使用独立线程进行磁盘 I/O 和 RPC 等操作。
针对第二个问题,我们设计了一个纯用户态的轮询调度器,通过不停轮询所有可执行 Pipeline Task 的状态,将当前需要执行的 Task 交给执行线程执行。这种做法避免了操作系统频繁线程切换的开销,同时也可以加入更多优先级等定制化的调度策略,提高系统灵活性和可扩展性。

并行化改造
在 2.0 之前版本中,Apache Doris 执行引擎的并发度需要由用户手动设置(即会话变量 parallel_fragment_exec_instance_num ),无法根据不同的 Workload 进行动态调整。而为了设置一个合理的并发度,往往需要进行细致的分析,这无疑是增加了用户的负担。同时,使用不合理的并发度可能会导致性能问题。因此,如何充分利用机器资源来实现每个查询任务的自动并发,成为亟需解决的问题。
当前常见的 Pipeline 并发方案分别以 Presto、DuckDB 为代表,Presto 并发方案是在执行过程中将数据 Shuffle 成合理的分区数量,这样做的好处是基本不需要特别的并发控制。DuckDB 并发方案执行过程中不会引入额外的 Shuffle 操作,但是需要引入额外的同步机制。我们对以上方案进行了综合对比,我们认为 DuckDB 并发方案在实现上很难规避使用锁,而锁的存在有悖于我们去阻塞化改造的思路,因此我们选择了以 Presto 为代表的实现方案。
为了实现 Pipeline 并发,Presto 引入了 Local Exchange 对数据进行了重分区,例如对于 Hash Aggregation,Presto 根据聚合 Key 进一步将数据分为 N 份,这样就可以充分利用机器的 N Cores,每个执行线程只需要构建更小的 Hash Table。而对于 Apache Doris,我们选择充分利用 MPP 自身的架构,在 Shuffle 时就直接将数据分区成合理的分区数,因此不再需要额外引入 Local Exchange。
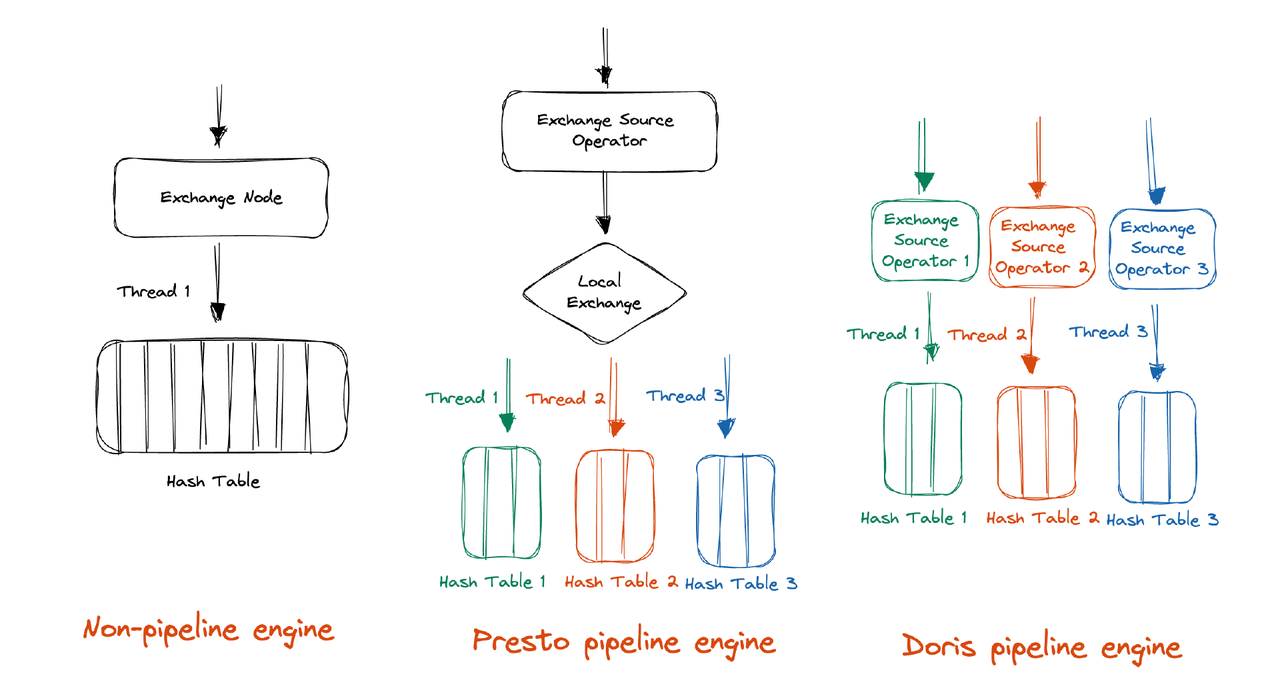
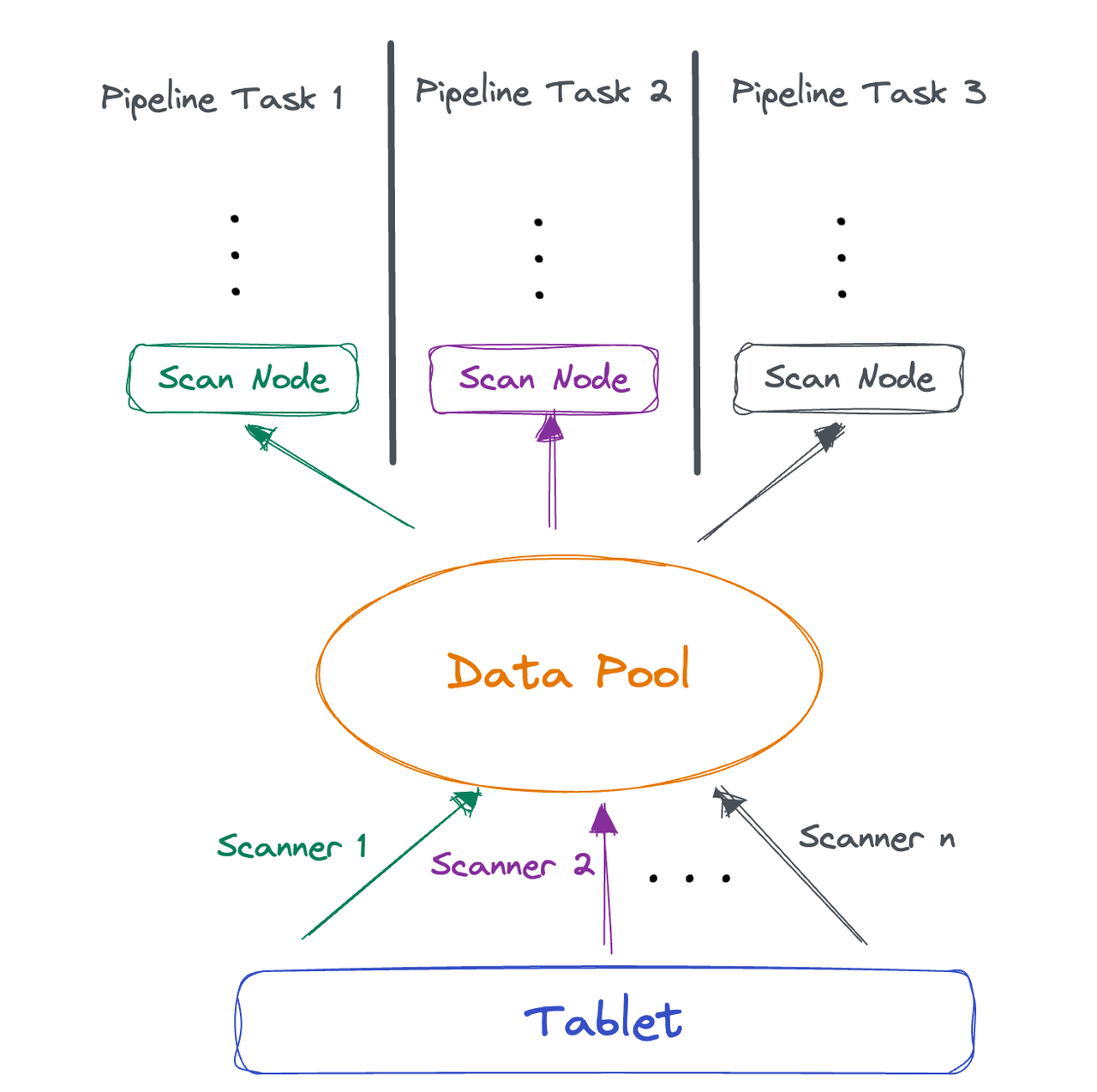
基于这个特性,我们需要对两个方面进行改造:一是在 Shuffle 时增加并发,二是在 Scan 层读取数据后实现并发执行能力。对于前者,我们只需要在 FE 感知 BE 环境,然后设置合理的分区数即可。而对于后者,目前 Doris 在 Scan 层的执行线程与存储 Tablet 数量是强绑定的,因此需要重构 Scan 层并发逻辑,以满足我们的需求。
Scan 池化的基本思路是将 Scanner 线程读取的数据进行池化,多个 Pipeline Task 可以直接从池中取数据执行。这样的方式可以充分解耦 Scanner 和执行线程,提高系统的并发性能和稳定性。
Pipeline 执行模型的进一步完善
Pipeline 执行模型的引入为 Apache Doris 在混合负载场景中的查询性能和稳定性都得到了明显提升,但在 Apache Doris 2.0 版本中仍为实验性功能,在社区用户使用的过程中,一些新的问题开始浮现:
执行并发受限: 由于当前版本 Doris 执行并发仍收到 FE 设置的静态并发参数和存储层 Tablet 数量限制,使得执行引擎无法充分利用机器的多核资源,同时存储层可能会存在数据倾斜问题,导致查询执行出现长尾。
执行开销较大: 表达式各 Instance 相互独立,而 Instance 的初始化参数存在大量公共部分,这导致每次执行都需要额外进行重复的初始化步骤,显著增加了执行开销。
调度开销较大: 在查询执行过程中,当前调度器会把阻塞 Task 全部放入一个阻塞队列中,由一个线程负责轮询并从阻塞队列中取出可执行 Task 放入 Runnable 队列,所以在有查询执行的过程中,会固定有一个核的资源作为调度的开销。尤其是在一些小机型上,固定调度线程带来的开销非常明显。
Profile 可读性差: Pipeline Profile 指标缺乏直观性和可读性,使得性能分析变得比较困难。
为了提供更高的查询性能和更稳定的查询体验,Apache Doris 在最新发布的 2.1 版本中,对 Pipeline 执行模型进行大幅优化,将其改造为基于事件驱动的执行模型,并对已存在问题提供了改进方案。为便于理解,后文将改进后的 Pipeline 执行模型称为 PipelineX。
执行并发改造
前文提及,Pipeline 执行并发受两个因素制约:FE 设置的静态并发参数和存储层 Tablet 数量限制,这就导致执行引擎无法充分利用机器资源。另外如果数据本身存在倾斜,还可能导致查询执行时出现长尾问题。为此,我们以一个简单的聚合查询为例展开详细介绍。
假定有 Table A,Table A 中 tablet 总数为 1 ,共有数据 100M 行,执行聚合查询:
SELECT COUNT(*) FROM A GROUP BY A.COL_1;一般而言,在查询 SQL 的完整执行过程中,查询会被切分成为多个查询分片(Fragment),每个查询分片表示查询执行过程中的逻辑概念,可能包含多个 SQL 算子。当 BE 收到 FE 下发的 Fragment 后,启动多个执行线程并行执行 Fragment,确保每个 Fragment 均能得到高效处理。如下图,Doris 将其切分成了 2 个 Fragment 分别执行:

为便于理解,仅介绍逻辑计划的第一部分(Fragment 0)。由于 Table A 只有一个 Tablet,因此 Fragment 0 的执行并发始终被限制为 1,即由单线程完成 100M 行数据的聚合。而在理想状态下,16 核可承载并发数为 8,假定执行时间为 x,每个执行线程可读取 100M/8 行数据,那么执行时间约为 x/8。然而在该例子中,大约会带来 8 倍的性能损失。
为解决这一问题,Apache Doris 2.1 版本在执行引擎中引入了 Local Shuffle 节点,摆脱了存储层 Tablet 数量对执行并发的限制。 具体实现上:
执行线程执行各自的 Pipeline Task,而 Pipeline Task 仅持有一些运行时状态(即 Local State)。全局信息则由多个 Task 共享的同一个 Pipeline 对象持有(即 Global State)。
在单个 BE 上,数据分发由 Local Shuffle 节点完成,并由 Local Shuffle 保证多个 Pipeline Task 间的数据均衡。
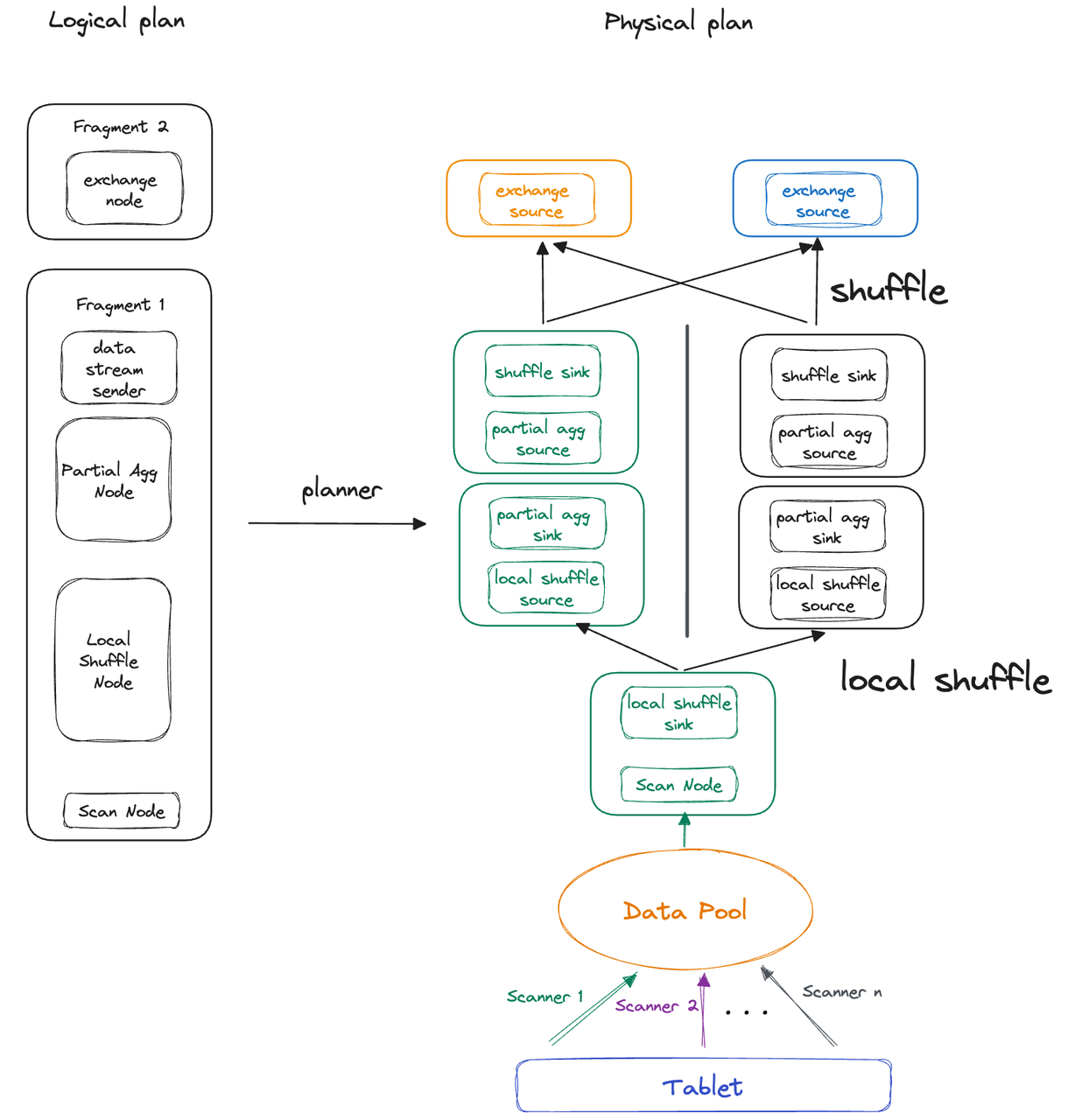
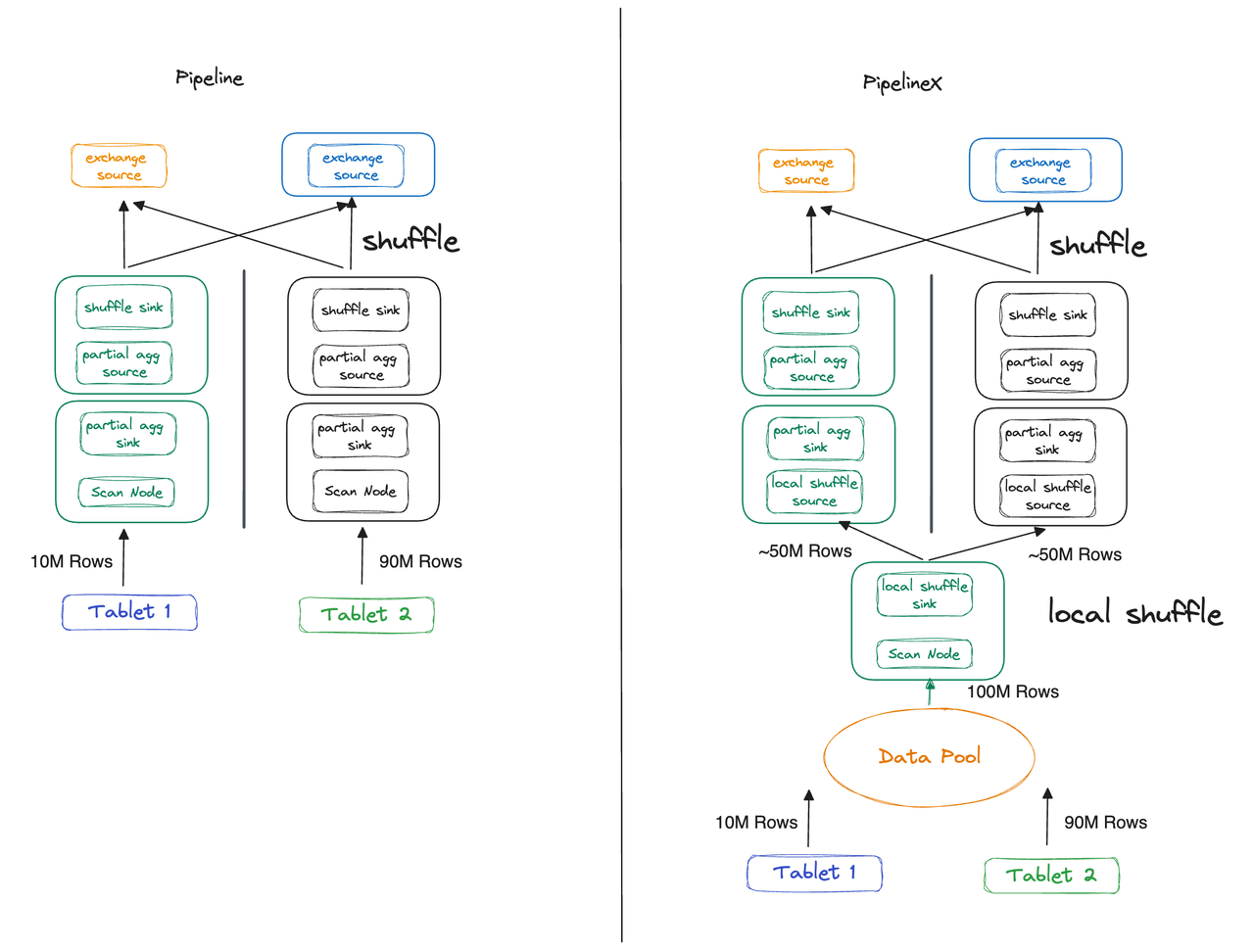
上述问题阐述了 PipelineX 执行引擎如何摆脱 Tablet 数量的限制,除此之外,Local Shuffle 还可以规避数据倾斜带来的长尾查询问题。我们仍假定使用上面的聚合查询,将 Table A 的 Tablet 数量改为 2,其中 Tablet 1 有 10M 行数据、Tablet 2 有 90M 行数据:
Pipeline 引擎:在改造之前(下图左),当执行 Fragment 1 时,Thread 2 的执行时间约为 Thread 1 的 9 倍。
PipelineX 引擎:在改造之后(下图右),Local Shuffle 会将把这 100M 行数据均匀地分发给 2 个执行线程,使其不再受存储层数据倾斜的影响,执行时间相同。
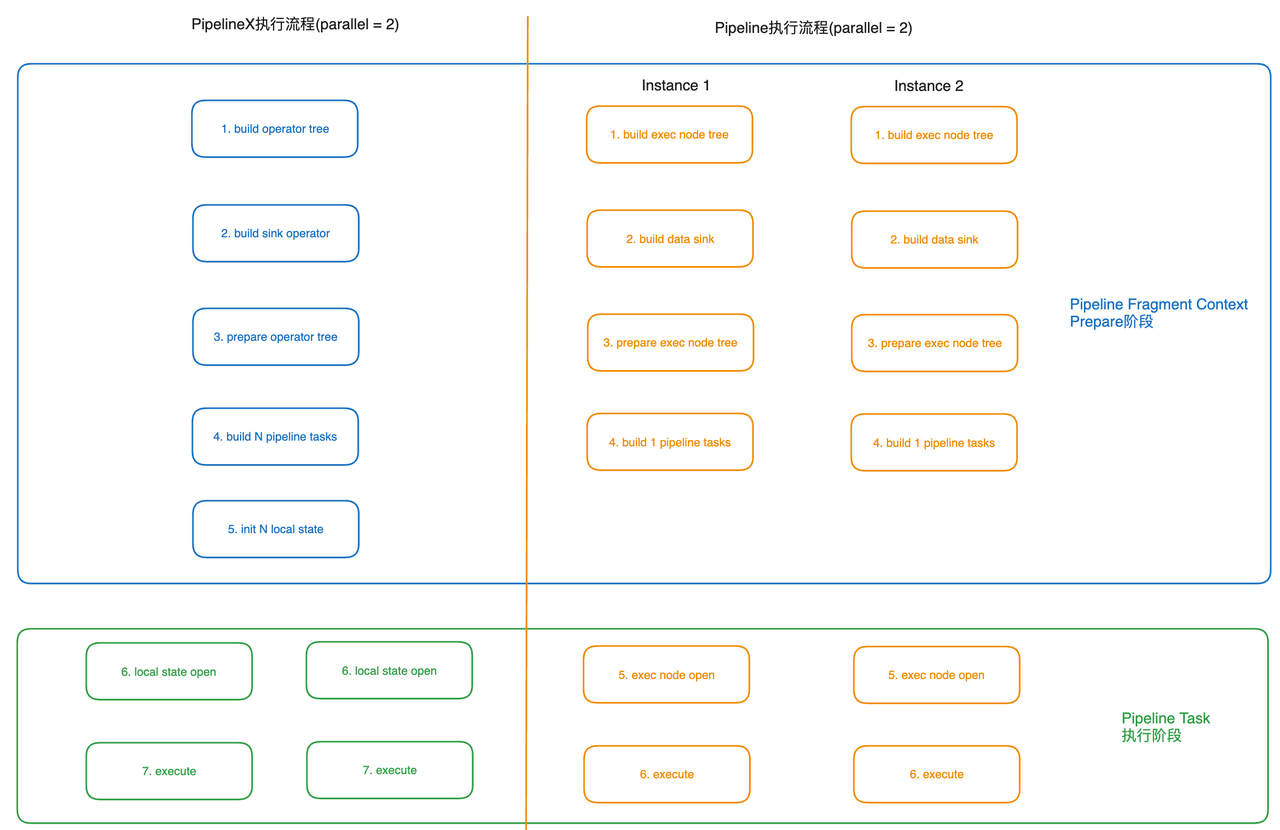
执行流程改造
上文中提到,表达式各 Instance 相互独立,而 Instance 的初始化参数存在大量公共部分,这导致每次执行都需要额外进行重复的初始化步骤。为了降低不必要的执行开销,PipelineX 对共享状态进行了复用,将 Pipeline 执行流程中的第 3 步拆分为 Pipelinex 执行流程中的第 3 步和第 5 步。这样就可以只对较重的 Global State 进行一次初始化,而对更轻量级的 Local State 进行串行初始化。
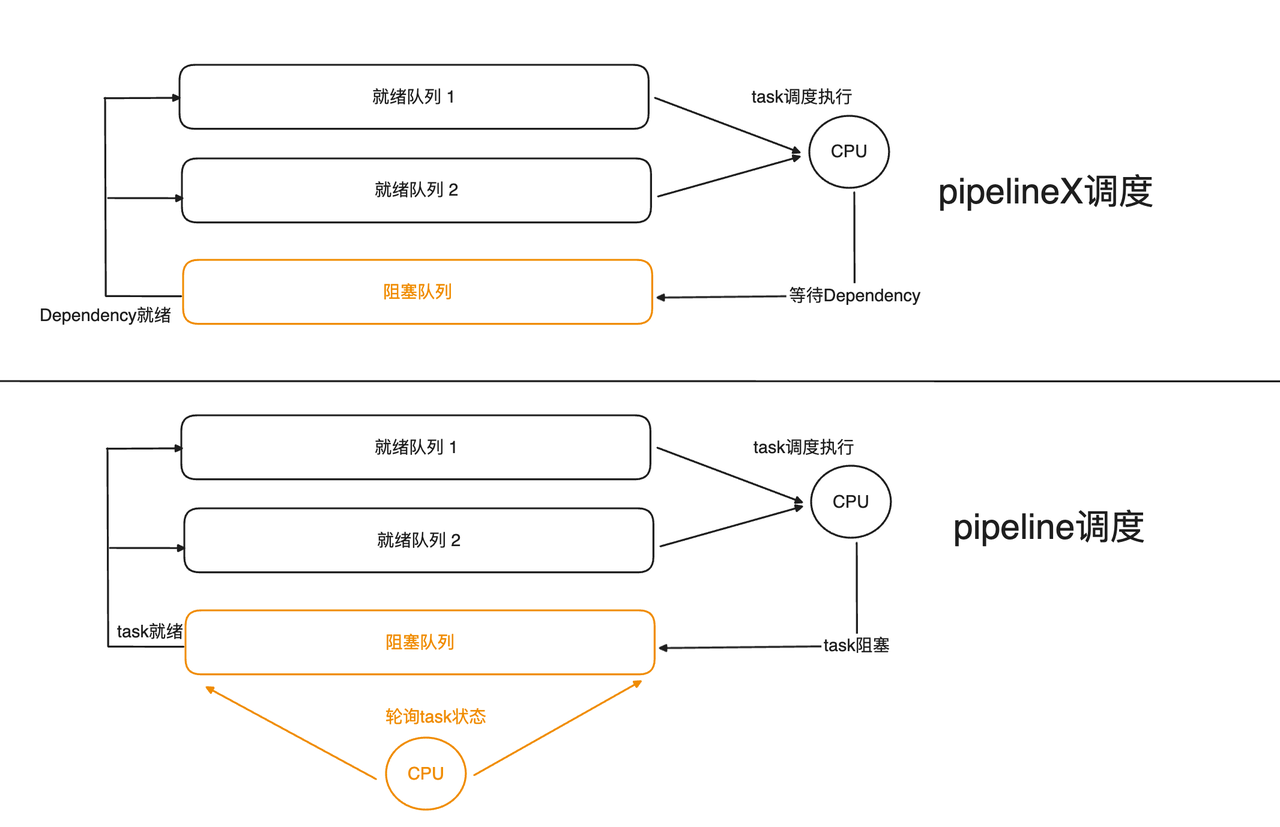
调度模型改造
Pipeline 调度过程中,就绪 Task 保存在就绪队列中等待调度、阻塞 Task 保存在阻塞队列中等待满足执行条件,因此额外需要一个 CPU Core 去轮询阻塞队列,如果 Task 满足执行条件则保存在就绪队列中。而 PipelineX 将阻塞条件通过 Dependency 封装,Task 的阻塞/就绪状态完全依赖于事件通知。当 RPC 数据到达时,将触发 ExchangeSourceOperator 满足执行条件,并进入就绪队列。
PipelineX 对执行调度的核心改造就是引入了事件驱动, 一个查询被分割为多个 Pipeline,所有的 Pipeline 组成一个有向无环图(DAG),以 Pipeline 为点、上下游 Pipeline 彼此的依赖作为边,我们将所有边抽象为 Dependency,每个 Pipeline 是否可以执行取决于其所有的 Dependency 是否满足执行条件。继续以简单聚合查询为例,查询被切分成如下 DAG:
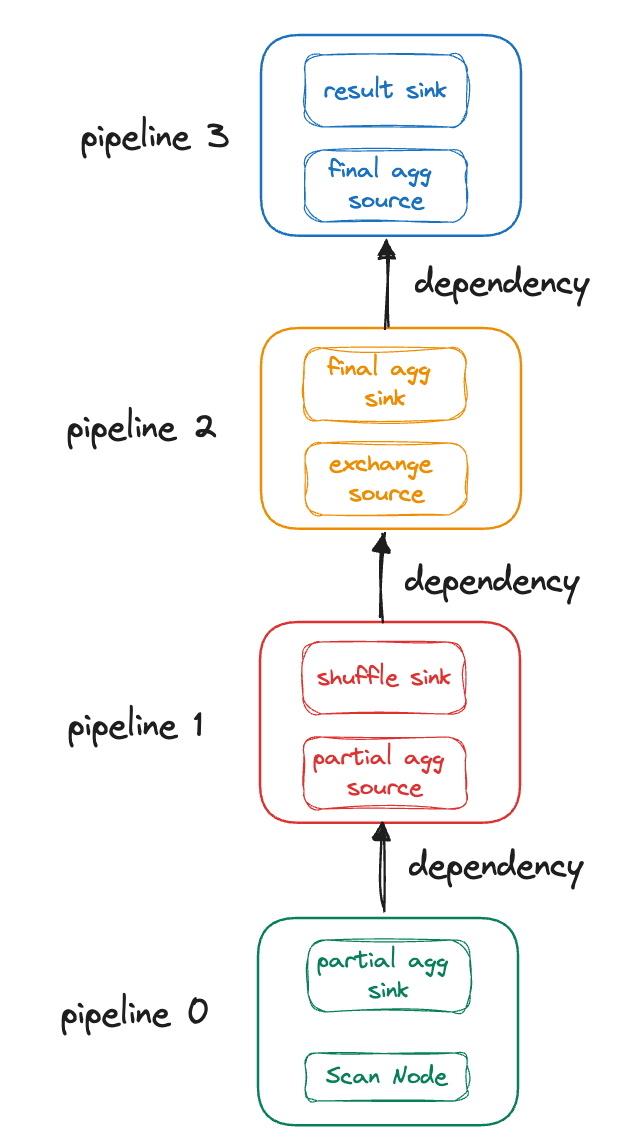
简单起见,图上只标明了 Pipeline 上下游之间构成的 Dependency,事实上,Pipeline 所有的阻塞条件都被抽象成为了 Dependency,例如 Scan Node 依赖 Scanner 读取数据才可以执行,这一部分同样被抽象成为 Dependency 作为 Pipeline 0 是否可以执行的条件。
对于每个 Pipeline 来说,执行流程图如下:
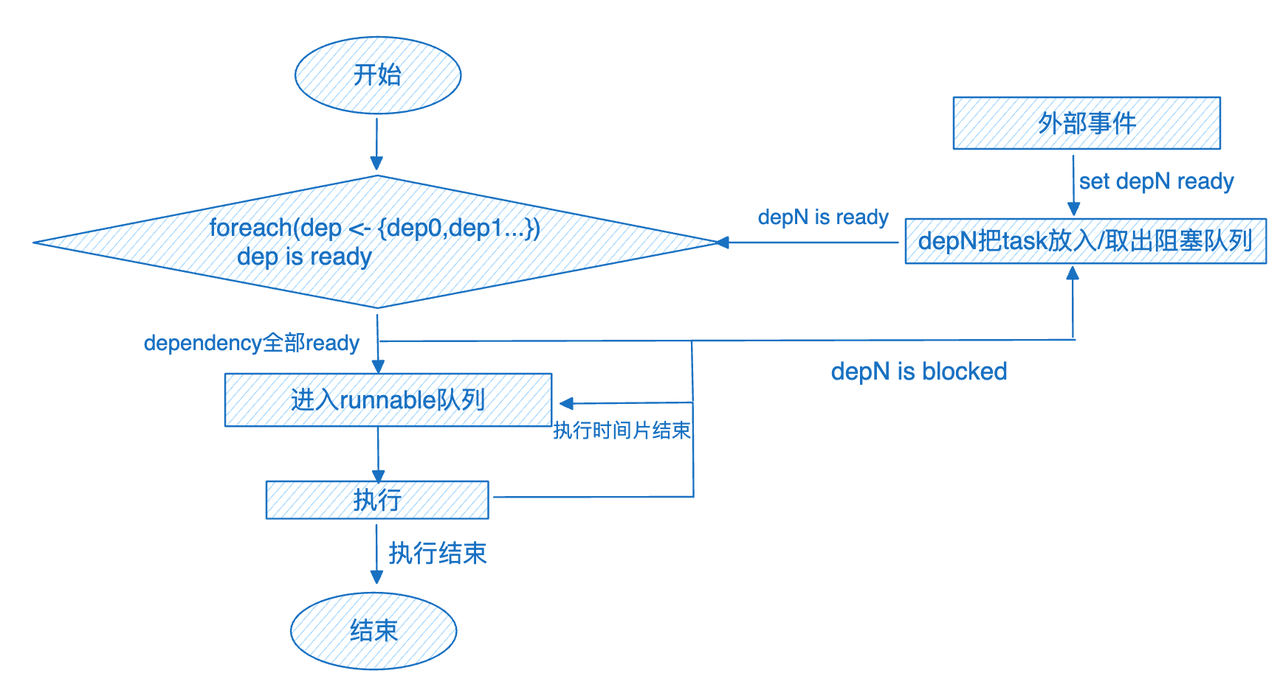
在经由事件驱动的 PipelineX 改造后,每个 Pipeline Task 在执行前都会判断所有的执行条件是否满足。当所有依赖关系都满足执行条件时,Pipeline 被执行。当有条件不满足时,Task 会被添加到相应 Dependency 的阻塞队列中。当有外部事件到达时,所有阻塞 Task 重新判断执行条件,条件满足则进入执行队列中。
基于以上改造,PipelineX 消除了轮询线程的额外开销,尤其是消除了当集群负载较高时轮询线程轮询所有 Pipeline Task 带来的性能损耗。同时得益于 Dependency 的封装,Doris 的 PipelineX 引擎也拥有了更灵活的调度框架,使得后续实现 Spill 更容易。
Profile 改造
对于 Operator Profile,PipelineX 引擎进行了重新整理,删除了不合理的指标并新增了必要的指标。除此以外,得益于对调度模型的改造、所有阻塞都被 Dependency 封装,我们将所有 Dependency 的就绪时间添加到 Profile 中,通过 WaitForDependency 可直观掌握每个环节的时间开销。以 Profile 中的 Scan operator 和 Exchange Source Operator 为例:
Scan Operator:
OLAP_SCAN_OPERATOR的执行总时间是 457.750ms(包括 Scanner 读数据和执行时间),因 Scanner 扫描数据阻塞了 436.883ms。
OLAP_SCAN_OPERATOR (id=4. table name = Z03_DI_MID): - ExecTime: 457.750ms - WaitForDependency[OLAP_SCAN_OPERATOR_DEPENDENCY]Time: 436.883msExchange Source Operator:
EXCHANGE_OPERATOR的执行时间为 86.691us,等待上游数据的时间为 409.256us。
EXCHANGE_OPERATOR (id=3): - ExecTime: 86.691us - WaitForDependencyTime: 0ns - WaitForData0: 409.256us总结与展望
在完成 Pipeline 执行模型的改造后,Apache Doris 在高负载情况下集群假死以及资源抢占的问题得以彻底解决、CPU 利用率得到大幅提升,而 PipelineX 执行引擎的迭代又进一步优化了执行引擎的并发执行模式与调度模式,使得 Apache Doris 执行引擎取得了显著的收益和进步,能够在真实生产环境中帮助用户进一步提升执行效率。
目前,我们正在将广泛应用于大数据场景的数据落盘技术与 PipelineX 引擎相结合,旨在进一步提升查询的性能及可靠性。未来,我们计划在 PipelineX 运行时实现更多的自动优化功能,如自适应并发和自适应计划调优,以进一步提高执行效率和性能。同时,我们也将深耕 NUMA(非一致性存储访问)本地性,以更充分利用硬件资源,提供更卓越的查询性能表现。
Reference
Peter A. Boncz, Marcin Zukowski, Niels Nes.MonetDB/X100: Hyper-Pipelining Query Execution. CIDR 2005: 225-237.
Leis, Viktor and Boncz, Peter and Kemper, Alfons and Neumann, Thomas. Morsel-driven parallelism: A NUMA-aware query evaluation framework for the many-core age. SIGMOD 2014: 743-754.




