欢迎阅读新一期的数据库内核杂谈。上一期杂谈介绍了 Parquet 存储格式。这一期,咱们收个尾,介绍一下 Parquet 如何支持表结构的演进(schema evolution)以及使用 Parquet 时的一些最佳实践。
支持 schema evolution(add/delete/rename columns)
在大数据业务驱动下,数据的表结构(table schema)会因为需求快速迭代而被改变。大数据系统需要具备在不影响现有应用程序或工作流的情况下,支持表结构演进(schema evolution)的能力。Parquet 格式为 schema evolution 提供了良好的功能支持,使其成为现代大数据系统的理想存储格式。
首先,Parquet 的 datafile 存储了数据的 schema information;这个信息以元数据的形式存储在数据文件中,见下图(源于上一期的实操数据)。但是,这个 schema 信息,并不是作为查询引擎的 source of truth,只是定义了这个数据文件存储的 schema(相当于这个 datafile 的 source of truth)。这个信息用来对于数据读取做优化以及确保查询引擎可以正确地解析数据。
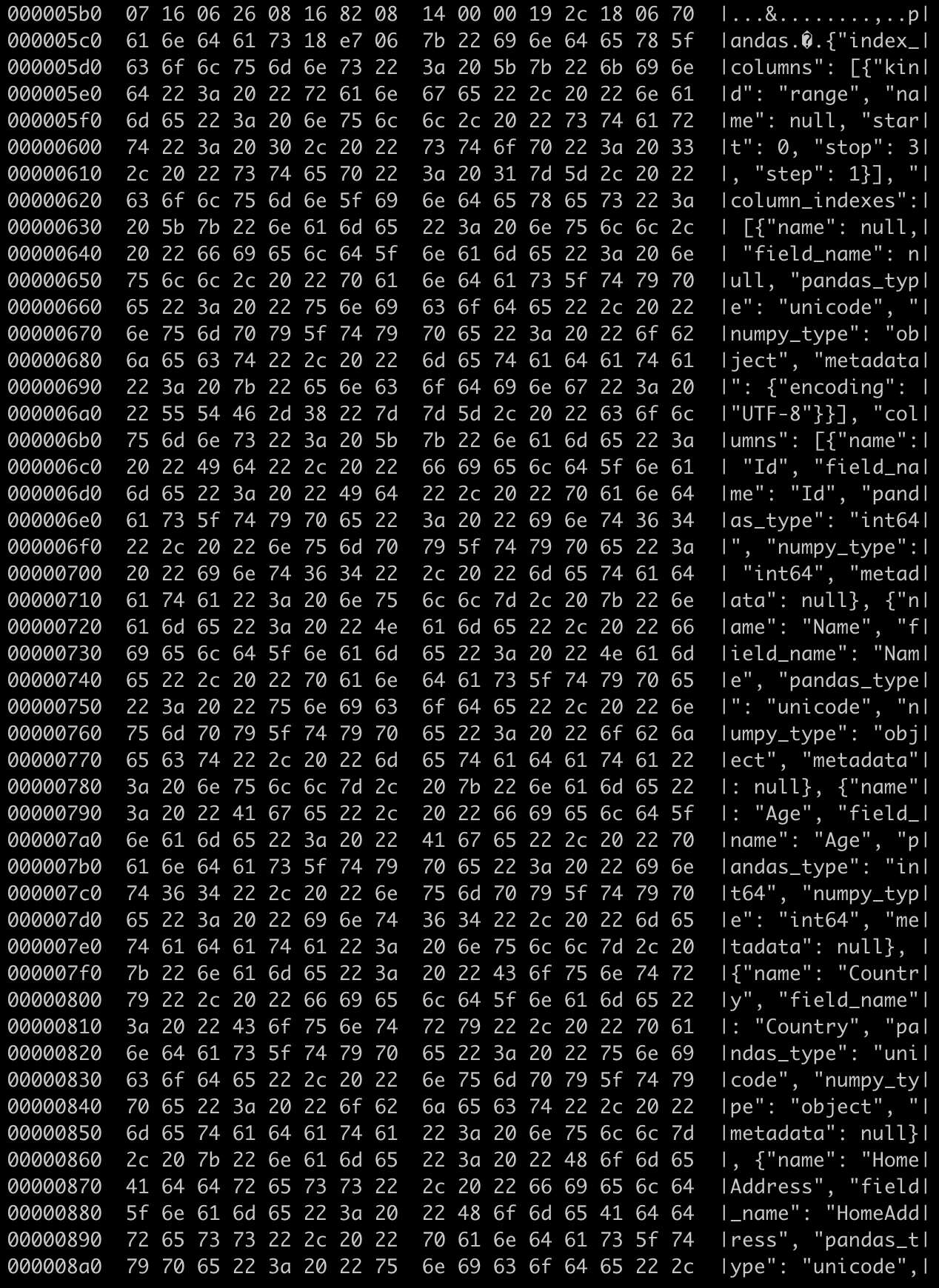
(Parquet datafile 中存储了 schema 信息)
表格式的 source of truth 通常存储在大数据系统的元数据中心(比如 Hive Metastore,或者是 Apache Spark Catalog)。元数据中心会记录 schema 的改变,比如新增或者删除 column。同时也会保存 schema 的所有历史 version。
我们通过一个例子(接着使用 student 表),来看 Parquet 的 schema 信息,结合数据系统的 metadata service 是如何支持 schema evolution 的。表 student 的初始 schema 定义如下:
Table student(bigint id, string name, int age, string country, string home_address)
在某个时间点,schema 改成了如下:
Table student(bigint id, string name, int age, string country, string school_name optional)(添加了一个新的 optional 的 field school_name,同时,为了保护隐私,删除了 home_address)。系统在改变 schema 后,新导入(插入)的数据,都用了最新的 schema。即,新的 Parquet datafile 只有 id, name, age, country 和 school_name 这些 columns,但旧的 datafile 有 id,name,age,country 和 home_address 这些 columns。
此时,用户对数据进行查询时,查询引擎会根据数据系统的 metastore 中存储的 schema 信息,结合读取的 Parquet datafile 上的 schema 信息,来决定如何正确地读取数据:1)当读取最新 Parquet datafile 的时候,因为 schema 是匹配的,没有任何问题。2)但读取旧 Parquet datafile 的时候,查询引擎会发现 home_address 这个 column 在新的 schema 已经被删除了。因此,没有必要读取这个 column 的数据(归功于 Parquet 的列存设计,可以避免这一块数据的 IO);同时,查询引擎发现旧 datafile 并不存在 school_name 这个 column,查询引擎可以直接返回 NULL 值或者是 default 值。3)同理可得,当我们使用一个旧的 schema 去读取数据的时候(这种情况比较少,比如 time-travel query),对于新 schema 的 column mismatch 也可以通过相同的方法来返回数据(对于已经删除的 column,返回 NULL 值或者 default 值;对于新增的 column,不用读取这部分数据)。
虽然 Parquet 本身不支持 rename column 操作(因为 Parquet 的 datafile 只存储了当前数据 schema 信息),但是配合 metadata service 的 schema versioning,依然可以通过新旧 column 的 mapping 信息来支持 rename column 后的数据读取。对于 column 的 type change,查询引擎配合新旧 type 的 compatibility,就可以支持数据的读取,比如 int -> bigint 等(可能会因为数据转换导致精度缺失)。
最佳实践
Devils in the detail,Parquet 有很多可配置的使用选项。合理、正确的配置才能做到在查询性能、存储优化上获得收益和平衡。在本节中,我们讨论使用 Parquet 的一些需要关注的点和相应的最佳实践。
压缩算法(compression)和编码选项(encoding)
Parquet 支持多种压缩和编码算法,来优化存储和查询性能。选择合适的组合对于实现最佳效果至关重要。下面是一些最佳实践:
压缩:Parquet 支持几乎所有流行的压缩算法,包括 Snappy、Gzip 和 LZO。Snappy 在压缩比和速度之间提供了良好的平衡,使其成为常见的选择。Gzip 提供更好的压缩比,但以较慢的压缩和解压速度作为代价。LZO 优化了速度,但提供了较低的压缩比。高度压缩的数据可能需要更多的 CPU 资源来进行解压缩,影响查询性能。所以,根据具体的业务需求(是追求查询性能还是追求存储成本)选择一个平衡的压缩算法和压缩级别。
编码:Parquet 支持多种编码方案,如 dict encoding, run-length encoding(RLE)和位打包(bit packing)。编码的选择取决于数据特征。例如,对于基数较低(不同值较少)的列,字典编码效果很好,而对于单调递增或递减值的列,增量编码更为合适。在绝大部分情况下,让 Parquet 自行选择就好,Parquet 会根据 column 的数据类型和分布自动选择最高效的编码技术。
数据文件大小和分区
优化文件大小和合理的分区策略可以显著地提高查询性能。
文件大小:将文件大小控制在 64MB 到 1GB 之间。较大的文件可以实现更好的压缩,减少管理众多小文件的开销,提高查询性能。然而,非常大的文件可能会导致内存使用增加和处理速度变慢。最佳实践就是,根据实际的查询逻辑,尝试配置不同文件大小,以找到平衡点。
分区:分区策略并不只适用于 Parquet。根据经常用作查询过滤器的列对数据进行分区。这允许查询引擎仅读取相关的分区,减少 I/O 开销并提高查询性能。常见的分区策略包括按日期或分类变量进行分区。避免创建太多小分区,因为这可能导致管理元数据的开销增加。
避免创建过多小文件,因为这可能对查询性能产生负面影响。
Schema evolution 支持
在第一节中,我们介绍了 Parquet 如何支持 schema evolution。下面是一些相关的最佳实践:
添加新 column:在添加新 column 时,尽量将其设为可选,并提供默认值。这确保了向后兼容性,因为查询引擎可以为旧数据中的新 column 返回空值或默认值。
重命名 column:由于 Parquet 不直接支持 column 重命名,所以需要和支持重命名的数据系统引擎联动。最佳实践就是规范命名,尽可能避免重命名。
更改列数据类型:将数据类型更改限制为扩展数字类型或将可为空类型更改为不可为空类型。对于更复杂的更改,使用查询引擎在查询进行时(runtime)执行类型转换。
分析型查询优化工作
过滤和排序:利用 Parquet 的谓词下推(predicate push down)和列剪裁(column prune)功能来优化查询性能。将过滤器下推到存储层可减少从磁盘读取的数据量,而列剪裁可确保只读取相关列。
向量化查询处理:使用支持向量化查询的查询引擎(如 Apache Arrow),以进一步提高列式数据的查询性能。
总结
这一期,咱们对 Parquet 存储格式的内容进行了收尾,聊了一下 Parquet 是如何配合大数据系统做 schema evolution 的,以及一些实际使用中的最佳实践。
写在 5 周年之际
数据库内核杂谈,最开始是在简书开始连载的(附上了第一篇的截图)。也算是一个阴差阳错的契机吧(说起来都物是人非啦。哈哈哈!)不知不觉,已经快 5 周年了!感谢大家的陪伴和支持!也感谢一下自己的坚持。周期性的更新杂谈也是反向 push 我不断去学习。期待下一个 5 年。

内核杂谈微信群和知识星球
内核杂谈有个微信群,大家会在上面讨论数据库相关话题。目前群人数快 400 人啦,所以已经不能分享群名片加入了,可以添加我的微信(zhongxiangu)或者是内核杂谈编辑的微信(wyp_34358),备注:内核杂谈。
除了数据库内核的专题 blog,我还会 push 自己分享每天看到的有趣的 IT 新闻,放在我的知识星球里(免费的,为爱发电),欢迎加入。