
Linux 存在众多 tracing tools,比如 ftrace、perf,他们可用于内核的调试、提高内核的可观测性。众多的工具也意味着繁杂的概念,诸如 tracepoint、trace events、kprobe、eBPF 等,甚至让人搞不清楚他们到底是干什么的。本文尝试理清这些概念。
注入 Probe 的机制
Probe Handler
如果我们想要追踪内核的一个函数或者某一行代码,查看执行的上下文和执行情况,通用的做法是在代码或函数的执行前后 printk 打印日志,然后通过日志来查看追踪信息。但是这种方式需要重新编译内核并重启,非常麻烦。如果是在生产环境排查问题,这种方式也是无法接受的。
一种比较合理的方式是在内核正常运行时,自定义一个函数,注入到我们想要追踪的内核函数执行前后,当内核函数执行时触发我们定义的函数,我们在函数中实现获取我们想要的上下文信息并保存下来。同时因为增加了内核函数的执行流程,我们定义的函数最好是需要的时候开启,不需要的时候关闭,避免对内核函数造成影响。
这个自定义的函数就是 probe handler,注入 probe handler 的地方被称为探测点或者 Hook 点,在探测点前执行的 probe handler 叫 pre handler, 执行后的叫 post handler,注入 probe handler 的方式被称为“插桩”,内核提供了多种 probe handler 注入机制。接下来我们聊一聊他们是如何实现在内核运行时注入 probe handler。
Kprobes 机制
Kprobes 是一个动态 tracing 机制,能够动态的注入到内核的任意函数中的任意地方,采集调试信息和性能信息,并且不影响内核的运行。Kprobes 有两种类型:kprobes、kretprobes。kprobes 用于在内核函数的任意位置注入 probe handler,kretprobes 用于在函数返回位置注入 probe handler。出于安全性考虑,在内核代码中,并非所有的函数都能“插桩”,kprobe 维护了一个黑名单记录了不允许插桩的的函数,比如 kprobe 自身,防止递归调用。
kprobes 机制如何实现注入 probe handler
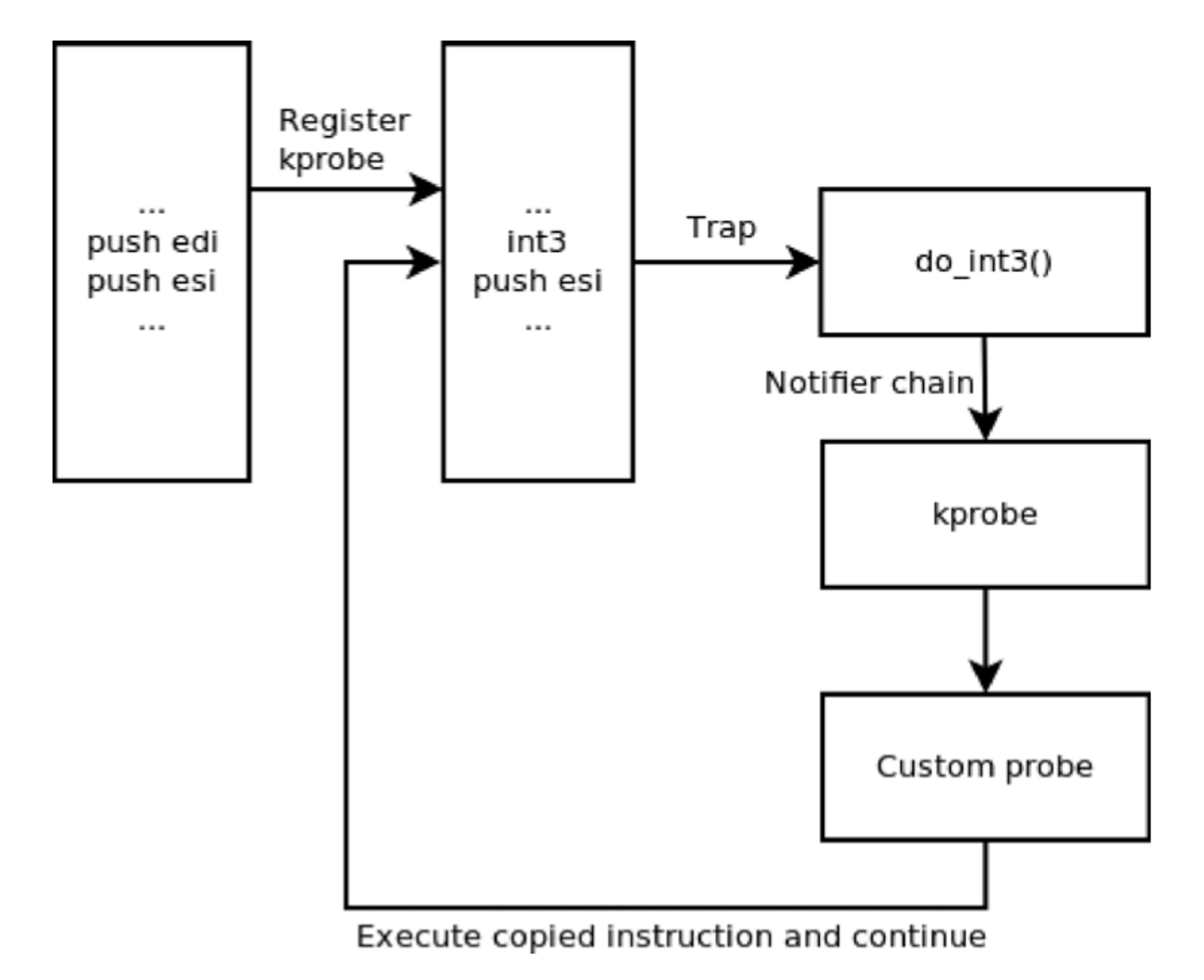
内核提供了一个 krpobe 注册接口,当我们调用接口注册一个 kprobe 在指定探测点注入 probe handler 时,内核会把探测点对应的指令复制一份,记录下来,并且把探测点的指令的首字节替换为「断点」指令,在 x86 平台上也就是 int3 指令。
cpu 执行断点指令时,会触发内核的断点处理函数「do_int3」,它判断是否为 kprobe 引起的断点,如果是 kprobe 机制触发的断点,会保存这个程序的状态,比如寄存器、堆栈等信息,并通过 Linux 的「notifier_call_chain」机制,将 cpu 的使用权交给之前 kprobe 的 probe handler,同时会把内核所保存的寄存器、堆栈信息传递给 probe handler。
前面已经提到了,probe handler 分两种类型,一种是 pre handler、一种是 post handler。pre handler 将首先被调用(如果有的话),pre handler 执行完成后,内核会将 cpu 的 flag 寄存器的值设置为 1,开始单步执行原指令,单步执行是 cpu 的一个 debug 特性,当 cpu 执行完一个指令后便会产生一个 int1 异常,触发中断处理函数「do_debug」执行,do_debug 函数会检查本次中断是否为 kprobe 引起,如果是的话,执行 post handler,执行完毕后关闭单步,恢复原始执行流。
kretprobe 探针很有意思,Kprobe 会在函数的入口处注册一个 kprobe,当函数执行时,这个 krpobe 会把函数的返回地址暂存下来,并把它替换为 trampoline 地址。
Kprobe 也会在 trampoline 注册一个 kprobe,函数执行返回时,cpu 控制权转移到 trampoline,此时又会触发 trampoline 上的 kprobe 探针,继续陷入中断,并执行 probe handler。
为什么有了 kprobe 还需要 kretprobe?
Kprobe 在可以函数的任意位置插入 probe,理论上他也能实现 kretprobe 的功能,但是实际上会面临几个挑战。
比如当我们在函数的最后一行代码上注入探针,试图使用 kprobe 实现 kretprobe 的效果,但是实际上这种方式并不好,函数可能会存在多个返回情况,比如不满足 if 条件,发生异常等情况,此时代码完全有可能不会执行最后一行代码,而是在某个地方就返回了,也就意味着不会触发探针执行。
kretprobe 的优势就在于它可以稳定的在函数返回时触发 probe handler 执行,无论函数是基于什么情况下返回。
另外一方面 kprobe 虽然可以在函数的任意位置插入探针,但是实际情况下都是在函数入口处插入探针,因为函数入口是有一条标准的指令序列 prologue 可以进行断点替换,而函数内部的其他位置,可能会存在跳转指令、循环指令等情况,指令序列不太规则,不方便做断点替换。
Uprobes
Uprobes 也分为 uprobes 和 uretprobes,和 Kprobes 从原理上来说基本上是类似的,通过断点指令替换原指令实现注入 probe handler 的能力,并且他没有 Kprobes 的黑名单限制。Uprobes 需要我们提供「探测点的偏移量」,探测点的偏移量是指从程序的起始虚拟内存地址到探测点指令的偏移量。我们可以通过一个简单的例子来理解:
root@zfane-maxpower:~/traceing# cat hello.c#include <stdio.h>void test(){ printf("hello world");}int main() { test(); return 0;}root@zfane-maxpower:~/traceing# gcc hello.c -o hello通过 readelf 读取程序的 ELF 信息,拿到程序的符号表、节表。符号表包含程序中所有的符号,例如全局变量、局部变量、函数、动态链接库符号,以及符号对应的虚拟内存地址。
汇编语言是按照节来编写程序的,例如.text 节、.data 节。每个节都包含程序中的特定数据或代码,节表就是程序中各个节的信息表。
通过符号表可以拿到 hello 函数的虚拟内存地址,通过节表拿到.text 节的虚拟内存地址,以及.text 节相较于 ELF 起始地址的偏移量。
root@zfane-maxpower:~/traceing# readelf -s hello|grep test 36: 0000000000001149 31 FUNC GLOBAL DEFAULT 16 testroot@zfane-maxpower:~/traceing# readelf -S hello|grep .text [16] .text PROGBITS 0000000000001060 00001060那么 test 函数的指令在 hello 二进制文件的偏移量就可以计算出来了。
offset=test函数的虚拟地址 - .text段的虚拟地址 + .text端偏移量offset= 0000000000001149 - 0000000000001060 + 00001060offset= 0000000000001149现在我们可以通过编写内核模块向二进制程序注入 probe handler 获取数据了。
#include <linux/kernel.h>#include <linux/init.h>#include <linux/module.h>#include <linux/fs.h>#include <linux/uprobes.h>#include <linux/namei.h>#include <linux/string.h>#include <linux/uaccess.h>#define DEBUGGEE_FILE "/home/zfane/hello/hello"#define DEBUGGEE_FILE_OFFSET (0x1149)static struct inode *debuggee_inode;static int uprobe_sample_handler(struct uprobe_consumer *con, struct pt_regs *regs){ printk("handler is executed, arg0: %s\\n",regs->di); return 0;}static int uprobe_sample_ret_handler(struct uprobe_consumer *con, unsigned long func, struct pt_regs *regs){ printk("ret_handler is executed\\n"); return 0;}static struct uprobe_consumer uc = { .handler = uprobe_sample_handler, .ret_handler = uprobe_sample_ret_handler};static int __init init_uprobe_sample(void){ int ret; struct path path; ret = kern_path(DEBUGGEE_FILE, LOOKUP_FOLLOW, &path); if (ret) { return -1; } debuggee_inode = igrab(path.dentry->d_inode); path_put(&path); ret = uprobe_register(debuggee_inode, DEBUGGEE_FILE_OFFSET, &uc); if (ret < 0) { return -1; } printk(KERN_INFO "insmod uprobe_sample\\n"); return 0;}static void __exit exit_uprobe_sample(void){ uprobe_unregister(debuggee_inode, DEBUGGEE_FILE_OFFSET, &uc); printk(KERN_INFO "rmmod uprobe_sample\\n");}module_init(init_uprobe_sample);module_exit(exit_uprobe_sample);MODULE_LICENSE("GPL");Tracepoint
Tracepoint 是一个静态的 tracing 机制,开发者在内核的代码里的固定位置声明了一些 Hook 点,通过这些 hook 点实现相应的追踪代码插入,一个 Hook 点被称为一个 tracepoint。
tracepoint 有开启和关闭两种状态,默认处于关闭状态,对内核产生的影响非常小,只是增加了极少的时间开销(一个分支条件判断),极小的空间开销(一条函数调用语句和几个数据结构)。
在 x86 环境下,内核代码编译后,关闭状态的 tracepoint 代码对应的 cpu 指令是:nop 指令,
启用 tracepoint 时,通过 Linux 内核提供的 static jump patch 静态跳转补丁机制,nop 指令会被替换为 jmp 指令,jmp 指令将 cpu 的使用权转移给 static_call 静态跳转函数,这个函数会遍历 tracepoint probe handler 数组获取当前 tracepoint 注册的 probe handler,并进一步跳转到 probe handler 执行,probe handler 执行完成后,再通过 jmp 指令跳转回原函数继续执行。
#include <linux/module.h>#include <linux/ftrace.h>#include <linux/tracepoint.h>#include <linux/proc_fs.h>#include <linux/seq_file.h>#include <linux/hashtable.h>#include <linux/slab.h>#include <linux/time.h>#include <linux/percpu.h>#include <trace/events/sched.h>static void probe_sched_switch(void *ignore, bool preempt, struct task_struct *prev, struct task_struct *next, unsigned int prev_state) { pr_info("probe_sched_switch: pid [%d] -> [%d] \\n",prev->tgid, next->tgid);}struct tracepoints_table { const char *name; void *fct; struct tracepoint *value; char init;};struct tracepoints_table interests[] = {{.name = "sched_switch", .fct = probe_sched_switch}};#define FOR_EACH_INTEREST(i) \\ for (i = 0; i < sizeof(interests) / sizeof(struct tracepoints_table); i++)static void lookup_tracepoints(struct tracepoint *tp, void *ignore) { int i; FOR_EACH_INTEREST(i) { if (strcmp(interests[i].name, tp->name) == 0) interests[i].value = tp; }}static void cleanup(void) { int i; // Cleanup the tracepoints FOR_EACH_INTEREST(i) { if (interests[i].init) { tracepoint_probe_unregister(interests[i].value, interests[i].fct,NULL); } }}static void __exit tracepoint_exit(void) { cleanup(); }static int __init tracepoint_init(void){ int i; // Install the tracepoints for_each_kernel_tracepoint(lookup_tracepoints, NULL); FOR_EACH_INTEREST(i) { if (interests[i].value == NULL) { printk("Error, %s not found\\n", interests[i].name); cleanup(); return 1; } tracepoint_probe_register(interests[i].value, interests[i].fct, NULL); interests[i].init = 1; } return 0;}module_init(tracepoint_init)module_exit(tracepoint_exit)MODULE_LICENSE("GPL");通过追踪工具来注入 Probe
Event Tracing
在前面的代码示例中,我们需要通过编写 kernel module 的方式注册 probe handler,看上去非常简单,但在实际开发的过程当中,编写内核模块是一个很大的挑战,如果内核模块的代码写的有问题,会直接导致内核 crash,在生产环境上使用内核模块需要谨慎考虑。
Linux 内核为此提供了一个不需要编写内核模块就能使用 tracepoint 的机制:event tracing。他抽象出了如下概念:
TraceEvent:事件是在程序执行过程中发生的特定事情,例如函数调用、系统调用或硬件中断。事件被描述为一个有限的结构,包含有关事件的元数据和数据。每个事件都有一个唯一的标识符和名称。
Event Provider:事件提供程序是一个模块或应用程序,用于在事件跟踪系统中注册和定义事件。事件提供程序负责确定事件的格式和语义,并将事件发送到跟踪缓冲区。
Event Consumer:事件消费者是从事件跟踪缓冲区中读取事件的进程或应用程序。事件消费者可以将事件输出到文件、控制台或通过网络发送到远程主机。
Event Tracing Session:事件跟踪会话是一个包含多个事件提供程序和事件消费者的 ETI 实例。在一个事件跟踪会话中,可以收集多个事件源的事件数据,并将其聚合到单个跟踪缓冲区中。
Trace Buffer:跟踪缓冲区是一个在内核中分配的内存区域,用于存储事件数据。事件提供程序将事件写入跟踪缓冲区,事件消费者从跟踪缓冲区读取事件数据。
Trace Event Format (TEF):跟踪事件格式是一个描述事件数据布局和语义的模板。它指定事件的名称、参数和字段,以及每个字段的大小和类型。在 ETI 中,跟踪事件格式可以由事件提供程序静态定义或动态生成。
Trace Event Id (TEID):跟踪事件 ID 是唯一标识一个跟踪事件的整数值。每个事件提供程序都有自己的 TEID 命名空间,它们使用不同的整数值来标识它们的事件。在内核代码中,包含 tracepoint 代码的函数就可以理解为是一个 event provider,event provider 通过在 tracepoint 上注册一个 probe handler。当这个函数执行到 tracepoint 时,触发 probe handler 执行,它会构建一个 TraceEvent。内核代码中已经有了专门用于构建 trace event 的 probe handler,无需我们自己注入了。
TraceEvent 会包含当前函数的上下文和参数,probe handler 会将 event 保存至在 Trace Buffer 中,接下来对于事件的分析、处理操作可以放在用户态执行,通过系统调用从 Trace Buffer 中读取 event,或者直接通过 mmap 直接将 Trace Buffer 映射到用户态的内存空间读取 event。
我们现在可以这样使用 tracepoint:
查看当前内核支持的 event。
cat /sys/kernel/debug/tracing/available_events启用 syscalls:sys_enter_connect 这个事件。
echo 1 > /sys/kernel/debug/tracing/events/syscalls/sys_enter_connect/enable查看事件数据。
root@zfane-powerpc:~# cat /sys/kernel/debug/tracing/trace# tracer: nop## entries-in-buffer/entries-written: 195/195 #P:16## _-----=> irqs-off/BH-disabled# / _----=> need-resched# | / _---=> hardirq/softirq# || / _--=> preempt-depth# ||| / _-=> migrate-disable# |||| / delay# TASK-PID CPU# ||||| TIMESTAMP FUNCTION# | | | ||||| | | sd-resolve-809 [001] ..... 1401.623886: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10) sd-resolve-809 [001] ..... 1411.634396: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10) systemd-resolve-793 [001] ..... 1411.634827: sys_connect(fd: 14, uservaddr: 7ffe2e97d050, addrlen: 10) systemd-resolve-793 [001] ..... 1411.634967: sys_connect(fd: 13, uservaddr: 7ffe2e97d000, addrlen: 10) sd-resolve-809 [001] ..... 1421.645348: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10) rsyslogd-848 [002] ..... 1426.678287: sys_connect(fd: 6, uservaddr: 7f3be1fb3bc0, addrlen: 6e) sd-resolve-809 [001] ..... 1431.655820: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10) systemd-resolve-793 [001] ..... 1436.661514: sys_connect(fd: 13, uservaddr: 7ffe2e97d050, addrlen: 10) systemd-resolve-793 [001] ..... 1436.661679: sys_connect(fd: 14, uservaddr: 7ffe2e97d000, addrlen: 10) rsyslogd-848 [009] ..... 1436.677930: sys_connect(fd: 6, uservaddr: 7f3be1fb3bc0, addrlen: 6e) rsyslogd-848 [009] ..... 1436.686721: sys_connect(fd: 6, uservaddr: 7f3be1fb3bc0, addrlen: 6e) sd-resolve-809 [001] ..... 1441.666368: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10) systemd-resolve-793 [001] ..... 1451.675741: sys_connect(fd: 13, uservaddr: 7ffe2e97d050, addrlen: 10) sd-resolve-809 [000] ..... 1451.675874: sys_connect(fd: c, uservaddr: 7f618b836d8c, addrlen: 10)在这个示例中,我们只是查看了 sys_enter_connect 这个 trace event,没有做进一步的分析和处理操作,在后面我们可以借助一些工具消费 trace event。
基于 tracepoint 的 Trace Event 虽然解决了 tracepoint 的 probe handler 注册需要编写内核模块才能使用的问题,但任然有 2 个问题没有解决:
并非所有的内核函数都有 Tracepoint,即使有某个内核函数有 Tracepoint,如果内核开发者没有为这个 Tracepoint 实现构建 Event 和保存 Event 到 Trace Buffer 的逻辑,同样也没有办法获取 Trace 信息。
内核开发者需要编写代码将 trace 信息保存到 Trace Buffer,作为内核的用户,我们只能看到内核开发者想让我们看到的数据根据前面提到的 trace event 的实现原理,event 就是 probe handler 构建的,那么如果我们在 kprobe 的 probe handler 中实现构建一个 event 并保存的逻辑,不就能实现一个基于 kprobe 的 Trace Event 吗?Event Trace 已经支持了这样的骚操作,下面是 Linux 内核给出的示例:
添加基于 kprobe、kretprobe 的 event。
echo 'p:myprobe do_sys_open dfd=%ax filename=%dx flags=%cx mode=+4($stack)' > /sys/kernel/tracing/kprobe_events他的语法格式按照如下约定:
p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] : Set a prober[MAXACTIVE][:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] : Set a return probep:[GRP/]EVENT] [MOD:]SYM[+0]%return [FETCHARGS] : Set a return probe-:[GRP/]EVENT : Clear a probe[GRP/][EVENT] 定义一个 event,[MOD:]SYM[+offs]|MEMADDR, 定义一个 kprobe。[FETCHARGS] 是设置参数的类型。在上面的示例中,为什么往这个文件里写入一些文本,就可以实现 kprobe 的 probe handler 的能力?这主要依赖于 TraceFS 文件系统。
Tracefs 是什么?
TraceFS 是 Linux 内核提供的一个虚拟文件系统,他提供了一组文件和目录,用户可以通过读写这些文件和目录来与内核中的跟踪工具交互。
以 kprobe_event 为例,krpobe_event 在 tracefs 文件系统中注册了一个回调函数 init_kprobe_trace,在挂载 tracefs 文件系统时执行,他会创建 kprobe_events 文件,并注册对这个文件的读写操作监听。
static const struct file_operations kprobe_events_ops = { .owner = THIS_MODULE, .open = probes_open, .read = seq_read, .llseek = seq_lseek, .release = seq_release, .write = probes_write,};/* Make a tracefs interface for controlling probe points */static __init int init_kprobe_trace(void){ struct dentry *d_tracer; struct dentry *entry; if (register_module_notifier(&trace_kprobe_module_nb)) return -EINVAL; d_tracer = tracing_init_dentry(); if (IS_ERR(d_tracer)) return 0; entry = tracefs_create_file("kprobe_events", 0644, d_tracer, NULL, &kprobe_events_ops); /* Event list interface */ if (!entry) pr_warning("Could not create tracefs " "'kprobe_events' entry\\n"); /* Profile interface */ entry = tracefs_create_file("kprobe_profile", 0444, d_tracer, NULL, &kprobe_profile_ops); if (!entry) pr_warning("Could not create tracefs " "'kprobe_profile' entry\\n"); return 0;}fs_initcall(init_kprobe_trace);当 kprobe_event 文件有写操作时,便会触发create_trace_kprobe函数执行,按照特定的语法解析 kprobe_event 文件内容,创建一个 kprobe。
static ssize_t probes_write(struct file *file, const char __user *buffer, size_t count, loff_t *ppos){ return traceprobe_probes_write(file, buffer, count, ppos, create_trace_kprobe);}在内核追踪技术的发展初期,追踪相关的文件都放在 debugfs 虚拟文件系统中,debugfs 主要设计目的是为了提供一个通用的内核调试接口,内核的任意子系统都有可能使用 debugfs 做调试,所以很多人出于安全考虑 debugfs 是不启用的,这就导致无法使用内核的追踪能力,tracefs 随之诞生了,他会创建一个/sys/kernel/tracing目录,但为了保证兼容性,tracefs 仍然挂载在/sys/kernel/debug/tracing下。如果没有启用debugfs,tracefs 可以挂载在/sys/kernel/tracing。
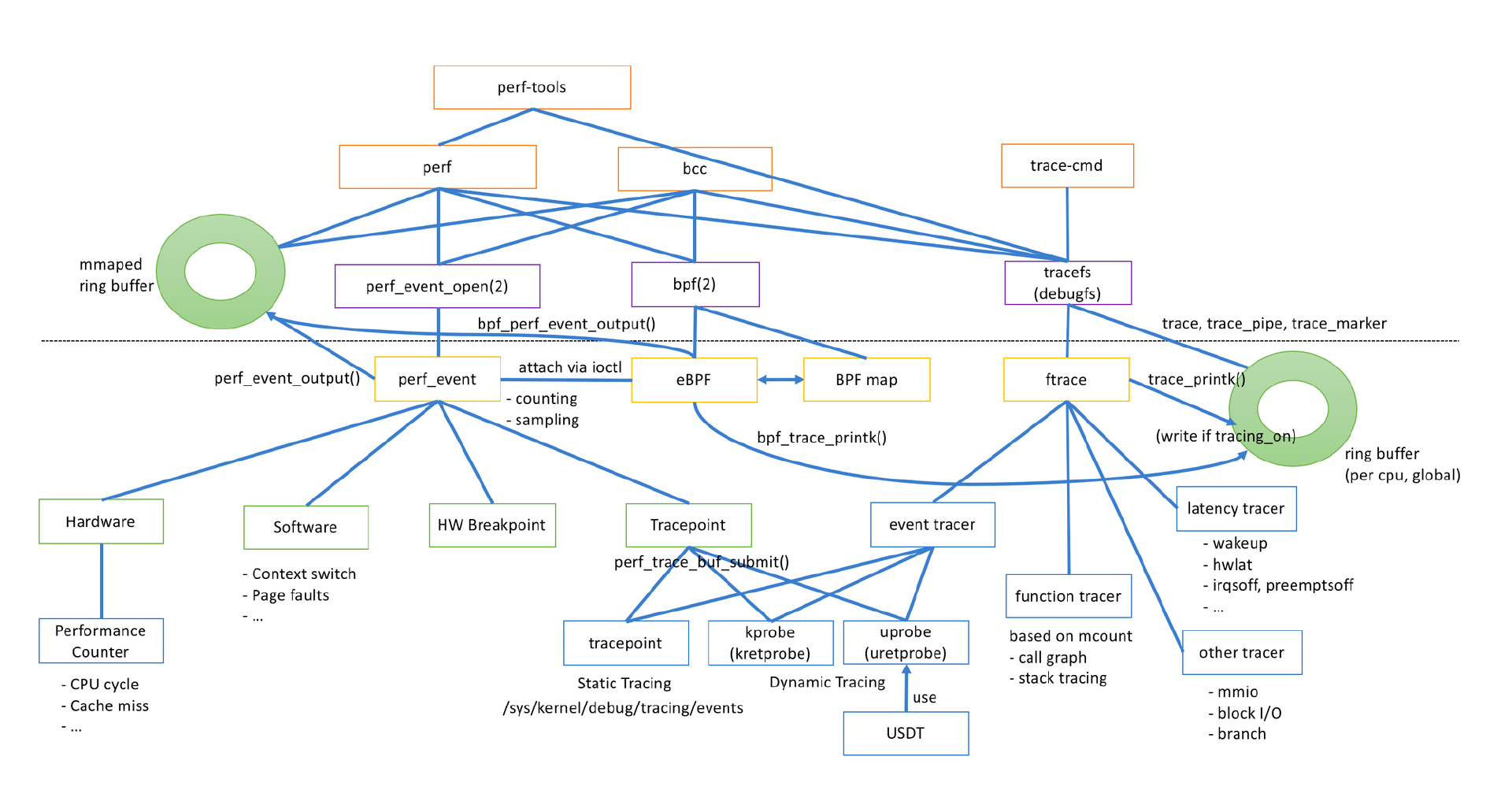
随着 Linux 追踪技术的发展,TraceFS 文件系统也成为了追踪系统的基础设施,很多跟踪工具都使用 TraceFS 作为管理接口,比如 Perf、LTTng 等。
Function Trace
前面提到的 event trace 机制与基于 tracefs 文件系统管理 event 的机制最初就是 Ftrace 的一部分能力,现在已经成为 Linux 内核追踪系统的通用模块,很多追踪工具也都依赖它。那么 Ftrace 是什么呢?
Ftrace 有两层含义:
为函数注入 probe handler 的函数跟踪的机制;
基于 trace fs 和 event trace 机制的 trace 框架。我们前面已经了解了 kprobes、tracepoint 两种注入 probe handler 的机制,而 Ftrace 又带了一种新的实现方式:编译时注入。
gcc 有一个编译选项:-pg,当使用这个编译选项编译代码时,他会在每一个函数的入口添加对 mcount 函数的调用,mcount 函数由 libc 提供,它的实现会根据具体的机器架构生成相应的代码。一般情况下 mcount 函数会记录当前函数的地址、耗时等信息,在程序执行结束后,生成一个.out 文件用于给 gprof 来做性能分析的。我们可以编译一个 hello.c 文件查看汇编代码中包含了 mcount 调用。
root@zfane-maxpower:~/traceing# cat hello.c#include <stdio.h>void test(){ printf("hello world");}int main() { test(); return 0;}root@zfane-maxpower:~/traceing# gcc -pg -S hello.croot@zfane-maxpower:~/traceing# cat hello.s .file "hello.c" .text .section .rodata.LC0: .string "hello world" .text .globl test .type test, @functiontest:.LFB0: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 61: call *mcount@GOTPCREL(%rip) //在这个地方添加了 mcount 调用 leaq .LC0(%rip), %rax movq %rax, %rdi movl $0, %eax call printf@PLT nop popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc.LFE0: .size test, .-test .globl main .type main, @functionmain:.LFB1: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 61: call *mcount@GOTPCREL(%rip) //在这个地方添加了 mcount 调用 movl $0, %eax call test movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc.LFE1: .size main, .-main .ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0" .section .note.GNU-stack,"",@progbits .section .note.gnu.property,"a" .align 8 .long 1f - 0f .long 4f - 1f .long 50: .string "GNU"1: .align 8 .long 0xc0000002 .long 3f - 2f2: .long 0x33: .align 84:内核代码的编译是不依赖 libc 库,而 ftrace 提供了一个 mcount 函数,在这个函数中实现 probe handler 的能力,如果所有的内核函数都在函数入口添加 mcount 调用,运行时会对性能造成极大的影响,我们之前介绍的 kprobes、tracepoint 都具备动态开启和关闭的能力尽可能的减少对内核的影响,Ftrace 也不例外,他具备动态开启某个函数的 probe handler 的能力,其实现思路有一点特别。
内核编译时(设置-pg 的编译选项),在汇编阶段生成.o 的目标文件,再调用 ftrace 在内核代码包中放置的一个Perl脚本Recordmcount.pl,他会扫描每一个目标文件,查找 mcount 函数调用的地址,并记录到一个临时的.s 文件中(一个目标文件对应一个.s 文件),查找完成后,将临时的.s 文件编译成.o 目标文件和原来的.o 文件链接到一起。
在编译过程的链接阶段,vmlinux.lds.h 把所有的__mcount_loc 端的内容放在 vmlinux 的.init.data 端,并声明了两个全局符号__start_mcount_loc 和__stop_mcount_loc 来开启和关闭 mcount 函数调用。
在内核启动阶段,会调用 ftrace_init 函数,在这个函数中,根据记录的 mcount 函数偏移地址,把所有的 mcount 函数调用对应的指令修改为 NOP 指令。ftrace_init 函数在 start_kernel 中调用,比 kerne__init 还要先执行,此时不会有任何内核代码执行,修改指令不会有任何影响。
在对某个函数启用 ftrace probe handler,会将 NOP 指令修改为对 ftrace probe handler 的调用即可,和 kprobe trap 一样的原理,找到需要被 trace 的函数,函数的 mcount 调用是 NOP 指令,把 NOP 指令的第一个字节改为 int 3,也就是断点指令,再把 NOP 指令调整为 probe handler 的地址。
在内核 4.19 版本,提升了最低版本的 gcc 限制,最低可允许 gcc 4.6 版本编译,gcc 4.6 版本支持-mfentry 编译参数,使用 fentry 的特殊函数调用作为所有函数的第一条指令,他可以替代 mcount 函数调用,并且性能更好。
Ftrace 这种通过编译参数注入的 probe handler 非常好用,编译完成后,相当于各个内核函数都声明了 tracepoint,在内核运行时可以动态打开和关闭。那我们能否可以只使用 Ftrace 的 probe handler 注入能力呢?也是可以的,他有一个新的名字叫 fprobe,在 2022 年合入内核代码,他是 ftrace 的包装器,可以仅使用 ftrace 的函数追踪的功能。
#define pr_fmt(fmt) "%s: " fmt, __func__#include <linux/kernel.h>#include <linux/module.h>#include <linux/fprobe.h>#include <linux/sched/debug.h>#include <linux/slab.h>#define BACKTRACE_DEPTH 16#define MAX_SYMBOL_LEN 4096static struct fprobe sample_probe;static unsigned long nhit;static char symbol[MAX_SYMBOL_LEN] = "kernel_clone";module_param_string(symbol, symbol, sizeof(symbol), 0644);MODULE_PARM_DESC(symbol, "Probed symbol(s), given by comma separated symbols or a wildcard pattern.");static char nosymbol[MAX_SYMBOL_LEN] = "";module_param_string(nosymbol, nosymbol, sizeof(nosymbol), 0644);MODULE_PARM_DESC(nosymbol, "Not-probed symbols, given by a wildcard pattern.");static bool stackdump = true;module_param(stackdump, bool, 0644);MODULE_PARM_DESC(stackdump, "Enable stackdump.");static bool use_trace = false;module_param(use_trace, bool, 0644);MODULE_PARM_DESC(use_trace, "Use trace_printk instead of printk. This is only for debugging.");static void show_backtrace(void){ unsigned long stacks[BACKTRACE_DEPTH]; unsigned int len; len = stack_trace_save(stacks, BACKTRACE_DEPTH, 2); stack_trace_print(stacks, len, 24);}static void sample_entry_handler(struct fprobe *fp, unsigned long ip, struct pt_regs *regs){ if (use_trace) /* * This is just an example, no kernel code should call * trace_printk() except when actively debugging. */ trace_printk("Enter <%pS> ip = 0x%p\\n", (void *)ip, (void *)ip); else pr_info("Enter <%pS> ip = 0x%p\\n", (void *)ip, (void *)ip); nhit++; if (stackdump) show_backtrace();}static void sample_exit_handler(struct fprobe *fp, unsigned long ip, struct pt_regs *regs){ unsigned long rip = instruction_pointer(regs); if (use_trace) /* * This is just an example, no kernel code should call * trace_printk() except when actively debugging. */ trace_printk("Return from <%pS> ip = 0x%p to rip = 0x%p (%pS)\\n", (void *)ip, (void *)ip, (void *)rip, (void *)rip); else pr_info("Return from <%pS> ip = 0x%p to rip = 0x%p (%pS)\\n", (void *)ip, (void *)ip, (void *)rip, (void *)rip); nhit++; if (stackdump) show_backtrace();}static int __init fprobe_init(void){ char *p, *symbuf = NULL; const char **syms; int ret, count, i; sample_probe.entry_handler = sample_entry_handler; sample_probe.exit_handler = sample_exit_handler; if (strchr(symbol, '*')) { /* filter based fprobe */ ret = register_fprobe(&sample_probe, symbol, nosymbol[0] == '\\0' ? NULL : nosymbol); goto out; } else if (!strchr(symbol, ',')) { symbuf = symbol; ret = register_fprobe_syms(&sample_probe, (const char **)&symbuf, 1); goto out; } /* Comma separated symbols */ symbuf = kstrdup(symbol, GFP_KERNEL); if (!symbuf) return -ENOMEM; p = symbuf; count = 1; while ((p = strchr(++p, ',')) != NULL) count++; pr_info("%d symbols found\\n", count); syms = kcalloc(count, sizeof(char *), GFP_KERNEL); if (!syms) { kfree(symbuf); return -ENOMEM; } p = symbuf; for (i = 0; i < count; i++) syms[i] = strsep(&p, ","); ret = register_fprobe_syms(&sample_probe, syms, count); kfree(syms); kfree(symbuf);out: if (ret < 0) pr_err("register_fprobe failed, returned %d\\n", ret); else pr_info("Planted fprobe at %s\\n", symbol); return ret;}static void __exit fprobe_exit(void){ unregister_fprobe(&sample_probe); pr_info("fprobe at %s unregistered. %ld times hit, %ld times missed\\n", symbol, nhit, sample_probe.nmissed);}module_init(fprobe_init)module_exit(fprobe_exit)MODULE_LICENSE("GPL");除了编写内核模块的方式,能否通过 event trace 机制来使用呢?答案是可以的,需要使用最新版的内核才行,fprobe 支持 event trace 是在 23 年 4 月份刚合并到内核里。
Perf
Perf 是一个 Linux 下的性能分析工具的集合,最初由英特尔公司的 Andi Kleen 开发,于 2008 年首次发布。Perf 设计之初是为了解决英特尔处理器性能分析工具集(Intel Performance Tuning Utilities)在 Linux 上的移植问题而开发的,它可以利用英特尔的硬件性能监视器(Hardware Performance Monitoring)来对 CPU 性能进行采样和分析。随着时间的推移,Perf 逐渐成为了一个通用的性能分析工具,也支持内核追踪。
有了前面提到的 Ftrace,为什么 Perf 也要支持内核跟踪机制呢,主要原因在于 perf 有着特殊的分析方式:采样分析。采样的对象是 event,以基于时间的采样方式为例,他的大致流程是这样的,每隔一段时间,就在所有 CPU 上产生一个中断,查看当前是哪个 pid,哪个函数在执行,并将 pid/func 构建成一个 event 做统计,在采样结束后,我们就能知道 CPU 大部分时间耗在哪个 pid/func 上。
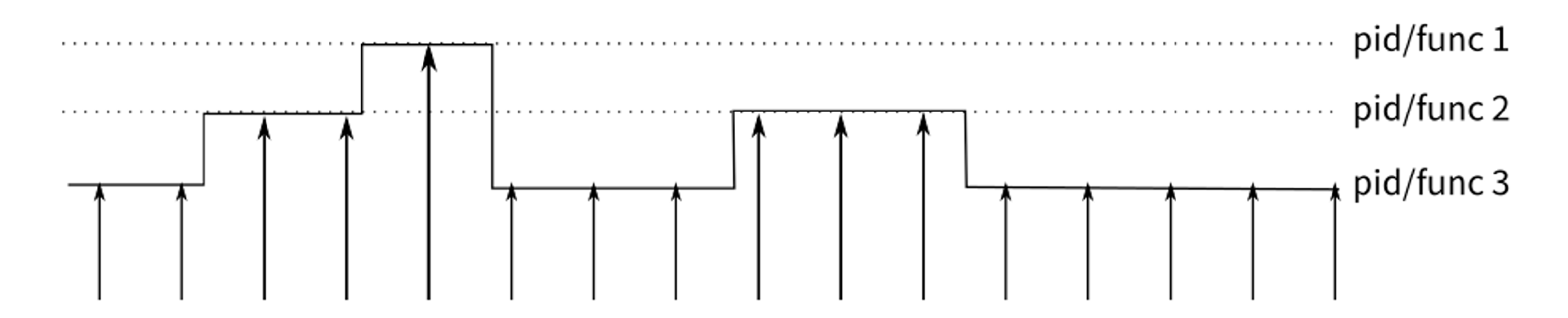
除了上面提到的基于时间的采样,perf 还支持如下采样方式:
计数. 统计某个事件的发生次数。
基于事件的采样. 每当发生的事件数达到特定的阈值时,就会记录一个样本。
基于指令的采样. 处理器跟踪按给定时间间隔出现的指令,并对这些指令生成的事件采样。这样便可以跟踪各个指令,并查看哪些是对性能至关重要的指令。最开始 perf 是仅支持由硬件产生的 Hardware event,这种方式可以推广到各种事件,比如 trace event 事件,当这个事件发生的时候上来冒个头,看看击中了谁,然后算出分布,我们就知道谁会引发特别多的那个事件了。
接下来我们看一下 perf 是如何使用 trace event。
我们可以通过 perf 命令设置一个 probe。
$ sudo perf probe -x /usr/lib/debug/boot/vmlinux-$(uname -r) -k do_sys_open接下来通过 record 子命令 启用 Trace Event,并将 trace 信息保存到 perf.data。
$ sudo perf record -e probe:do_sys_open -aR sleep 1现在我们可以通过 report 子命令,分析 trace 信息。
$ sudo perf report -i perf.dataperf 采样拿到的 event 最终会被放到一个叫做 perf event 的数据结构里面,因为 event 都是在内核态产生的,采样时需要一个数据结构存储采集到的 event,并在采样结束后,将采集到的 event 从内核态发送到用户态来使用,perf event 就是用来做这个事情的,我们通常说的 perf 是指用户态的工具,perf event 是内核态的数据结构。perf 工具通过系统调用 perf_event_open 来创建 perf event。
在内核中,perf_event 结构体,存储该事件的配置和运行状态。创建 perf event 时还会创建 perf event 对应的 ring buffer 用来存储 trac event 数据。 perf 工具通过 perf_event_open 系统调用拿到 perf event 的 fd 后,就可以通过 mmap 内存映射机制 将内核态的 ringbuffer 映射到用户态来访问,最终 perf 将数据写到 perf.data 中以供后续分析。
Perf 使用 Trace Event
Perf 工具是基于 Perf Event 这个数据结构来实现分析能力的,当使用 Perf 添加 Trace Event 时,内核会将追踪数据写到 perf event 对应的 ringbuffer。
还是以上面的 perf 使用案例为例。我们通过 perf probe 子命令添加一个 uprobe event,在 TraceFS 中也可以看到 uprobe_event 的定义,但处于禁用状态。
root@zfane-maxpower:~/traceing# perf probe -x /root/traceing/hello show_test=testAdded new event: probe_hello:show_test (on test in /root/traceing/hello)You can now use it in all perf tools, such as: perf record -e probe_hello:show_test -aR sleep 1root@zfane-maxpower:~/traceing# cat /sys/kernel/tracing/uprobe_eventsp:probe_hello/show_test /root/traceing/hello:0x0000000000001169root@zfane-maxpower:~/traceing# cat /sys/kernel/tracing/events/probe_hello/enable0root@zfane-maxpower:~/traceing#同样是往 uprobe_events 文件中写 trace event definition,为什么手动写就是往 Trace Buffer 里发送数据,用 perf 写就是往 perf event ring buffer 发送数据呢?
在使用 perf record 子命令采集数据时,会通过 perf_event_open 创建 perf event,perf event 在初始化阶段扫描所有的 trace event,检查是否存在与 perf event 关联的 uprobe_event,找到对应的 uprobe event 事件后,就可以启用 urpobe event 了。
uprobe event 启用时才会触发 uprobe 注册操作,但是 perf event 不是通过 TraceFS 的 enable 文件来注册 uprobe event 的,而是直接调用 uprobe event 注册接口,uprobe event 注册接口有两种注册类型:TRACE_REG_PERF_REGISTER、TRACE_REG_REGISTER。TRACE_REG_PERF_REGISTER 表示由 perf event 注册,uprobe event 有一个 flag 属性 用于存储注册类型,TRACE_REG_PERF_REGISTER 对应的 flag 值为 TP_FLAG_PROFILE,其他的则是 TP_FLAG_TRACE。
uprobe event 的 probe handler 固定是 uprobe_dispatcher 函数,uprobe_dispatcher 函数会根据 uprobe event 的 flag 属性来判断往哪个 ring buffer 里写追踪数据,kprobe 也是同理。tracepoint 和它俩不一样,用于声明 tracepoint 的 TRACE_EVENT 宏定义中包含了专门给 perf event 使用的 probe handler,他会直接往 perf event 的 ringbuffer 中写数据。
为什么要有两套 Ring buffer?
Event Tracing 框架下,内核中的追踪数据往 Ring Buffer 中写入,我们可以通过 Tracefs 文件系统来访问 Ring Buffer,为什么 perf 工具不直接使用这个 Ring Buffer 来获取追踪信息?而是在内核中让 Trace Event 的追踪数据直接写入到 Perf Event 的 ring buffer 中。
其实主要原因就是 Ftrace 实现的 Ring Buffer 无法满足 Perf 的需要,Perf 需要在 NMI 场景下也能往 Ring Buffer 中写入数据。
Non-Maskable Interrupt (NMI) 是一种中断信号,它可以打破处理器的正常执行流程,而且无法被忽略或屏蔽。一般来说,NMI 通常用于紧急情况下的故障处理或者硬件监控等场景。NMI 信号通常是由硬件触发的,例如内存错误、总线错误、电源故障等,这些故障可能会导致系统崩溃或者停机。为了避免在故障发生后丢失重要的性能事件数据,Perf 需要将这些数据尽可能快地写入 ring buffer 中,以确保数据不会丢失,这就要求 Ring Buffer 的实现上不可以有写竞争,或可能导致死锁的情况。
很不凑巧的是,Ftrace 的 Ring Buffer 在设计上,使用了自旋锁来防止并发访问,自旋锁会一直占用 CPU 资源直到锁可用,在 NMI 的场景下,如果 Ftrace 正在持有自旋锁,NMI 中断处理程序就无法获取自旋锁,可能会导致系统死锁或者卡死。
另外一点就是 NMI 场景下 RingBuffer 的访问一定要快,处理器必须尽可能快地响应 NMI 中断信号,任何慢速的操作都可能会导致系统的稳定性和性能受到影响。Ftrace Ring Buffer 也没有足够的快,最终 Perf 的开发人员自行实现了一套新的 无锁 Ring Buffer。
通过编写 eBPF 代码来注入 probe
如何使用 eBPF 追踪内核?
由于内核态和用户态的内存空间是隔离的,他们的虚拟内存实现原理不同,想要从内核态向用户态传递数据需要经过地址转换和数据拷贝,比较耗时。而在分析网络数据包时,如果所有的网络数据包都从内核态发到用户态,带来的成本也更大,很多时候我们都是只需一部分数据包就可以了,所以最理想的方式是内核态有一个 Packet Filter 机制,能够过滤我们不需要的数据包,这样就大大减少了内核需要拷贝的数据。
早期 unix 系统也提供了 packet filter 机制,提供了一个基于内存栈的虚拟机,来对内核态的数据包做过滤计算,比如 CMU/Stanford Packet Filter(CSPF)、NIT(Network Interface Tap)等,它们的性能不够好。tcpdump 的作者 Steve McCanne 和 Van Jacobson 在 BSD 操作系统上实现了一个全新架构的 Packet Filter 机制:Berkeley Packet Filter (BPF),抛弃了之前基于内存栈虚拟机的设计,改为基于寄存器的虚拟机,号称性能比之前的 packet filter 机制快很多。同时可以在内核态接到 device interface 传过来的包时就进行 filter,不需要的包直接丢弃,不会多出任何无效 copy。凭借优秀的架构设计和性能表现,BPF 被移植到了很多操作系统。
BPF 的作者发表了一篇论文The BSD Packet Filter: A New Architecture for User-level Packet Capture来详细描述了 BPF 的设计理念与实现思路,感兴趣的可以看一下。
BSD 系统的 BPF 在被移植到 Linux 上后被称为 Linux Socket Filter(LSF),但是大家依然称呼它为 BPF,BPF 在 Linux 内核最初也是提供 Packet filter 的能力,用户态使用 BPF 字节码来定义过滤表达式,然后传递给内核,由内核虚拟机解释执行。
随着时间的推移,Linux 内核开发者为 BPF 添加了更多的能力,比如 Linux 3.0 版本增加 BPF JIT 编译器,在 2014 年 Alexei Starovoitov 为 BPF 带来了一次革命性的更新,将 BPF 扩展为一个通用的虚拟机,也就是 eBPF。eBPF 不仅扩展了寄存器的数量,引入了全新的 BPF 映射存储,还在 4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等。
话说回 Linux 追踪技术。eBPF 的影响也来到了内核追踪领域,2015 年 eBPF 支持 kprobe、2016 年开始支持 tracepoint、perf event,现在我们可以通过在 eBPF 虚拟机运行自定义的 probe handler 获取跟踪数据,并通过 eBPF Map 共享到用户态来对跟踪数据做分析。相比于编写内核代码或是 ftrace、perf 灵活性大大增强。
eBPF 的本质是一个在内核态的虚拟机,可以在虚拟机中执行简单代码,一个完整的 eBPF 程序通常包含用户态和内核态两部分:用户态程序通过 BPF 系统调用,完成 eBPF 程序的加载、事件挂载以及映射创建和更新,而内核态中的 eBPF 程序可以理解为我们的 probe handler,用来获取追踪数据。
eBPF 程序根据其用途划分为多种类型,在追踪方面有如下类型:
BPF_PROG_TYPE_KPROBE
BPF_PROG_TYPE_TRACEPOINT
BPF_PROG_TYPE_PERF_EVENT
BPF_PROG_TYPE_RAW_TRACEPOINT
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITEABLE
BPF_PROG_TYPE_TRACING 从类型名称也能看出来对应类型的 eBPF 程序是如何实现追踪能力的,比如 kprobes 类型的 eBPF 程序,就是通过 kprobes 机制注入 probe handler,probe handler 就是我们在内核态虚拟机中运行的 eBPF 代码。同时 eBPF 程序类型里面没有 UPROBE,主要原因是因为 uprobes 和 kprobes 原理相同,KPROBE 类型的 eBPF 程序也可以使用 uprobes。
那么 eBPF 是如何使用 kprobe、tracepoint 等机制将自己作为 probe handler 注入到内核函数中的?
在前面的介绍里,我们如果使用 kprobe 机制探测内核函数,可以使用 register_kprobe 函数、event trace、perf event 方式来注册 probe handler。**eBPF 采用 perf event 将内核态程序做为 probe handler,**在 eBPF 用户态程序中,可以通过 attach_kprobe 函数将内核态 eBPF 程序通过 kprobes 机制附加到某个内核函数中。attach_kprobe 函数会创建一个 perf event,再将 eBPF 内核态程序附加到 perf event。每个 perf event 的 kprobe probe handler 都是 kprobe_dispatch 函数,他会去 perf event 中获取注册在当前 perf event 的回调函数列表并依次执行,同时将指向 perf ringbuffer 的指针的传递给 eBPF 程序,eBPF 程序可以通过 libbpf 封装好的 PT_REGS_PARAMx 宏定义来获取缓冲区中的数据。
static int kprobe_dispatcher(struct kprobe *kp, struct pt_regs *regs){ struct trace_kprobe *tk = container_of(kp, struct trace_kprobe, rp.kp); int ret = 0; raw_cpu_inc(*tk->nhit); if (trace_probe_test_flag(&tk->tp, TP_FLAG_TRACE)) kprobe_trace_func(tk, regs);#ifdef CONFIG_PERF_EVENTS if (trace_probe_test_flag(&tk->tp, TP_FLAG_PROFILE)) ret = kprobe_perf_func(tk, regs); // 调用perf event 的probe handler#endif return ret;}/* Kprobe profile handler */static intkprobe_perf_func(struct trace_kprobe *tk, struct pt_regs *regs){ struct trace_event_call *call = trace_probe_event_call(&tk->tp); struct kprobe_trace_entry_head *entry; struct hlist_head *head; int size, __size, dsize; int rctx; if (bpf_prog_array_valid(call)) { unsigned long orig_ip = instruction_pointer(regs); int ret; ret = trace_call_bpf(call, regs); // 在这里调用bpf 程序 /* * We need to check and see if we modified the pc of the * pt_regs, and if so return 1 so that we don't do the * single stepping. */ if (orig_ip != instruction_pointer(regs)) return 1; if (!ret) return 0; } head = this_cpu_ptr(call->perf_events); if (hlist_empty(head)) return 0; dsize = __get_data_size(&tk->tp, regs); __size = sizeof(*entry) + tk->tp.size + dsize; size = ALIGN(__size + sizeof(u32), sizeof(u64)); size -= sizeof(u32); entry = perf_trace_buf_alloc(size, NULL, &rctx); if (!entry) return 0; entry->ip = (unsigned long)tk->rp.kp.addr; memset(&entry[1], 0, dsize); store_trace_args(&entry[1], &tk->tp, regs, sizeof(*entry), dsize); perf_trace_buf_submit(entry, size, rctx, call->event.type, 1, regs, head, NULL); return 0;}不论是 kprobes、tracepoint 类型的 eBPF 程序,都是复用 perf event 来实现 probe handler 注入,在某个内核版本,eBPF 的负责人 Alex 提出了一个新的方式 Raw Tracepoint,不需要依赖 perf event,eBPF 程序直接作为 probe handler 注册到 tracepoint 上。
从使用上来说,tracepoint 类型的 eBPF 程序需要定义好 tracepoint 关联的函数的参数的数据结构,这个可以在 TraceFS 中查看,比如 sched_process_exec 这个 tracepoint。
root@zfane-maxpower:~# cat /sys/kernel/tracing/events/sched/sched_process_exec/formatname: sched_process_execID: 311format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:__data_loc char[] filename; offset:8; size:4; signed:1; field:pid_t pid; offset:12; size:4; signed:1; field:pid_t old_pid; offset:16; size:4; signed:1;print fmt: "filename=%s pid=%d old_pid=%d", __get_str(filename), REC->pid, REC->old_pidtracepoint 定义好数据结构,配合 bpf 辅助函数提取 tracepoint 传递过来的数据。
struct sched_process_exec_args{ // 声明数据结构 unsigned short common_type; unsigned char common_flags; unsigned char common_preempt_count; int common_pid; int __data_loc; pid_t pid; pid_t old_pid;};SEC("tracepoint/sched/sched_process_exec")int tracepoint_demo(struct sched_process_exec_args *ctx) { struct event *e; e = bpf_ringbuf_reserve(&events, sizeof(*e), 0); if (!e) { return 0; } unsigned short filename_offset=ctx->__data_loc & 0xFFFF; char *filename=(char *)ctx +filename_offset; bpf_core_read(&e->filename,sizeof(e->filename),filename); // 通过辅助函数读取值 e->pid=bpf_get_current_pid_tgid() >>32; bpf_get_current_comm(&e->command,sizeof(e->command)); bpf_ringbuf_submit(e, 0); return 0;}char _license[] SEC("license") = "GPL";eBPF 程序接受到的数据是由 perf probe 传递过来的。tracepoint 关联的函数的参数会写到 perf ringbuffer 缓冲区,perf probe 会将指向缓冲区的指针传递给 eBPF 程序。tracepoint 关联的函数参数在缓冲区的布局如下:
+---------+| 8 bytes | hidden 'struct pt_regs *' (inaccessible to bpf program)+---------+| N bytes | static tracepoint fields defined in tracepoint/format (bpf readonly)+---------+| dynamic | __dynamic_array bytes of tracepoint (inaccessible to bpf yet)+---------+perf probe 传递了指向缓冲区的指针,eBPF 也无法直接使用指针访问内存上的数据,各个内核函数的参数不一样,在不知道数据的类型、长度,无法保证安全访问,所以需要借助 bpf 辅助函数读取数据。
再说回 raw tracepoint 类型的 eBPF 程序,从使用上来说,它的函数参数结构体变成了 struct bpf_raw_tracepoint_args,不在需要我们定义 tracepoint 关联的结构体了。SEC 声明也改成 raw_traceoint,其他的在使用上和 tracepoint 类型的 eBPF 程序保持一致。
// include/trace/events/sched.hSEC("raw_tracepoint/sched_process_exec")int raw_tracepoint_demo(struct bpf_raw_tracepoint_args *ctx) { struct event *e; e=bpf_ringbuf_reserve(&events,sizeof(*e),0); if (!e) { return 0; } bpf_core_read(&e->filename,sizeof(e->filename),ctx->args[0]); e->pid=bpf_get_current_pid_tgid() >>32; bpf_get_current_comm(&e->command,sizeof(e->command)); bpf_ringbuf_submit(e, 0); return 0;}raw_tracepoint 类型的 eBPF 程序相比于普通的 tracepoint 类型的 eBPF 程序核心的改变是,直接附加在 tracepoint 上,可以提供参数的“原始访问“。 直接附加在 tracepoint 的意思是,tracepoint 对应的函数执行时,内核将直接调用 bpf 程序执行,为此内核提供了 tracepoint 注册 bpf 程序的注册接口 bpf_raw_tracepoint_open。而参数的原始访问不好描述,但可以对比 raw_tracepoint 和 tracepoint 参数传递方式来理解。
对于 tracepoint 类型 eBPF 程序,是 perf event 在 ringbuffer 中分配一块内存空间,然后内核会将函数的参数写到这个内存空间中,perf probe 再把这个内存空间的地址传递给 eBPF 程序,而原始访问则是,直接把函数参数全部转换为 u64 类型,得到一个数组,并把数组传递给 eBPF 程序。更短的调用链和跳过参数处理,相比于 tracepoint ,raw tracepoint 有更好的性能。
samples/bpf/test_overhead performance on 1 cpu:tracepoint base kprobe+bpf tracepoint+bpf raw_tracepoint+bpftask_rename 1.1M 769K 947K 1.0Murandom_read 789K 697K 750K 755KBTF-enabled raw_tracepoint
在内核 4.18 版本,引入了 BTF (BPF Type Format),它用来描述 BPF prog 和 map 相关调试信息的元数据格式,后面 BTF 又进一步拓展成可描述 function info 和 line info。BTF 为 Struct 和 Union 类型提供了对应成员的 offset 信息,并结合 Clang 的扩展(主要是 [__builtin_preserve_access_index]()和 BPF 加载器,BPF Prog 就可以准确访问某个 Struct 或者 Union 类型的成员,而不用担心重定位问题。
在内核 5.5 版本专门定义了一个 BPF_PROG_TYPE_TRACING 类型,支持访问 BTF 信息,率先支持的就是 raw_tracepoint,不再需要辅助函数访问内存。
SEC("tp_btf/sched_process_exec")int BPF_PROG(sched_process_exec,struct task_struct *p, pid_t old_pid, struct linux_binprm *bprm) { struct event *e; e =bpf_ringbuf_reserve(&events,sizeof (*e),0); if (!e){ return 0; } bpf_printk("filename : %s",bprm->filename); // 直接访问 bpf_core_read(&e->filename,sizeof(e->filename),bprm->filename); e->pid=bpf_get_current_pid_tgid() >>32; bpf_get_current_comm(&e->command,sizeof(e->command)); bpf_ringbuf_submit(e, 0); return 0;}内核函数与 BPF 程序的桥梁:BPF Trampoline
BPF_PROG_TYPE_TRACING 类型的 eBPF 程序通过不同的 Attach 类型,可以实现不同的能力,除了支持 raw_tracepoint attach 类型外,还支持 FENTRY/FEXIT。FENTRY、FEXIT 已经是老朋友了,在前面介绍 Ftrace 时就有提到过,这俩是用于函数追踪的,FENTRY 类似于 kprobe、FEXIT 类似于 kretprobe(除了函数返回值,FEXIT 还可以获取到函数的参数)。
它们依赖 gcc 的-pg -mentry 编译参数在每个函数入口添加__fentry__ 调用,在不开启 fentry 时,__fentry__调用指令会被替换为 NOP 指令,避免影响性能,开启时__fentry__指令会被替换为 BPF Trampoline 函数调用指令,在 BPF Trampoline 函数中会调用 eBPF 程序执行。
BPF Trampoline 是一个内核函数和 bpf 程序之间的一个桥梁,它允许内核函数调用 BPF 程序,当我们通过 Fentry 机制 attach 到某个内核函数时,内核会为这个 eBPF 程序生成一个 BPF Trampoline 函数,被追踪的内核函数的参数会被转换成 u64 数组,存储到 Trampoline 函数栈中,指向这个栈的指针又存储到 eBPF 程序可以访问的 R1 寄存器中,再根据 BTF 信息,BPF 程序可以直接访问内存了,同样也不需要辅助函数来读取数据。
Fentry、FEXIT 这种基于 Trampoline 方式的 probe handler 注入方式,没有额外的 kprobe、perf event 数据结构引入,其开销成本非常小,如果内核支持 FENTRY 机制,函数追踪场景使用 FENTRY 代替 kprobes 有更好的性能。
eBPF 如何从内核态向用户态传递数据?
BPF Map 是 eBPF 在用户态和内核态共享数据的方式,在上面的示例中我特意使用了 BPF ringbuffer Map 从内核态向用户态传递数据,它需要内核 5.8 及其以上的版本才可以使用。在此之前,perf event Map 是事实上的标准,通过 perf ring buffer 可以高效的在内核态与用户态之间传递数据。
但在实践中发现,perf ring buffer 存在两个缺点:内存浪费和数据乱序。
perf ring buffer 需要在每一个 cpu 上创建,每一个 cpu 都有可能执行 BPF 代码,产生的数据会存储到当前 CPU 的 perf ring buffer 上,如果某个时刻执行的 BPF 程序可能会产生大量的数据,perf ring buffer 空间满了的情况下,就覆盖掉老数据,造成一部分数据丢失,但是大部分情况下不会产生很多的数据,针对这种情况,要么容忍数据丢失,要么就每个 cpu 创建大容量的 perf ringbuffer,防止突发的数据暴增,但大部分时间空着。
同时每个 cpu 具有独立的 perf ring buffer,可能会导致连续的追踪数据分布在不同的 perf ringbuffer 上,比如追踪进程的生命周期 fork、exec、exit,eBPF 程序在 3 个不同的 cpu 上执行,用户态是通过轮询 cpu 上 perf ringbuffer 来接收数据的,可能就会出现 exit 事件比 exec 事件先接收。
perf ringbuffer 这两个问题并非无解,比如可以在构建一个跨 cpu 的全局计数器,每一次往 perf ringbuffer 写入数据时带上序列号。在用户态聚合所有的 perf ringbuffer 上的数据时,创建一个队列,并根据序列号按序入队,这样就可以保证事件的顺序,这种方案总归是增加了用户态程序的复杂度和带来额外的成本。
为此社区内提出了一个新的 ring buffer 设计,BPF ringbuffer,它是一个跨 CPU 共享、MPSC 模型的 ringbuffer,可以直接通过 mmap 机制映射到用户态访问 ringbuffer。对于低效率内存使用的问题,由于是跨 cpu 共享的 ring buffer,所以这个问题就不存在了;对于数据乱序的问题,每个事件被写入 bpf ringbuffer 时都会被分配一个唯一的 sequence number,并且 sequence number 会递增。这样,在读取 buffer 数据时,可以根据 sequence number 来判断哪些事件先发生,哪些事件后发生,从而保证读取的数据是有序的。
应该选择哪个内核追踪技术?
Brendan Gregg 博客中有一片文章讨论了选择哪个 trace 追踪工具(发布于 2015 年),我认为直到现在依然有帮助(Choosing a Linux Tracer (2015)),于我个人而言,排查问题和检测性能时,我会优先考虑 perf 系列的工具,它可以帮助我获取追踪数据,并快速的得到一个分析结果。如果构建一个常驻的内核追踪程序,eBPF 是我的好帮手,它具备可编程性,可以让我在多个节点上按照期望的方式拿到追踪数据并汇总计算。
总结
(kprobes、uprobes)、tracepoint、fprobe(fentry/fexit) 是注入 probe handler 调用的机制。kprobes、uprobes 通过动态指令替换实现在指令执行时调用 probe handler。
tracepoint 是代码里静态声明了 probe handler 的调用,提供 probe handler 的注册接口,内核开发者定义发给 probe handler 的追踪数据,执行 tracepoint 时将追踪数据传递给 probe handler,可以动态开启和关闭,tracepoint 由内核开发者维护,稳定性很好。
fprobe(fentry/fexit) 是通过在内核编译期间对函数添加第三方调用,可以动态开启和关闭,达到了类似于 tracepoint 的效果,除了 frpobe ,eBPF 同样也可以实现 fentry/fexit 的机制,他们都是通过 Trampoline 来跳转到 probe handler 执行。
probe handler 在内核态执行,抓取到的追踪数据往往需要传递到用户态做分析使用,perf_event、trace_event_ring_buffer、eBPF Map 是从内核态向用户态传递数据的方式。
perf_event 存储的追踪数据可以通过 MMAP 映射到用户态来访问。trace_event_ring_buffer 是通过虚拟文件系统 TraceFS 的方式暴露追踪数据。eBPF Map 有多种实现方式,有基于 perf event 的、有基于系统调用的,有基于 BPF ringbuffer 的。
作者介绍
张帆,政采云有限公司高级运维开发工程师,关注云原生相关领域,目前聚焦在 BPF 技术及实践。




