
本文受访嘉宾:蒋志伟,爱好技术的架构师,先后就职于阿里、Qunar、美团,前 pmcaff CTO,目前 OpenTelemetry 中国社区发起人,https://github.com/open-telemetry/docs-cn 主要维护者。
有心人可能已经发现,可观测问题正在悄然成为 IT 行业的热门话题。尤其是从 2021 下半年到今日的一年间,对可观测问题的讨论,不断见诸技术圈内,大有愈演愈烈之势。
从技术的角度看,这是因为微服务架构逐渐普及,导致可观测问题变得十分复杂。
差不多在五年前,分布式系统也已成熟,微服务架构尚未普及,可观测问题就已经在桎梏技术团队的工作效率。一个 To C 的软件使用问题可能由客服发起,整条支撑链路的所有技术部门,都要逐一排查接口和日志,流程非常原始,也非常低效。如果业务到达一个量级,支撑系统变多,两名研发查上两三个星期也是常事。
微服务架构普及后,问题变得更加严峻。一个服务被拆分成数个黑盒的、虚拟的微服务,故障排除彻底成为一种折磨。
从行业的角度看,则是因为 Datadog 在美上市,两年间市值翻了三倍多(截止到 5 月 30 日,市值为308亿美金),让从业者看到:可观测不但是个未被妥善解决的疑难老病,也有十分广大的市场空间。巨大的需求背后,必然是急速扩张中的市场。
这一切都使可观测成为 2022 年技术人必须关注的话题。
当我们谈论可观测,究竟是在谈论什么?
2016 年,一本名叫《Site Reliability Engineering - How Google Runs Production Systems》出版,谷歌的工程师在书中描绘了故障生命周期的五个阶段:故障预防、故障发现、故障定位、故障恢复、故障改进。而对 IT 系统故障的发现和定位,正是可观测问题的另一种诠释,某种程度上也最接近可观测问题本质的定义。
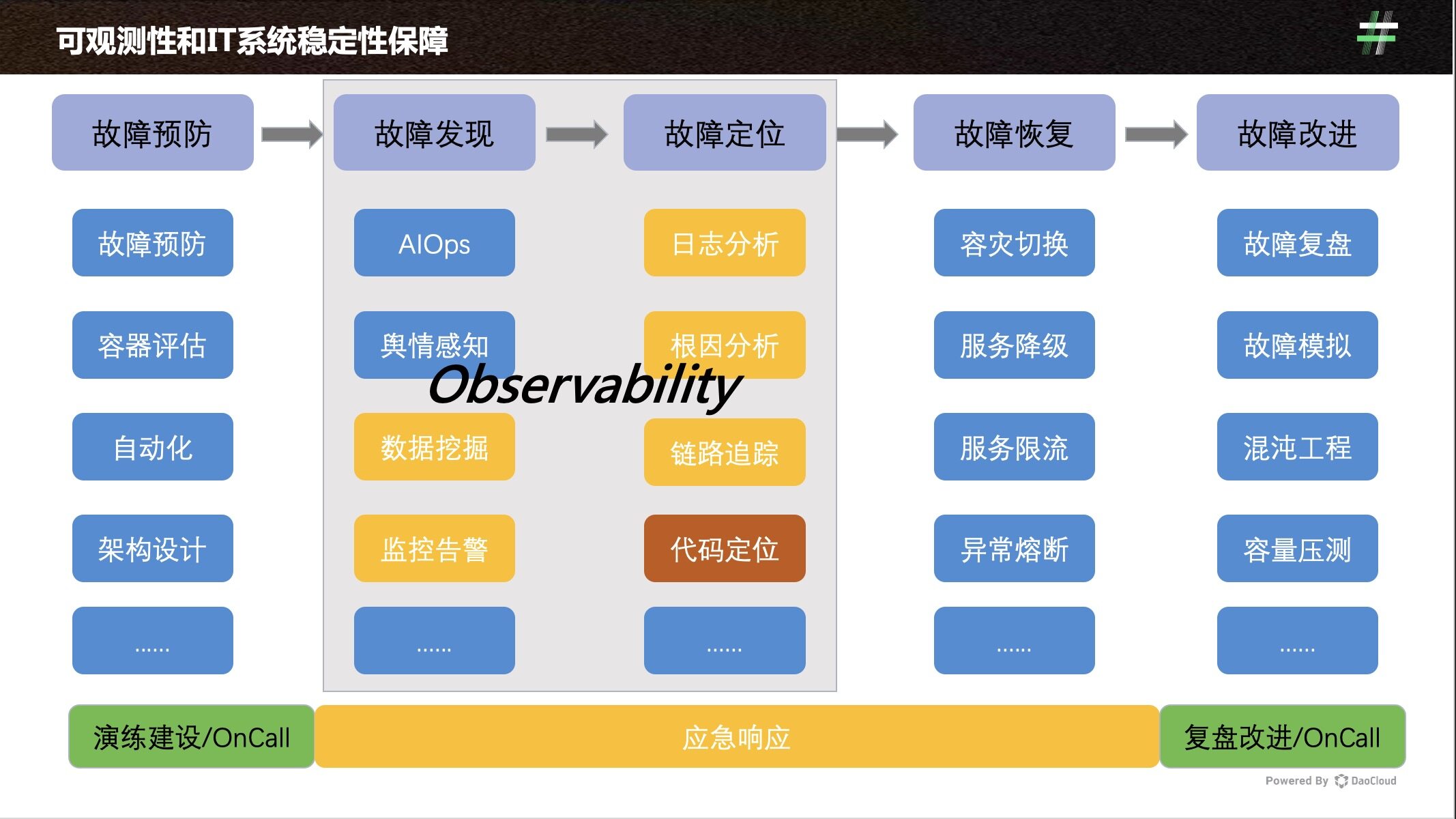
在此基础上,我们可以将可观测问题大致分为四类:
分布式链路追踪技术:可观测的基石
APM:Application Performance Monitoring ,应用性能监控
NPM:Network Performance Monitoring ,网络性能监控
RUM:Real User Monitoring,真实用户监控
其中,分布式链路追踪技术的核心思想是:在用户一次请求服务的调⽤过程中,无论请求被分发到多少个子系统,子系统又调用了多少其他子系统,我们都要把系统信息和系统间调用关系都追踪记录下来,最终把数据集中起来做可视化展示。(引用自《怎么理解分布式链路追踪技术》,作者:蒋志伟,该文章会在专题的后续更新中放出)
APM 主要是为了对企业核心业务系统进行性能的故障定位和处理,帮助优化性能,提高业务系统的可靠性和用户体验,更多偏向产品维度,其底层虽依赖分布式链路追踪技术,但不能直接用来解决分布式链路追踪的问题 —— 这是此前很多工程师容易混淆的问题。(《在生产环境如何选择靠谱的 APM 系统》,作者:蒋志伟,该文章会在专题的后续更新中放出)
NPM ,顾名思义,其关键在于实现全网流量的可视化,对数据包、网络接口、流数据进行监控和分析。
RUM 的关键在于端到端反应用户的真实体验,捕捉用户和页面的每一个交互并分析其性能,是种高度实用主义的监控设计。
同时,可观测存在三个主要的数据源:
指标(metrics)
链路(trace)
日志(log)
其中指标告诉我们是否有故障,链路告诉我们故障在哪里,日志则告诉我们故障的原因。
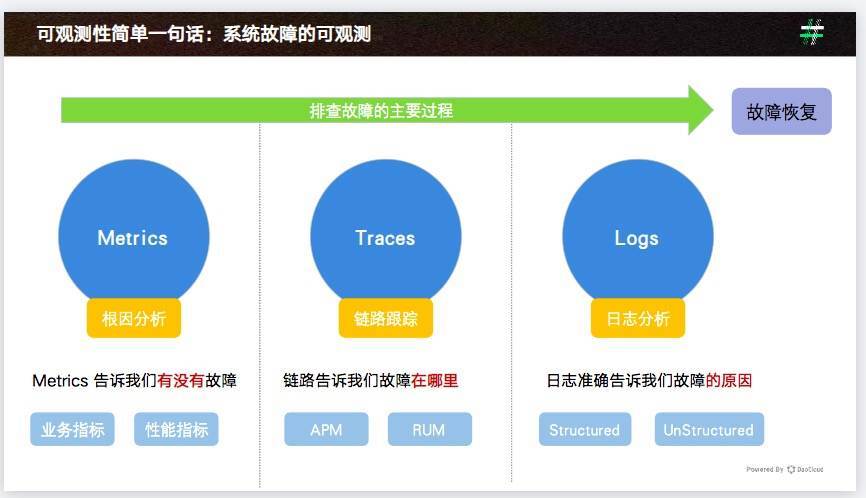
这三类可观测问题加上三种监控类型,共同构成了可观测问题的主要内容。
不同企业如何建设可观测体系
不过对于一个企业来说,想构建可观测体系,并不意味着要直接复刻上述所有目标维度。不同的企业类型,以及不同的行业背景,都有不同的侧重点和建设方式。我们可以简单将建设方式分为三种情况:
自研;
采用开源作品;
购买 SaaS 服务;
再来看看,如何应用其中 1 - 3 条方式完成企业的可观测体系建设。
首先,从团队规模来说,可分为几种不同的情况。
第一类:企业是互联网大厂,整体业务并发量非常大,稳定性要求很高。那么开源产品基本很难满足需求,只能依赖自研。因为达到一定规模的并发量与可靠性要求,在业内永远是少数派,开源产品很难遵循这样的演进路线。
第二类:中型企业,位于行业腰部,没有特别高的性能要求,同时有一定的自研能力。该类企业在可观测体系的建设上可以有三种思路:
如果目前技术栈内全部是主流框架、组件和编程语言,可以尝试直接采用开源产品,或是基于开源产品做定制化改造。当然,要注意反哺社区,有出有进;
如果包含一部分非主流框架或编程语言,比如 .net ,可以尝试单独购买第三方 SaaS 服务;
如果包含一部分非主流框架或编程语言,且对自研能力非常有信心,可以围绕这部分进行自研;
第三类:创业公司。创业公司的业务、方向都可能出现较大变化,数据体系也不一定非常健全,所以创业公司可以暂缓建设可观测体系。
第四类:非 IT 技术驱动的传统企业,如律师事务所、报社等,只要能保证服务高可用(相对于当下业务的忍耐度),可以不购买或自研建设可观测体系。可观测体系是为了解决 IT 故障,不是为了显示技术团队很牛。如果需要的话,可以直接购买第三方服务。
企业在不同生命周期的方案不同,因为所处行业不同,对可观测体系的需求也会有较大差异。
蒋志伟为 InfoQ 记者举了个例子:“比如说,电商行业可能对链路和日志监控的联动要求很高,但物联网系统可能很多不需要链路监控。银行系统业务迭代不频繁,看重故障系统化改进, 更关心压测系统。”
因行业背景而产生巨大差异的案例还有很多,像 IoT 因为行业特性,也基本没有链路追踪诉求。凡此种种,难以尽述,更为行之有效的办法,是找一找该行业内的标杆企业,观察一下他们可观测体系是如何建设的。
国内外可观测行业与技术发展现状
行业和技术的发展情况,则是我们应当关注的,最后、最重要的一个维度。
首先是行业层面。目前国内的行业发展和创新,仍然有些“硅谷追随者”的感觉,Datadog 的市值翻倍,给了大家信心,这让国内可观测产品的孵化速度正在加快。
在美国,Datadog 是该领域绝对的“当红炸子鸡”。蒋志伟对 InfoQ 记者说:
“Datadog 的获客成本非常低,销售占公司人员比例很少,大部分都是研发——他们的市场扩展,依赖的就是口碑和社区。Datadog 的 Slack 群聊中,居然有五万多名商业客户,这些客户每天都在抛出自己的需求和问题。而 Datadog 也以惊人的速度更新版本,满足这些客户的诉求。双向打磨下来,这些客户其实已经无法离开 Datadog —— 只有 Datadog 才能满足他们的需求。这是开源软件相对难以实现的商业闭环。”
阿尔法公社一篇 2020 年的采访显示:Datadog 上市后的年利润增长率达到了 82%,Rule of 40(SaaS 行业关键指标:增长率+利润率不低于 40%)高达 93%,净收入留存率 > 145%,三者皆是行业领先水平,是 SaaS 行业绝对的“头部玩家”。
事实上,Datadog 的成功只是 APM 行业在美高速发展的一个象征。如 DataTrace、Splunk 等企业不但通过高客单价保证了营收,也合力使 APM SaaS 产品覆盖了超过 50% 的美国市场。
相比较之下,国内的可观测产品还处于发展期,但也有 Skywalking 这样的开源作品,以及阿里云 ARMS、Prometheus 这样的商业产品,提供了比较好的使用体验。
但 ARMS 也暴露出一个可观测的关键技术障碍 —— 数据孤岛问题。如果要在企业内建设完善的可观测体系,很可能会形成链路监控、日志监控、指标监控等多套不同的监控系统,要打通是相当困难的。不同的业务线间,日志规则不互通,要完全互通也很困难。系统一旦过多,相关维护以及故障排除的时间成本就会大幅增加。
针对数据孤岛问题,目前行业内的一大趋势是:拥抱 OpenTelemetry。OpenTelemetry 是由一组 API 和库构成的标准,由 OpenTracing 和 OpenCensus 项目的合并而来,服务于可观测技术的底层数据采集,最早由微软和 Google 发起,当下已经成为美国可观测行业研发的事实标准 —— 微软、Google、Datadog、Splunk 等企业全部采用 OpenTelemetry 完成底层的数据采集,而 OpenTelemetry 的主要贡献者也来自这些公司。
OpenTelemetry 的特点在于制定统一的协议数据格式,并提供底层数据采集器。蒋志伟提到,OpenTelemetry 的数据采集器,目标是兼容所有的语言、所有的系统。
而与 OpenTelemetry 打配合的各大厂,要负责提供兼容该采集器的插件系统,是数据能够同步到这些企业的平台。
这使得 OpenTelemetry 既不会因动了“数据的蛋糕”,引起生态抵制,也极大保存了精力,得以专注于数据采集器,努力去兼容“所有的语言、所有的系统”。可以说,OpenTelemetry 试图从开源数据采集器的层面,解决可观测数据孤岛的问题,并且取得了开创性的成果和进展,值得特别关注。
关于 OpenTelemetry 发展的下一阶段,蒋志伟认为,AIOps 可能是一个重点。可观测的最终目的在于解决故障,如果能通过 AI 的手段,更高效的、自动化的排除故障,无疑又会开辟一个非常有想象力的技术应用领域。
参考链接:
https://finance.sina.com.cn/tech/2020-10-24/doc-iiznctkc7346044.shtml




