
北京时间 12 月 15 日,英伟达专为中国开发者打造的 GTC China 2020 正式在线上举办。但是本次发布会的主讲人不再是黄仁勋,而是著名计算机科学家、英伟达首席科学家 Bill Dally。
Bill Dally 的演讲主要分为以下几个部分:
硬件产品:基于 Ampere 的高性能计算设备
软件产品:
计算图形领域
自然语言处理领域
医疗健康领域
自动驾驶领域
硬件:基于 Ampere 的高性能计算设备

计算机科学家、英伟达首席科学家 Bill Dally
说是今天 keynote 的“重头戏”,倒不如说是上半年 GTC 发布会的一些补充说明。
早在今年 5 月,黄仁勋就在 GTC 大会上宣布推出 NVIDIA A100,全新的数据中心 GPU,也就是 Ampere,它包含 540 亿晶体管,拥有比原来强大 20 倍的 AI 算力。

A100 的技术创新体现在以下 5 点:
1、台积电 7nm 工艺,将内存和芯片放在相同的基材上以便可以互操作,并且已经连接到 HBM2 内存,该内存现在提供 1.5TB 帧缓冲区带宽,这是历史上第一个每秒超过 1TB 的带宽的处理器。
2、 第三代 Tensor Core AI 核心,支持 TF32 运算,无需任何代码改变就可以让性能提升 20 倍,还支持 FP64 双精度运算,与 HPC 应用相比带来了 2.5 倍的性能提升。
3、 MIG 新架构:这是一项创新技术,可以将一个 GPU 划分为七个独立的 GPU,针对不同的目标提供运算,最大化提高计算效率。
4、 NVLink 3.0:新一代 GPU 总线的性能翻倍,可以在服务器应用中提供更有效的性能扩展。
5、 结构稀疏性:这项新技术利用了 AI 运算中固有的稀疏性,从而实现了性能翻倍(这是 Bill Dally 认为最令人兴奋的一点)。
这 5 大技术创新使得 A100 加速卡不仅可用于 AI 推理、AI 训练,还可以用于科学仿真、AI 对话、基因组与高性能数据分析、地震建模及财务计算等。
此外,在这一代的核心中,英伟达增加了对新数据类型的支持,TensorFLOAT 32 解决了曾经在 BFLOAT16 和 FP16 之间进行数据类型选择的问题,能够使计算性能得到巨大提升。
有关神经网络的稀疏性,可参考 Bill Dally 的论文:https://arxiv.org/abs/1510.00149
自 2012 年的 Kepler,到 2020 年的 Ampere,8 年的时间里,英伟达将单芯片处理性能提高了 317 倍,下图这张曲线也被业内称之为“黄氏定律”or“黄仁勋定律”,即:GPU 将推动 AI 性能实现逐年翻倍。
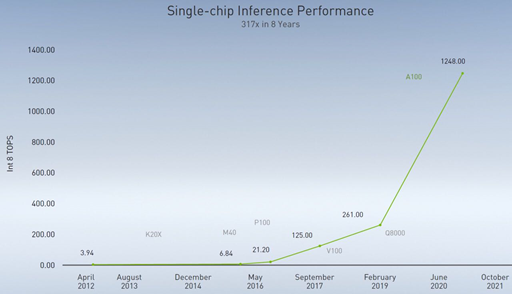
但实际上,随着英伟达对 Tensor Core 的改进,AI 性能每年的提升已不止一倍。
值得一提的是,Bill Dally 认为制程工艺对于提升性能的帮助并不算大,从 28nm 的 Kepler 到 7nm 的 Ampere,总体上发挥的左右可能不到两倍,更大的优势来自于对架构的改进。“‘摩尔定律’之后我们幸好还有‘黄氏定律’来提升计算性能。”Bill Dally 这样说。
如果想要比较在深度学习方面的表现,MLPerf 的基准测试是一项比较通用的方法,英伟达也在这项测试中与其他公司的产品进行了比较。
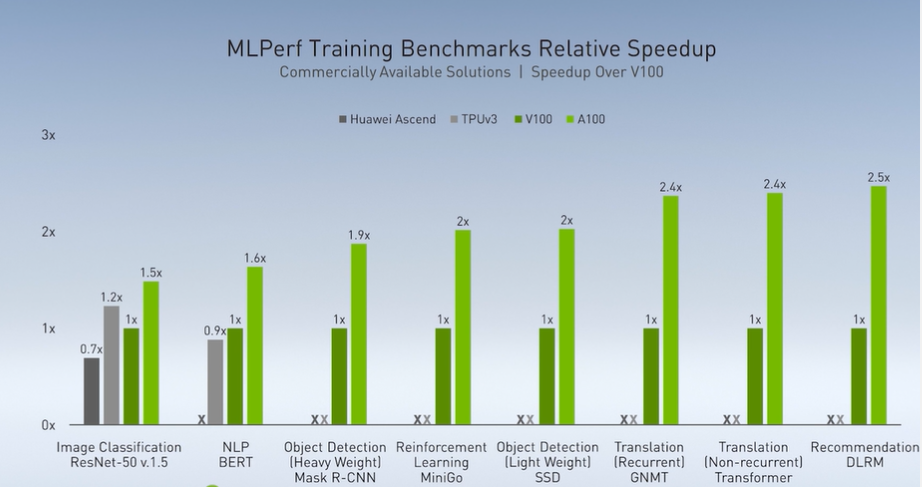
Bill Dally 介绍到:在最新的基准测试中,英伟达基本横扫了所有类别,尤其在自然语言处理模型以及推荐系统方面,英伟达的产品相较上一代速度提升了 2.5 倍。
他还专门提到,目前的两个竞争对手是谷歌的 TPU v3 以及华为的产品。
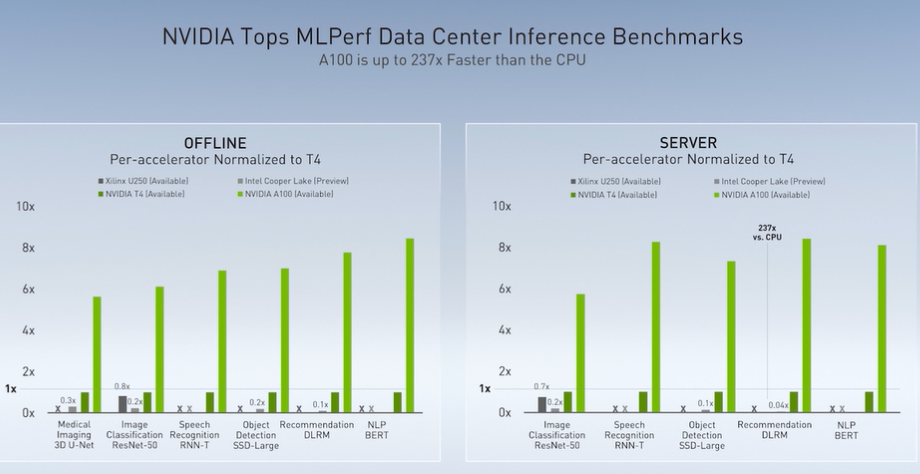
在推理测试中,与之前英伟达的 AI 推理解决方案 Turing T4 相比,A100 的速度提高了 6-8 倍。Bill 表示,在这一领域的竞争对手只有英特尔与赛灵思,但是他们也都被 Ampere 击败了。
此外,Bill 说,所有声称在 AI 训练以及推理方面有更好解决方案的初创公司,一家都没有上榜。
同时,为了达成更好的推理效果,英伟达推出了 Triton 推理服务器,这是一款开源软件,支持多个不同的推理后端,让数据中心的推理部署更加便捷。
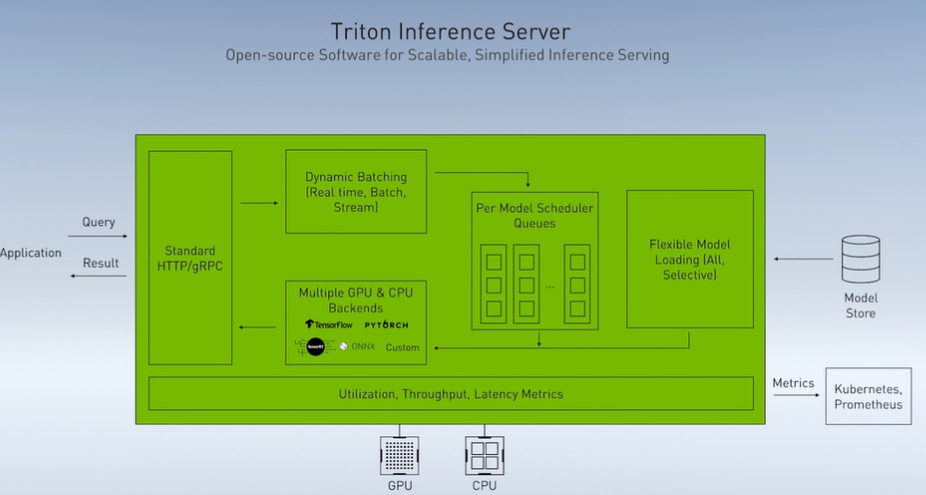
软件产品
计算图形
GPU 的计算性能除了 AI,更多地还是被用在了图像图形领域。

如今特效电影大片越来越大,而这背后离不开 GPU 的计算能力。Bill 介绍到,离线的计算机图形通常是通过一种基于物理性质的路径追踪渲染技术完成的,对每个像素投射数万条光线,耗费数个小时才能窜然生成一帧。
而英伟达则找到了一种不用如此复杂也可以达成同样效果的办法:每帧 60 秒的速率渲染,也可以接近几乎真实的效果。
首先是称之为 RTXDI 的技术,即直接照明。通过这项技术,每个光源都会将其光线投射在相邻的表面上,以达成投射逼真的阴影效果,如下面两张图所示:


Bill 表示,可以使用这项技术支持多达数百万个光线,通过一种名为容器重要性采样的技术,又称:ReSTIR。
另外在图像领域的一个问题是:间接照明。因此英伟达也开发出了一项技术来解决此类问题,名为:RTXGI。

RTXGI 使用光探测器,将管线从一个表面投射到另一个表面,这些光点被放入包含各个点的图像中,以及算在该点看到的间接照明,光线通过数次反射以确保不漏掉任何一个点,从而渲染出更加逼真的图像效果。
此外还有一项称之为 DLSS 的技术也是英伟达为图像渲染开发的,一个 1440P 分辨率的图像,经过 DLSS 的渲染,可以达到 4K 级别的分辨率。
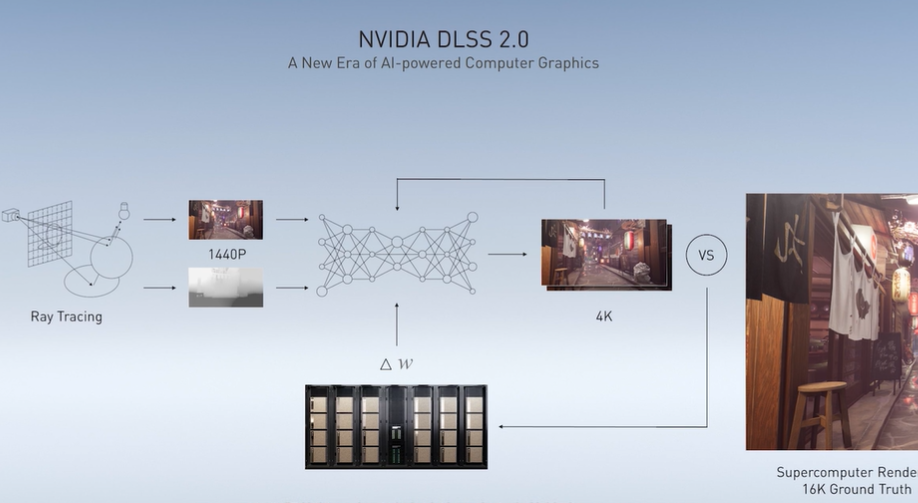
达成 4K 之后的图像会与更高品质的图像进行对比,误差被计入其中一个 DGX superPODS 训练神经网络的 loss 函数,经过对数据集的特定迭代,可以训练网络权重从而以更加精准的方式生成更高像素的图像。
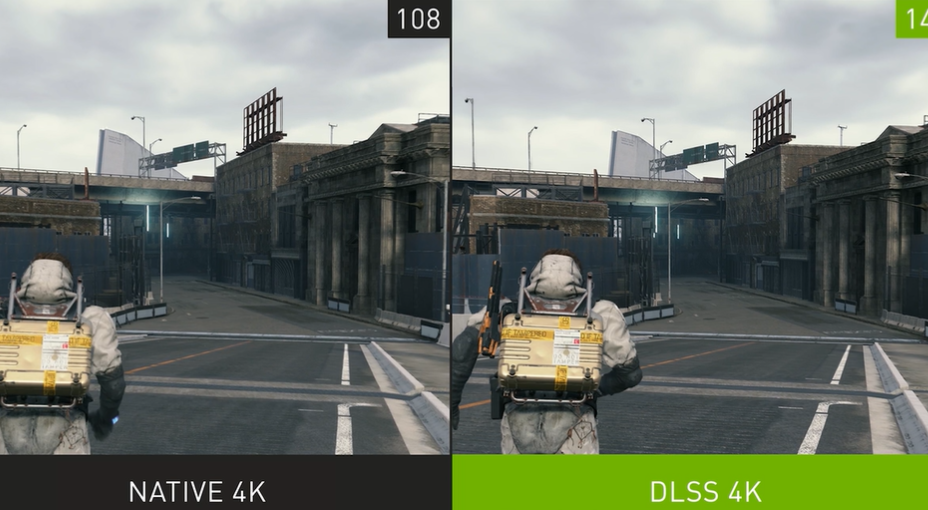
左:正常 4K;右:经过 DLSS 渲染升级到 4K 画质的图像
未来,英伟达希望能够达成实时的图像渲染效果。而更长远的目标,则是达成 AI 自动生成图像。不仅是生成头像、照片,而是生成任何可以与真实照片媲美的图像,并能够借助 AI 构建整个场景。
NLP 领域
在 NLP 领域,英伟达的 Jarvis 是多模态对话式 AI 服务,也是今年 5 月发布的产品,基本上包括了对话的全部功能。可以跟它对话,神经网络会提取说话者的音频,并从这些音频中转换出文本;之后,就可以将文本输入到 NLP 模型中进行查询、翻译、问答等等。
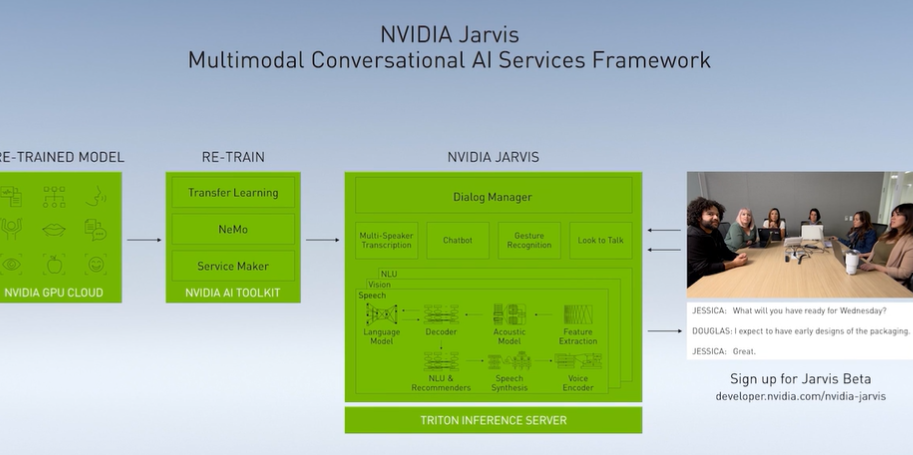
在获取答案之后,文本会再次由 NLP 模型生成出来,进而再次转换为语音并生成音频波形,播放出来。
Bill 介绍说,更有意思的是,通过 Jarvis,NLP 与 AI 可以进一步结合,只需要语音输入,GauGAN 就能进行绘画,比如你希望哪里有山、水等等。
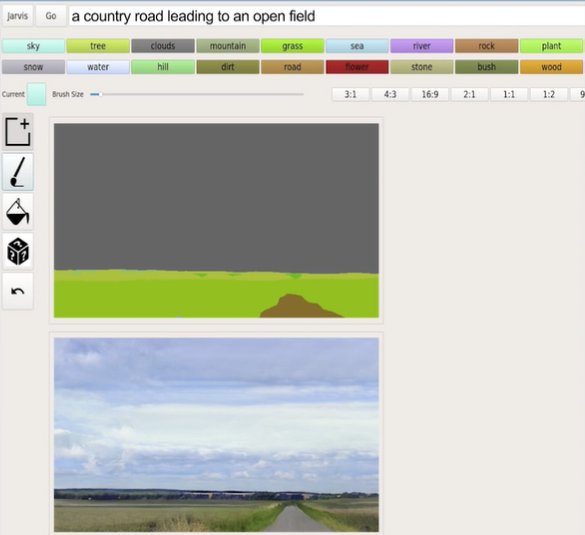
通过 Jarvis 还可以使用语言模型构建系统,在大量文本上训练语言模型,再给出提示,让其编写句子;而在推荐系统领域,通过更高的算力支持,英伟达可以让模型达成更加精准的推荐。
医疗健康领域
英伟达曾经发布了一款通过 GPU 加速医疗健康发展应用的产品:Clara。通过 Parabricks 从基因组学入手,获得一个基因组序列,组装、对比序列,并检测编译,根据基因组,实现对个人的个性化医疗健康服务。
比如今年造成严重疫情的新冠肺炎,通过将病毒影像上传至 GPU,构建病毒结构,并根据结构进行对接实验,从数据库中提取化合物与之分析,进而找到对新冠最有可能发生作用的化合物,再进行进一步的筛选;之后则可以根据化合物与特定位点的结合,适当地进行物理测试。
Clara 还可以分析 X 光检查、超声检查等等,帮助医生发现一些重要的情报。
自动驾驶领域
自动驾驶是一个极其复杂的问题,涉及到传感器、摄像头、雷达、激光雷达、实时计算等多种问题。汽车不仅需要高速行驶,还要预测其他汽车、行人以及周围其他交通参与者的行为。

上面这张图中,从左至右涵盖了整个自动驾驶从数据采集到模型训练,再到模拟场景,最后上路的各个步骤,英伟达也在每一个环节有对应的产品或功能,直到最右边人工远程接管,也有对应的技术来执行操作。
Bill Dally 的演讲还包括了不少深度学习发展历程、数据处理等方面的内容,感兴趣的读者可以点击此处的链接回顾 keynote 全程。




