
导读: 机器学习算法的不断进步,搜索引擎巧妙的人机交互设计,分布式系统的革新让搜索引擎在不知不觉中成为人们生活中不可或缺的一部分。同时,随着人们新需求的不断涌现,搜索引擎也没有停下变革的步伐。本文主要分享智能搜索在电商的应用探索,介绍如何构建一个好的电商搜索引擎。主要内容包括:
为什么要做搜索
整体的技术方案
实际应用效果
01 电商搜索需求背景
+首先,给大家分享下为什么要做搜索。
1. 被忽视、低估的搜索行为

在电商的 app 里,流量来自很多不同的渠道,比如说搜索、推荐、活动和直播等等。搜索,是电商 app 非常重要的一个流量入口,可能很多电商 app 来自搜索的流量都会占过半以上。对于需求明确的用户主要还是通过搜索来触达,对于需求不明确的用户主要通过推荐。那么,对于搜索,因为需求比较明确,所以会更容易转化。
2. 搜索用户体验痛点
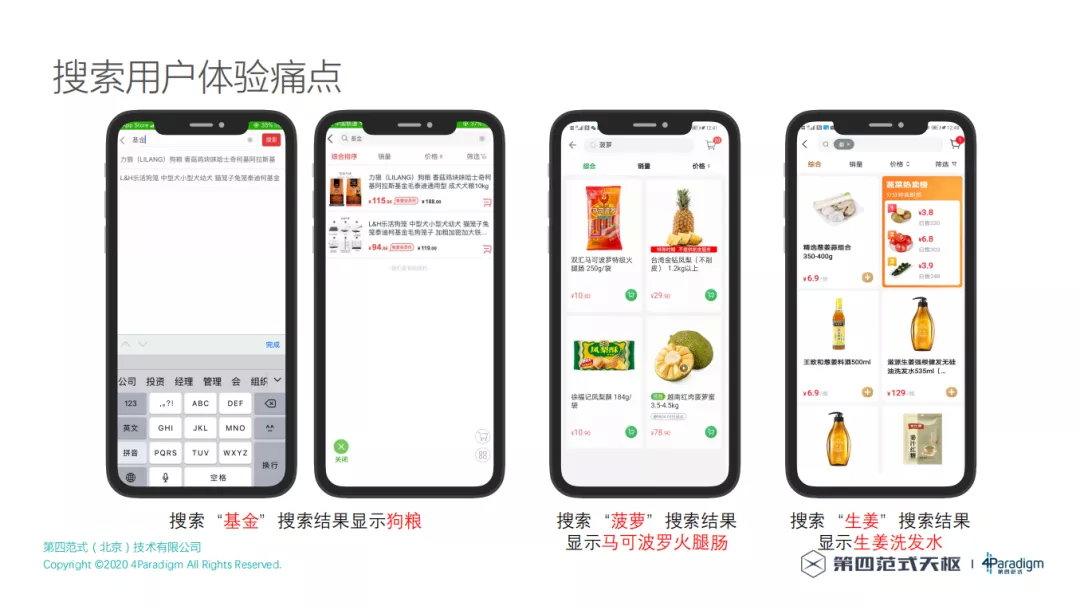
一些电商巨头其实已经把搜索体验做得非常好,但是一些体量较小的客户依然做不好搜索体验,所以这就给我们提供了市场机会。
3. 搜索痛点下的用户流失

如果搜索做得不好,用户搜索多次,浏览搜索结果超过一定时间或者翻页几次以后,都找不到结果,就会因为无法忍受搜索体验而流失。
4. 智能搜索挖掘用户行为数据价值
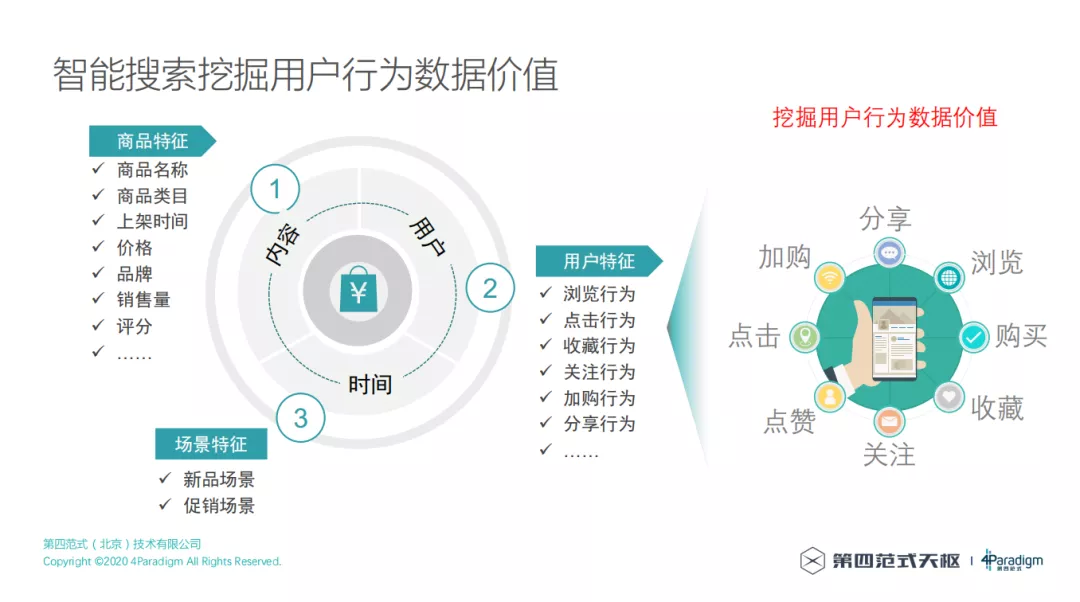
所以应该优化搜索体验,留住用户,那应该如果做好智能搜索呢?可以通过用户行为日志挖掘到很多有价值的数据,从这些数据中找到丰富的特征,利用这些特征去将搜索流量的价值最大化。
5. 电商搜索举例
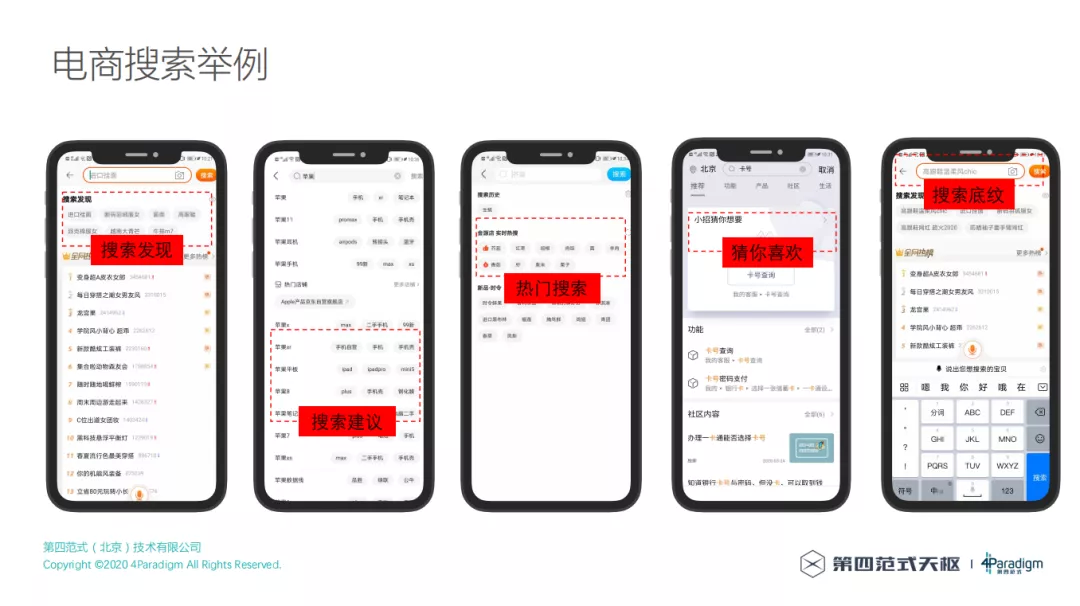
一般情况下,对于搜索,除了我们经常看到的去搜索框里面敲一些关键词来搜索以外,搜索还有其他场景,比如搜索发现、搜索建议、热门搜索、猜你喜欢和搜索底纹,其实这些已经不是单纯的搜索,而是跟推荐相结合的场景。
6. 商品搜索 VS. 网页搜索
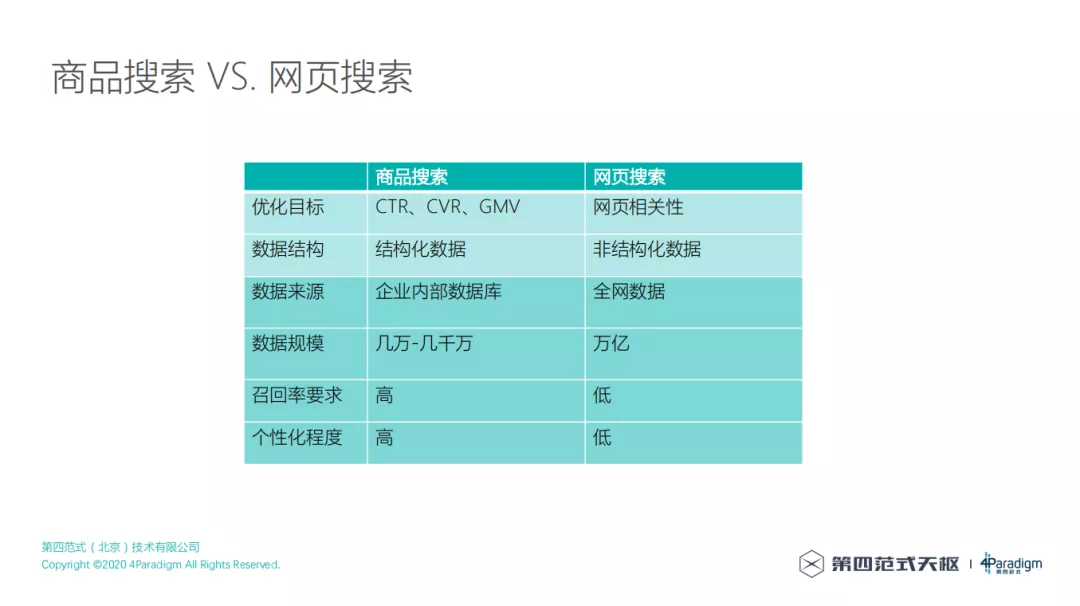
日常生活中,最熟悉的网页搜索和商品搜索有什么区别?可以从这几个方面来分析:
商品搜索和网页搜索的优化目标不一样,网页搜索主要是优化网页和搜索词的相关性 ( 不考虑网页搜索中的广告点击率优化 );而商品搜索主要优化目标是点击率 ( CTR )、转化率 ( CVR )、交易额 ( GMV ),两者的优化目标是有一些不同的。
从数据结构方面来讲,网页搜索使用的是全网的非结构化数据,需要额外的非结构化数据处理工作;而对于商品搜索,使用的是优质的结构化数据,比起网页搜索里面参差不齐的非结构化数据,少了数据整理和处理的工作。
从数据来源方面来讲,网页搜索使用的是整个互联网的数据,而商品搜索,往往是一家企业内部的数据,而且这些数据存储在它的业务数据库或者数仓里,相对来说数据是比较好处理的。
从数据规模来讲,网页搜索使用的数据一般是万亿级的规模,有超过万亿的网页,但是商品搜索的话,根据客户规模的大小,商品的 SKU 数或者 SPU 数基本上是几万到几千万这个级别,与网页搜索不在一个量级。
从召回率来讲,网页搜索对召回率的要求不会太高,但是商品搜索对召回率的要求是很高的,因为不能让一些商品永远没有曝光的机会,所以一定是需要让所有的商品都有曝光的机会,商品搜索对于召回率的要求是很高的。
从个性化程度来讲,网页搜索一般情况下也能做到个性化,通常像谷歌、百度等搜索公司在个性化上也会做一些工作,但是对个性化的要求并不高;而商品搜索对个性化的要求很高,比如搜索的时候,不同的人消费能力的不同,那么排序的时候,需要考虑把合适价格的产品返回给不同消费能力的人群。个性化要求的不同是网页搜索和商品搜索的重要区别,这就决定了两者技术实现的不同。
02 技术方案探索
接下来,介绍一下总体的技术方案。
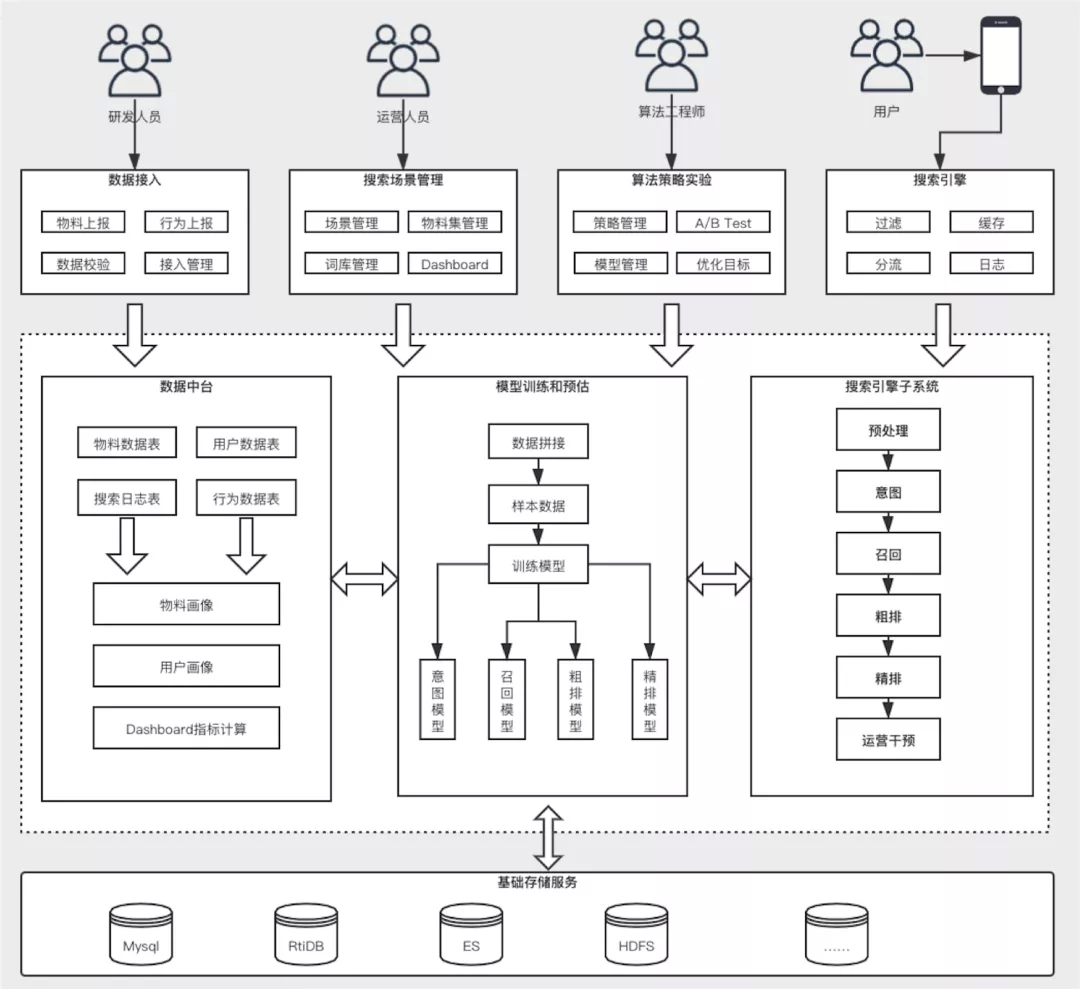
技术架构图主要分为三大块,一块是数据,一块是模型,一块是搜索引擎本身,其中数据和模型是为搜索引擎服务的,会有数据接入的一些模块,把客户的数据接入到系统里面,放入数据中台上去计算物料画像、用户画像等等;接下来,需要用这些数据建一些模型,这些模型会在搜索引擎的各个环节中用到,比如意图、召回、粗排、精排中各个环节都会用到;再往下,就是一些基础的数据存储中间件。我们主要围绕着搜索引擎本身这个流程展开,最右侧就是搜索引擎的流程,接下来我们从上往下来介绍一下整个搜索是如何做的。
1. Query 预处理
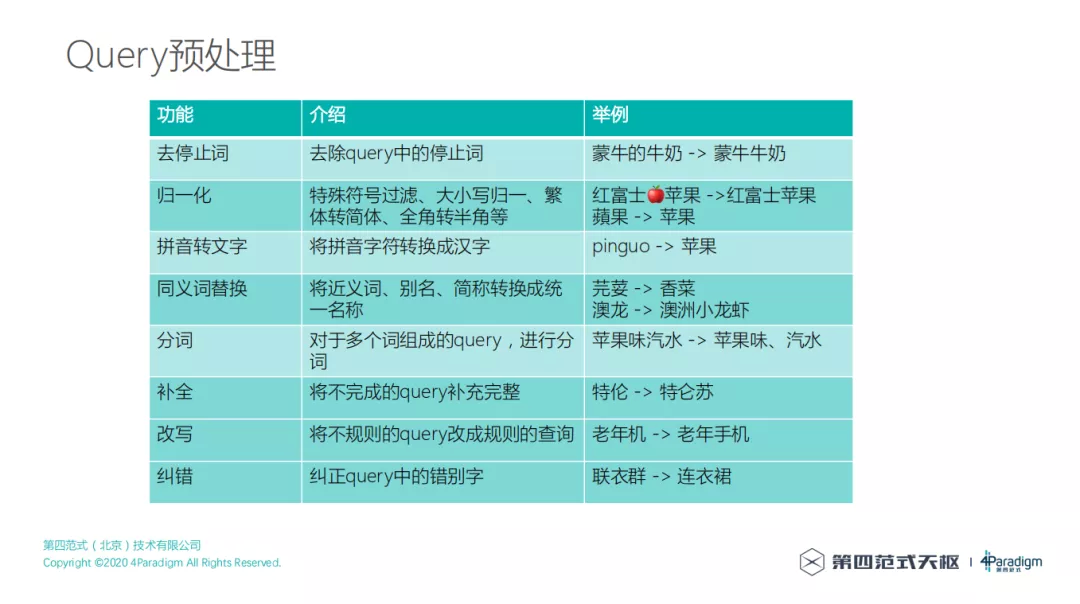
当用户在一个电商 app 上输入搜索词的时候,会先对搜索词进行预处理,这种预处理就包括常见的去停止词、归一化、拼音转文字、同义词替换、分词、补全、改写和纠错等等一系列的处理,然后把用户搜索的不太规范或者不正确的 query 处理成规范形式和正确形式,并且做一些分词、转换的处理。
2. 实体识别

做完预处理之后,得到了用户搜索词分词的结果,拿到这个分词结果,要把分词结果里面每一个词识别成一个实体,什么是实体呢?在电商里面的实体类型其实有很多,这里列出了三种,有商品实体类型,矿泉水就是一种实体,属于商品实体类型;农夫山泉是品牌这种实体类型;饮用水是一种分类或者叫类目,这些都是实体类型,实体类型下面有具体的实体,实体就是矿泉水,农夫山泉,所以需要知道输入的词到底是一个什么实体,比如说输入“奥利奥饼干”,做完预处理之后,得到“奥利奥”和“饼干”两个词,这个时候就需要做实体识别,识别后可以知道“奥利奥”是一种品牌,“饼干”是一种商品,这样就能做后续的处理。
实体识别是序列标注的一种,有很多种方法,像 CRF、BERT 之类的,都可以用来做实体识别,在工程上处理的时候不一定是在线使用这些算法,因为这些算法在线计算成本比较高,通常会进行离线计算,把计算出的结果放到缓存中,这样在线只需要做一些简单的匹配,处理会快很多,另外有时候还需要经过一些人工纠正,这样才能得到比较准确的实体词。做实体识别有一些前提条件,怎么知道矿泉水是一种商品?农夫山泉是一种品牌呢?这些知识其实是需要外部输入才能知道,这就是领域知识,所以首先要积累一些领域知识。
① 领域知识积累

领域知识其实是不太好分析出来的,举个例子,猪舌和口条其实是一回事,茭瓜和西葫芦是一回事,这些知识,当然可以去分析,那如何分析?其实有很多现成的知识可以抓取过来利用,把它作为领域知识积累下来。这个领域知识有很多形态,最简单就是词库,也可以构建知识图谱,构建知识图谱是构建领域知识最常用的方式。
② 词库挖掘

词库如何构建,需要挖掘各种类型的词,比如最常用的同义词和上位词,同义词理解可以用前面举的例子,茭瓜和西葫芦是一回事,获取同义词有很多种方法,使用预训练的词向量方法去找共现关系可以大量的找到同义词 ( 也就是类似 word2vec 的方法 ),但是找出来之后可能不太准确,需要后期处理一下才能使用。从百度百科上可以爬取到很多同义词,以及业务运营数据库和企业现有词库积累都可以找到同义词,有各种各样的方法去构建同义词库。
那么如何挖掘上位词,举例理解上位词,比如商品类目就是具体商品的上位词,矿泉水的上位词就是饮用水。词库的构建是做搜索必要的工作,但是在构建词库的过程中,不一定是手工的过程,完全可以用其他的自动化方法甚至模型去筛选词库,最后再做一些人工纠正。
③ 商品知识图谱构建
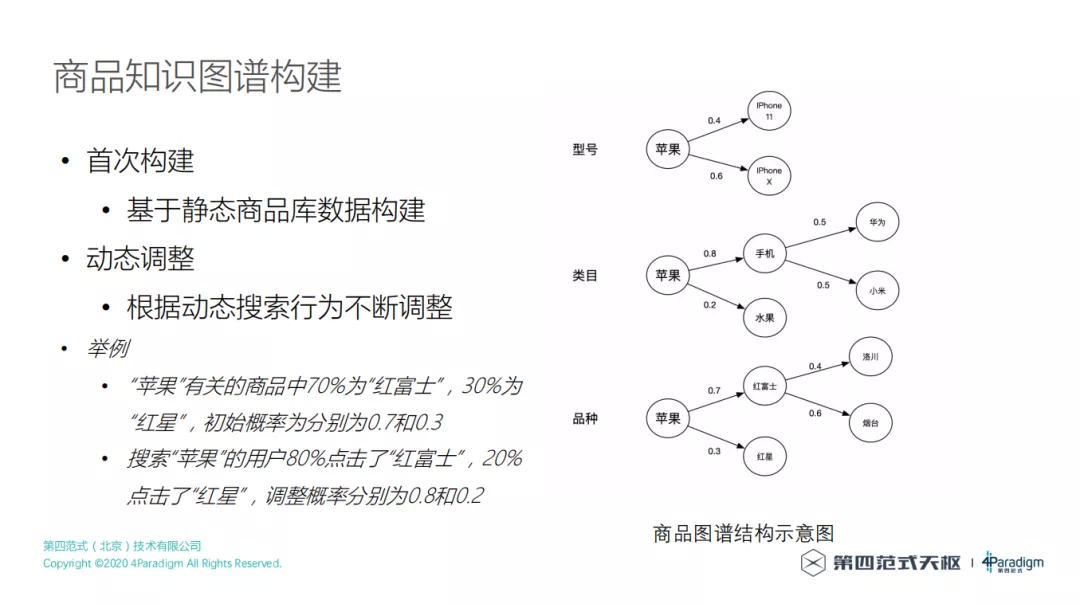
如何构建商品知识图谱,我们可以构建很多种不同类型的知识图谱,本文是根据不同实体来构建知识图谱,比如按照三种实体类型来构建知识图谱,像上图最右侧的示意图,苹果有很多种型号,如果用户搜索苹果,用户有可能想买 iPhone 11、iPhone X 或者还是没出来的 iPhone 12,可以通过先验知识,把知识图谱构建出来,最后排序时可以把这些知识融入进去,比如用户都更加倾向于去买 iPhone X,后面排序的时候 iPhone X 就会更靠前一些。对于类目来说,搜索苹果有可能是一个手机,也有可能是水果,那到底是想买手机还是想吃水果,是有一个概率的,不同用户有不同的倾向性,但是目前我们构建的图谱还不能做到特别个性化,它只是一个宏观的统计,搜苹果时有 80%的用户其实是要买苹果手机的,有 20%的用户要买水果,这样就给了我们一种排序的参考。知识图谱其实是做了一个非个性化全局的知识构建,通过商品库去分析静态概率,最后根据用户点击行为会做一些动态调整,调整完的知识图谱再用在后面的排序上。
3. 意图识别

将用户搜索词做了预处理之后,基于分词结果识别搜索词对应的实体类型,可以知道用户搜一个商品的时候,搜的是什么样的实体,是一个品牌,还是一个商品名称,还可以通过图谱去猜测用户的搜索意图,如果他只输一个苹果,能猜出来很大概率上可能要买手机,也可以把其他实体类型也猜出来,猜完了以后,还是有一部分猜不出来,那猜不出来的这部分怎么办呢,就要用意图识别。
那么如何做意图识别,使用用户导入的物料库自动的去训练意图模型,意图识别就是去做类目预测,甚至去做一些字面没有表达出来的其他实体类型的预测。在初始的物料库里面,商品的各种属性就是一些天然的标注数据,使用这些标注数据去训练一个初始的意图模型,来预测隐含的实体类型,当这个初始模型训练完成之后,再用搜索日志去动态调整这个意图模型。
做完预处理、分词、实体识别、基于知识图谱的预测和意图识别,能做到什么效果呢?能做到搜"手机",根据这个用户的信息,就可以知道手机是一个商品名字,还可以猜出来具体商品,但是猜的可能不一定那么准,这个用户可能有 80%的概率要买苹果手机,而且他买的这个苹果手机可能是 iPhone 11,还可能猜出来要买的颜色是红色的。这样在用户输入一个词的时候,就能预测出他可能要搜的所有的信息,当然这个预测有时准有时不准,但后面会调整,这样的话,就可以拿着这些信息去做一些召回。
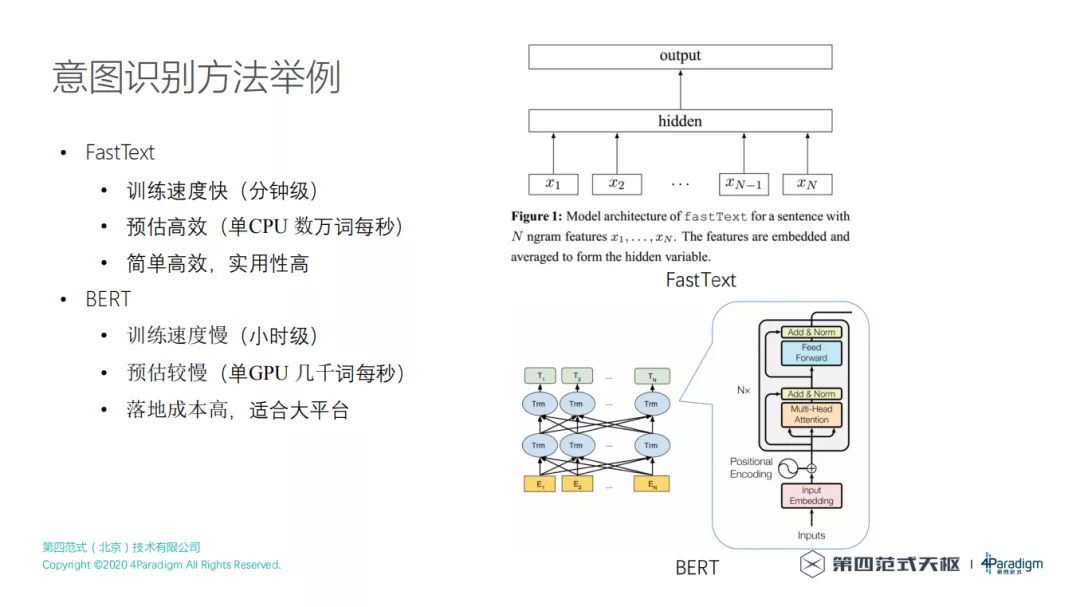
意图识别有哪些方法,意图识别的方法有很多种,因为意图识别本身用的就是分类器,分类器其实有好多种,但是经过各种对比之后,我们选择了能在线上使用的 FastText,同等效果下,FastText 是最快的,并且简单高效,实用性高。
4. 粗排

做完前面的工作就开始做召回,从用户搜索的一个词通过一系列流程,通过知识图谱 ( 其实知识图谱放的是一些比较头部的实体,但是长尾的实体词还是需要意图识别的方法来预测 ) 预测出了各种信息,拿着这些信息去构建召回的条件,用这个召回的条件去召回出来完整的结果集合,这个时候召回的工作就完成了。
召回的工作完成之后,接下来就是粗排,可以使用简单的模型来粗排,这个模型里面的特征可以用相关性 ( 搜索和推荐不同,搜索一开始就会有相关性,但推荐就不会有相关性,推荐不会先输入一些搜索词 )、时间、热度、销量、好评数和收藏数等等特征,训练出简单的模型,做一些粗排的排序,进行截断,进入下一个环节,想要更简单的话,可以找出核心的特征,做加权平均也可以。粗排还不能达到个性化的效果,当然也可以把粗排做得更个性化,可以根据不同搜索的用户做个性化的粗排模型。
5. 精排

得到粗排结果以后,接下来就是精排,对于搜索来讲,目前来讲主要的优化目标是 CTR,用的主要是 CTR 预估方法,CTR 预估有很多不同的方法,比如传统的特征工程方法、深度学习方法等,也可以使用第四范式自研的 HyperCycle。
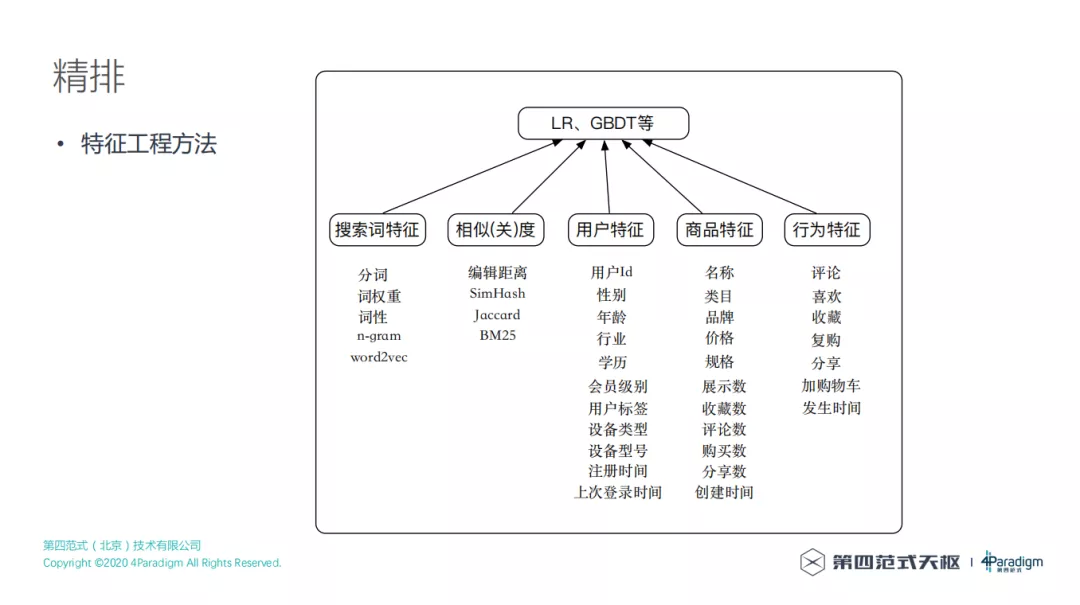
特征工程方法主要是利用不同种类的多种特征,构建机器学习排序模型,上面列了几组特征,有搜索词特征、相关性特征、用户特征、商品特征和行为特征等。
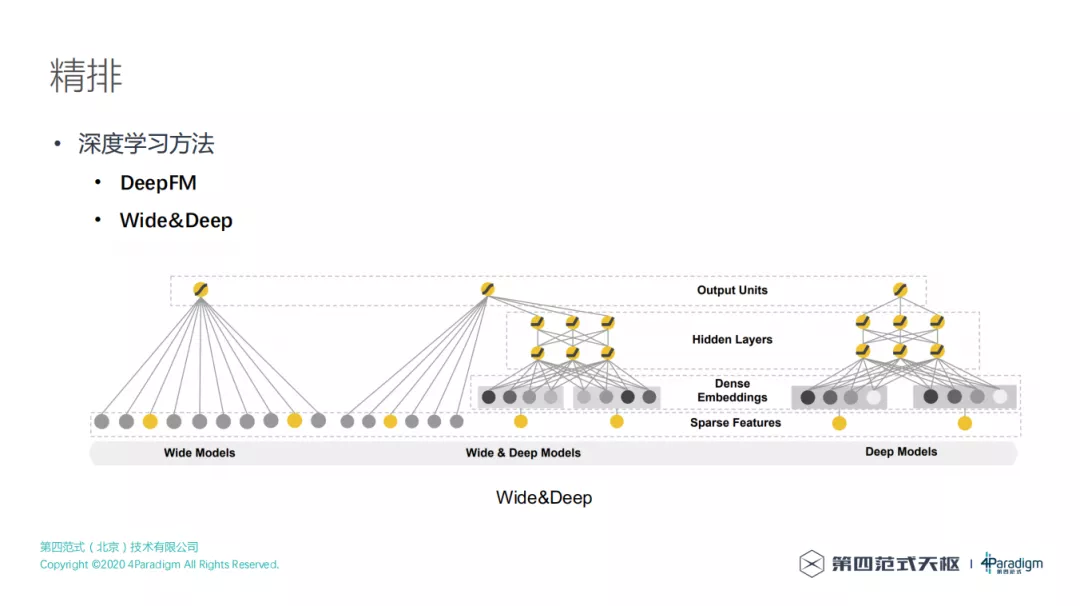
深度学习方法也是常用的 CTR 预估方法,有很多深度学习模型可以用于搜索场景的排序,比如 DeepFM、Wide&Deep 等。
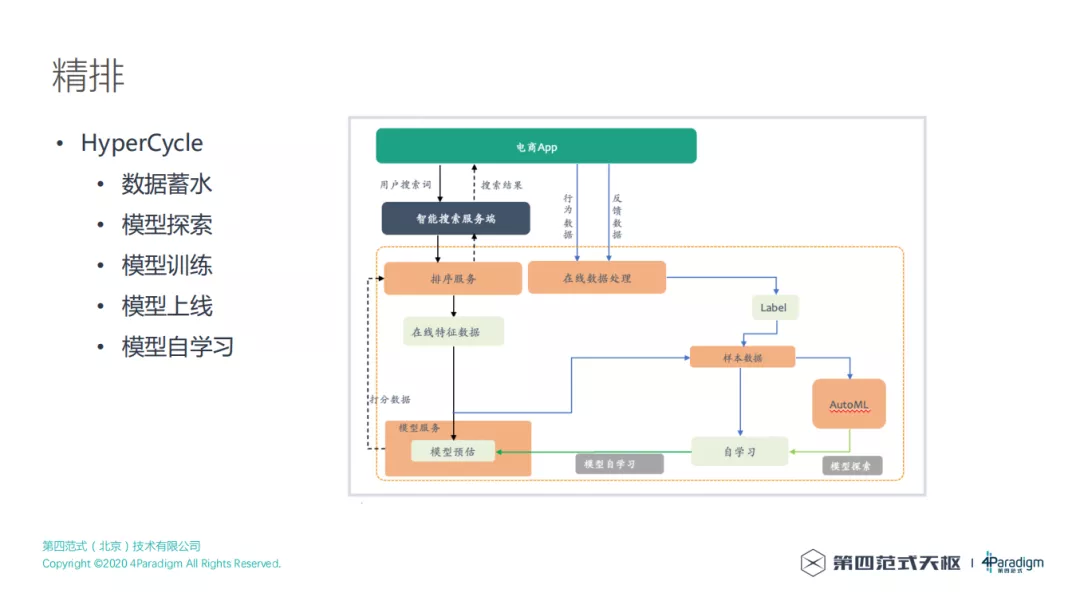
我们系统中主要使用的是自研的 HyperCycle。简单来说会自动蓄水积累数据、自动探索模型、自动挖掘特征,自动训练上线,还会定期自动更新,详细信息可以参考后面石光川分享的 HyperCycle。
6. 其他

搜索中会出现推荐相关的应用场景,像搜索底纹、搜索发现、搜索提示、猜你喜欢和相关搜索等等都和推荐相关。
搜索底纹就是搜索框里面唯一的那个词,其实就是对搜索框 top1 的推荐,根据用户的历史行为,推荐出该用户最有可能搜的词汇取 top1 放在搜索底纹里,然后推荐给用户,用户看见这个底纹以后就有可能去搜这个底纹上的搜索词,目的是希望引导用户,猜出用户想要搜什么,提高转化率;搜索发现跟搜索底纹的原理差不多,只是有了更多推荐的搜索词;搜索提示是在搜索中做一些推荐,相关搜索是在没有搜索结果时做一些相关推荐;有的地方还会有猜你喜欢,猜你喜欢其实是一个纯推荐的场景,当用户打开搜索页面时,去猜用户最想要搜索的是什么,然后推荐给用户。这些其实都是搜索中的推荐,搜索中的流量和推荐中的流量是完全可以打通的。

以上,逐个讲了整个搜索的流程,那么现在分步的去看搜索一个词时是怎样的过程。第一步会先输入搜索词"康师傅方便面",第二步预处理,预处理会做一些事情,首先是分词,之后会算出来该搜索词可能的实体类型,比如康师傅是一个品牌,它识别出康师傅是一个品牌,方便面可能是一种修饰语,也可能是一种类型,还有一些同义词:袋装面、桶装面和泡面,做完第二步的处理,会拿到这样一些处理结果;第三步意图识别,可以看到有 96%的概率所属类目是粮油调味;

第四步构建一个搜索 query,从 ES 召回结果;第五步拿到 ES 召回的结果之后,做粗排并截断;第六步做精排;最后做基于业务规则的运营干预,把最终的搜索结果返回给用户,以上就是完整的技术流程。
03 应用案例和效果
最后,我们看看搜索技术方案应用案例,分析产生的效果。
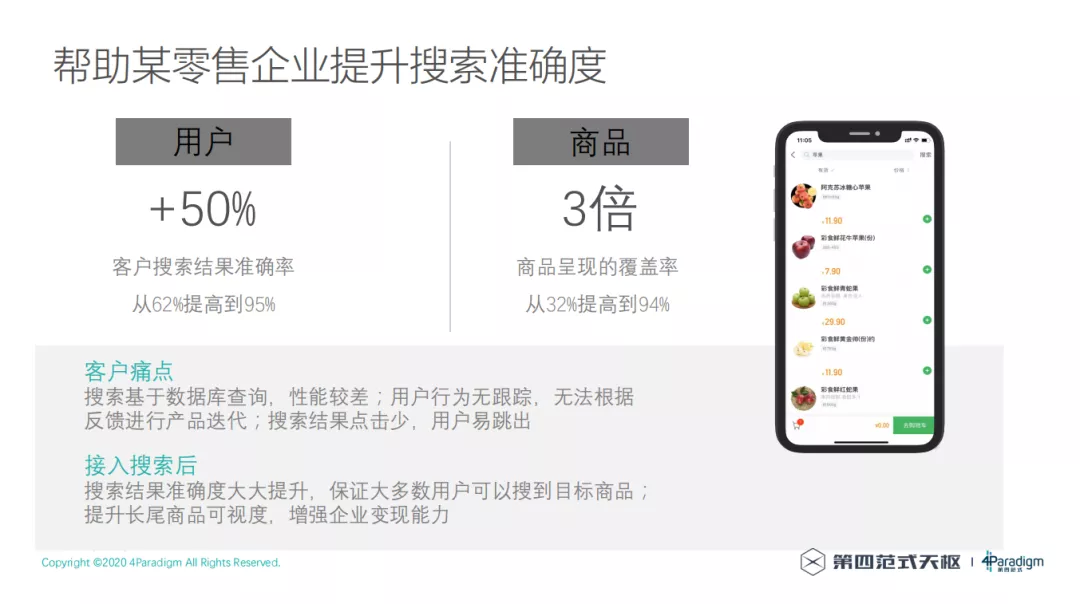
在一些零售企业场景应用之后搜索结果准确率提升了 50%,整个商品的覆盖率提高了 3 倍,解决了客户的搜索体验痛点。
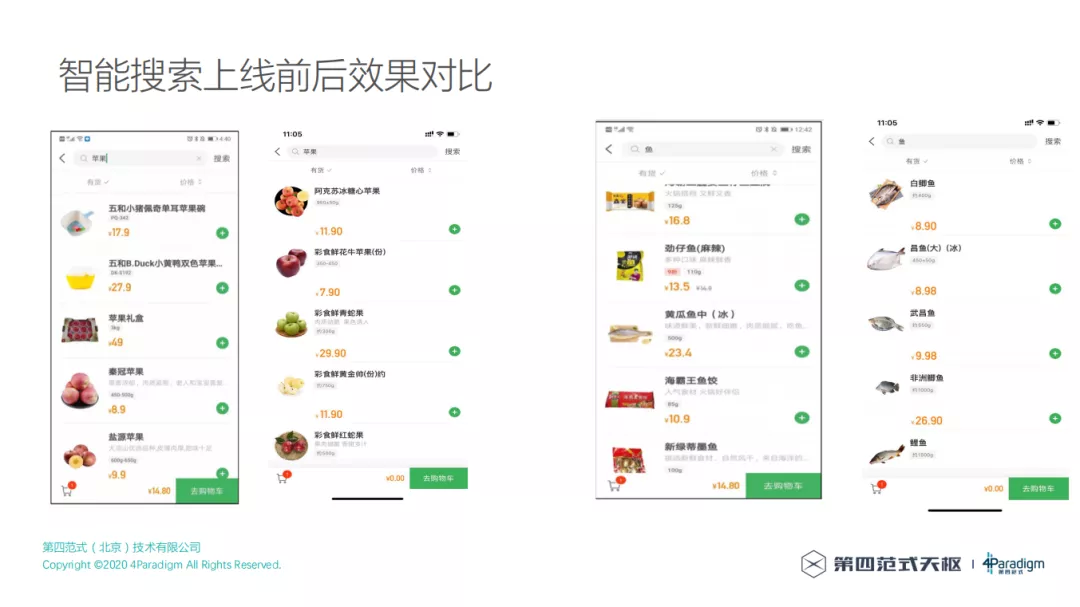
这是上线前后搜索结果的对比,没上线前搜索"苹果"时,排在前面并不是苹果,上线智能搜索之后,搜索结果都是"苹果"相关的。
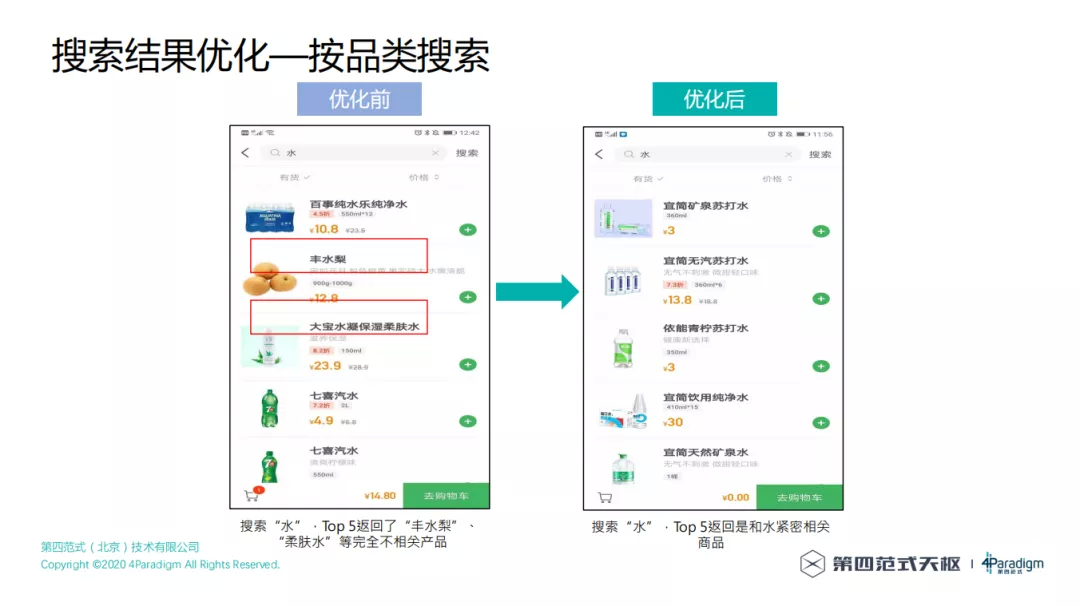
按品类搜索,优化前搜索"水",Top 5 返回了"丰水梨"、"柔肤水"等完全不相关产品,优化后搜索"水",Top 5 返回是和水紧密相关商品。
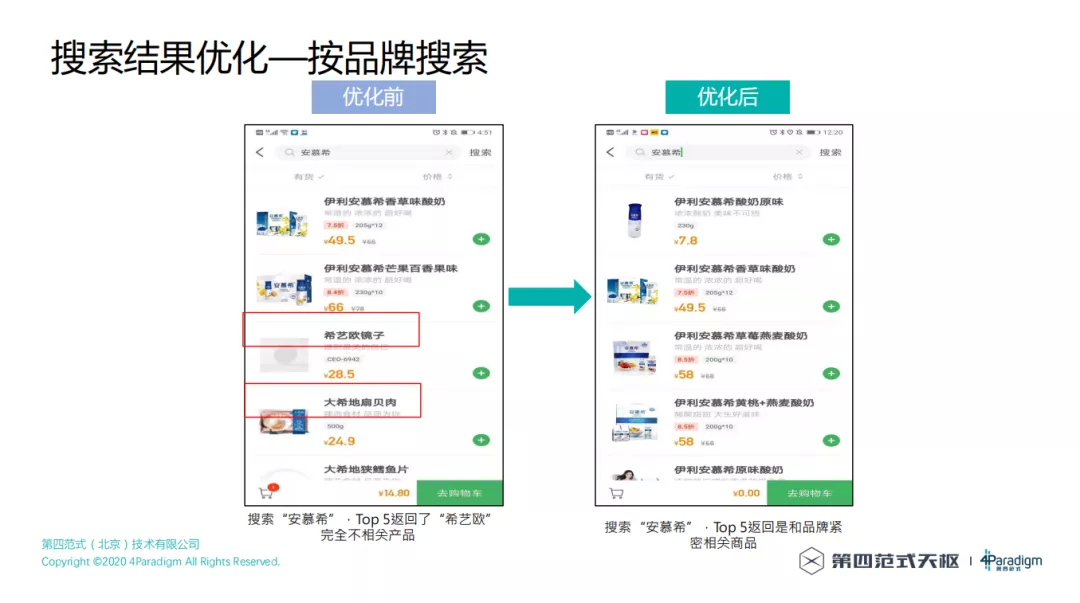
按品牌搜索,优化前搜索"安慕希",Top 5 返回了"希艺欧"完全不相关商品,优化后搜索"安慕希",Top 5 返回是和品牌紧密相关商品。
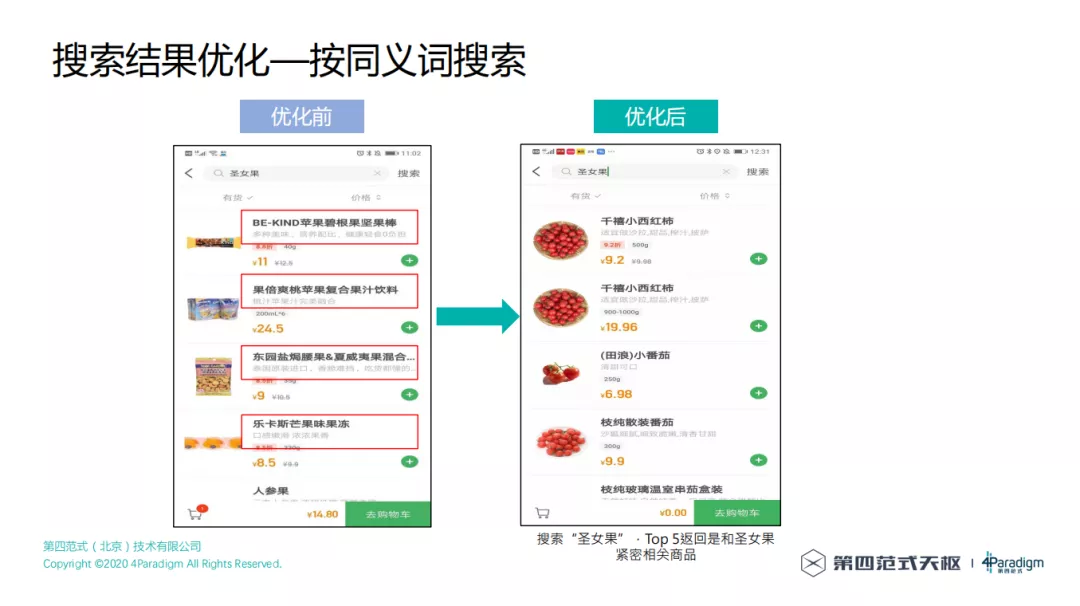
按同义词搜索,优化前搜索"圣女果",Top5 返回了"果汁饮料"、"芒果味果冻"毫不相关的商品,优化后搜索"圣女果",Top5 返回是和圣女果紧密相关商品。
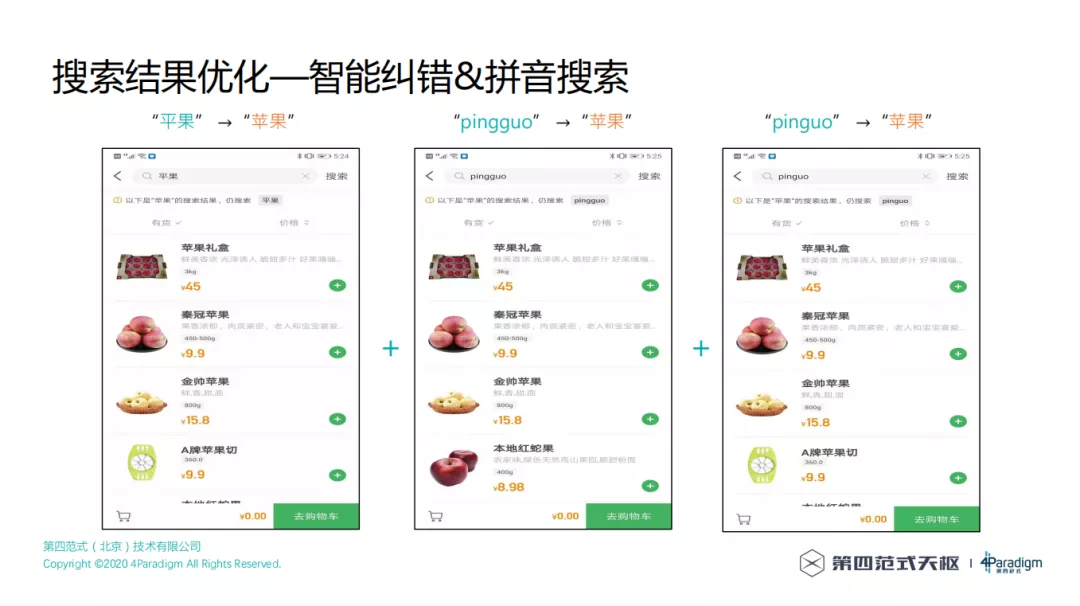
优化后,可以进行智能纠错和拼音搜索,比如搜索 "平果"、"pingguo" 和 "pinguo" 时,都能准确搜索出苹果相关的商品。
今天的分享就到这里,谢谢大家。
作者介绍:
邢少敏,17 年加入第四范式,一直在做业务产品的研发,最初做智能客服系列产品,去年孵化了智能搜索产品,今年同时在做智能推荐产品的研发。
本文来自 DataFunTalk
原文链接:




