
一、背景介绍
作为网易集团的基础软件团队,网易数帆在存储层面研发和维护了面向高性能需求的Curve开源存储、面向对象存储场景的 NOS 以及面向大数据场景的 HDFS 等多套系统,其中 NOS(NetEase Object Storage)作为一款对象存储产品,旨在为用户提供简便高效的互联网数据存取服务。从 2012 年上线至今,NOS 已有近 8 年的历史,当前数据总量接近百 PB 规模。早期的 NOS 底层存储引擎使用的是网易数帆自研的 SDFS 和 NEFS,虽然它们都提供了极高的稳定性和足够的性能,但在数据保护方式上均采用了三副本的冗余策略,这使得存储成本随着数据规模的不断扩大而快速上涨。因此,NOS 团队近几年来开始实践另一种数据保护策略,即Erasure Coding(纠删码,简称为 EC)。鉴于网易数帆块存储团队已经积累了多年的Ceph实践和运维经验,而且 Ceph 本身也是开源社区最火热的存储系统之一,我们最终选择了使用其作为底层 EC 存储引擎。不过,考虑到 NOS 已有成熟的网关和用户/桶管理等系统,我们并没有使用 Ceph 提供的对象存储RGW,而是选择了直接对接Rados接口。
二、架构调整
显然,对于一个庞大的存储系统而言,切换底层引擎不是一蹴而就的事情,在很长一段时间内会存在多个引擎同时运作的情况。为此我们专门开发了一套 LifeCycle 组件,将较低频的数据逐步迁移到 EC 池,整个系统的基本架构大致如下:
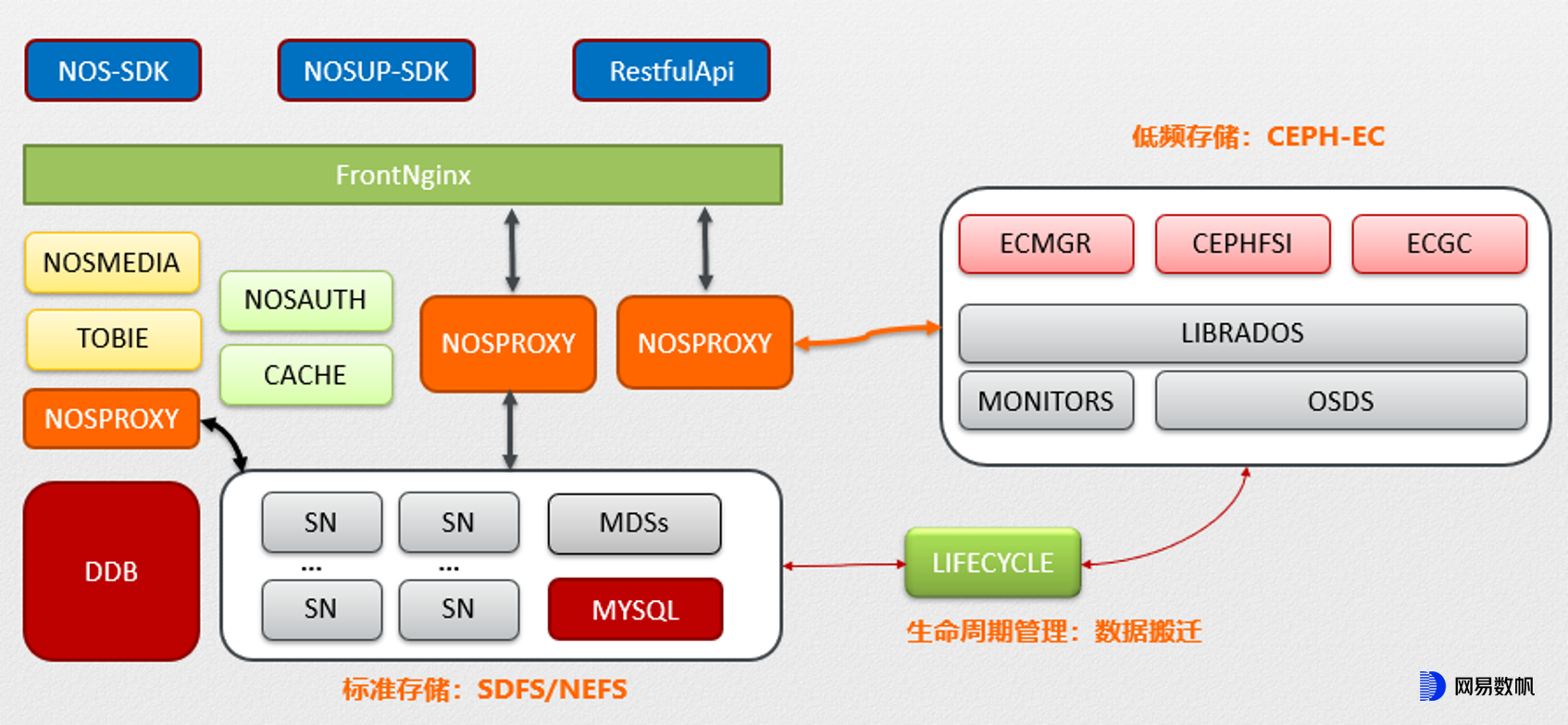
其中的DDB是网易自研的高性能分布式数据库,主要用于存储 NOS 的各项元数据信息。在它的帮助下,我们可以方便地做到小对象合并,管控数据存储位置等(在下一章节详述);同时它也让 Rados 成为一个比较纯粹的数据存储引擎。
EC 策略虽然可以节省空间成本,但是在性能尤其是时延方面与副本有较大差距,因此我们并不打算完全替换掉原来的副本池,而是采用类似分层存储的设计,使得:
用户业务数据依然先写入副本池,保障其上传性能
数据在达到预设条件(如一段时间无访问等)后,通过 LifeCycle 程序自动转入 EC 池
当数据再次被读取时,由 EC 池提供服务,而且不再转回副本池
在此设定下,写入 EC 池的流量比较可控,IOPS 性能要求不高,主要保证写入带宽即可,正好可以发挥 SATA 机械盘的长处;但业务读请求会直接进入 EC 池,需要尽力保障。
三、问题与优化
虽然开源的 Ceph 本身是一个开箱即可用的产品,但是在实践中依然会遇到各种各样的问题。为了使其能更好地适用在 NOS 场景中,我们做了一系列优化措施,下面分享几个比较重要的修改点。
1. 小对象合并与条带放大
EC 策略的一个重要限制是读写一般以条带(stripe)为单位进行。例如,以业界常见的 8+3 配置为例,假设每个分片(stripe unit 或者 chunk)的大小为 4KiB,那么条带的数据区大小即为 8 * 4KiB = 32KiB。在写入时,如果业务数据大小不是条带长度的整数倍,那么其尾端需要填上一些无用数据(通常是补 0,称之为 padding)进行对齐;这就要求条带不能设置的过大,以免容量浪费严重。在读取时,需要分别读取各个分片,再将结果拼接成原始数据;跟副本仅需从单一数据源读取相比,显然这种方式的请求时延会有所上升。
上面提到过,NOS 对读性能的要求比较高,常规的 EC 设计无法满足我们的业务需求。另外,据内部统计,NOS 中有 80%以上的对象大小不到 128KiB,如果每个都单独存储,势必效率低下。为解决这两个问题,我们选择将每个分片大小调大到 128KiB(即单条带增大到 8 * 128KiB = 1MiB),同时在 LifeCycle 组件中加入了小对象合并的功能,以减小 padding 和元数据所带来的开销。如下图所示:
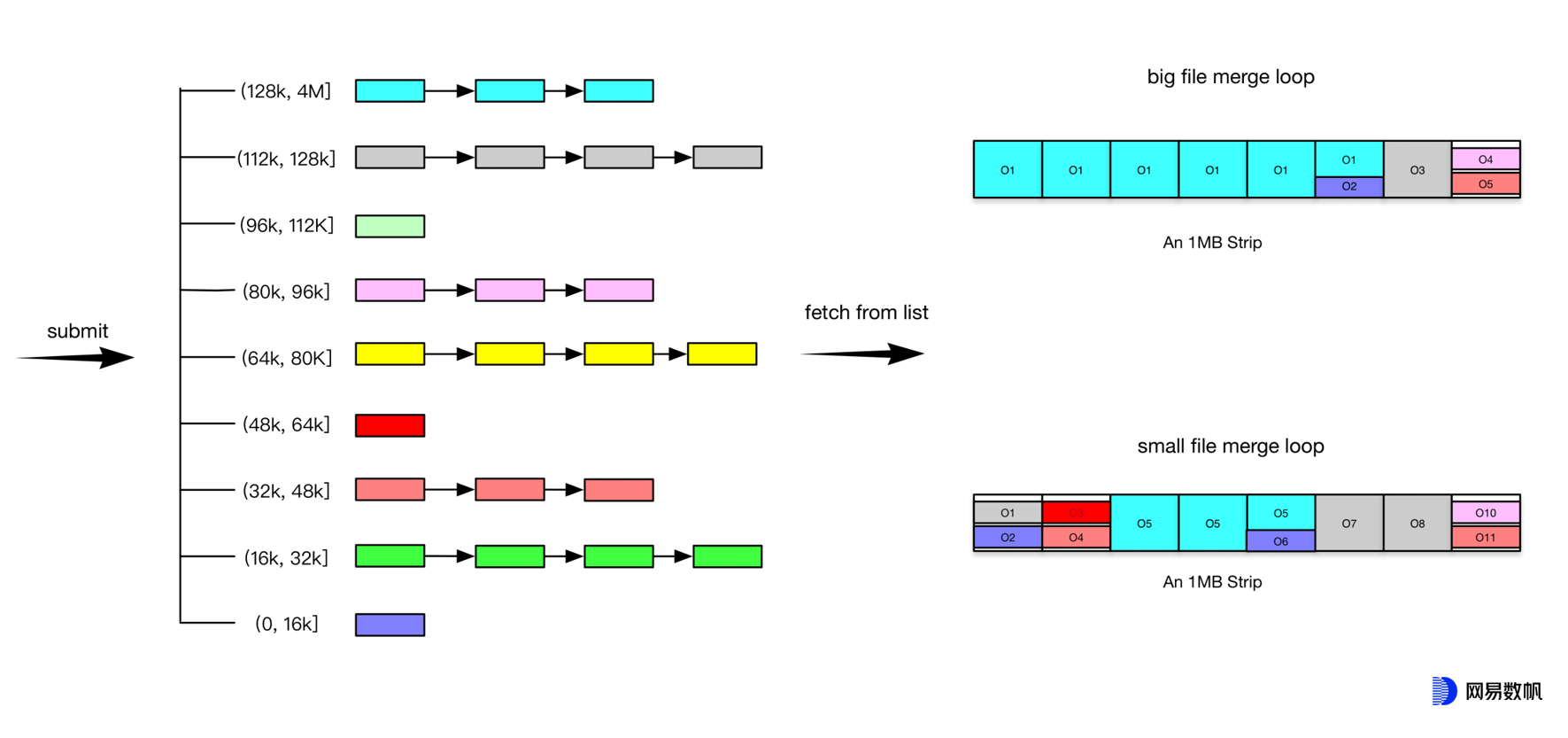
具体步骤如下:
缓存一批 NOS 对象元数据(其实只要 ID 和 size),将其按大小放入预设的离散空闲列表(类似于反向的Segregated Free List)中
按一定的匹配算法选择合适的 NOS 小对象,合并到一个条带中,再统一 append 到 Rados 大对象;算法基本限制条件有:
小于等于分片大小的对象,不能跨分片
大于分片大小的对象,头部应该与某一个分片对齐,尾部再考虑是否需要再填充其他小对象
一个分片允许保存多个小对象
尽可能充分利用每个分片空间,减少浪费
对于比条带大小更大的 NOS 对象,则将其按条带取余后剩下部分再考虑合并即可
每消耗一组 NOS 对象,立时加入新对象补充,保证缓存内总数维持在预设值上下
一般而言,合并的效率取决于缓存中 NOS 对象 size 的离散程度。理想情况下,我们总能找到合适大小的对象,刚好将分片/条带填充满,这样就不会有空间浪费。然而现实并不会如此美好,总有部分空洞填哪个对象都不怎么合适。因此,我们设定了最低的有效空间利用率,如果达不到此阈值,则放弃此次合并并将相关的小对象放回到空闲列表;当然,对于被放弃多次的小对象,也必须能打破此利用率的限制,避免进入死循环。
此外,我们还修改了 Rados 的接口,使客户端可以单独向一个分片发送读请求。这样,对于八成以上的对象读取,性能基本能与副本池相当。而转存写入时由于几乎全是 1MiB 的大 IO,其带宽也完全可以跟得上副本池业务写入的速度。从客户端角度看,整体性能与纯副本集群相差无几。
2. 对象名称生成器
Ceph 的一大开创性设计是其CRUSH算法,可以不需要查表,仅通过计算得到 Rados 对象的存储位置。这虽然省去了元数据表的消耗,但也为 Ceph 带来了经常被诟病的问题,即数据分布不均衡(因为完全依赖于哈希函数的随机性)。在 NOS 原有的存储引擎中,互为副本的硬盘成对使用,每块硬盘仅需保留数十 GiB 左右的空间作缓冲即可,对于对象存储中动辄上 10TB 的硬盘这完全可以接受,其最终的容量使用率可以达到 99%甚至以上。而 Ceph 在一个存储池中某块盘达到 full ratio(默认为 95%)时就会限制整个池的业务写入(因为无法预测到新数据是否会哈希到这块盘上),这时同一个池中使用率最低的硬盘可能仅用了 60% ~ 70%,导致整体容量利用率往往只能维持在 80%左右,这无疑是一种巨大的浪费。虽然 Ceph 在较新的版本中提供了一定的自均衡功能,然而其会引发大量的数据迁移,代价依然不小。
这个问题的根本原因在于 Ceph 中映射关系完全靠固定的计算得到。当用户选定好对象名(算法主要变化的入参就是对象名称)后,其存放位置就已经基本确定下来;而用户选择什么样的名称是存储系统不可控的。NOS 在实现对象合并功能时,使用 DDB 记录了 NOS 对象到 Rados 对象的映射关系;换一个角度看,这相当于在业务数据和 Ceph 系统之间增加了一层映射隔离,带来的好处是我们可以自主地选择 Rados 对象名称,从而控制数据存放的位置。因此,在 LifeCycle 程序中我们又加入了对象名称生成功能,提前准备好合适的对象名,确保该对象能尽可能地写到使用率较低的硬盘上。另外,对于那些已经达到 full ratio 阈值的硬盘,可以选择将其过滤,然后继续往剩下的盘中写入。在上线此功能后,NOS 的硬盘容量平均使用率可以提升到 97%左右,大大节省了成本。
3. 本地 Key-Value 数据库
实现小对象合并功能时,我们在 DDB 中存放了每个 NOS 对象到 Rados 对象的映射信息,这已经可以满足正常的业务流程。然而做垃圾回收时,我们必须知道某个 Rados 对象上一共存放了哪些 NOS 对象,即反向映射关系。出于成本考虑,我们并不想把这层映射存储在高性能数据库中,而是希望能与对象数据一起放到 Rados 里。值得一提的是,Ceph 本身就为 Rados 设计了一个重要的附属存储,即 omap。本质上讲它是在每一个OSD里运行的本地 Key-Value 数据库(默认为 RocksDB),用于辅助存放一些元数据信息;这正是我们所需要的。然而很遗憾,可能出于编解码难度和存储效率考虑,现有的 Ceph 版本并不支持 EC 池使用 omap(只有副本池支持)。
为解决此问题,我们参考副本 omap 的实现,在 EC 池上也开放了相同的接口。从底层看,omap 被存储在每个 Rados 对象的前 M+1 个分片(如 8+3 则为前 4 个)上,且内容完全一致(这点与副本相同)。借助于此,仅需一个简单的 Get 接口即可获取被合并在一起的 NOS 对象列表,方便快捷。
4. 硬件资源优化
对于高密度的存储机器而言,硬件成本(主要是内存和 CPU)通常抠算的很紧,因此如何在有限的资源下提供更高更稳定的性能一直是我们钻研的重点之一。在深入分析开源代码后,我们对其做了“大瘦身”,删去了 Rados 中一些不必要的功能(例如快照),简化了关键结构体(例如 Onode)的缓存形态,仅保留 NOS 真正需要的流程和信息。目前为止,在相同硬件配置下 NOS Rados 相较开源版本读写性能提升均在 30%以上。
四、总结与展望
在切换到 EC 策略后,存储硬件成本有了大幅度的下降;后续针对低频数据,可以采用 EC 20+4 甚至 28+4 配比,进一步提升有效空间利用率。Ceph 作为一款出色的开源存储产品,提供了高度的可靠性和优秀的可运维性,但是性能和可用性上确实比较薄弱。NOS 团队站在这位巨人的肩膀上,深耕源码,定制优化,取长补短,持续演进,相信定能提供一个越来越有竞争力的产品。
作者简介
徐桑迪,网易数帆轻舟事业部资深系统开发工程师,具有多年分布式存储研发运维经验,负责存储平台的架构设计、性能优化、特性开发等,支持各种云上业务并推动产品持续演进。目前主要专注于低成本对象存储和容器化文件存储领域。




