
作为推动 AI 应用大规模落地的关键力量,深度学习平台的重要性日益凸显。近年来,全球人工智能学术界以及产业界各研发主体陆续开源旗下自主研发深度学习技术,搭建人工智能开放平台,推动人工智能产业生态的建立。
据 2021 年 IDC 报告显示,中国首个自主研发、开源开放的产业级深度学习平台百度飞桨,在中国深度学习平台市场综合份额位列第一。以飞桨为代表的深度学习平台正在发展成为更适合产业需求、更受中国开发者欢迎的 AI 新型基础设施。

11 月 30 日,由深度学习技术及应用国家工程研究中心主办的 WAVE SUMMIT+ 2022 深度学习开发者峰会如期举行。鹏城实验室主任、中国工程院高文院士,深圳大学电子与信息工程学院院长、深度学习技术及应用国家工程研究中心技术委员会副主任、中国工程院丁文华院士受邀致辞。百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰发表题为《深度学习平台加大模型,产业智能化基座》的主题演讲。会上,百度发布了飞桨产业级深度学习平台和文心大模型的生态成果和最新进展:截至 2022 年 11 月,飞桨平台已凝聚 535 万开发者,服务 20 万企事业单位,基于飞桨创建了 67 万个模型。飞桨构建了全方位的生态体系,协同开发者、科研院所、企事业单位、技术伙伴、硬件厂商等共创、共生、共赢。

在数字技术与实体经济加速融合的趋势下,AI 与产业结合的场景越来越深入,正在持续为中国数字经济注入新动能,在这样的背景下,百度飞桨与英特尔的合作也在纵深发展。
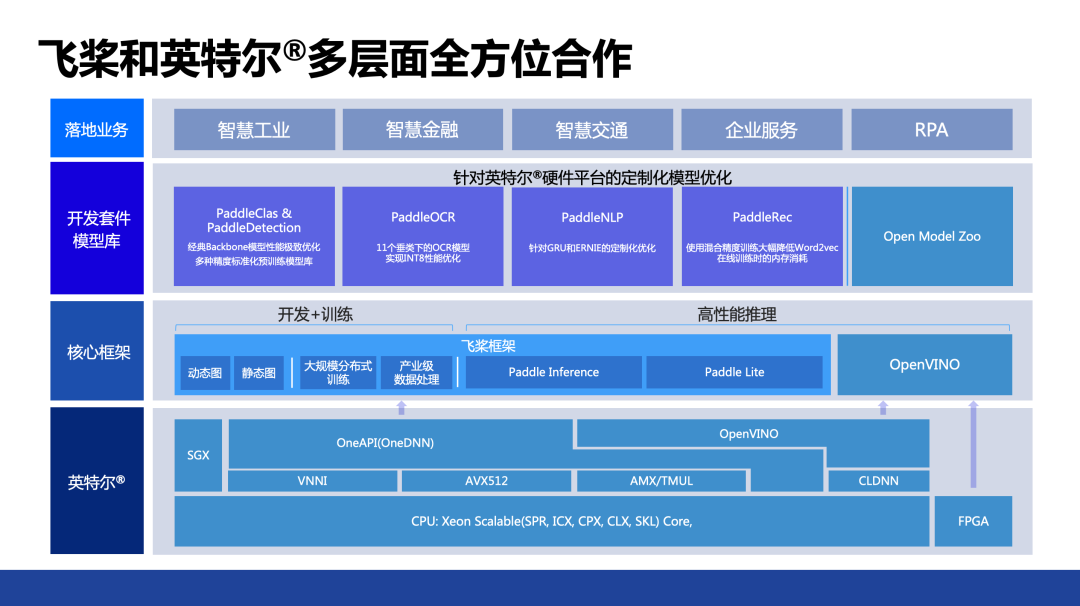
此次峰会上,百度飞桨与英特尔联合发布了两个白皮书——《验证至强内置全新 AI 加速技术》和《见证 CPU 加速 AI for Science 普及潜能》,详细介绍了双方在近期的技术合作情况。在数据中心层面,全系列英特尔®至强®可扩展处理器针对百度飞桨的各种模型和框架进行了深度优化。此外,基于英特尔软硬件的联合优化,百度 ERNIE 3.0 轻量化版本 ERNIE-Tiny 的性能获得了显著的提升。作为百度面向 NLP 领域的重要技术方案,基于轻量化技术的 ERNIE 3.0 轻量版可在搜索排序、推荐、信息抽取、地图检索、自然语言推断等应用场景中为用户提供响应迅速、质量可靠的能力输出。全新第四代英特尔®至强®可扩展处理器及英特尔® AMX 技术的引入,配合英特尔®oneAPI 深度神经网络库 (英特尔® oneDNN) 来调用英特尔®AMX 指令,使轻量版 ERNIE 3.0 在通用 CPU 平台上也能获得令人满意的推理效能,进而帮助更多用户在其既有 IT 设施中更方便地部署 ERNIE 3.0。
此外,AI 在科学领域的应用也面临各种挑战——如何让 AI 模型和物理模型进行联合扩展,如何保证各种 AI 框架和计算模型、计算框架实现无缝连接等。为此,百度飞桨与英特尔共同探索 AI for Science 领域,借助各种深度学习加速技术,共同助力深度学习技术在 AI 和科学计算领域的应用,有效提高用户深度学习应用的各种效率。
为加速一站式边缘 AI 开发部署,英特尔与百度飞桨携手,使广大开发者可以借助百度飞桨 EasyDL 零门槛 AI 开发平台 快速开发针对边缘硬件优化的模型,并基于英特尔视频 AI 计算盒与 OpenVINO 深度学习推理工具在边缘端加速视频 AI 计算。英特尔视频 AI 计算盒是一款基于英特尔硬件的高性能、可扩展通用计算平台,覆盖各类行业与场景的商用 AI 算法,聚合诸多生态伙伴,能够有效应对边缘 AI 碎片化挑战,并实现云边端灵活部署。基于英特尔视频 AI 计算盒的以上特点,结合 EasyDL 全场景、零门槛、广适配的优势,用户可以缩短模型训练周期,并根据实际场景选择不同部署方式,以实现更便捷的落地。
与此同时,百度飞桨与英特尔一起,共同繁荣 AI 生态,实现共同发展。近年来,英特尔 OpenVINO 与百度飞桨围绕构建模型、优化及部署三个方面的合作不断深入,不仅帮助开发者减少中间环节,还能够让一些大规模大模型在边缘部署成为可能,优化了整个的边缘推理和操作流程。如今,OpenVINO 不仅能够支持飞桨模型在英特尔 CPU 和集成显卡上部署,还可以支持飞桨模型在英特尔独立显卡上部署。此外,OpenVINO 不仅支持飞桨模型在单张独立显卡上部署,还可以通过一行代码支持飞桨模型在多张独立显卡上部署。




