简介
Spring XD(eXtreme Data,极限数据)是 Pivotal 的大数据产品。它结合了 Spring Boot 和 Grails ,组成 Spring IO 平台的执行部分。尽管 Spring XD 利用了大量现存的 Spring 项目,但它是一种运行时环境,而不是一个类库或者框架,它包含带有服务器的 bin 目录,你可以通过命令行启动并与之交互。运行时可以运行在开发机上、客户端自己的服务器上、AWS EC2 上或者 Cloud Foundry 上。
Spring XD 中的关键组件是管理和容器服务器(Admin and Container Servers)。使用一种 DSL ,你可以把所需处理任务的描述通过 HTTP 提交给管理服务器。然后管理服务器会把处理的任务映射到处理模块(每个模块都是一个执行单元,作为 Spring 应用程序上下文实现)中。
该产品具有两种操作模式:-single 和 multi-node。第一种是由单独的进程负责所有处理和管理的工作。这对于入门很有用,同样适合于应用程序的快速开发和测试。本文中的所有实例都被设计为在单一节点模式下工作。第二种是一种分布式模式。分布式集成运行时(Distributed Integration Runtime,DIRT)会在多个节点之间分发处理的任务。除了可以拥有 VM 或者物理服务器作为这些节点之外,Spring XD 还让你可以在 Hadoop YARN 集群上运行。
XD 管理服务器会把处理的任务切分成彼此独立的模块定义,并把每个模块分配给使用 Apache ZooKeeper 的容器实例。每个容器都会监听分配给它的模块定义,然后部署模块,创建 Spring 应用程序上下文来运行它。需要注意的是,在我撰写这篇文章的时候,Spring XD 中还不会自带 Zookeeper。兼容的版本是 3.4.6,你可以从这里下载。
模块通过使用配置好的消息中间件传递消息来共享数据。传输层是可插拔的,并且支持其他两种Pivotal 项目—— Redis 和 Rabbit MQ ——以及现成可用的内存数据库。
用例
下图让你可以对 Spring XD 有个总体上的了解。
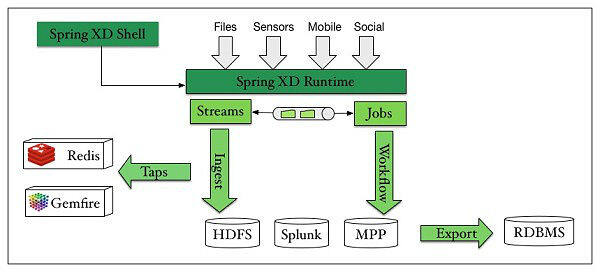
Spring XD 团队认为,对于创建大数据解决方案来说,创建的主要用例有四种:数据吸纳、实时分析、工作流调度以及导出。
数据吸纳提供了一种能力,可以从各种输入源接收数据,并把它传输给大数据存储库,像 HDFS(Hadoop 文件系统)、Splunk 或者 MPP 数据库。和文件一样,数据源可能包括来自于移动设备、支持 MQ 遥感传输协议(MQTT)的传感器以及像 Twitter 之类的社交流的事件。
吸纳过程会贯穿事件驱动数据的处理,以及针对其他类型数据的批处理(MR、PIG、Hive、Cascading、SQL 等等)。流和作业的两个世界截然不同,但是 Spring XD 试图使用通道抽象(channel abstraction)来模糊二者之间的边界,从而让流可以触发批处理作业,而批处理作业也可以发送事件从而触发其他流。
对于流来说,会通过叫做“Taps”的抽象来支持某些实时分析,像获取指标和计数值。从概念上,Taps 让你可以介入到流中,执行实时分析,并有选择地为外部系统生成数据,像GemFire、Redis 或者其他内存数据网格。
一旦你在大数据仓库中拥有数据,那么就需要某种工作流工具来对处理进行调度。调度非常必要,因为你编写的脚本或者map-reduce 作业通常会长时间运行,并采用带有多个步骤的事件链的方式。理想状况下,你需要在事件失败的时候,能够从特定的步骤重新启动,而不是完全从头来过。
最后还需要导出步骤,从而把数据放到更适合展现的系统中,可能还会做进一步的分析。例如从HDFS 到RDBMS(关系型数据库管理系统),在那里你可以使用更为传统的商业智能工具。
Spring XD 想要提供一种统一、分布式和可扩展的服务来满足这些用例。它没有从头开始,而是利用了大量已经存在的 Spring 技术。例如,它使用了 Spring Batch 来支持工作流调度和导出用例,使用 Spring Integration 来支持流处理,此外还使用了各种各样的企业应用程序集成模式。其他关键的 Spring 产品包括:使用 Spring Data 处理 NoSQL/Hadoop 工作,使用 Reactor 为编写异步程序提供简化的 API,特别是在使用 LMAX Disruptor 的时候。
安装 Spring XD
在接下来的部分,我们会详细看一下每个用例。你可能想要自己来试验一下这些例子。起步非常简单。
为了开始,你要确保系统至少安装了 Java JDK 6 或者更新的版本。我推荐使用 Java JDK 7。
对于 OSX 用户,如果还没有 Homebrew 的话,请安装,然后运行:
brew tap pivotal/tap
brew install springxd
这会安装到 /usr/local/Cellar/springxd/1.0.0.M7/libexec (依赖于 Spring XD 的库)。
注意:如果你随后想要安装更新的版本,那么使用 _brew upgrade springXD_ 就可以。
红帽或者 CentOS 的用户可以使用 Yum 来安装。
Windows 用户可以下载最新的.zip 文件,解压,安装到文件夹,然后把 XD_HOME 这个环境变量设置成安装文件夹。
你可以通过键入以下命令,从而在单一节点上启动 Spring XD:
xd-singlenode
键入以下命令来打开另一个终端窗口并启动 shell 程序:
xd-shell
你会看到下面这样的情况:
为了检查它是否正常工作,让我们创建一个快速的流:
stream create --definition "time | log" --name ticktock --deploy
在你启动 Spring XD 的控制台中,你会看到下面这样的显示:

你可以从 shell 中使用 _stream destroy_ 命令删除流。
stream destroy --name ticktock
数据吸纳
流
在 Spring XD 中,基本的流会定义事件驱动数据的吸纳,从源到目的地,经过任意多个处理器。
Spring XD 外壳程序支持针对流定义的一种 DSL,其中带有管道和过滤器语法 - source | processor | sink。
例如,像这样的命令 stream create _–name filetest --definition “file | log” --deploy_ 会记录文件内容的日志。
除了能够处理文件之外,Spring XD 还支持很多其他源,包括:
HTTP
命令 _HTTP POST /streams/myStream “http | file --deploy” -_ 表示“从 HTTP 消费我的流,并转到文件”。这会默认到 9000 端口。你可以使用–port 选项覆盖默认的端口设置。这是针对 HTTP 的唯一参数。
例如(从 XD 的外壳程序):
xd:> stream create --name infoqhttptest9010 --definition "http --port=9010 | file" --deploy
你可以向这个新端口提交一些数据来测试:
xd:> http post --target http://localhost:9010 --data "hello world"
你会在控制台窗口看到以下文本:
> POST (text/plain;Charset=UTF-8) http://localhost:9010 hello world
> 200 OK
打开另一个终端窗口并键入:
$ cd /tmp/xd/output
$ tail -f infoqhttptest9010.out
你会在输出中看到“hello world”。
想要发送二进制数据,你需要把 Content-Type 头部说明设置为 application/octet-string:
$ curl --data-binary @foo.zip -H'Content-Type: application-octet-string' http://localhost:9000
键入 stream destroy infoqhttptest9010 来完成清理工作。
Mail 是用来接收 email 的源模块。根据所使用的协议,它可以以池的形式工作,或者在可用的时候就接收 email。
例如:
xd:> stream create --name infoqmailstream --definition "mail --host=imap.gmail.com
--username=charles@c4media.com --password=secret --delete=false | file" --deploy
注意:这里的 delete 选项很重要,因为对于 Spring XD 来说一旦被消费,默认情况就会删除电子邮件。Spring XD 也拥有 _markAsRead_ 选项,但默认值是 false。 Spring 集成文档中对此做出了详细的说明,但主要问题是,POP3 协议只知道在单独一个会话中读取了什么。作为 POP3 邮件适配器运行的结果,当邮件在每个池中变成可用状态时,就会被成功发送,且没有任何一个邮件消息会被多次发送。然而,当你重启适配器并开始新的会话时,所有位于上一个会话中已经获取过的邮件消息就可能会被再次获取。
如果你在控制台日志中看到这样的错误信息:
WARN task-scheduler-1 org.springframework.integration.mail.ImapIdleChannelAdapter:230
- error occurred in idle task
javax.mail.AuthenticationFailedException: failed to connect, no password specified?
试着在你的 URL 把 @符号替换为 URL 编码的样子: %40:
stream create --name infoqmailstream --definition "mail --host=imap.gmail.com
--username=charles%40c4media.com --password=secret --delete=false | file" --deploy
打开另一个终端窗口并键入:
$ cd /tmp/xd/output
$ tail -f infoqmailstream.out
给你自己发送一封邮件,以看到它在日志文件中显示的内容。
Twitter 搜索
Spring XD 就可以使用 Twitter 搜索 API(twittersearch),也可以使用来自于 Twitter’s Streaming API 的数据。
例如:
xd:> stream create --name twittersearchinfoq --definition "twittersearch
--outputType=application/json --fixedDelay=1000 --consumerKey=afes2uqo6JAuFljdJFhqA
--consumerSecret=0top8crpmd1MXGEbbgzAwVJSAODMcbeAbhwHXLnsg --query='infoq' | file" --deploy
它使用 twittersearch 的 JSON 输出格式,每 1000 毫秒使用令牌“infoq”在 Twitter 中进行查询。为了运行上面的内容,你需要一个消费者密钥(由 Twitter 发放的应用程序消费者密钥)以及它相关的密钥。
它的结果会通过管道以同步的方式传输给一个文件,默认是 _/tmp/xd/output/[streamName].out_。
打开另一个终端窗口并键入:
$ cd /tmp/xd/output
$ tail -f twittersearchjava.out
稍等一会儿,你会发现超出了 Twitter APE 搜索的限制,并且会在控制台窗口中(你在其中在单一节点上启动了 XD)看到这样的消息:
11:27:01,468 WARN task-scheduler-1 client.RestTemplate:581 - GET request for
"https://api.twitter.com/1.1/search/tweets.json?q=infoq&count=20&since_id=478845525597237248"
resulted in 429 (Client Error (429)); invoking error handler
11:27:01,471 ERROR task-scheduler-1 handler.LoggingHandler:145
- org.springframework.social.RateLimitExceededException: The rate limit has been exceeded.
键入 stream destroy twittersearchinfoq 来完成清理工作。
其他输入流
GemFire:在 XD 容器进程中配置一个缓存(cache)和副本区域,它和 Spring Integration GemFire 同时存在于通道适配器中,它们由 CacheListener 支持,而后者会输出区域中外部输入事件所触发的输出消息。它还支持连续的查询,那让客户端应用程序可以使用对象查询语言(OQL)来创建 GemFire 查询,并注册一个 CQ 监听器,它会订阅查询,每次查询的结果集发生变化的时候都会得到通知。
Reactor IP:它会作为服务器,让远程的组织能够连接到 XD,并通过原生的 TCP 或者 UDP socket 提交数据。reactor-ip 源和标准的 tcp 源的区别在于,它基于 Reactor 项目,可以被配置为使用 LMAX Disruptor RingBuffer 库,它能够允许极高的吸纳率,大概每秒 1M。
Syslog:有三种 syslog 源:reactor-syslog、syslog-udp 和 syslog-tcp。reactor-syslog 适配器使用 tcp,会构建 Reactor 项目中可用的功能,并提供超过 syslog-tcp 适配器中更好的吞吐量。
TCP:它会作为服务器,让远程的组织能够连接到 XD,并通过原生的 TCP socket 提交数据。
MQTT:连接到 MQTT 服务器并接收遥测消息。
Taps
在流的任意位置,你都可以插入 tap——这个词来自于 Gregor Hohpe 等人著的《应用程序集成模式(Application Integration Patterns)》一书中的“wire tap”模式。
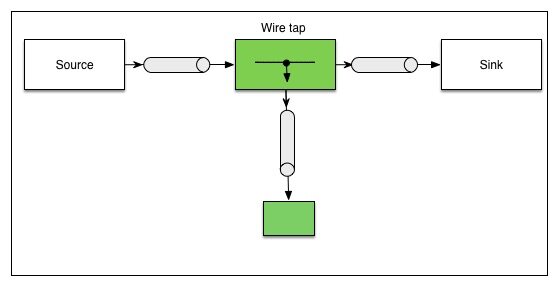
从概念上说,你会在通道中插入一个简单的接收列表,它会把每个进入的消息发布到主通道和次通道中。流并不知道它的管道中任何tap 的存在。删除流并不会自动删除tap——它们需要单独删除。然而,如果加入了tap 的流被重新创建,那么已经存在的tap 会继续起作用。
tap 可以在流的任意位置(或者多个位置)插入。
处理器
流中的数据可以以多种方式处理:
过滤器:它可以用于决定消息是否应该发送给输出通道。最简单的情况是,过滤器只是一个 SpEL 布尔表达式,它会返回真或假。例如:
xd:> stream create --name filtertest --definition "http | filter
--expression=payload=='good' | log" --deploy
会记录带有“good”关键字的所有内容的日志。然而,过滤器也可以相当复杂。Spring XD 支持 JSONPath 计算式以及自定义的 Groovy 脚本。
转换:用来转换消息的内容或结构。它支持简单的 SpEL,对于更复杂的转换,可以使用 Groovy 脚本。
分割器:和 Spring 集成中的分割器概念类似,这里的分割器会使用 SpEL 表达式,它会计算一个数组或者集合的值,从而把单独一条消息切分成多个独立的消息。你可以使用 JSON oath 表达式,但无法使用自定义的 Groovy 脚本。
聚合器(Aggregator):和分割器相反,它会把多条消息组合成一条。
最后是脚本,可以用于调用特定的 Groovy 脚本作为处理步骤。
槽(Sinks)
最简单的槽是日志和文件。其他可以支持的槽包括 Hadoop(HDFS)、JDBC、TCP、Mail、RabbitMQ、GemFire 服务器、Splunk 服务器和 MQQT。还有一个动态路由选项,允许基于 SpEL 表达式或 Groovy 脚本的值,把 Spring XD 消息路由到命名通道中。让我有一点奇怪的是,在这里缺少一般目的的 JMS 槽,尽管我们可以像 https://github.com/spring-projects/spring-xd/wiki/Extending-XD "> 这里描述的一样构建自定义的槽模块。
实时分析
Spring XD 为各种机器学习评分算法的实时计算提供了支持,还为使用各种类型的计数器和计量器进行实时数据分析提供了支持。分析功能是通过可以添加到流中的模块实现的。在那种情况下,实时分析是通过和数据吸纳一样的模块完成的。
尽管流的主要角色可以是执行实时分析,但更为常见的是添加一个 tap 来初始化另一个流,其中分析——例如:一个字段值的计数器——会应用给通过主要流吸纳的同样数据之上。
Spring XD 中自带提供了一些简单的分析工具,它们都实现为抽象 API,针对内存数据库和 Redis 而实现,如下:
- 简单计数器
- 字段值计数器:计算特定字段出现的次数。
- 聚合计数器: 在 Mongo 和 Redis 之类的工具中比较常见,让你可以对数据根据时间——例如分钟、小时、月、年等——进行分片。
- 计量器(Gauge):最新的值
- 富计量器:最新的值,运行的平均值,最大、最小值
对于预测性的分析,Spring XD 包含了一个可扩展的类库,基于它可以构建其他实现。例如在 GitHub 上提供的 PMML 模块,它和 JPMML-Evaluator 库集成,为更广范围内的模型类型提供了支持,并且可以与从 R 、 Rattle 、 KNIME 和 RapidMiner 导出的模块进行互操作。
产品还包含了一些抽象,可以在流处理应用程序中事件分析模型。在撰写这篇文章的时候,只支持预测性模块标记语言(Predictive Model Markup Language,PMML),但 Pivotal 告诉 InfoQ:
我们正在进行一个内部项目,以提供广泛的分析解决方案,它的目标是围绕“欺诈检测”和“网络安全”之类的情况。我们还在与 OSS 库——像“ stream-lib ”和“ graphlab ”——的整合做了一些设计。
Pivotal 还说明,他们期望,随着时间的推移能够在这个领域看到发展,并且对预测性建模提供额外的支持。
批处理作业、工作流调度和导出
除了流之外,Spring XD 还包含了基于 Spring Batch 启动和监控批处理作业的功能,而 Spring Batch 也被用于支持工作流调度和导出用例。
工作流的概念会被转换成批处理作业,那可以被认为是各个步骤的有向图,每个图都是一个处理步骤:
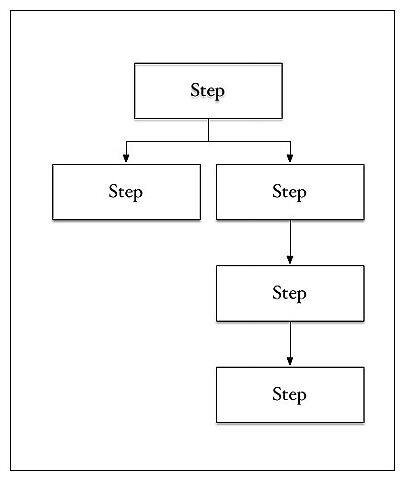
根据配置的情况,步骤可以顺序或者并行执行。它们可以复制或者处理来自于文件、数据库、MapReduce、Pig、Hive 或 Cascading 作业的数据,并且和允许重启的检查点一起持久化。和流一样,作业支持单节点,或者可以和数据分区一起分布。
Spring XD 自身带有少量预定义的作业,可以用来向 Hadoop 文件系统 HDFS 导出数据,或者从中导入数据。这些作业覆盖了 FTP 到 HDFS、HDFS 到 JDBC、HDFS 到 MongoDB 和 JDBC 到 HDFS。还有一个作业用于向 JDBC 导出文件。你可以在 _/libexec/xd/modules/job_ 文件夹中找到。
Spring XD 提供了相当基础的、基于浏览器的图形化界面,当前让你可以执行和任务相关的批处理作业。对于启动 Spring XD,管理员界面在这里提供:
(点击图像可以放大)

正如在上面的截屏中可以看到的,管理员界面当前包括四个标签页:
- 模块:列举了可用的批处理作业和更多细节(像作业模块选项以及模块的 XML 配置文件)。
- 定义:列举了 XD 批处理作业定义,并提供了部署或者卸载那些作业的动作。
- 部署:列举了所有部署了的作业,并提供了一种选项来启动部署好的作业。一旦作业已经部署,它就可以通过管理员界面启动。
- 执行:列举了批处理作业的执行状况,并提供了一种选项,如果批处理作业可以重启,并且处于停止或者失败状态,那么就重启。
结论
Spring XD 当前还处于开发中。第一个里程碑版本已经在 2013 年六月发布,而 GA 版本期望在今年(2014 年)七月发布。它基于 Apache 第二版许可。在 GitHub 上提供了源代码和示例。你还可以找到在线的 Sonar 代码度量。
产品可能还很新,但正如我们看到的,它构建在成熟的基础之上——Spring Batch、Spring Integration 和 Sping Data,以及 Reactor 项目、LMAX Disruptor 和 Apache Hadoop——并提供了一种轻量级的运行时环境,可以通过 DSL 来配置和集成,只需要很少代码,甚至不需要。Spring XD 为开发者提供了一种便利的方式,可以开始构建大数据应用程序,为构建和部署这样的应用程序提供了“一站式服务”。
对于想要探索这个产品的读者,有大量资源可用,包括主要的 wiki ,还有覆盖了实时分析的视频。
关于作者
 Charles Humble从 2014 年三月开始担任 InfoQ.com 编辑团队的主编,引领我们的内容创建工作,包括新闻、文章、书籍、视频和采访。在全职加入 InfoQ 之前,Charles 领导过我们的 Java 部分工作,是 PRPi 顾问公司的 CTO,该公司是一家简历研究公司,在 2012 年七月被 PwC 收购。他作为开发者、架构师和开发经理在软件企业中工作了近 20 年。在空闲时间,他会写一些音乐,并且是伦敦周边的技术小组 Twofish 的成员。
Charles Humble从 2014 年三月开始担任 InfoQ.com 编辑团队的主编,引领我们的内容创建工作,包括新闻、文章、书籍、视频和采访。在全职加入 InfoQ 之前,Charles 领导过我们的 Java 部分工作,是 PRPi 顾问公司的 CTO,该公司是一家简历研究公司,在 2012 年七月被 PwC 收购。他作为开发者、架构师和开发经理在软件企业中工作了近 20 年。在空闲时间,他会写一些音乐,并且是伦敦周边的技术小组 Twofish 的成员。
查看英文原文: Introducing Spring XD, a Runtime Environment for Big Data Applications




