本文源自 3 月 9 日『高效开发运维』微信群的在线分享《360DoctorStarange:集预测、处理、关联和资源优化于一体的智能运维系统》,分享者为 360 的运维开发工程师籍鑫璞,转载请在文章开头注明来自『高效开发运维』公众号。加群学习请关注『高效开发运维』公众号,并点击菜单中的“加群学习”或直接回复“加群”。
DoctorStarange 背景介绍
为了保证 360 公司内部的私有云平台的稳定性和可靠性,我们部门开发了监控系统--wonder 来监控系统的状态。但是随着业务量的增加,通过设置单纯的阈值来监控报警是远远不够的。而且这种被动式的触发报警很多时候需要人工去处理。
我们提出来 DoctorStarange,它是一个智能的预测和处理系统,能够提前预测出一些监控项的报警,并提前处理预测的报警,最大程度减少报警次数;它是一个关联不同报警项的系统,能够帮助运维人员去更快地排查报警;它还是一个对机器各个维度进行检测的系统,能够优化机器资源。
下面分三个部分对该系统进行介绍:首先介绍智能预测与处理系统,然后介绍报警关联分析,最后引入机器健康度的概念,来及时了解机器的运行状况,最大化机器资源的利用率。
智能预测与处理系统
我们对监控项的历史数据进行分析后就会发现,有些监控项的历史趋势的增长(或下降)趋势趋于稳定,如磁盘空间使用率,而有些监控项的趋势就波动的比较厉害,如 cpu、网卡流量等。对于这两种趋势,我们需要使用不同的预测模型对未来一段时间的趋势进行预测。预测只是第一步,如果预测后能让机器自动处理一些危险的监控项,就可以最大程度上减少人工干预。
下图是我们智能预测与处理系统的框架图
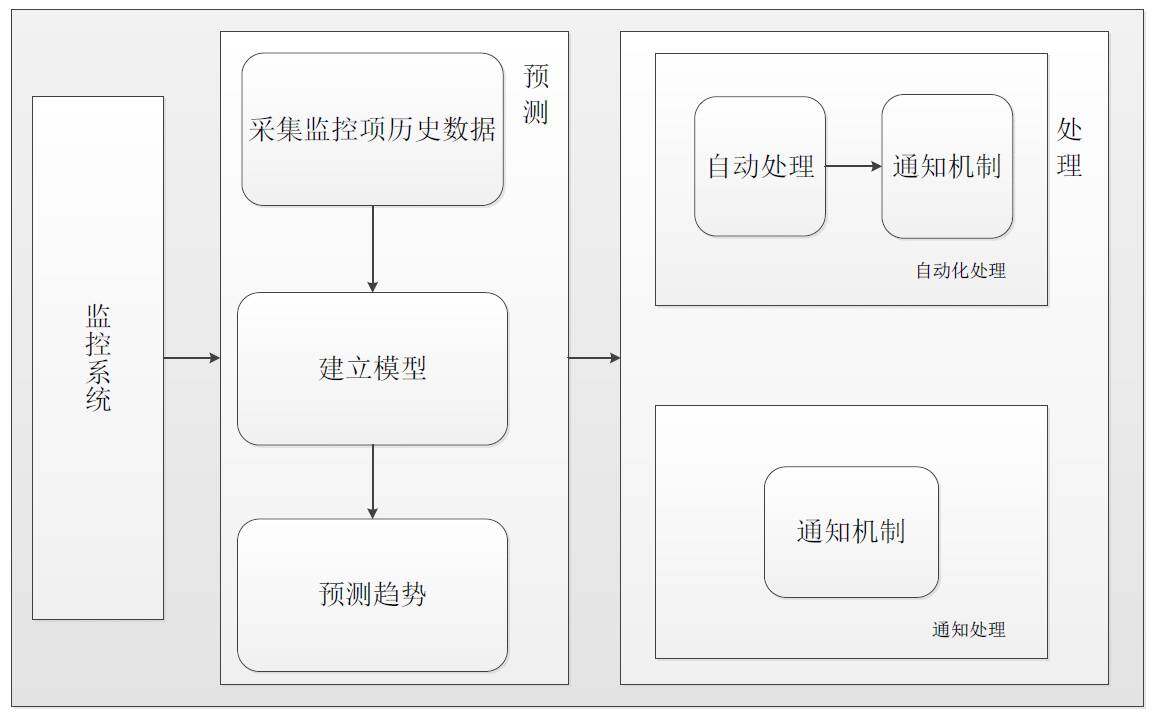
趋势稳定的监控项的预测与自动化处理
应用系统出现故障通常不是突然瘫痪造成的,而是一个渐变的过程。本节我们将结合磁盘空间使用率来说明我们的系统如何做到智能预测与处理。很明显,磁盘预测工作应该分为两部分,一部分是预测,另一部分是处理,具体的流程:
首先说一下预测。系统长时间运行,数据会持续写入存储,存储空间逐渐变少,最终磁盘被写满而导致系统故障。由此可见,在不考虑人为因素的影响时,存储空间随时间变化存在很强的关联性,且历史数据对未来的发展存在一定的影响。所以可以采用时间序列分析法对磁盘容量进行预测分析。
我们使用 ARIMA 模型来处理时间序列,ARIMA 涉及到三个参数:p(自相关系数),q(偏自相关系数)以及 d(差分次数)。差分次数可以使用 ACF 函数来检测差分后该序列是否为平稳序列,而 p 和 q 可以使用 AIC 或者 BIC 准则来得到使 AIC 或者 BIC 信息量达到最小的模型阶数。
有人可能会问这个系统可能依赖于预测模型的准确率。为了验证模型的准确率,我们提出来两个概念来说明效果:
- 预测准确率:预测准确率 = 预测报警且具有报警趋势的机器数 / 预测报警的机器数
- 报警减少率:预测覆盖率 = 预测报警且真正报警的机器数 / 报警的机器数
我们对线上 20000+ 台机器未来 24 小时的走势进行预测,跟踪了将近一个月的预测结果。可以发现我们的模型预测准确率能够达到 100%,报警减少率能够达到 70% 左右,这说明我们的模型能够获得比较好的效果。
接下来将重点介绍在预测磁盘使用率将要达到阈值后,我们如何自动处理的过程。用户可以根据自己的意愿选择处理类型:一种是自动处理,一种是通知邮件。
如果是自动处理类型,我们会清理 100% 可以确定删除的日志文件,比如 allweb 文件以及一些归档的日志文件。虽然我们有一定的目录规范和定期的日志轮转,但是因为有些程序编写的不规范,业务访问量的增长,还是会有磁盘被写满的情况,所以单纯依靠自动清理会有一定的风险,所以我们还有一种是通知邮件,我们会定期将扫描出来的占用空间比较大的文件信息发送给用户,由用户自己去处理。
波动剧烈的监控项的预测与故障定位
和磁盘这种趋势稳定的监控项不同的是,波动剧烈的监控项由于历史数据变化情况比较复杂,采用传统的 ARIMA 或者指数平滑的方法很难达到比较好的效果,因为他们很难捕捉到以前从未出现过的情况。相反,神经网络模型由于输入的是非线性方程,可以处理更复杂的时间序列。对于 cpu 预测,我们也分了两个过程:预测以及故障定位。
本节采用神经网络模型去预测 cpu 的走势,提前预测出将要发生报警的机器,尽可能将具有隐患的故障扼杀在摇篮中,提高系统的可靠性和可用性。
建立神经网络模型,首先要确定输入、隐藏和输出层的神经元个数。由于我们的线上业务具有天的周期性,所以我们将输入层的个数设为 24(当然这个值也可以通过求自回归系数来求得),隐藏层的个数一般为输入层个数乘以 2 再加 1,所以输出层为 49,输出层的个数为 1,,我们根据此规则建立模型。
和趋势稳定的监控项的预测准确率和报警减少率一样,我们也预测了波动剧烈的监控项的未来一个小时的趋势,同样的机器数量,我们的预测准确率能够达到 80% 左右,报警减少率能够维持在 50%。由于波动剧烈的项相比于趋势稳定的项来说,不太容易预测,能够一定程度减少报警也可以达到比较好的效果。
接下来说明预测报警后,如何进行故障定位。我们会根据 top 值来找到占比比较高的进程,由于直接处理占比比较高的进程会有风险,所以我们只会邮件通知负责人以及运维人员。
以上我们以磁盘使用率和 cpu 为例子介绍两种不同趋势的监控项的预测以及处理工作,其他具有此特征的监控项的思路类似,在此就不一一展开。
报警关联分析
随着监控系统监控项的数目越来越多,报警的次数也会随之暴增。不同报警项他们之间并非孤立的,而是存在着千丝万缕的联系。我们分析出某一时间段内协同发生变化的监控项,能够帮助我们排查出问题,找到问题的根源。报警关联分析系统主要做了两件事情:报警系统:加入报警合并算法,能够减少报警次数;实时报警分析:找到存在因果关系的监控项,帮助排查问题;下图是我们报警关联分析系统的框架图:
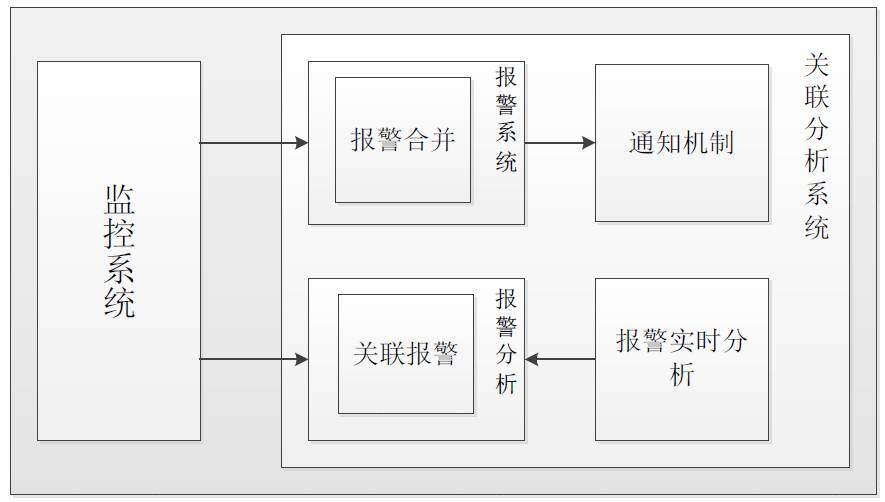
怎样去找到关联项呢?我们根据自相关系数来获得该段时间内发送波动的监控项。一起发生波动的项可能非常多,通过求曲线斜率的方法来获得各个波动项的波动剧烈程度,并按照波动剧烈程度排序。利用均值波动法获得波动持续的时间。在综合考虑波动剧烈程度和持续时间后,我们可以给每个波动项赋予一定的权值,并由此得出正关联和负关联的项。
现实场景中,单纯依靠当前的数据来得到相关联的项可能不太准确,这时候我们就需要一个自学习的关联分析系统,通过老 case 和人工经验的加入,该模型得到不断地修正和补充,因而会获得比较好的效果。
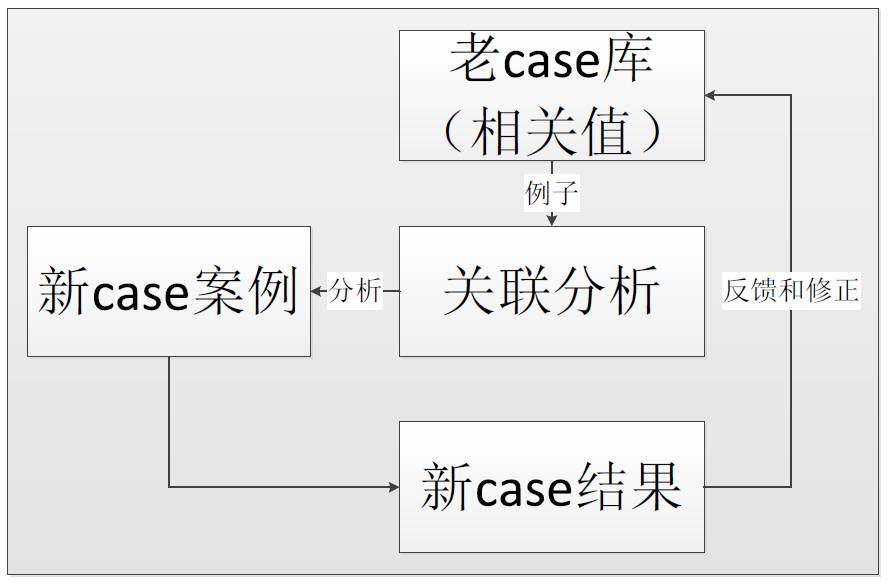
对于报警系统,我们主要找到正关联系数比较高的监控项,来合并一些报警之后,以最少的报警次数通知给用户。而对于实时报警分析,我们就可以通过输入一个波动项(原因),找到由此原因导致的其他波动的项(结果)。
机器资源优化方案
面对不同业务的机器使用程度不同的问题,如何在不影响业务的同时,最大化机器资源利用率越来越成为业界比较关注的话题。我们不能使机器使用率过高,同样也不能使机器利用率过低,因此我们提出来一个“机器健康度”的概念,该值会反映出该机器过去一段时间内重要指标的使用情况。
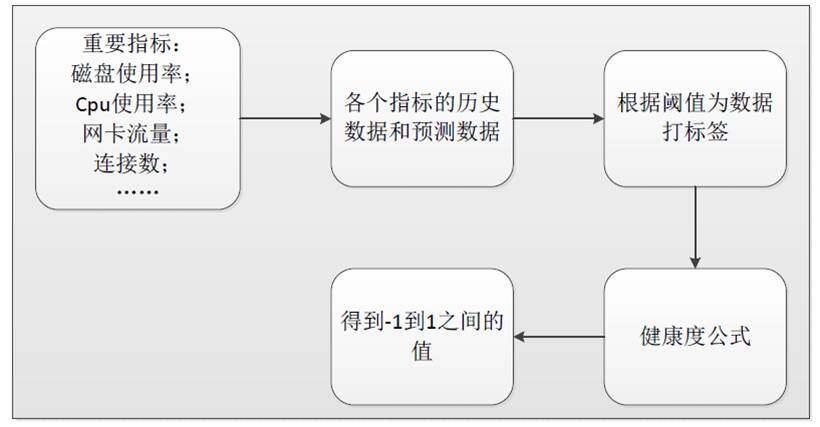
首先,如何选择机器指标?在我们的方案中,我们选择 cpu 空闲率、内存使用率、网卡流入流量、网卡流出流量和状态连接数作为考量因素。之所以选择这几个指标是因为这几个监控项能够总体反映出机器的负载情况。
我们分别通过阈值的方法为这六个监控项设置上限和下限后,针对于每个监控项我们得到了四个值:
- 历史数据的均值上限
- 历史数据的均值下限
- 预测数据的均值上限
- 预测数据的均值下限
经过一个公式计算后,我们将得到一个 -1 到 1 区间内的一个值,即为健康度。如果该值越接近于 -1,则说明机器比较空闲,如果该值越接近于 1,表明机器使用率比较高。
下图说明了我们方案实施的具体流程:
健康度的概念毕竟是一个学术的东西,我们如何将此概念应用到实际的场景中呢?下面将介绍我们具体的应用场景:
场景一 动态扩容和缩容
设置 cron 任务,比如每隔一周全量跑一次线上的机器,将有问题的机器录入到数据库中。 该数据库可以用于以下方面:
- 资源回收的依据(关注健康度值为 -1 的机器)
- 业务扩容的依据(关注健康度值为 1 的机器)
场景二 机房物理拓扑(及时了解机房机器的健康状况)
场景二是我们针对于运维人员经常不能了解线上机房机器的运行状况做得一个拓扑图。在该拓扑图里面,运维人员可以更方便知道机器的总体运行状况。而我们可以以上面提到的“机器健康度”来表示每个机器现在的运行状态。如下图是我们一个简单机房的物理拓扑,在图中,白色的机器表示该机器运行良好,红色的机器表示该机器使用率过高,而灰色的机器则表示该机器使用率过低。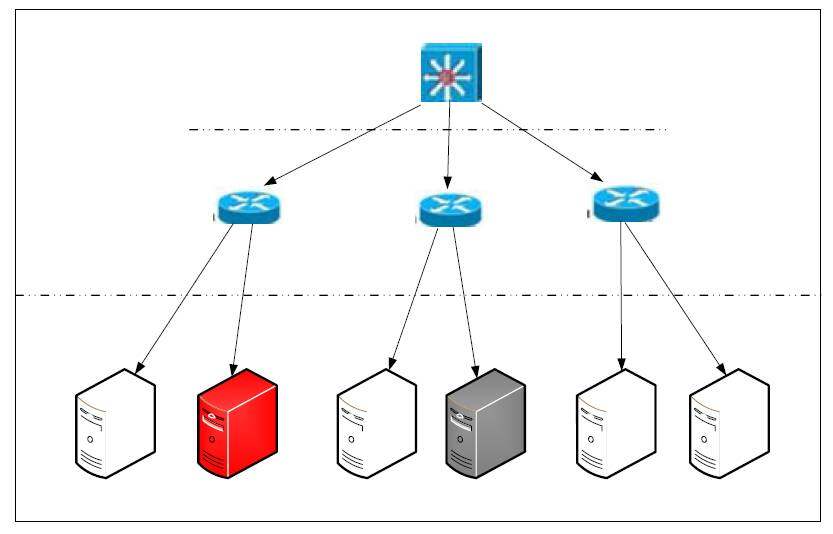
今后方向
- 业务拓扑:业务四层和七层的拓扑图。
- 报警自发现:报警后结合关联分析和分析算法找到问题的根源。
QA 环节
Q1:第一部分预测后自动处理能举一个例子吗?
A1: 比如磁盘空间使用率,在有比较好的预测模型后,预测出将要发生故障的机器后,会有两种处理策略:一种是自动清理,我们会处理一些日志文件(绝大部分的磁盘空间是因此导致的),当然如果觉得不稳妥,我们可以将占比比较高的文件信息发送给用户,由用户来自己处理。
Q2:感谢分享,请问能否说一下你们使用的报警合并算法?你们会发送并处理所有的报警吗?
A2: 第一个问题:我们的报警合并算法是考虑该报警发生的一段时间内,综合每个波动剧烈程度和持续时间后,给每个波动项赋予一定的权值,并由此得出正关联,我们会选择关联系数比较高的项进行综合。第二个问题:我们现在只做了磁盘使用率和 cpu 发生报警后如何去处理,我们接下来会做报警自发现的模块,这是我们后期的一个目标。
Q3:请问你们采用的什么技术、语言进行的神经网络模型搭建?
A3: 我们使用 python 里面的 pybrain 这个算法包去搭建的模型。
Q4:能推荐一些监控技术相关的比较好的书籍和学习资料吗?
A4: 我们团队有专门的做监控的同事,他们使用的是小米的开源监控系统 open-falcon,建议从开源系统学起。
Q5:自学习的关联分析系统,通过老 case 和人工经验的加入,该模型得到不断地修正和补充,能不能详细的说明下,最好能举一个案例,谢谢
A5: 先说老 case 吧,将以前的有关联关系的结果保存在 case 库里面;人工经验比如某个机器的网络流量突增有可能导致 cpu 的上升,有可能单纯依靠算法无法达到好的效果,case 库需要不断的丰富。
Q6:是通过什么手段识别误告警的?如何保证关键告警不被其他告警覆盖掉?
A6: 这个只是辅助手段,最大限度减少报警,报警关键还是人来识别。
Q7:报警自发现和异常检测,我们也很感兴趣,请问能简单介绍下思路吗?
A7: 先说异常检测吧,最近看到一个开源技术估计对你们有帮助:Skyline timeseries 异常判定算法,有兴趣可以看一下。报警自发现:这个就是找到问题的根源,比如 cpu 报警,可以通过查看 top 来找到是什么进程导致 cpu 报警。
Q8: 动态扩缩容基于什么实现的?如何衡量整个系统的瓶颈?扩了一部分,引起其它模块压力上升甚至崩溃
A8: 预测和健康值只是给出评估需要扩容的建议,并没有真正执行,决策还是需要业务负责人去定。比如说某些业务下机器都比较忙,那就需要扩容。
Q9: 神经网络模型的输入,隐藏层,输出层具体使用哪些参数数据
A9: 输入层是跟踪自相关系数得到的,比如通过求 1,2……,7 得到 7 天的自相关系数最高,那么输入层就可以知道了,而隐藏层一般是输入层的 2 倍加 1,输出层是你想要预测的时间窗口。推荐你看一篇论文:PRACTISE: Robust Prediction of Data Center Time Series
Q10:除了你提的 CPU 使用率等监控项是简单可衡量的,还有哪些监控项是你们的监控目标?
A10: 我们的监控项不只是 cpu,磁盘这样的普通监控项,它会涉及到硬件、软件各个层面。我们的监控系统还加入了一个自定义的监控功能,更丰富了业务需求。
Q11:您好,老师,你们这么大的体量,能介绍下你们运维部门的组织结构和规模吗?
A11: 我们属于奇虎 web 平台部 addops(应用运维)团队
Q12:在一开始做选型的时候你们是否考虑过 ZABBIX、Nagios 或者 Open-falon,能说说你们在选型时的一些考虑不
A12: 这属于基础监控范畴,有专门同事在做,以后有机会可以让他们分享一下。
Q13: 感谢分享。请问你们的网络拓扑是如何实现的?根据什么数据制作的。这些数据怎么来的?
A13: 这些数据是从我们公司网络部门的接口获得,他们会有机器直接的流量。
作者介绍
籍鑫璞,毕业于南开大学,360 公司运维开发工程师,参与 web 平台智能运维系统、业务拓扑和 APM 等项目的开发工作。
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




