持续集成(Continuous Integration)是一种软件开发实践,它倡导开发团队频繁地进行系统集成,每一次的集成都可以通过流水线(Pipeline)快速验证。和传统的集成方式相比,持续集成可以有效地缩短反馈周期、提高软件质量、降低开发成本。这种开发实践也越来越为更多的开发者所接受。对于一个有七年历史的项目,非常幸运的是我们在项目刚开始就使用了持续集成,这也是我们可以长期、稳定地给客户交付高质量软件的保障之一,但是有时我们在项目中也经常会听到一些这样的声音:
- 每次想提交代码的时候都没有机会, 我们是不是要考虑引入提交“令牌”机制,拥有“令牌”的人才能提交
- 这个 Pipeline 已经挂了这么久了,今天估计是无包可测了
- 这个是测试“随机挂”,重新触发一下 Pipeline 就好了
- 我的提交 Break 了 Pipeline 了吗?我确认一下
- ….
通过分析我们发现,这些声音背后的真相更是残酷:
- 约 20 对 Pair 依赖的核心 Pipeline 构建时间超过 1 个小时,开发的反馈周期长,大量的半成品积累在本地开发环境和 Pipeline 上
- 代码提交之后大约需要 2 个小时才能出包,每周平均每天可供 QA 测试的包数量不足 1 个,平均每个 Story 的周期时间长
- 上线前冻结代码、回归测试的时间大约需要 2 周左右,冻结期间产生的代码无法集成、验证
- Pipeline 不稳定测试导致某些 Pipeline 构建至少需要重新触发 2 到 3 次左右
- 依赖关系复杂,牵一发而动全身,优化不知从何做起
有时“正确地做事情”比“做正确的事情”还要困难,在项目一开始便在项目中尝试实施 TDD 等敏捷开发实践,但是随着项目的规模的增加,功能越来越丰富,单元测试在增加、基于 UI 的功能性测试也在增加,流水线的构建速度却变得越来越慢。微服务架构具有易扩展,技术选择灵活和部署独立等特性,于是我们把应用拆分为不同的微服务,但是同时也带来了流水线的数量和微服务之间集成测试的增加,Pipeline 的依赖关系也变得越来越复杂。
在去年,项目中的 DevOps 小组,在前人的基础上和团队便大刀阔斧地开始了 Pipeline 的改进工作,希望可以通过一些必要的措施,优化流水线,保证 QA 每天有包可测、缩短开发期间的反馈周期。
改进什么?
这是我们在改进刚开始就面临的一个问题,本地 Pipeline 数量众多,每一个 Pipeline 平均有 3-4 个构建阶段,每一个阶段又有 2-3 个并行执行的任务,如此众多的 Pipeline 和任务,应该从什么地方着手?面对 Pipeline 构建时间长、测试不稳定、代码冻结时间长,依赖关系复杂等问题,应该如何决定改进的优先级?根据高德拉特的约束理论(ToC),所有在非约束点的改进都是假象,我们可以把整个构建流水线看作是一个完整的系统,如果我们改进的是约束点的上游,就会增加约束点的负担;如果我们改进的是约束点的下游,由于通过下游的工作量主要由约束点决定,所以任何在这个位置的改进都是徒劳无获,无益于整个系统产出的提高还造成了浪费。
现状问题树是寻找约束点的方法之一,借助于这个思维过程(Thinking Process)可以帮助我们梳理“不良效果”(Undesirable Effects )之前的因果关系,最后找到需要解决的核心问题,解决了根本问题之后,由其衍生的各种“不良效果”也大多会消失。通过内部的讨论和演练,我们最终把问题定位在以下几个方面:
- 核心 Pipeline 构建时间过长
- 集成环境测试成功率低
- 缺少必要的监控预警机制
如何改进?
降低资源的占用时间
在零件制造车间中,每一个零件都需要按照既定工序通过车、镗、铣、磨、刨等车床,每一个阶段都需要占用车床资源进行特定的加工工作。和零件加工类似,来自客户的每一个功能性需求也同样要经过类似处理流程,从需求分析到编码开发,从构建打包到部署测试,每一个环节都需要占用一定的资源。如果在单位时间内,资源占用的比率越高,就会产生比较严重的排队现象。如下图所示,在单位时间内如果资源占用大于百分之七十,队列的长度也会呈指数型增长。
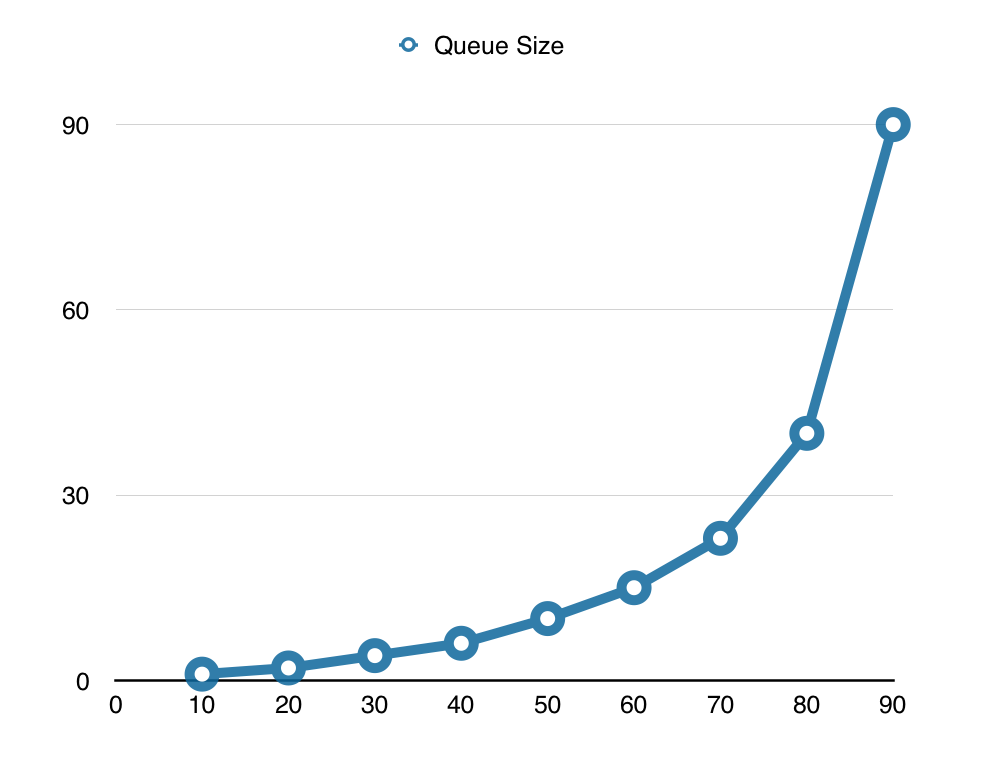
Pipeline 作为整个软件交付流程重要的一环,如果每次构建资源占用比例过高,会导致大量的代码积压在开发环境等待构建、验证和打包,“在制品”数量也越来越多,而过多的“在制品”恰恰就是软件交付延期的隐形杀手之一。解决对 Pipeline 资源占用比例过高的途径只有一个:加速处理“在制品”的流程。在改进的过程中我们总结出了以下几种主要的加速手段:
- 并行化
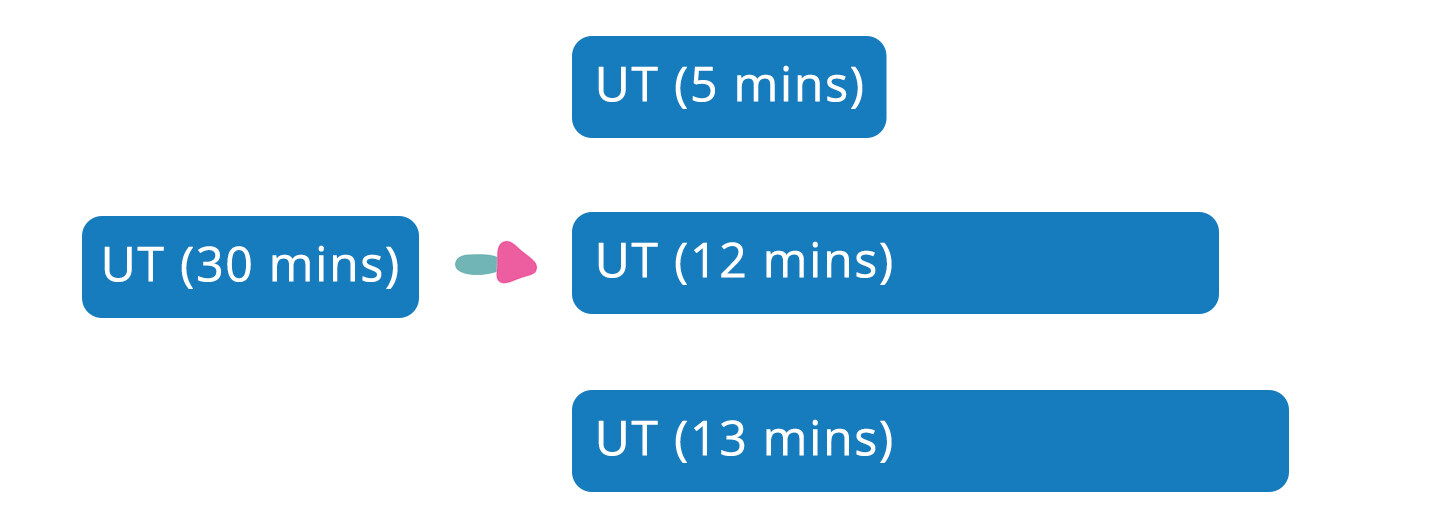
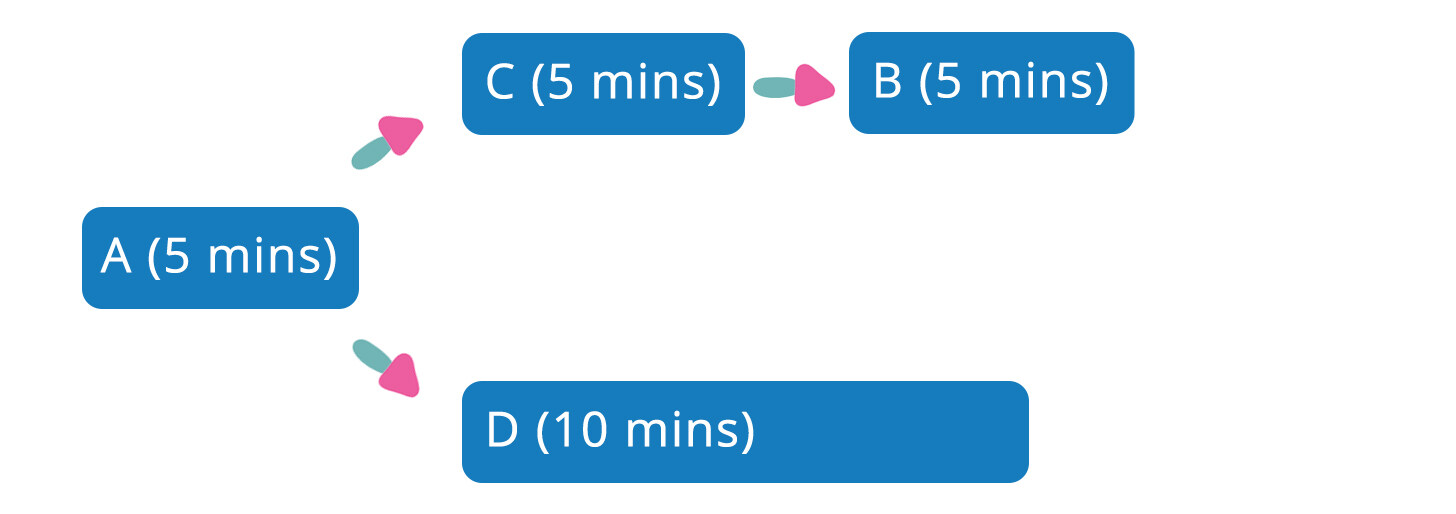
假设 Pipeline 单元测试需要 30 分钟才能运行结束,可以通过切分单元测试多进程并发执行,如下图所示,可以节省近 20 分钟的运行时间:
同样也可以把并行化用于优化 Pipeline 结构,如下图所示,通过减少不必要的 Pipeline 依赖关系,让不同的 Pipeline 并行执行,可以减少大约五分钟的端到端的构建时间。
优化前: 端到端构建时间 20 分钟
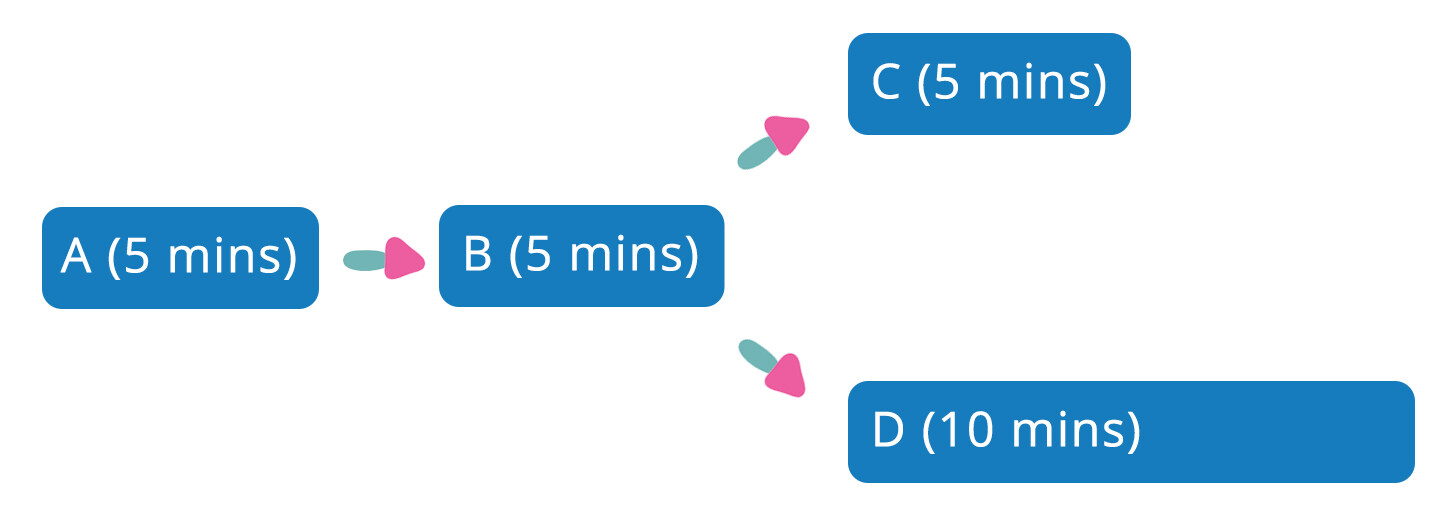
优化后:端到端构建时间 15 分钟
2. 使用 Mock 或者 Stub,隔离真实服务
对于有数据库依赖的单元测试,如果在运行期间连接真实的数据库,读写速度会比较慢,除了 IO 操作之外,为了保证不同测试之间的隔离性,往往还需要考虑测试运行之后的数据清理工作,而这也会带来一部分的性能损耗。针对这种情况,可以考虑使用内存数据库替代真实的数据库,在提升 IO 操作的同时,数据清理工作也变得很简单。
为了保证代码的修改没有破坏现有的功能,一般我们会增加基于 UI 的回归测试,在测试运行之前部署当前应用以及其所依赖的各个服务。对于应用依赖的服务的部署和 API 调用,也会消耗部分时间。这是可以考虑使用 Sinatra 、 Moco 等工具隔离部分第三方服务,从而缩短部署时间和 API 的调用时间。
但是隔离真实服务的同时也掩盖了测试替身和真实组件之间的差异性,比如我们在 API 测试中使用 Sqlite 替代 SQL Server,但是 SQLite 并没有datatime字段类型,需要在测试代码中需要做额外的映射配置,这种差异性同样也会导致潜在的产品缺陷。所以我们在选择 Mock 或者 Stub 时需要权衡利弊,如果使用则需要额外的手段来验证这种差异性。
3. 优化基础设施和运行环境
增加硬件配置如 CPU,内存、替换固态硬盘等也可以一定程度地降低 Pipeline 的构建时间。对于由于语言或者框架本身带来的性能约束,也可以通过升级到新版本来解决,比如把 Ruby 从 1.8.7 版本升级到 2.0 版本。
提高构建成功率
团队在改进的过程中发现可以通过下面的公式大致估算出平均每天 Pipeline 产出的可用包的数量:

根据这个公式,如果要增加平均每天出包的数量,除了降低每次构建的时间之外还需要提高 Pipeline 的构建成功率,而影响构建成功率最常见的问题就是“非确定性”测试。在项目的 Pipeline 上曾经出现过下面这些情况:
- 一些 UI 测试每次至少需要被重新执行一次才能通过
- 部分单元测试在特定的时间段会稳定失败
- 构建结构和测试被执行的顺序有关
Martin Fowler 在 Eradicating Non-Determinism in Tests 中指出了这种非确定性测试存在的两个问题:首先它们属于无用测试,由于测试本身的不确定性,它们已经无法用来描述、验证对应的功能。测试运行的结果也无法给开发人员提供正确的反馈,如果测试失败,开发人员无法直接判断这个测试是由于产品缺陷导致还是由于非确定行为导致。其次这些测试就像“致命的传染病菌”一样,降低正常测试的存在价值。假设一个测试套件中有 100 个测试,其中 10 个测试为非确定性测试,这些非确定测试会给开发团队带来很多的“噪音”,团队对于 Pipeline 失败会觉得司空见惯、习以为常,剩余 90 个测试的作用也会大打折扣。
- 保证隔离性
在 Pipeline 的结构方面,由于非确定性测试的“传染性“,在着手解决非确定性测试之前可以考虑从测试套件中隔离这种类型的测试,这种隔离一方面可以保证正常的测试可以继续提供正确的反馈,另一方面也方便开发人员解决非确定性的测试问题,如果被隔离的测试失败,只需要重新执行部分测试而不是整个测试套件,很大程度地缩短了修复过程中的反馈周期。

从测试代码级别也需要保证不同测试之间的隔离性,构建的结果不应该依赖于测试被执行的顺序。在优化过程中我们遇到过这样的情况:基于 UI 的功能性测试依赖于一部分用户基础数据,其中测试 T1 在运行过程中需要修改特定用户的角色,在测试 T2 需要使用该用户完成其他的业务操作。如果 T1 在 T2 之前执行可以构建成功,反之则会构建失败。解决这类问题通常有两种做法,测试运行之前创建不同的用户或者测试运行结束之后恢复用户数据。对于第二种方法,如果当前测试没有正确地清理数据会导致下一个执行测试失败,增加了定位问题的难度,所以更推荐使用前者来保证不同测试之前数据隔离。
2. 增加必要的等待
在 UI 测试中很多操作都依赖于页面元素出现的时间、位置等,在不同的网络环境、机器性能不同,页面的加载速度也不一样,测试运行的结果也会有所不同。通常 web driver 会提供一系列的方法来帮助开发者判断元素是否已经加载完成、是否可见、页面是否已经加载完成等(比如Watir的when_present, wait_until_present等),在测试代码中合适的地方使用这些方法可以让测试代码更加健壮,从而提升 Pipeline 构建的成功率。
3. 正确测试异步行为
系统中的异步操作可以为用户提供更好的使用体验,系统不需要等待当前操作完成就可以继续处理其他操作,但是异步操作也增加了测试的复杂度。在项目的集成测试代码中我们发现类似这样的等待操作:sleep 10, 这种原始的等待策略不够稳定,对于网络状况、机器性能、数据量等外部因素依赖较大。回调(callback)和轮询(loop)是两种推荐的测试异步的方法,回调不会有任何尝试任何多余的等待时间,但是使用场景比较有限;轮询通用性更高但是会产生一定的多余等待时间,对于轮询操作,建议使用更小的等待时间间隔(interval)和重试(retry)上限。
调整测试结构
不合理的测试结构也是影响 Pipeline 性能的重要因素,根据测试金字塔理论,就测试数量来说,从低层级到高层级的测试需要保证金字塔状的结构。测试的运行时间呈现的却是一个倒金字塔状,测试的层级越高测试运行的时间越长,对应 Pipeline 的构建时间也越长。所以改进 Pipeline 也可以从调整测试层级结构开始。
- 梳理业务流程,简化测试结构
新的功能在不断增加,已有的需求也不断在变动,产品本身也不断接受来自最终用户和市场的反馈,现有的测试有可能并没有覆盖那些最有价值的场景而已经覆盖的场景也许在真正的产品环境下使用率很低;有些场景已经在低层级的单元测试覆盖,在高层级测试中出现了很多重复的用例。
调整测试结构可以和领域专家一起,重新梳理业务流程,把测试的重点放在那些最有价值的业务场景上,在高层级增加适当的 UI 测试保证核心功能没有被破坏。对于出现重复或者价值不大的测试,可以考虑删除高层级的测试,用更多的单元测试来替代,从而降低测试的运行时间。关于自动化测试更多的优化手段可以参考一个遗留系统自动化测试的七年之痒。
除此之外还需要构建有效的反馈回路,通过 Google Analytics 等网站分析平台收集来自于最终用户和市场的数据、用户使用习惯、时区语言等地域性信息对应地调整现有的测试结构,让测试环境下的业务场景更加接近真实的产品环境。
2. 用契约测试替代集成测试
Integrated tests are a scam. A self replicating virus that threatens the very health of your codebase, your sanity, and I’m not exaggerating when I say, your life.” - JB Rainsberger
JB Rainsberger 的这个说法一点也不夸张,在项目中总是有关于集成测试的各种“吐槽”,构建时间慢、问题难以复现和定位、修复难以验证、不稳定等。而契约测试就是那个可以拯救你,让你脱离“苦海”的利器。
契约测试是“单元级别”的集成测试,基于消费者驱动的契约测试把契约测试分为了两个阶段:消费者(Consumer)生成契约和提供方(Provider)验证契约,在生成契约时通过Mock隔离真实的服务提供方,运行单元测试生成用JSON描述的契约文件;服务端验证只需要部署自身就可以验证契约文件的正确性。
契约测试有很多优点,首先它不依赖于完整的集成环境,部署成功率高,其实在测试运行期间无真实的 API 调用和模拟的 UI 操作,测试运行的速度快,成功率高;而且在本地开发环境就可以验证契约测试,问题容易定位,修复的反馈周期短。引入契约测试不但给 Pipeline 性能带来大幅度的改善,还可以提升整个团队的开发效率。
如何保护改进成果
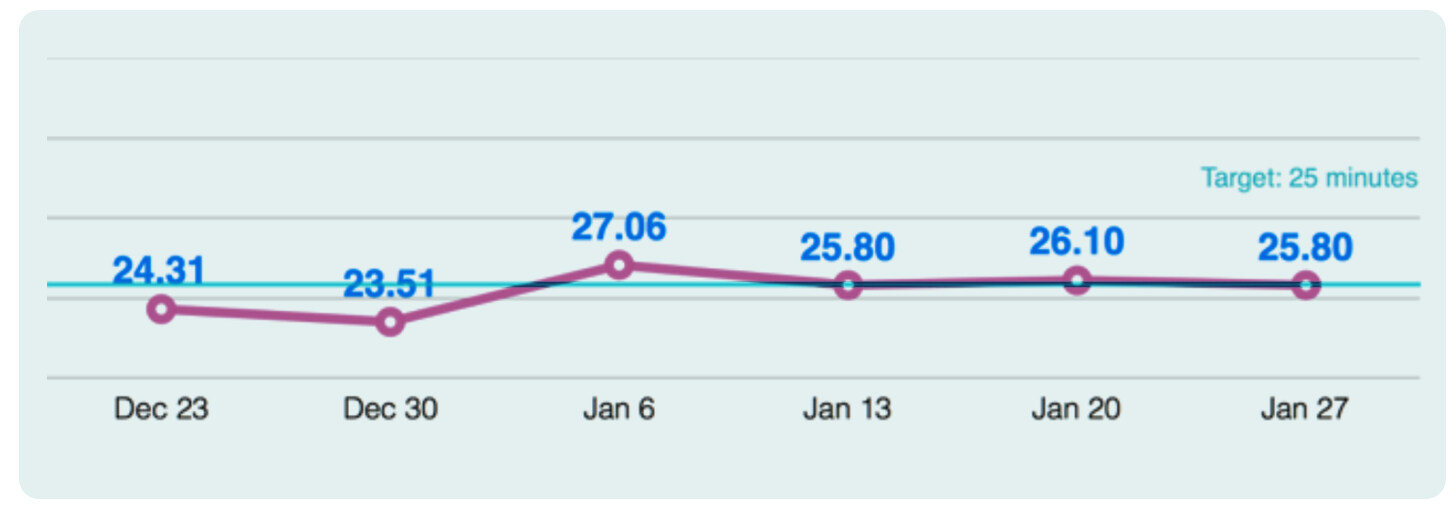
Pipeline 是软件交付的命脉,为了保证每一个功能需求可以长期稳定、源源不断地通过,在优化过程中我们引入了关于 Pipeline 性能的监控机制,我们基于 ThoughtWorks 的开源产品 GoCD 提供的 API 开发了一个监控工具,每一次构建之后可以自动统计该次构建的时间和成功率,如果超过这两个指标超过了阈值,则让该次构建失败,提醒代码提交者检查是否引入了影响 Pipeline 性能的变更,避免性能的进一步恶化。考虑到网络和机器性能的问题,在设置实际的阈值的时候可以稍大于期望值。

我们还构建了基于邮件通知的预警机制,每个工作日的下午发送出包数量通知,提醒团队解决影响出包的问题,同时我们把 Pipeline 的性能可视化并纳入每周的周报中。
写在最后
优化 Pipeline 除了 Pipeline 结构、测试策略和监控可视化手段之外,还需要关注软件架构和团队组织结构,下面是我们项目架构的局部依赖图:
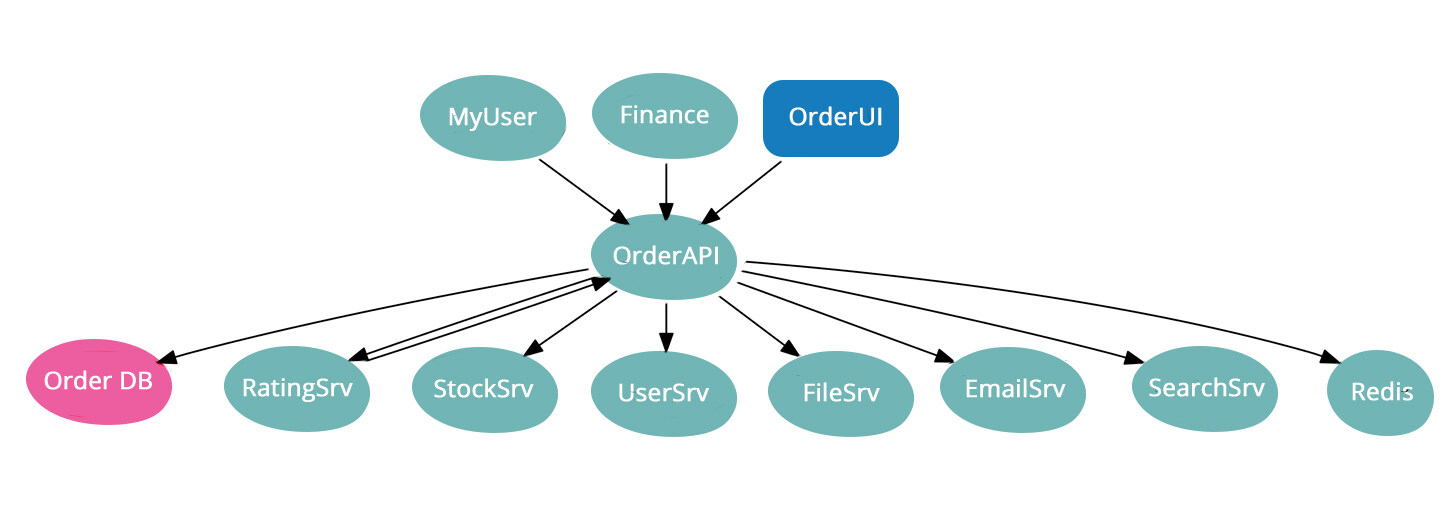
核心的微服务OrderAPI依赖复杂,和RatingSrv之间甚至出现了双向依赖,领域上下文(Bounded Context)的不合理切分使得业务逻辑散落在不同的服务之间,不管我们增加集成测试还是契约测试,这种依赖关系也同样会体现在 Pipeline 之间的依赖关系上,增加 Pipeline 的复杂度。
在 ThoughtWorks 技术雷达上 A single CI instance for all teams 目前处于 Hold 状态,在一个组织中多个团队共享一个臃肿的 CI 会导致很多的问题,比如上文中提到的构建队列过长,构建时间长等,一旦这个共享的 Pipeline 出现问题会造成多个团队工作 的中断。技术雷达建议在具有多团队的组织中由各个团队分布式地管理自己独立的 CI。这种分布式的 CI 同样也依赖于整洁的软件架构和与之相契合的团队组织形式。
在项目的 DevOps 小组解散之后,我们成立的项目内部的 DevOps Community,以保证产品交付为目标,同时肩负着项目提高内部 DevOps 技能的职责。项目内部的成员有跨多个开发团队的不同角色组成,DevOps community 产生的相关 Task,最后都会分配到不同的开发团队中。DevOps 是一种文化而不应该是一个单独的小组,DevOps 主旨在于构建整个团队中的责任共享的文化,改进现有的流水线是每一个开发团队都需要具有的技能之一。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




