
字节跳动火山引擎-多媒体实验室团队获得了 ICME 21 Best Grand Challenge Winner Team 。
团队成绩
比赛共有 12 支来自不同国家的参赛队伍,其中包括上海交通大学、深圳大学、日本东京工业大学和印度 IIT 大学参赛队伍。字节跳动火山引擎-多媒体实验室在无参指标赛道中所有评价指标均排名第一;在全参考指标赛道中部分指标排名第一。
竞赛简介
该比赛为鹏城实验室、北京大学深圳研究院、腾讯和美国南加州大学联合举办项目,主办方在视频编码和质量评估方面有比较深厚的学术积累,合作参与过业界知名的全参质量评估算法 VMAF 开发工作,对 UGC ( User Generated Content )视频画质的相关学术和落地应用也有广泛的探索研究。
比赛名称: Challenge on Quality Assessment of Compressed UGC Videos ,主要针对 UGC 源视频画质和 H.264/AVC 压缩失真对视频主观画质的影响的研究,该竞赛共包含两个赛道,分别对应 VQA 领域两类主流的解决方法:
无参考视频质量评价( NR-VQA ) MOS 赛道:在参考信息缺失的前提下对损伤视频质量进行评价
全参考视频质量评价( FR-VQA ) DMOS 赛道:衡量参考视频和损伤视频之间的质量差异
竞赛数据集
竞赛数据集包含 6400 个训练视频片段和 800 个验证视频片段,另外举办方保留 800 支测试片段用于对参赛模型进行比较,参赛者无法获取测试集视频片段。
数据集中参考视频是从实际的视频分享 app 中收集。
通过设置不同的压缩参数,每个参考视频被 H.264/AVC 编码器压缩成损伤程度由弱到强的 7 个损伤片段。
主办方通过主观测试针对每一支视频片段收集了超过 50 个主观 MOS 评分。
竞赛难点
相比于传统的 PGC 视频, UGC 视频画面内容和损伤种类的复杂性为质量评价提出了巨大的挑战。
从画面内容角度, UGC 包含 CG 游戏录屏、自然风景、食物、建筑、人像、动物等各种类型(图 1 );同时画面中的特效,诸如文字、 CG 贴纸、特效滤镜、含黑边的三明治视频等(图 2 )都对传统评价算法性能有一定影响。

(图 1: UGC 内容种类)

(图 2: UGC 画面特效)
同时 UGC 中包含多种来源损伤(图 3 )。拍摄端的噪声、过度曝光、欠曝光和抖动等与传输过程的压缩失真等相互叠加,为质量评价算法的研究提出更大的挑战。

(图 3: UGC 画质损伤)
1.算法背景简介
早期的质量评价算法多在手工特征的基础上设计的,随着深度学习技术的发展,深度神经网络( CNNs )在 VQA 中得到了广泛的应用。
由于 Transformer 在自然语言处理( NLP )领域取得巨大成功, QOE-LAB 采用 Transformer 进行 UGC 视频的全参考和无参考视频质量评估,提出了一种 CNN 和 Transformer 相结合的框架。
采用 CNN 提取局部特征,利用 Transformer 结构通过自注意机制预测主观质量分数。
2.框架和流程

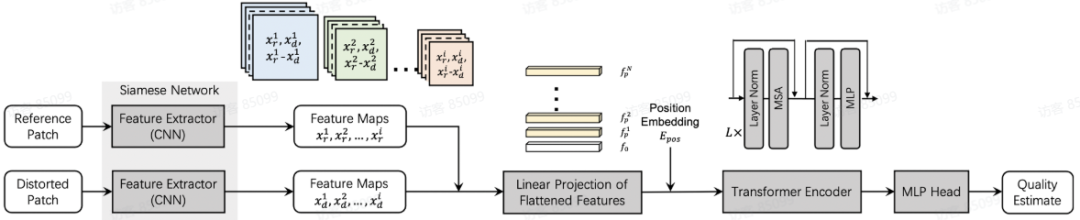
(图 4: 提出的无参考模型)
我们使用 CNN 作为特征提取器来计算输入视频块的深度特征。提取 ResNet 不同层的特征,在空间维度上利用 MaxPooling 将这些特征降采样到相同大小,并在特征维度上进行拼接。
将该特征的空间维度展平并进行 Linear projection , 并添加 embedding 作为 Transformer 的输入:
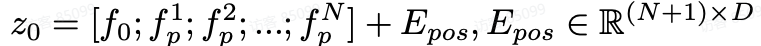
采用的 Transformer 架构遵循标准的 Vision Transformer ,包含 L 层多头注意力模块( MSA )和多层感知器模块( MLP )。
Transformer 与 MLP 头连接,用于回归最终的主观评分。
用于训练的损失函数均方误差 l1-Loss 和 PLCC-Loss 加权相加构成:
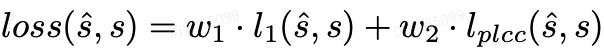
PLCC 表示一个 batch 内预测值和 groudturthlabel 的相关性,其值归一化至 [-1,1] , PLCC 值越大性能越好,因此 PLCC 损失表示为:
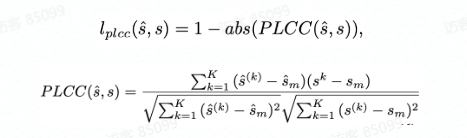
全参考模型框架如图 5 所示。 reference patch 和对应位置的 distortion patch 输入共享权值的孪生神经网络分别提取深度特征,并在特征空间的计算 L1 距离,拼接成新的特征输入回归模块映射得到主观 DMOS 分值。
(图 5: 提出的全参考模型)
3.实验
如图 6 所示,在训练过程中,从压缩视频片段和相应的参考视频片段中随机裁剪出一个 256×256 的图像块 patch (针对 FR 框架),然后将压缩视频的质量评分直接作为裁剪 patch 的训练标签。
测试时,从每一帧的四个角和中心裁剪得到 5 个大小为 256×256 的 patch 分别计算分值( FR 框架),所有 patch 的平均得分作为压缩视频的预测分。

(图 6: patch selection )
在实验中,用于特征提取的 ResNet18 网络使用在 ImageNet 上预训练的用于分类任务的网络的权值进行初始化,并使用相同的学习率与框架的其他部分一起进行训练;
Transformer 包含 2 层, MSA 头数为 16 。在加权 w1=1.00 , w2=0.02 的条件下,利用 L1 损失和 PLCC 损失联合优化框架。
通过对比竞赛结果中的各队伍在测试集上的性能指标( PLCC/SROCC/KROCC/RMSE )以及 SOTA FR/NR 算法预测质量分数散点图,对提出模型的性能进行验证:
A. MOS track:
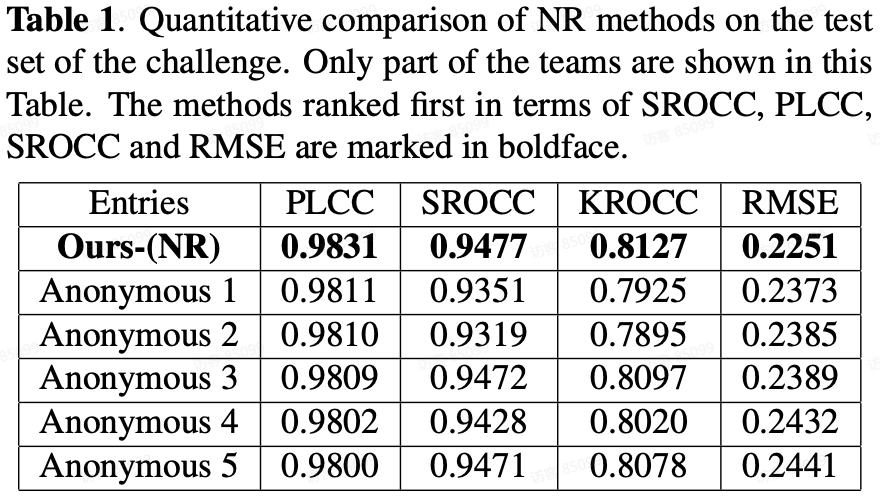
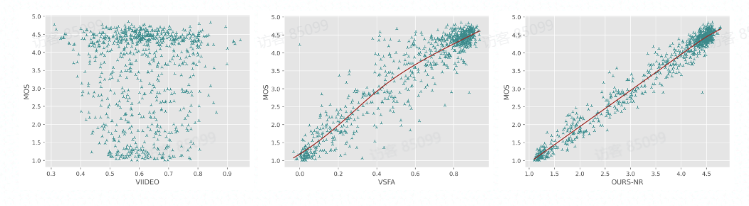
Comparing with SOTA NR-VQA metrics:
B. DMOS track:
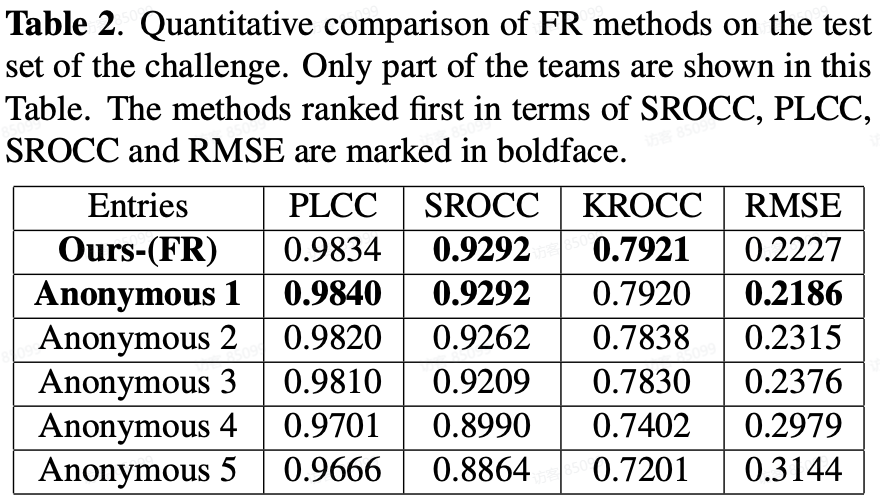
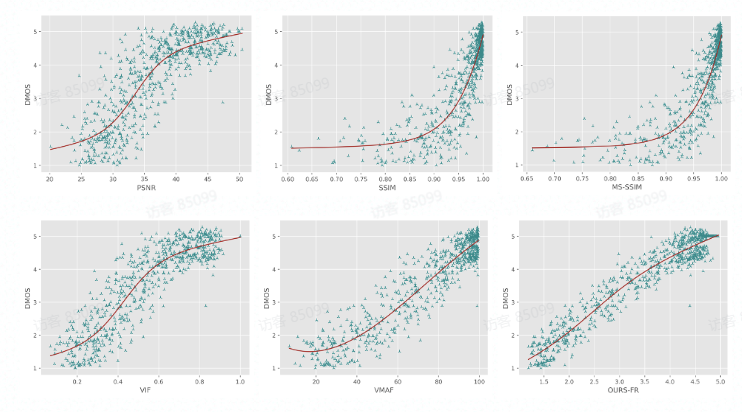
Comparing with SOTA FR-VQA metrics:
对于直接预测损伤视频 MOS 分的 NR 方法,我们提出的 NR 框架在所有评价指标中排名第一。
对于预测参考视频和损伤视频质量差异 DMOS 分值的 FR 方法,我们提出的 FR 框架在预测单调性(即 SROCC 和 KROCC )方面排名第一,在预测精度(即 PLCC 和 RMSE )方面排名第二。
同时通过散点图可以看出,提出的方法与主观评分具有较高的相关性,显著超出了其他的 SOTA FR/NR 方法。
针对 UGC 内容的研究与实际应用场景更加贴近, UGC 质量评价算法对监控视频平台整体画质、监督画质提升算法、指导压缩效率提升等场景有重要作用。
提出的 Transformer 结构实现了算法性能的提升,对算法研究具有较强的指导意义。
Reference
ICME 比赛官方网:
https://2021.ieeeicme.org/conf_challenges
UGCVQA 官方网站:http://ugcvqa.com/




