
在 Criteo(中文名科稻,一家在纳斯达克上市的全球性的效果营销科技公司)的通用目录(Universal Catalog)团队,我们每天与数十亿产品打交道,来创建全球最大的电子商务目录之一:250 多亿种产品。这些产品,由我们的电子商务合作伙伴提供,具有不同的数据字段,我们使用这些数据字段来创建补充(enrichments):新的产品字段标准化给定数据,并由 Criteo 全球团队重复使用。一个重要的补充是按类别对产品进行分类。
在本文,我将描述我如何解决通过使用电子商务产品的主图像将其划分为数千个类别的难题。我选择了一种在 GPU 上使用 TensorFlow 的深度学习算法,使用了一个包含数百万图像的标注过的数据集。
在 Criteo,我们有数万个电子商务合作伙伴,他们为我们提供了总计 250 多亿种产品的目录。这些产品通过我们的在线广告推荐给互联网用户,确保这些互联网用户与我们的电子商务合作伙伴的广告活动相关。为了保证推荐的质量,我们需要标准化这组异构目录。特别是,每个产品都应归入其电子商务类别。而且无论原始目录如何,所有这些产品的这组电子商务类别都应该是相同的。然而,每个电子商务合作伙伴都为我们提供了每种产品的类别,但不是用通用的参考。在 Criteo,我们使用了一种由谷歌提供的被电子商务生态系统广泛使用的分类:谷歌产品分类法(Google Product Taxonomy)。它仅用于零售产品,而不同类型的产品使用了其它技术。然后,我们用这个分类法将零售产品重新分类。所有可能的零售产品都分类到这个树型结构中。
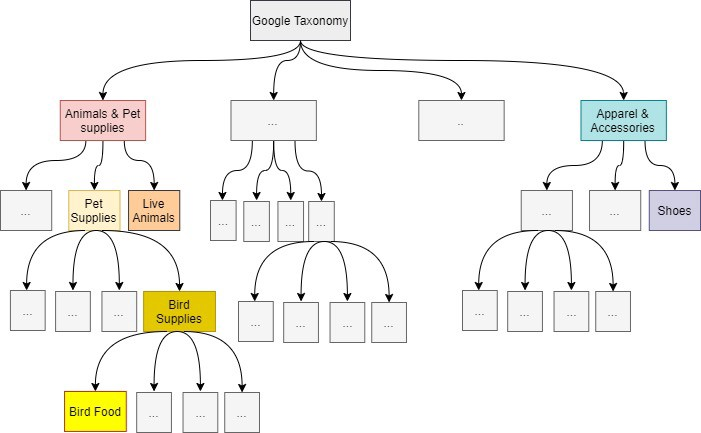
产品类别参考
上图是上述谷歌产品分类法(Google Product Taxonomy)的一个示例。这是一个树型结构,我们截断到第 4 级或更上层的叶子类别。我们构建了一个机器学习模型来预测每个产品的所有类别,直到它的叶子类别。但是我们只使用预测的叶子类别,其它预测的父类别用于调试。预测到的叶子类别信息能够检索到根类别的路径。
重新计算出的叶子类别称为“通用类别”。如果一个目录已经使用了这种分类法,我们仍然会重新对其进行计算。一旦重新计算,所有这些目录就构成了一个独特的大型电子商务目录(超过 250 亿种产品),称为“通用目录”,在 Criteo 的整个生态系统中使用。
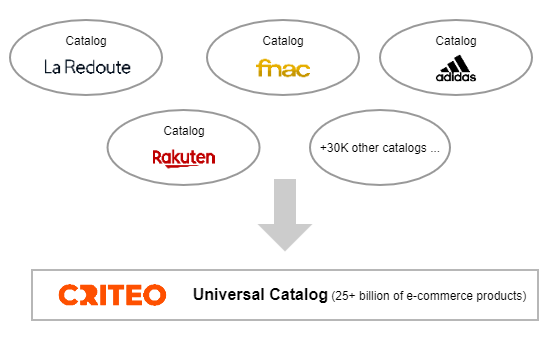
Criteo 通用目录
这种产品分类问题存在于 Criteo 环境中,但只要你希望合并不同来源的目录(其目录对于类别字段的值没有一种通用的格式),这在电子商务生态系统中是一个普遍存在的问题。
目前,在生产环境中,为了计算每种产品的通用类别,我们已经根据这些产品的文本特性构建了一个机器学习模型。但没有利用到产品图像。我们能否仅使用这些产品图像来预测“通用类别”,同时保持良好的性能?对于这个机器学习问题,特征(feature)是唯一的主图像,标签(label)是预测产品所属的类别。
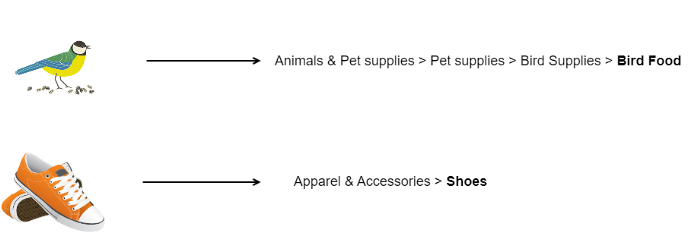
使用产品图像来预测通用类别
在本文中,我将描述我们是如何解决使用电子商务产品的主图像来将它们分类的这一挑战的。这是一个有监督机器学习问题,目标是 K 类,其中 K 是+3000,这是截断的谷歌产品分类法中的叶子类别的数目。为了构建这个分类器,我选择了使用深度学习,这是一种非常有效的方法,如果你可以像这里一样构建大型训练数据集。
在这种有监督深度学习情况下,我按照以下步骤来训练和运行我选择的深度学习模型:
创建用于训练/验证和测试的大型标注过的数据集:(feature=产品图像,label=产品类别),使用 Spark 分布式计算将数百万电子商务产品进行分类
根据基于图像的深度学习技术的现状选择深度模型
创建一个通用的深度学习架构来解决这种机器学习分类问题。
使用 TensorFlow 1.15 在训练/验证数据集上训练每个模型,然后在多个 GPU 上使用 TensorFlow 2+进行训练
使用准确性和 Criteo 业务价值来评估数据集上的每个模型,然后使用比较网格和多维混淆矩阵分析它们的得分
让我们具体看看每一步吧!
使用分布式计算创建一个数据集
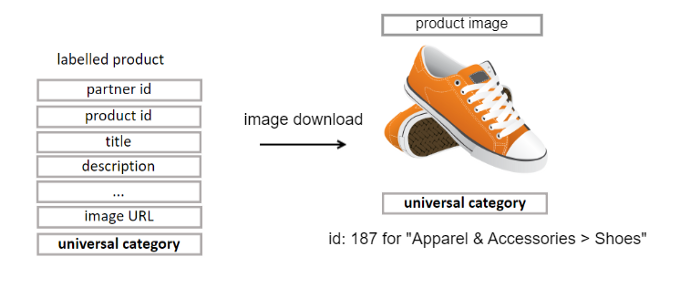
在 Criteo,我们已经积累了数百万种标注有它们的目标类别的产品。这很棒,但是这些标注过的数据集只有到图像的链接,而没有图像本身!这意味着在这里提到的工作之前——合作伙伴的产品没有可用的图像数据集!
为了检查有多少图像不可用或响应太慢,并使用已经可用的标注过的数据,我首先用 2 个多小时下载了 10000 个产品的小样本。我发现有 1%的图像链接无效或者丢失,约 12%的图像无法下载(图像不再存在,链接仍然存在但被重定向到首页,等等)。
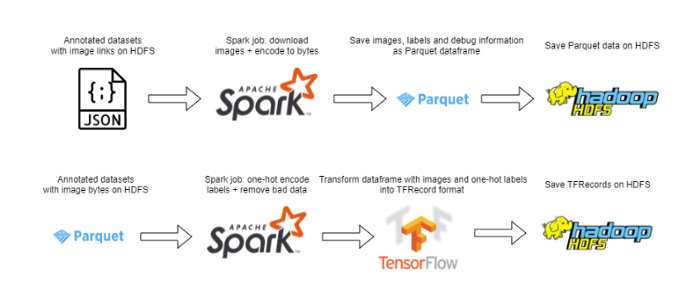
创建数据集的 Spark jobs
用简单的按次序的方案来下载 10000 种产品是没问题的,但是当扩展到 3600 多万个带注释的产品时,速度就太慢了(估计超过 300 个小时)。为了解决这个问题,我使用了一种分布式方案,通过在数百个 64 核容器的集群上运行代码来充分利用 Spark 的能力。尽管结果出现了一些问题(需要为 Spark 会话创建一个自定义 Python 可执行程序,来访问所有必要的包,并为我们的容器添加条件,以防合作伙伴将其列入恶意下载请求和其它问题的黑名中),解决这些问题之后,针对 3000 倍以上的数据集,下载程序可以同时运行。
下载完图像后,我们对其进行处理(调整大小来降低内存占用、标准化像素值或者其它特定域模型的更改),并对标签应用一个热编码,然后将图像和标注作为 TensorFlow TFRecordDatasets(TensorFlow 数据集)存储到 HDFS 上。

数据集拆分
一旦下载并存储了所有东西,我们就可以使用 70-15-15 的比例来对数据进行拆分,分别是训练(大约 2500 万个产品)、验证(大约 500 万个产品)、测试(大约 500 个产品)。我们的数据集构建好之后,我们就可以深入到深度学习问题本身,选择使用哪些模型。
学习最先进的方法
在 Criteo,我们使用 TensorFlow 1.15。尽管 TensorFlow 1.15 一开始非常方便,但这个版本很快就被证明是一个问题:与自定义的 TFRecords(没有批量训练)的兼容性差、最新的模型不可用、文档呆板...
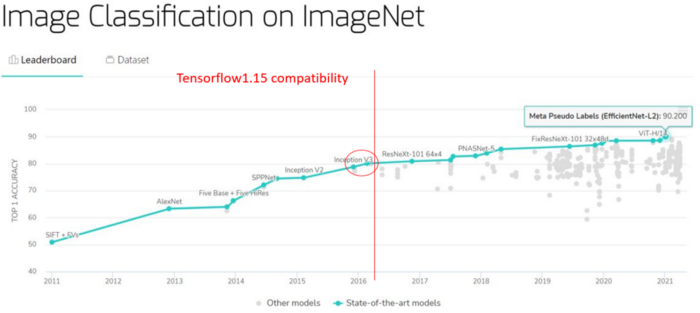
ImageNet 上图像分类的现状
在上图(红色圆圈)中,我们看到 Inception V3[1] 和 Xception [2]虽然不错,但性能优于 TensorFlow 1.15 中没有的更多的最新模型。
然后我推动将 TensorFlow 1.15 更改为 TensorFlow 2+来测试处于最前沿的最新模型。虽然这意味着需要迁移整个项目,但最终还是值得的。
在这个项目中,我们首先使用:
InceptionV3,因其在 ILSVRC’15 中的出色成绩
Xception,因其设计(基于大量类别进行分类)
当我们受到 TensorFlow 1.15 的约束时,这些模型特别有用(如前所述,它们是最先进的模型),但是当我们迁移到 TensorFlow 2 之后,我们又将 EfficientNet [3]添加到我们的比较基础上。这些模型当然不是所有可用的模型,而且这仍然是我们在这里介绍的工作的一个优化点。
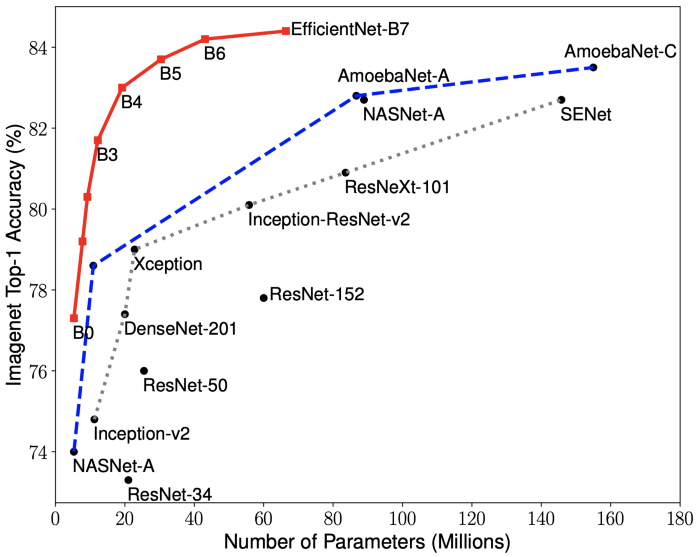
EfficientNet vs State-of-the-Art
即使所选择的模型提供了坚实的基础,但在我们将它们用于数据集之前,我们需要调整它们来适配我们的问题。
创建一个通用架构
为了能够快速改变我们想要实验的神经网络,设计一个通用的架构非常重要。我们创建了一个模板,将完成层添加到所选的深度学习模型中,以便预测谷歌分类法的所有 4 个级别。这些层次根据深度进行加权,因为我们的客户希望 4 级分类高于其它任何分类。
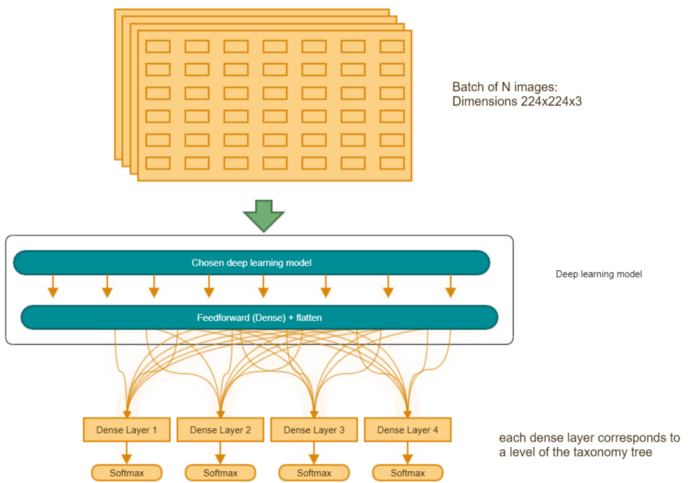
通用训练架构
训练模型
一旦选择了模型,我们将根据以下流程对其进行训练:
连接到 Criteo 机器学习容器。
训练模型:
a) 获取存储在 HDFS 上的作为 TFRecords 的训练和验证数据集。
b) 在 MLFlow 上记录机器学习指标 (accuracy、 loss、 top_k_accuracy …)
将训练过的模型保存到 HDFS 上。
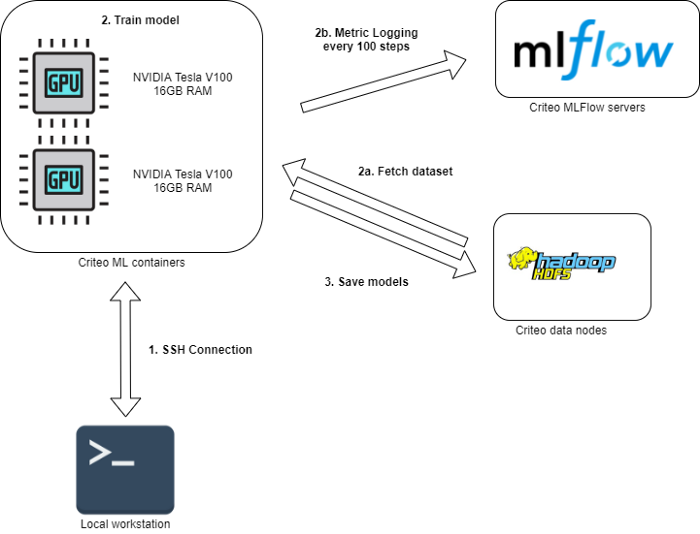
用于训练的深度学习工作流
在 HDFS 上提供这些模型后,我们可以在不同的数据集(测试组)上比较结果。
分析结果
在对每个模型基于训练和验证数据集进行了训练之后,我们对这些模型进行评估。这些数据集对于我们想要比较的所有模型都是通用的。评估也在一个通用数据集上进行,我们称之为黄金数据集,它不同于训练和验证数据集:标注过的产品不会同时出现在训练/验证数据集和测试数据集中。
模型训练之后就是评估。图像分类任务通常使用精度(Accuracy)作为一个指标(获得正确预测类别的百分比),在我们的案例中这不是最适合的指标(尽管它仍然很重要!)。作为一家在线广告公司,正确预测鞋子或衣服(流行广告项)而不是农用卡车轮胎,这是很重要的:这与我们所谓的产品的商业价值有着内在联系。该商业价值是根据我们广告产品的受欢迎程度计算的指标:购买的产品越多,其商业价值越高。
在运行我们的测试集时,通过使用一个分类的商业价值,我们不仅能够计算每个模型的加权得分(通过考虑预测类别的商业价值来响应加权预测得分),而且能够以易于理解的方式评估模型的性能,例如使用混淆矩阵。
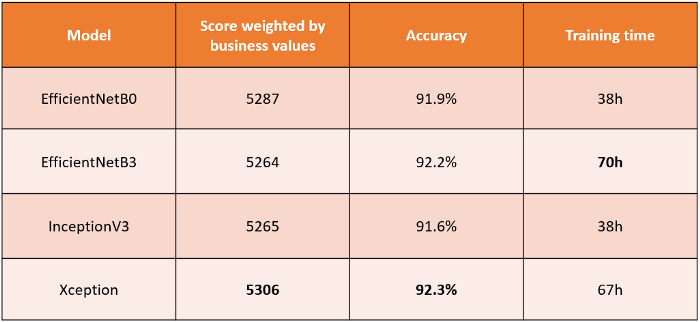
不同模型的性能比较
在上表中,我们看到了指标之间的并不都是相关的。训练时间通常是一个折中(更长的训练时间通常与更好的精度相关,但也与更大的模型相关,并不总是值得期待),但在这里并不总是有益的。通过比较我们不同模型的加权得分,我们注意到 EfficientNetB3 虽然在 ImageNet 上比所有其它这里展示的模型要好,但在我们的测试集上表现不佳:精度很高,但加权得分很低。Xception,针对基于大数目的类别进行分类而设计 [2],效果最好,虽然和其他模型的区间相同。
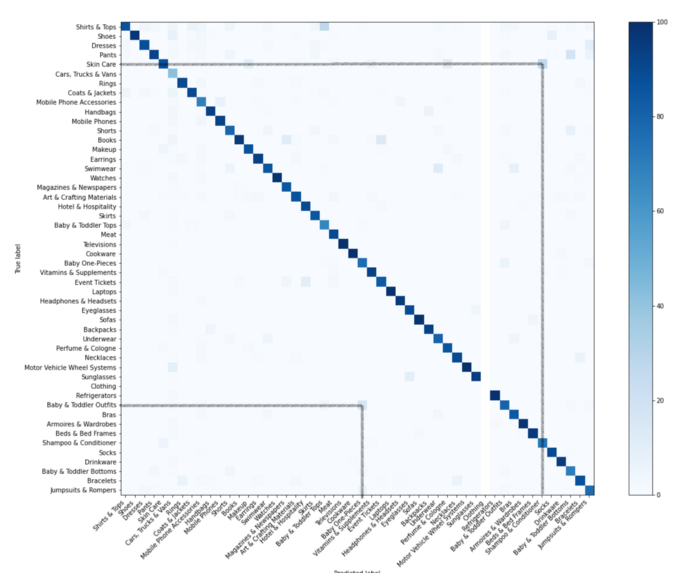
Xception 针对 50 个最高的商业价值的混淆矩阵 (左上角是最重要)
在混淆矩阵中,我们垂直方向记录预测到的类别,水平方向记录真正的类别。当一个模型预测到正确的类别,它会被记录在对角线中。在上图中,我们看到了我们的模型预测为“洗发水 & 护发素”而真实类别为“皮肤护理”的产品为 15%(或预测“婴幼儿上衣”而真实类别为“婴幼儿外套”的产品为 10%),这些产品在视觉上确实彼此相似。
深度总结
在 500 多万张图像的测试集上,准确率超过 90%,显然接下来的步骤之一就是将该项目与生产中已经使用的 NLP 方法集成,来构建通用目录。例如,可以使用多模式学习 [4] 或将这两种方法结合使用,例如使用集成学习 [5]。
为了在生产中集成一个新模型,我们需要考虑另外一个非常重要的因素:保持较低的推理时间。我们在导言中提到了通用目录每天如何与数十亿产品交互。如果一个模型的预测步骤很慢,它可能会大大减慢整个通用目录工作流的速度,该工作流每天预测数十亿产品来提供其通用类别。
由于模型的精度达到或高于被 ImageNet 引用的最先进的精度水平,预计获取每个百分比的额外精度都会很困难。尽管使用最新的 2021 模型(NFNets [6] 或 EfficientNetv2 [7])绝对是一种选择,但创建我们自己的模型也开始成为一条有吸引力的路线!
感谢阅读!
我要感谢Romain Beaumont,感谢他在机器学习方面的专长;感谢Gilles Legoux,因为他在分布式计算上的帮助,以及他对整个项目中的监督。最后,我还要感谢通用目录团队的其他成员(Alejandra Paredes、 Nasreddine Fergani、 Hadrien Hamel 和Agnes Masson-Sibut),因为他们让我体验到了良好的工作环境。
参考书目
[1] “Rethinking the Inception Architecture for Computer Vision”, Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna
[2] “Xception: Deep Learning with Depthwise Separable Convolutions”, François Chollet
[3] “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, Mingxing Tan, Quoc V. Le
[4] “Multimodal Machine Learning: A Survey and Taxonomy”, Tadas Baltrušaitis, Chaitanya Ahuja, Louis-Philippe Morency
[5] “Ensemble learning: A survey”, Omer Sagi, Lior Rokach
[6] “High-Performance Large-Scale Image Recognition Without Normalization”, Andrew Brock, Soham De, Samuel L. Smith, Karen Simonyan
[7] “EfficientNetV2: Smaller Models and Faster Training”, Mingxing Tan, Quoc V. Le
作者介绍
Celian Gossec 白天是机器学习工程师,晚上是交易员,我喜欢学习关于机器学习的方法及其在现实项目中的应用!
原文链接
Image-Based ML Techniques To Classify Billions Of E-Commerce Products Into Thousands Of Categories




