
编者按
销量预测是企业生产经营中的重要环节,但由于未来市场需求和销量来源等存在诸多不确定性,为企业销量预测提升了难度,如何提升产品全生命周期智能决策分析越来越成为企业关注的重点。百分点数据科学实验室多年来在项目中积累了丰富的实践经验,总结了一套基于数据驱动的销量预测模型建构方法,本文将从预测目标、评估方法、案例应用及效果等方面进行分享。
一、销量预测的价值
1. 销量预测的商业价值
由于供应链的滞后性,企业需要根据未来一段时间内的市场需求制定尽量准确的销售计划,再根据销售计划制定生产和采购计划。但未来的市场需求是不确定的,如果企业高估市场需求,就会造成库存积压,进而承担库存成本(包括库存费用和资金成本);如果企业低估市场需求,就会造成缺货,进而承担未实现销售的机会成本。这时,准确、高效地预测市场需求,即进行销量预测,就成为企业降低决策不确定性,最小化库存和机会成本的关键。
2. 数据驱动的销量预测
企业进行销量预测的传统方法是基于人工经验估计,也可以称为专家法。以一个消费品生产企业为例,制定销售计划有如下步骤:
(1)各个地区销售代表拜访当地客户收集需求意向,再根据经验判断,制定地区销售计划。
(2)总部将所有地区的销售计划汇总,得到全国销售计划。
(3)总部根据季度或月度业绩目标调整销售计划,再返回到地区进行确认。
(4)确认后得到最终的销售计划,交给生产部门。
上述流程本质上是通过收集客户的需求信息,再经过专家经验调整后得到未来销量的预测。这种专家法能够结合长时间积累的业务经验和人的逻辑判断能力,但完全依赖专家法有一定的局限性:
人工经验可能存在偏见(bias),忽略或放大某些影响销量的因素,例如总部调整销售计划时可能高估营销政策的影响。
专家法有较高的时间成本,无法对大量商品进行预测,例如对于一些销量很小的品规,地区销售可能选择忽略,不花时间采集信息。
数据驱动的销量预测可以解决上述问题。数据驱动的销量预测是指利用算法挖掘大量历史数据中可复现的规律,再用这些规律建立模型预测未来销量(图 1)。
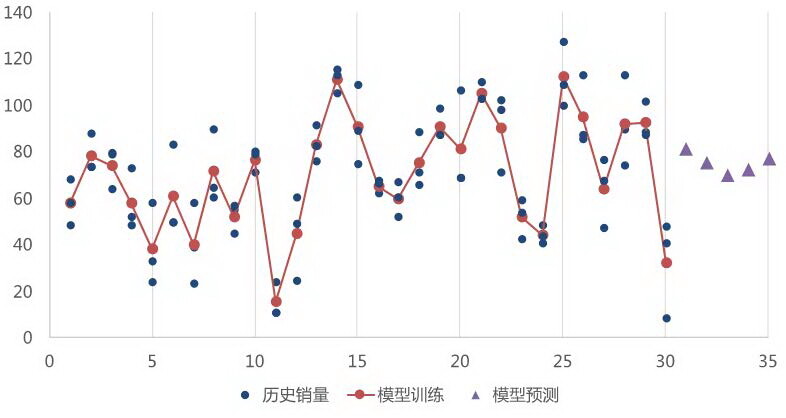
图 1 数据驱动的销量预测
算法挖掘数据中规律的过程其实本质上和人工判断的原理类似,都是在可能影响销量的因素和销量之间建立联系。销量的影响因素包括:销量的历史趋势、周期性、节假日、产品属性、渠道属性、营销投入、竞争情况等(图 2)。
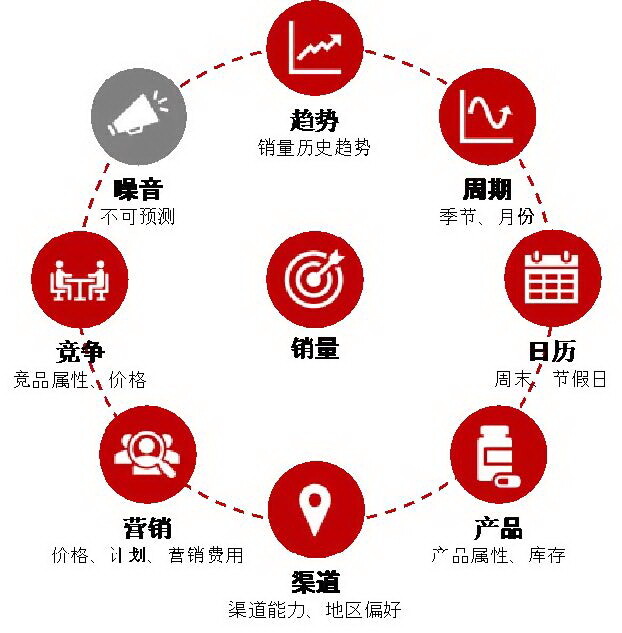
图 2 销量预测的影响因素
二、销量预测的难点
1. 世上没有水晶球
尽管销量预测十分重要,但在实践中进行高质量的销量预测并不容易,尤其是预测的准确率往往不尽如人意。在深度学习算法已经可以超越人类水平进行人脸识别的今天,为何销量预测仍然如此之难?在讨论这个问题之前,我们首先要明确未来销量不确定性的来源。不确定性可以分类三类(图 3):

图 3 不确定性的来源
(1)未知但可知:指数据中的随机性,即噪音造成的不确定性。
(2)博弈结果:指系统内参与者对其他参与者行为的预期造成的不确定性。
(3)复杂系统:指复杂系统中极小参数变化经过非线性转换造成的“黑天鹅”类不确定性。
在这三类不确定性中,预测模型只适合解决第一类,而人脸识别就符合第一类不确定性:人脸的结构和特征千百年来变化非常缓慢。第二和第三类不确定性从定义上来说无法在历史数据中积累足够多的案例,预测模型也就无法学习相关规律。未来销量的不确定性恰恰不仅来自第一类不确定性。举例来说,竞争对手的行为(定价、新品)会影响企业的销量,但这是竞争对手的行为是基于企业本身策略的预期制定的(博弈结果),无法通过历史数据预测。“黑天鹅”类的不确定性就更容易理解,去年发生的新冠疫情就是一个鲜明的例子。换而言之,即使我们能收集图 2 中所有影响销量的因素,也不可能百分之百准确地预测销量。因此,在建立销量预测模型时,我们不能以一个理想的准确率作为目标,而是将模型与基线对比,评估模型带来的效率和准确率提升。
2. 预测、目标和计划
除了预测方法的局限性,销量预测的另一个误区是企业通常会混淆预测、目标和计划三者的关系,造成预测的边界模糊,在实践中无法展现价值。根据预测专家 Hyndman[1]的定义:
预测(forecasting)是基于历史数据(历史销量)和未来可能发生的事件(营销投入),尽量准确地估计某个变量未来的数值(未来销量)。
目标(goals)是企业希望未来发生或达成的事件(销量增长 30%)。
规划(planning)是企业对于预测和目标的应对措施,即需要做什么(营销投入增长 15%)才能让预测和目标一致。
在实际项目中,企业一般会每个月制定下个月的销售计划。由于销售计划具有考核效力,下个月的实际销量和销售计划具有很高的相关性。因此,为了得到准确率较高的预测模型,建模人员通常会将销售计划作为特征加入销量预测模型。但销量预测模型的目的就是为了指导业务人员更加合理的制定销售计划,那么到底应该先有销量预测,还是应该先有销售计划?
出现这个问题的根本原因是没有区分预测、目标和规划。在上面的例子中,销售计划实际上是目标,也就是企业希望完成的销量。销量预测模型不应该使用销售计划作为特征,销售计划应该在预测结果的基础上制定。相应的,在评估模型表现时,也不能将模型的预测误差率同销售计划和实际销量的误差率直接对比。
我们使用销售计划作为特征是因为销售计划是一些通常无法观测到的变量的代理变量(proxy variable)。例如,为了完成销售计划,基层业务人员会加大拜访客户的频率,但拜访次数没有记录,所以模型无法捕捉这类信息。因此解决这个问题的根本方法是更加全面的收集数据。
三、销量预测解决方案
销量预测属于时间序列预测问题,时序预测通常采用传统时间序列模型,例如 ETS 和 ARIMA,对单序列进行建模。为了提升准确率,可以进一步进行多个时序模型的融合。但该方法在销量预测领域有一定局限性。我们从分析销量预测的技术挑战出发,决定最终模型解决方案。
1. 大规模多层级多时序问题
问题描述:销量预测可以理解为一个多层级多时序问题。具体来说,销量可以根据产品、地理等维度划分为多个时间序列。以一个有两级产品(品类和品规)和两级地理(地区和门店)管理体系的企业为例,最细的时序维度是地区-门店-品类-品规。一个较大规模企业可能需要预测数万,甚至数十万个时序。因此,模型需要对大规模时序组合进行预测。
另一个问题是时序之间存在附属关系,例如品规属于品类,门店属于地区。建模时需要考虑时序之间的交互关系,并且保证附属关系成立,例如品规销量汇总等于品类销量,门店销量汇总等于地区销量。
解决方法:为了捕捉时序之间的交互关系,并且允许相同层级的时序共享信息,我们选择多时间序列联合建模的方法,不使用传统的单时间序列模型。具体来说,我们将最细维度时序(地区-门店-品类-品规)的全部数据输入模型,再通过特征工程提取时序类特征(图 4)。在预测阶段,我们对最细维度时序预测结果进行汇总,得到更高层级时序(如品类和门店销量)。
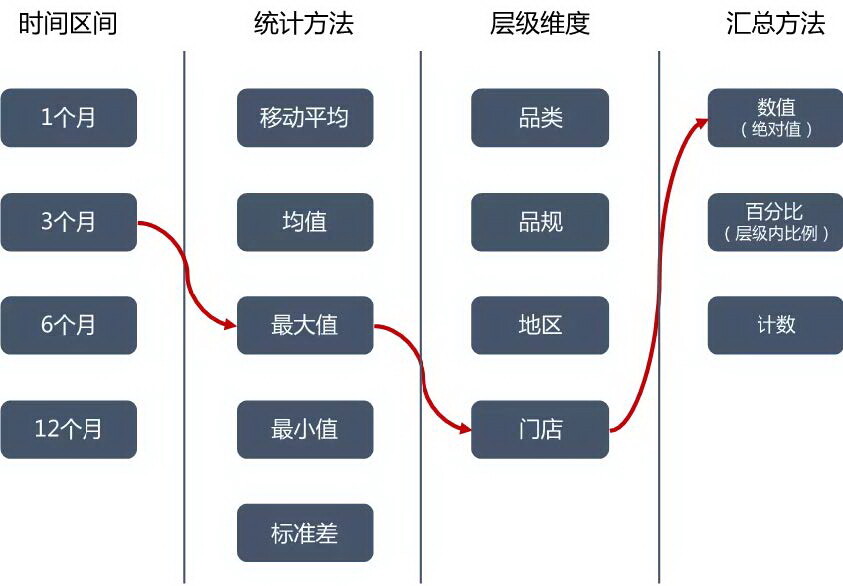
图 4 时序特征工程方法
由于以上建模方法针对最细维度时序,在汇总后,更高层级的预测不一定达到最佳效果。一种改进方法是对更高层级时序(品类或地区)分别单独建模,再用 Forecast Reconciliation 方法统一和优化各层级预测结果。
2. 多步预测问题
问题描述:多步预测是指我们关注多个目标,例如预测未来 1-3 个月每个月的向量。传统时序模型的应对方法是将 T+1 时间的预测结果作为 T+2 时间的输入值,用来进行滚动预测。这种方法的问题是可能造成预测误差累计。例如,如果模型有预测偏大的问题,那么每步预测时该问题都会放大。
解决方法:我们对每个预测目标时间(T+1,T+2 等)分别建立模型,使多步预测更加稳定,代价是需要训练预测目标时间倍数的模型。
3. 间歇性需求问题
问题描述:对最细维度时序建模时,会出现部分时间销售量为零的情况,这种情况被称为间歇性需求,在销量预测领域是一个常见问题。训练数据中存在大量零值会造成模型偏见,降低准确率。
解决方法:我们采取两个步骤解决这个问题。首先,我们将有大量连续零值时序视为已停产状态,从训练数据中剔除,不对其进行预测。在筛选完时序后,还会有间歇性需求存在。我们根据实际数据情况采用以下方法或方法组合应对:
使用 Tweedie Loss 等对零值敏感的损失函数训练模型。
使用 Hurdle Model,先训练一个分类模型预测销量是否为零,再训练一个回归模型预测在销量非零情况下的销量。
四、销量预测评估方法
销量预测模型的评估方法多种多样,可以分为技术指标和业务指标两类。
1. 技术指标
技术指标用来评估模型在验证集或实际生产中的预测准确率。最常用的技术指标是平均绝对百分比误差(MAPE),其定义如下:
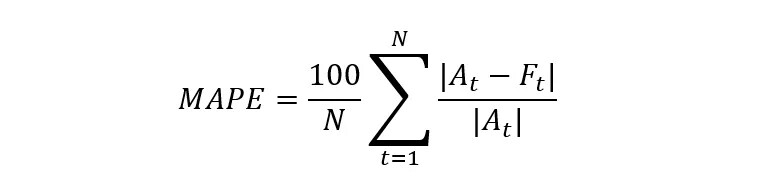
MAPE 的优点是作为一个百分比误差,非常易于业务人员理解。但 MAPE 有两个显著问题,导致在实际应用中会得到不直观的结果:
(1)MAPE 是非对称的:当预测值大于实际值时,MAPE 是没有上限的,而当预测值小于实际值时,MAPE 最大为 100%。
(2)MAPE 在实际值为零时无法计算,这在间歇性需求常见的销量预测领域是严重问题。
为了解决上述问题,人们提出对称平均绝对百分比误差(sMAPE),但 sMAPE 存在自己的问题。
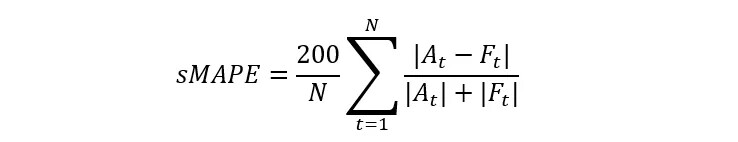
我们在实践中采取 MAD Mean Ratio 作为技术评估指标。该指标适用于间歇性需求场景,并且同样是一个百分比误差,易于理解。
2. 业务指标
业务指标用来评估模型应用后对业务产生的实际影响,是比模型准确率更加直观和有效的评估指标。业务指标需要根据具体业务设计,还是以消费品企业为例,与销量预测模型相关的业务指标包括库存周转率、订单拖欠率等。
五、对于业务设计的启示
根据项目实践中积累的经验,我们总结两点对于业务设计的启示:
(1)如果想最大程度挖掘数据中的价值,那么设计相关业务和 IT 系统时需要充分考虑数据分析和建模的需求。举例来说,一般业务系统的数据库设计不会考虑时间切片数据的保存,这就造成分析和建模时无法获取历史时点的数据,进而造成时间泄露等问题。
(2)销量预测是一种技术工具,需要和业务流程结合才能发挥作用。即使模型达到令人满意的准确率,如果混淆了预测、目标和规划,对模型产生不切实际的预期,或者模型结果无法被业务人员理解和接受,模型也不会对业务产生实际影响。
六、项目应用案例
1. 背景和需求
某医药企业生产数百种 OTC 药品,并通过多级分销商体系在全国进行销售。为了满足企业复杂的经营业务,供应链管理十分重要。该企业的供应链可以抽象为物料流和信息流,两者统称为产销协同链条,具体如下:
物料流:原料仓库-生产线-成品仓库-物流-渠道仓库-销售。
信息流:需求预测-渠道订单-总部计划-生产计划。
该企业产销协同链条面临以下问题:
(1)产销协同管理链条不同环节数据未打通。
(2)管理环节彼此独立,整个供产销协同执行过程预警信息不统一。
(3)销售预测不够快速和准确,供销协同动态调整不够快速。
针对第三点问题,实施项目的解决方案为基于历史销售和库存数据建立销量预测模型,以大幅扩展进行销量预测的品规范围,并且提供更加准确和更高频率的预测为目标。具体而言,由于该企业的最细管理粒度为地区-门店-品类-品规,我们需要对超过 90,000 个时间序列进行建模;预测频率为月度;预测周期为 3-16 个月。
2. 方案和效果
上述需求完全符合第三章节中描述的销量预测技术挑战,因此我们按照该章节提供的解决方案设计项目中的建模策略:我们对全部时间序列进行联合建模,对每个预测目标时间分别建立模型,并使用 Hurdle Model 应对间歇性需求问题。特征方面,我们使用基于销量、库存、营销政策等类型数据衍生出的数百个特征。算法方面,我们采用适合结构化数据并且高效的 LightGBM。
利用时序交叉验证方法(Time-series crossvalidation),我们验证模型在历史数据上的 MAD Mean Ratio 表现,和采用预测模型之前的人工基准方法比较,模型在主要品规上降低了 15%预测误差,取得较好效果。
参考资料
[1] Hyndman, R.J.,& Athanasopoulos, G. (2018) Forecasting: principles and practice, 2ndedition, OTexts: Melbourne, Australia. OTexts.com/fpp2. Accessed on <2021-03-23>.
本文转载自公众号百分点科技(ID:baifendian_com)。
原文链接:




