
导语 | 随着知识问答在行业不同垂直领域的发展,知识问答的能力也在不断的提高和升级,本着 Nlper 的初心和 AI 评测的态度,我们为知识问答设计了一份考题(评测集),让我们一起来看看在这份考题下,当前的知识问答能考多少分呢?文章作者:周磊,腾讯 CSIG 质量部评测研究员
一、背景
知识问答(KBQA)通常是指结合了自然语言理解,知识图谱,自然语言生成等技术的问答系统。
知识问答在行业中的应用是非常广的,目前涉及到百科知识类的问答基本上都是靠 KBQA 赋能。比如智能音箱,需要支持一些人物等百科类的问答;景区实体机器人,需要支持景点的一些景观问答和历史问答;包括外卖,电商应用上的一些逻辑复杂的查询,这些都是知识问答在具体应用上的落地。
知识问答已经发展了很多年了,从最早期基于模版,基于社区,直到基于知识图谱。知识图谱赋予了知识问答很强的解释性和问题的表示能力,但知识问答跟自然语言理解这个大主题一样,其能力本身还是一个很低年级的水平。
二、业界评测集
伴随着 KBQA 的发展,业界评测集的难度也在慢慢转变。从早期最简单的单跳问答,到多跳到更复杂的问题慢慢发展。
其中 WebQuestions 相对简单,基本上都是一些简单的问法。
ComplexQuestions 在前者的基础上包含了类型约束、显式或者隐式的时间约束、多实体约束、聚合类约束(最值和求和)等。
QALD 加入了一些复杂问题,包括多实体,多关系,以及时间等比较的问法。

本文提出的评测集与上述评测集的问法类型难免会有重复,但更多的是从符号逻辑的角度来阐述整个评测集的设计思路和评测集的可解释性。
三、知识问答的核心方法
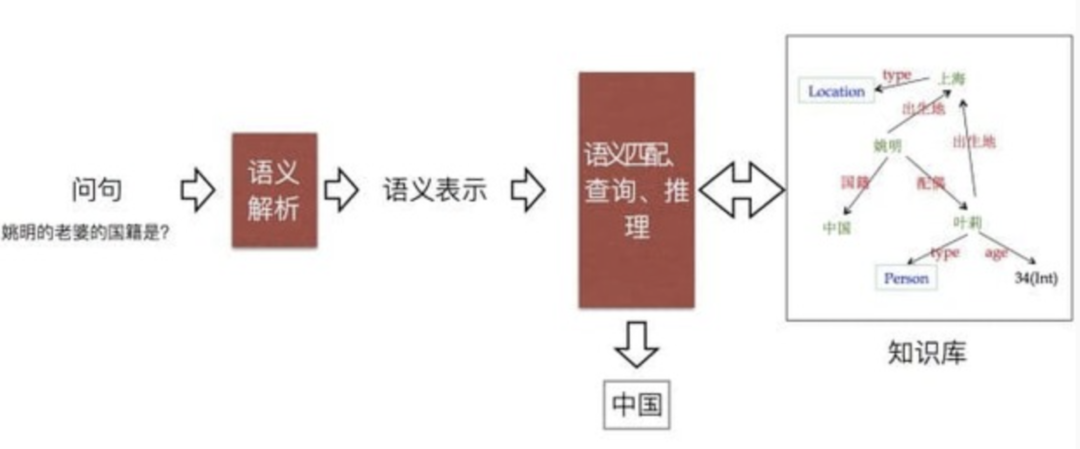
如上图所示,知识问答整个系统包含了语义解析,语义匹配,查询,推理等。拆解成更细的组件来看的话,可以拆解成实体抽取,属性映射,知识表示,知识图谱检索,查询算子等具体不同的能力。
实体抽取需要抽取出文本中的一个或多个实体;属性映射需要找出实体之间依赖的关系或者属性,并与图谱关系进行映射;知识表示需要将上述的实体和属性表达成一个适用于图查询的逻辑表达式;查询算子是图谱本身支持的一些查询方式(比如查询最值,查询 2 个集合的交集,查询 2 个实体之间的最短关系等)。
整个语义解析过程从早期解析出三元组,到最近几年兴起的 AMR(抽象语义表示),都是为了语义解析能更好的表示出更复杂的问题。但主要逻辑还是围绕三元组来进行语义表达的,本文的评测集也是基于三元组这个基础来进行设计的。
四、符号评测集的设计
1. 思考
KBQA 是基于三元组进行语义表示的,三元组的 subject 可以是一个和多个,比如“那个主持人李晨的身高是多少?”,"周杰伦和林俊杰的老婆分别是谁?"。
同样属性也可以是一个和多个,“周杰伦的妻子叫什么?”,“汪峰的老婆的母亲叫什么?”。
如果要去评测某个系统的知识问答能力,我们要如何去组织一个问法覆盖广的问法集合呢?有没有一种好的问法建模的思路?如果没有一种合理的问法评测集建模的能力,这个评测集永远都可能只包含了 KBQA 问法世界的一小部分而已。但是怎么建模呢?一个 subject?两个 subject?多个 predicate?比较?统计?
知识是无穷的,而 KBQA 涉及到的知识问法似乎也是无穷的。面对这个一个无穷无尽的问题,我们的评测集无法做到无穷无尽,而最终得到的评测集往往会与真实世界有一定的偏差,因为人所能理解的概念和评测集形成的渠道都是有限的。
尽管如此,我们还是希望以有限把握无穷,以少数的符号规则包含无限的事实,从有限的推导去抓住无限丰富的未知。我们希望用形式语言的方式,通过一些有限的描述符号集合,去生成无穷可能的问题。
知识问答从早期采用一阶谓语来做知识表示,过渡到产生式规则再到当前的语义网络,其每种表示方式都在不断的尝试用符号来做语义表示。直到语义网 RDF,RDFS,OWL 等表示框架的提出,才让语义表示可以更贴近人脑认知,可以更好的落地。
类似 OWL 等,为了增强其表达能力,增加了很多词汇,比如 owl:equivalentClass 等价类,owl:allValuesFrom 全称限定等。
而本文构造的评测集是融合了更多应用场景的技术和图谱算子能力的一种评测集构造方式。技术包括 ner,属性映射,实体对齐等,图谱算子能力包括求最值,最交集等能力。
2. 元素符号
一个问题就是若干三元组的组合,每个三元组表达的知识之间的组合符合是有所不同的,这里把组合符号分成了 3 类,分别是当每组知识是单个元素,多个元素(多个元素又分为了确定性集合元素,不确定性集合元素)。
(1)单个元素
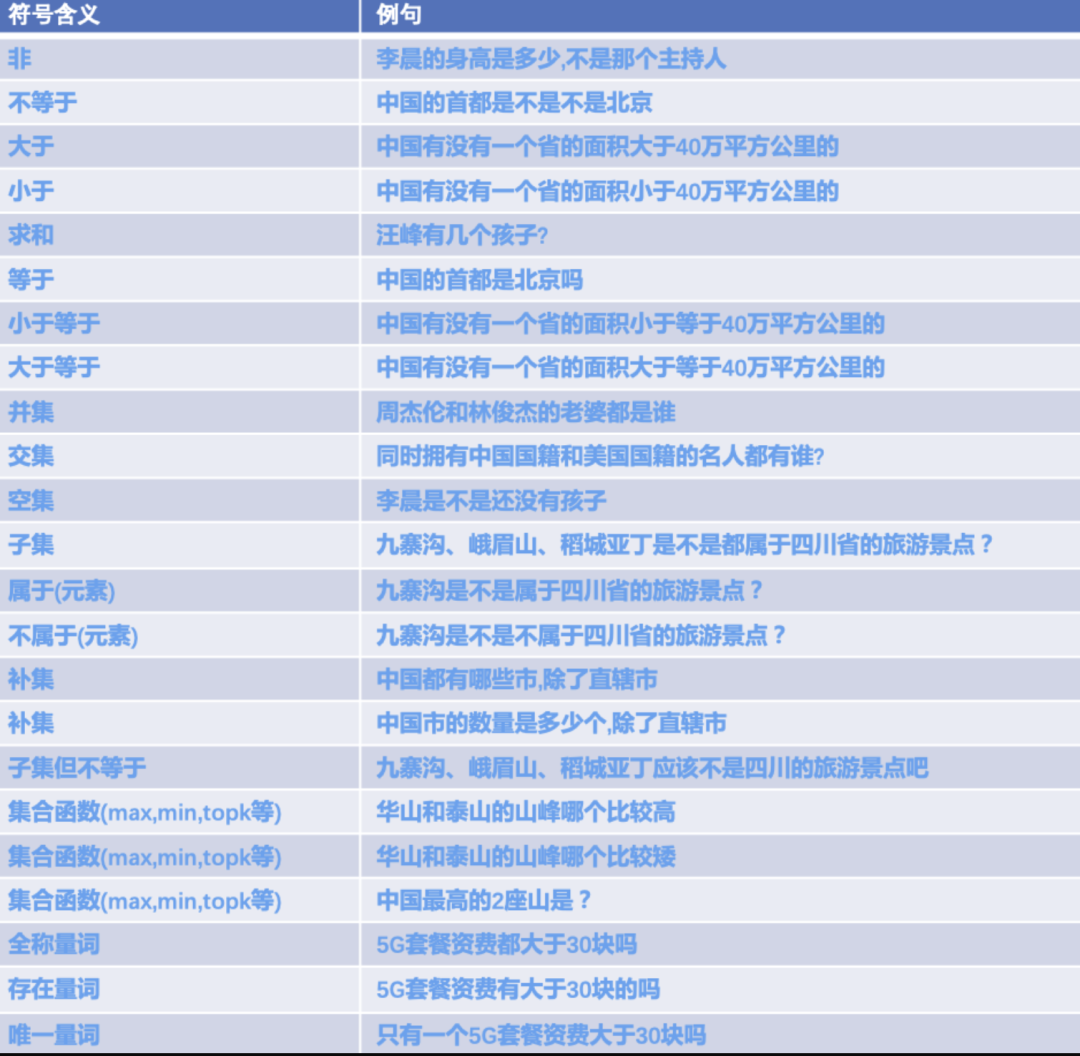
“这个 5G 套餐资费都大于 30 块吗”,其元素是指当前这一个“5G 套餐资费”。其对应的符号可以对单个元素进行修饰的有:大于,小于,大于等于,小于等于等。
(2)确定性集合元素
“既能做菜吃又是水果的食物都有哪些?”,其元素是指“做菜吃的食物”,“水果的食物”这两个不同的集合。
其对应的符号可以对集合元素进行修饰的有:交集,并集,包含等。
(3)不确定性集合元素
比如之前的例子:“5G 套餐资费都大于 30 块吗”和“5G 套餐资费有大于 30 块的吗”,如果“5G 套餐” 不止一个的话,那么前者指的是所有的资费是否大于,后者指是否存在一个。
针对上面这种情况我们引入量词,包括全称量词,存在量词,唯一量词来增加修饰能力。
以上是针对算子能力的评测集构造方法。
3. 元素标签
实际业务系统还有很多 ner,属性映射等问答能力需要去评估。基于此,我们针对上述每个三元组的元素增加了一维标签体系来对每个元素进行约束。
(1)sbj 标签
比如 sbj 的标签有 多义,别名,错字,漏字 等。多义表示这个 sbj 在图谱上有多个,比如"李晨",会存在一个主持人叫"李晨",也有一个演员叫"李晨"。
别名是指表达方式是某个实体的别名,比如"华仔","星爷"等。而错字表示表达方式包含错误字,比如"眉公河行动"。
(2)pred 标签
而 pred 的标签有 多义属性,别名属性,隐含属性 等。别名的,比如"周杰伦的高度是多少",这里"高度"可以作为“身高”这个属性的别名。
隐含属性,比如"周杰伦是不是有 1 米 7?",这里没有显示的问属性“身高”,但是隐含表达了这个想法。多义属性,比如“周杰伦有哪些作品”,这个作品可能是影视作品,也可能是音乐作品。
(3)obj 标签
object 的标签有 长度,金额,时间,温度,体积,字符 等。这些都很好理解,就不一一举例了。
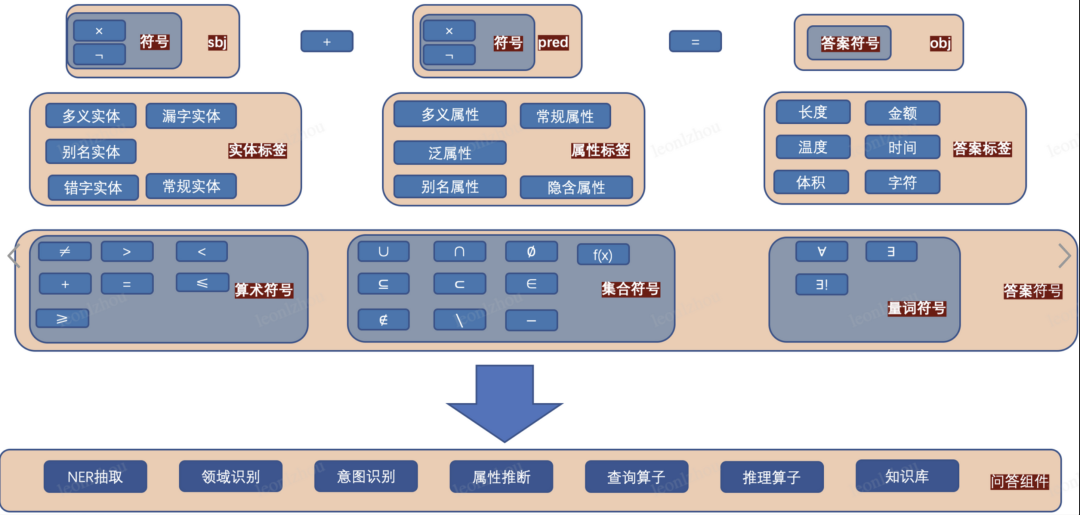
4. 评测集构造
通过上述符号体系,我们选定了目前知识问答系统几乎都会覆盖的百科人物问答领域来做落地。上图的例子也列举了一些地理类的问法。
在人物问答领域,娱乐人物的问答是高频的,所以我们选定的主体(subject)都是娱乐类人物,比如“胡歌”,“周润发”,“谢娜”等 100 个热门的人物实体;属性或者关系(predicate)我们选定的是娱乐人物都有的类型,包括“年龄”,“身高“,”体重“,”儿女“ 等。对应的 subject 标签有别名(“发哥”,“娜姐” 等),错字(“胡哥” 等);predicate 标签如上述体系中提到的,会包含多义属性,别名属性等;object 标签因为 predicate 的设计,会包含实体类型(儿子,女生等人物关系),长度(身高),重量(体重)等。
以上述类型为基本元素,我们将符号进行组合。
比如单个元素,大于,小于等可以适用于“年龄”,“身高”,“数量”,其对应的评测语料可以构造为:“娜姐的年龄是不是 38 岁了”(等于),“娜姐的年龄是不是大于 40 岁了?”(大于),“发哥有 75 公斤重吗?”(等于)。
多个元素确定性场景下,”邓超和孙俪的体重是多少“(并集),“宋丹丹一共几个丈夫”(求和),“王诗龄是李湘的女儿吗” (包含);不确定性场景下,“张学友和刘德华的年龄都大于 40 岁吗” (全称量词|大于),"杨丞琳和罗志祥体重有大于 110 斤的吗"(存在量词|大于)。
通过上述构造方法我们构造了一批人物地理类符号逻辑的评测集。
五、落地评测
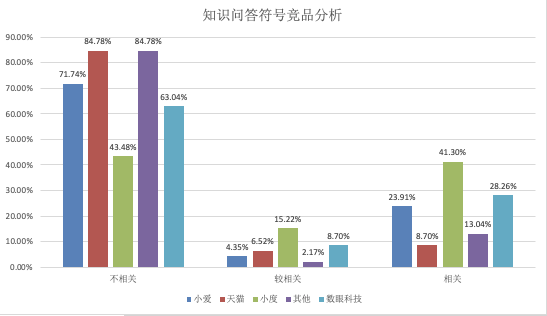
通过上述方法,我们选定了几个业界知名的知识问答产品进行评测,包括小爱,天猫,小度,数眼科技等,选定的评测领域为人物知识问答领域,评测的指标采用的是答案相关性(人工评估问答产品的回复与问题的相关性)。
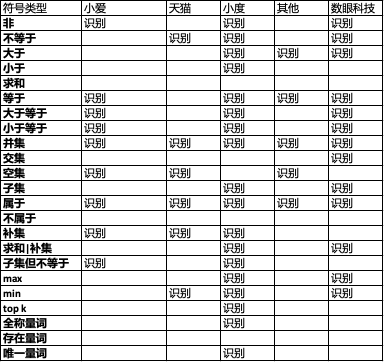
通过评测,我们发现当前几个主要的知识问答产品对这份考题的处理能力还待提高,效果最好的小度也仅处理了 41%的 query。
从效果上小度和数眼科技的复杂问题的理解能力较其他产品更优一些,比如在“周润发和谢娜谁的体重多”类似 max 的符号问法中,数眼科技的回复不仅能回复出答案“周润发”,还会给出其判断依据“[['73kg'], ['46kg']]”,可见其是具备这种求年龄的 max 算子的。
而小度因为有海量百度知道兜底,这类回复其实是走了百科,虽然答案是符合用户需求的,但是并不具备这种符号算子的理解能力。
当然因为是端到端的评测,实际上每个问答系统对每种符号的解析能力是不可知的,我们只是依靠这份评测集来对其处理能力进行有偏的推断。
六、总结
本文提出的这种符号构建高阶问答评测集的方法,提供了一种从更高纬度来对比知识问答原子能力的思路。
知识问答在实际产品上可能上述每种类型都要精细打磨才能有很好的效果。当然要评估其效果,必须得有一份考题。知识问答当前在某些垂直领域也在做的更细更复杂,希望这份考题能给大家带来一些启发和思考。
本文转载自公众号(ID:)。
原文链接:




