
本文最初发布于 Medium 网站,经原作者授权由 InfoQ 中文站翻译并分享。
原文链接:https://towardsdatascience.com/moving-from-pandas-to-spark-7b0b7d956adb
当你的数据集变得越来越大,迁移到 Spark 可以提高速度并节约时间。
多数数据科学工作流程都是从 Pandas 开始的。
Pandas 是一个很棒的库,你可以用它做各种变换,可以处理各种类型的数据,例如 CSV 或 JSON 等。我喜欢 Pandas — 我还为它做了一个名为“为什么 Pandas 是新时代的 Excel”的播客。
我仍然认为 Pandas 是数据科学家武器库中的一个很棒的库。但总有一天你需要处理非常大的数据集,这时候 Pandas 就要耗尽内存了。而这种情况正是 Spark 的用武之地。

Spark 非常适合大型数据集❤️
这篇博文会以问答形式涵盖你可能会遇到的一些问题,和我一开始遇到的一些疑问。
问题一:Spark 是什么?
Spark 是一个处理海量数据集的框架。它能以分布式方式处理大数据文件。它使用几个 worker 来应对和处理你的大型数据集的各个块,所有 worker 都由一个驱动节点编排。
这个框架的分布式特性意味着它可以扩展到 TB 级数据。你不再受单机器的内存限制。Spark 生态系统现在发展得相当成熟,你无需担心 worker 编排事宜,它还是开箱即用的,且速度飞快。

Spark 生态系统[参考]
问题二:我什么时候应该离开 Pandas 并认真考虑改用 Spark?
这取决于你机器的内存大小。我觉得大于 10GB 的数据集对于 Pandas 来说就已经很大了,而这时候 Spark 会是很好的选择。
假设你的数据集中有 10 列,每个单元格有 100 个字符,也就是大约有 100 个字节,并且大多数字符是 ASCII,可以编码成 1 个字节 — 那么规模到了大约 10M 行,你就应该想到 Spark 了。
问题三:Spark 在所有方面都比 Pandas 做得更好吗?
并非如此!对于初学者来说,Pandas 绝对更容易学习。Spark 学起来更难,但有了最新的 API,你可以使用数据帧来处理大数据,它们和 Pandas 数据帧用起来一样简单。
此外,直到最近,Spark 对可视化的支持都不怎么样。你只能对数据子集进行可视化。最近情况发生了变化,因为 Databricks 宣布他们将对 Spark 中的可视化提供原生支持(我还在等着看他们的成果)。
但在这一支持成熟之前,Spark 至少不会在可视化领域完全取代 Pandas。你完全可以通过 df.toPandas()将 Spark 数据帧变换为 Pandas,然后运行可视化或 Pandas 代码。
问题四:Spark 设置起来很困呢。我应该怎么办?
Spark 可以通过 PySpark 或 Scala(或 R 或SQL)用 Python 交互。我写了一篇在本地或在自定义服务器上开始使用 PySpark 的博文— 评论区都在说上手难度有多大。我觉得你可以直接使用托管云解决方案来尝试运行 Spark。
我推荐两种入门 Spark 的方法:
Databricks——它是一种完全托管的服务,可为你管理 AWS/Azure/GCP 中的 Spark 集群。他们有笔记本可用,与 Jupyter 笔记本很像。
Amazon****EMR 和 Zeppelin****笔记本——它是 AWS 的半托管服务。你需要托管一个 SparkEMR 端点,然后运行Zeppelin 笔记本与其交互。其他云供应商也有类似的服务,这里就不赘述了。

Databricks 是一种 Spark 集群的流行托管方式
问题五:Databricks 和 EMR 哪个更好?
我花了几个小时试图了解每种方法的优缺点后,总结出了一些要点:
EMR 完全由亚马逊管理,你无需离开 AWS 生态系统。
如果你有 DevOps 专业知识或有 DevOps 人员帮助你,EMR 可能是一个更便宜的选择——你需要知道如何在完成后启动和关闭实例。话虽如此,EMR 可能不够稳定,你可能需要花几个小时进行调试。DatabricksSpark 要稳定许多。
使用 Databricks 很容易安排作业——你可以非常轻松地安排笔记本在一天或一周的特定时间里运行。它们还为 GangliaUI 中的指标提供了一个接口。
对于 Spark 作业而言,Databricks 作业的成本可能比 EMR 高 30-40%。但考虑到灵活性和稳定性以及强大的客户支持,我认为这是值得的。在 Spark 中以交互方式运行笔记本时,Databricks 收取 6 到 7 倍的费用——所以请注意这一点。鉴于在 30/60/120 分钟的活动之后你可以关闭实例从而节省成本,我还是觉得它们总体上可以更便宜。
考虑以上几点,如果你开始的是第一个 Spark 项目,我会推荐你选择 Databricks;但如果你有充足的 DevOps 专业知识,你可以尝试 EMR 或在你自己的机器上运行 Spark。如果你不介意公开分享你的工作,你可以免费试用 Databricks 社区版或使用他们的企业版试用 14 天。
问题六:PySpark 与 Pandas 相比有哪些异同?
我觉得这个主题可以另起一篇文章了。作为 Spark 贡献者的 Andrew Ray 的这次演讲应该可以回答你的一些问题。
它们的主要相似之处有:
Spark 数据帧与 Pandas 数据帧非常像。
PySpark 的 groupby、aggregations、selection 和其他变换都与 Pandas 非常像。与 Pandas 相比,PySpark 稍微难一些,并且有一点学习曲线——但用起来的感觉也差不多。
它们的主要区别是:
Spark 允许你查询数据帧——我觉得这真的很棒。有时,在 SQL 中编写某些逻辑比在 Pandas/PySpark 中记住确切的 API 更容易,并且你可以交替使用两种办法。
Spark 数据帧是不可变的。不允许切片、覆盖数据等。
Spark 是延迟求值的。它构建了所有变换的一个图,然后在你实际提供诸如 collect、show 或 take 之类的动作时对它们延迟求值。变换可以是宽的(查看所有节点的整个数据,也就是 orderBy 或 groupBy)或窄的(查看每个节点中的单个数据,也就是 contains 或 filter)。与窄变换相比,执行多个宽变换可能会更慢。与 Pandas 相比,你需要更加留心你正在使用的宽变换!
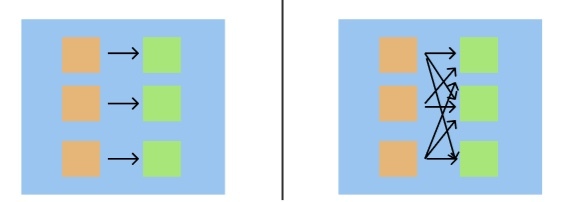
Spark 中的窄与宽变换。宽变换速度较慢。
问题七:Spark 还有其他优势吗?
Spark 不仅提供数据帧(这是对 RDD 的更高级别的抽象),而且还提供了用于流数据和通过 MLLib 进行分布式机器学习的出色 API。因此,如果你想对流数据进行变换或想用大型数据集进行机器学习,Spark 会很好用的。
问题八:有没有使用 Spark 的数据管道架构的示例?
有的,下面是一个 ETL 管道,其中原始数据从数据湖(S3)处理并在 Spark 中变换,加载回 S3,然后加载到数据仓库(如 Snowflake 或 Redshift)中,然后为 Tableau 或 Looker 等 BI 工具提供基础。

用于 BI 工具大数据处理的 ETL 管道示例

在 Amazon SageMaker 中执行机器学习的管道示例
你还可以先从仓库内的不同来源收集数据,然后使用 Spark 变换这些大型数据集,将它们加载到 Parquet 文件中的 S3 中,然后从 SageMaker 读取它们(假如你更喜欢使用 SageMaker 而不是 Spark 的 MLLib)。
SageMaker 的另一个优势是它让你可以轻松部署并通过 Lambda 函数触发模型,而 Lambda 函数又通过 API Gateway 中的 REST 端点连接到外部世界。
我写了一篇关于这个架构的博文。此外,Jules Damji 所著的《Learning Spark》一书非常适合大家了解 Spark。
本文到此结束。我们介绍了一些 Spark 和 Pandas 的异同点、开始使用 Spark 的最佳方法以及一些利用 Spark 的常见架构。
如有任何问题或意见,请在领英(https://www.linkedin.com/in/sanketgupta107/)上联系我!
资源:




