
由于要集成客户的数据堆栈,所以我们需要提供最高级别的安全性和遵从性。问题是:我们将如何构建它们?SaaS 吗?On-prem 吗?还是别的什么方法?为了实现这些目标,我们选择了混合部署架构,这是一种结合了 on-prem 安全性和 SaaS 便利性的新方法。本文将解释我们做出这一选择的原因。
本文最初发布于 Towards Data Science,经原作者授权由 InfoQ 中文站翻译并分享。
随着公司接收和存储的数据越来越多,比以往任何时候都要多,并且对这些数据的访问和使用方式的审查也越来越严格,在现有的数据基础设施中新增任何类型的第三方解决方案都隐含着一定的安全问题。
事实上,在 GDPR、CCPA、HIPAA(还有许多其他重要的缩写)的时代,管理复杂的数据系统和保持敏感数据的安全是两个截然不同的问题,没有一个适用于所有问题的解决方案。
对于数据负责人而言,选择解决哪个问题完全取决于你。
传统的 on-prem 部署模型

On-prem 部署架构,第三方软件在客户的环境中运行,提供了更高的安全性,但代价是速度和运营效率。图片由作者提供。
On-premises(on-prem)指传统的部署模型,软件运行在客户的环境中,通常在专用 VPC 内。特别是,服务存储或处理的所有数据都保留在客户的云中。
优势
虽然供应商编写代码,但客户保持对数据的完全控制和所有权。
On-prem 解决方案向客户提供二进制文件和许可密钥(对于授权软件),由客户管理部署。无数软件产品选择了这种传统的部署模型。例如 MemSQL 和 Splunk 早期的 on-prem 产品,需要依赖客户的工程和 IT 团队来处理部署。与 SaaS 解决方案相比,on-prem 平台通常根据客户的需求提供更好的定制和配置。
对于客户来说,选择使用 on-prem 架构的供应商,一个明显的好处是可感知的安全性和遵从性。通过将数据保存在客户的环境中,on-prem 架构不暴露与外部各方的连接。此外,由于所有的数据和软件都存放在客户的云里,供应商无法访问任何敏感信息。
挑战
On-prem 部署模型要求客户承担大部分的运营开销。客户必须自己分析解决灾难恢复问题,例如应用程序中断和数据停机,这可能会耗费大量的时间,并导致低于标准的体验。
On-prem 模型的第二个限制是部署速度慢,无论是基线软件还是未来任何产品更新。由于软件存在于客户的环境中,升级可能是一个冗长的过程,需要大量的访问权限和额外的资源。
SaaS 部署模型
软件即服务(SaaS)解决方案提供托管在供应商云中的现成软件,客户可以立即获得并使用这些软件。在这个模型中,软件由供应商运行和管理,客户数据存储在供应商的云中。在 Salesforce 的引领下,Snowflake、Segment和Chartio是近年来数据世界的著名案例。
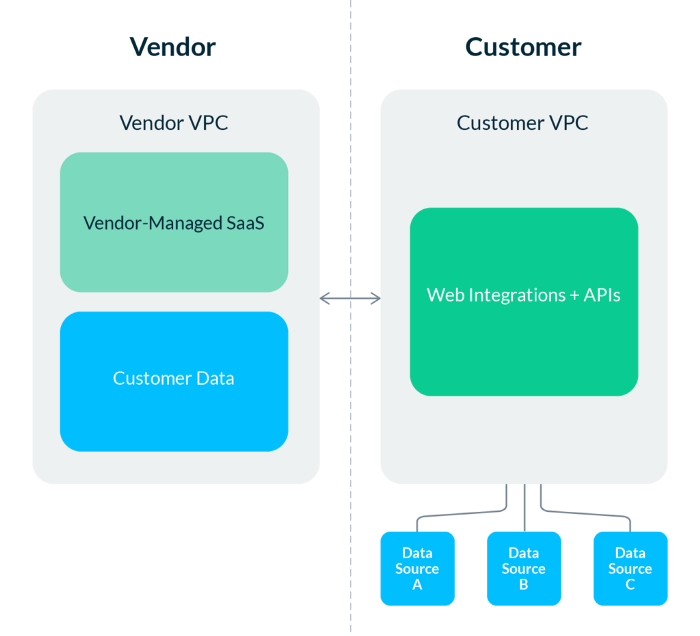
SaaS 模型托管在供应商的云环境中,允许快速部署和轻松更新,但会带来额外的数据安全和访问问题。图片由作者提供。
优势
SaaS 模型使供应商更容易进行更新、推出新功能并大规模地解决常见问题,而不是将更改推送到单个客户的环境中。对许多人来说,这通常都是以较低的成本创造了更令人愉快的用户体验。这也扩展到了软件的维护,这是将这项工作外包给最了解软件的供应商。
挑战
当将数据混合在一起时,SaaS 模型就会变得更复杂,特别是当关系到遵从性需求和数据锁定时。
尽管任何自重的 SaaS 提供商都会对静态数据进行加密,但它仍然被锁定在供应商的环境中。因此,许多客户不愿意(或出于监管原因不能)完全放弃数据的管理和存储。
即使客户愿意签字将数据存储在自己的环境之外,他们仍然必须接受这样一个事实,即数据现在完全锁定在供应商的控制之下。
那么,如何才能获得 on-prem 解决方案的遵从性和灵活性优势,同时又具备 SaaS 供应商的易于部署和便利性呢?
我们相信,现代数据产品有一个更好的发展方向:混合架构。
混合部署模型
在过去的十年里,我们看到,越来越多的软件工程和 DevOps 团队利用混合云架构来管理基础设施即服务应用程序,包括New Relic和Atlassian。最近,许多数据软件供应商也做出了类似的设计决策。
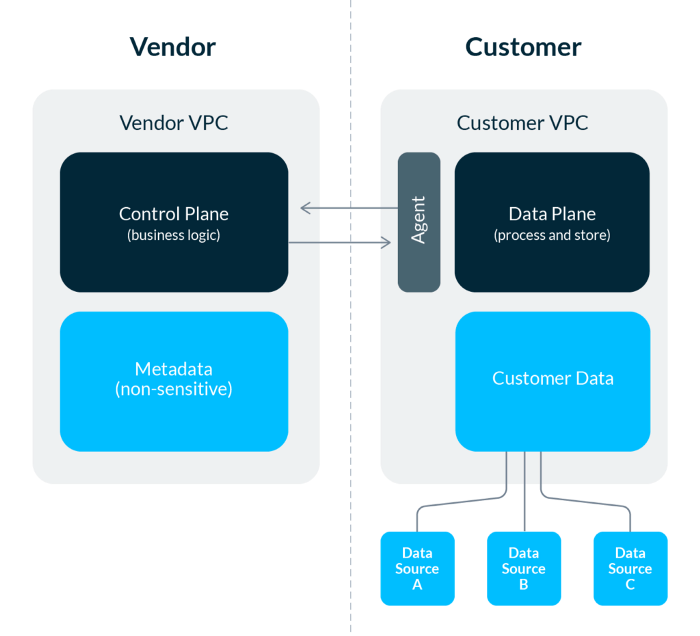
混合架构模型利用了软件工程和 DevOps 架构的最佳实践,将 on-prem 的安全性与 SaaS 部署的易用性结合起来。图片由作者提供。
为了在现代数据栈中将 SaaS 世界和 on-prem 世界的精华结合到一起,数据软件的买家应该考虑采用混合架构的解决方案。该方法由两部分组成:(1)由供应商管理的控制平面;(2)客户环境中的数据平面。
控制平面
通常,控制平面承载着软件的大部分业务逻辑,并处理不敏感的元数据。它与数据平面通信,并将敏感操作(如处理、存储或删除数据)委托给数据平面。控制平面还提供 Web 页面和 API 接口,并监视数据平面的运行状况。控制平面完全运行在供应商的环境中,通常遵循多租户架构,但有些供应商提供了单租户控制平面(通常需要额外付费),该控制平面运行在客户专用的、完全隔离的 VPC 中。
数据平面
数据平面通常处理和存储客户的所有敏感数据。它必须能够接收来自控制平面的指令,并传回有关其操作和运行状况的元数据。从技术上讲,控制平面和数据平面之间的接口通常是由运行在客户环境中的瘦代理来实现的。一些供应商甚至可以完全跳过代理,完全利用跨云帐户的 IAM 角色。
从本质上讲,将客户数据与管理软件分离开来,使客户获得了 SaaS 产品的灵活性,同时还拥有 on-prem 解决方案的遵从性和数据所有权,并始终将客户数据保存在客户的云环境中。
快速参与,缩短价值实现的时间
通常,这种混合架构使客户能够快速部署软件,而且只需很少的人工开销。
与此同时,这种快速参与使客户能够即时看到产品的效果,并在短期内从他们的数据或 ML 模型中快速获得价值。
通常,作为这种部署模型的一部分,采用混合解决方案的供应商会提供随叫随到的技术支持,这是他们产品的一个关键特性——几乎就像为客户提供一个嵌入式的 SRE 团队。
将复杂的基础设施与客户敏感数据的管理分开
混合模型的最大好处之一是,它不需要客户配置或维护供应商复杂的基础设施,同时让客户可以完全控制他们的数据。
一种方法是通过代理或跨帐户角色让供应商可以访问“数据平面”,提取诸如元数据、查询日志和聚合统计数据等信息。与许多 SaaS 产品不同,该方法不会从客户的数据仓库、数据湖或 BI 工具中提取个人记录或个人识别信息,并存储在供应商的云上。
这种混合方法还有助于添加控制供应商帐户权限范围的“旋钮(knob)”(例如,越宽松,客户方的管理就越少,反之亦然)。这让客户在数据访问和安全方面拥有更大的自主权,这对金融科技和医疗保健等行业至关重要,因为这些行业存在大量的敏感数据,对错误的容忍度很低,甚至完全不能容忍。
通过让供应商管理服务的计算资源,可以确保产品的任何问题都可以通过供应商快速解决,而不给客户带来负担。数据代理解决了这个问题,并确保基础设施可以轻松地维护、调试和更新,而无需客户投入资源。
给正在阅读本文的供应商的建议:我们建议您尽早取得 SOC2 认证——稍后您会感谢我们的。许多企业,特别是 GDPR、HIPAA 和 SOX 合规行业中的企业,在考虑与您合作之前都需要这个。
快速、持续的软件升级
混合部署模型将稳定的云原语(如 S3、EMR、DynamoDB)保存在客户云中,并将所有不断改进、快速变化的基础设施(即产品本身)保存在托管云中。因此,客户可以比较轻松地将新的解决方案集成到他们的数据栈中,因为与复杂的 on-prem 软件相比,尝试和开始使用混合模型成本要低得多。与在客户的私有云中托管服务相比,在供应商的环境中托管服务还可以让推出面向所有客户的更新更容易、更顺畅。
在供应商的环境中托管服务意味着客户可以访问新特性,确保创新和产品开发不是竖井驱动的。客户甚至不需要知道不同的软件版本和缓慢的升级周期——他们可以放心,他们将永远使用最新、最好的版本,而且是完全自动的。
混合模型为客户提供了选择如何使用产品的灵活性,例如,他们可能想要跨整个数据栈部署它,或者只在几个选定的数据环境中部署它,并且可以根据需要轻松地添加或删除服务实例。
为灵活、安全的数据栈指明方向
虽然我们在创立 Monte Carlo 和 Tecton 时并不认识对方,但我们最终为我们的产品选择了类似的架构。这种混合模型最终成为我们为数据和 ML 组织提供支持的关键,同时也得到了安全团队的批准。
通过利用 SaaS/on-prem 混合架构,解决方案提供商可以构建易于部署的数据产品,几乎不需要客户承担任何运营开销,促进完全的数据所有权,而且可能最重要的是,最大限度地确保数据安全性和遵从性。
英文原文链接:Data Software-as-a-Service: the case for a hybrid deployment architecture




