
API 网关(API-Gateway)是整体系统的唯一入口,作为流量入口,统一处理请求。它具有以下传统的功能:
反向代理和负载均衡;
动态上游、动态 SSL 证书和动态限流限速等运行时的动态功能;
对上游的主动和被动健康监测。
其他附加功能:
身份认证,限流熔断,统计,性能分析等。
网关主要有两种类型:
接入层网关,为多样的客户端提供统一的流量入口,通过不同路由策略进行负载均衡,主要负责的是路由,限流,日志,缓存等功能,我们使用的是 Kong;
应用层网关,提供服务注册、服务发现以及熔断功能,我们当前使用的是 sidecar(ZuulFilter)。
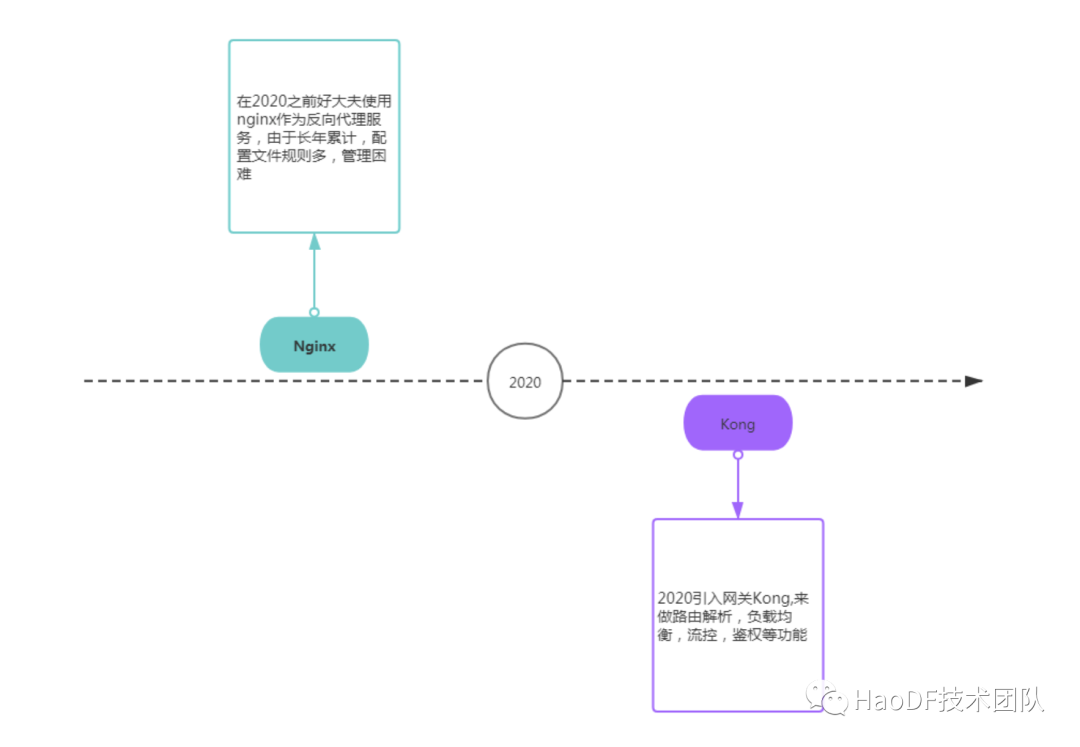
好大夫的接入层网关最初使用的 nginx,在 2020 年初替换成 Kong。
2.1 为什么我们用 Kong 替换现有的 Nginx?
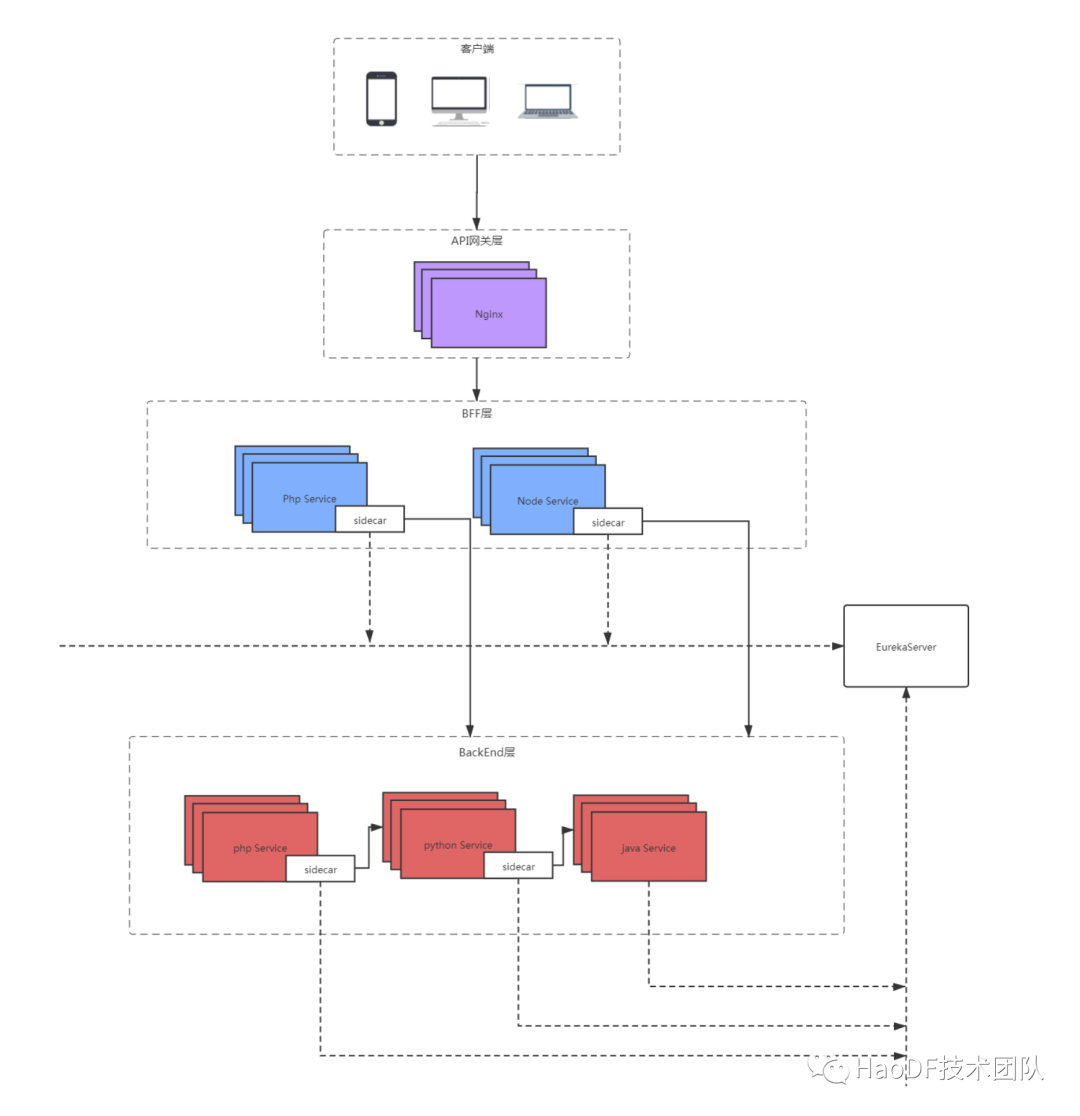
名词解释:
BFF(Backend For Frontend)聚合层:将后端微服务适配到不同前端;
Sidecar:我们使用的应用层网关,实现异构语言的服务注册和发现,以及熔断限流功能;
Microservices:微服务。
先聊一聊好大夫在线的架构:
API 网关层,提供客户端流量的唯一入口,用于做反向代理和负载均衡,最初使用的 nginx 提供一些如路由、缓存、访问控制等基本功能;
BFF 层,我们主要有 PHP(老)和 NodeJs(新)两类,这一层主要是做接口聚合,以及业务逻辑层的权限验证等;
BackEnd 层,是我们的微服务层,是多语言实现的(php,java,python),其中 php,python 通过 sidecar 注册到 Eureka 上,java 本身支持服务注册和发现到 Eureka。
我们引入网关 Kong 的契机是线上的流量有一部分是模拟用户抓取类流量,它的特点在于 QPS 的波动很大,当一波集中的抓取到来时,BackEnd 服务可能会因为 QPS 突增,导致机器负载的升高,响应变慢,同时影响正常用户的访问。如果不及时处理可能会引起雪崩效应。
为了解决这个问题,我们需要细化区分各种流量,要有较强的识别和控制能力,以保障正常用户、正常抓取的流量,同时排除掉异常访问的流量。在未引入 Kong 之前,我们能想到的办法是在 Api 网关 nginx 层做流量控制,以及在我们的应用层网关 sidecar 做流量控制。但是这两种方案都有一定的问题:
使用 nginx 进行流量限制,问题在于 nginx 的配置规则是以静态文件的形式进行管理的,无法通过 api 或者后台灵活的修改流量的封禁、降级和调度策略,同时配置生效需要 reload;
从我们的架构图可以看出,应用层网关 Sidecar 只负责处理服务出口的流量(即请求发起端),发起端可能来自各个系统,因此通过 Sidecar 进行发起端限流,限流值设置的波动会非常大,粒度也因为过细而不好控制。
以上两种解决方案,对我们日常精细化运维流量都不够友好,所以经过调研,决定在接入层引入 Kong 来替换 nginx,进而从源头细化流量。
2.2 网关选型,为什么选择 Kong

从表格上可以看来,Kong 的社区的活跃度比较高,基础插件功能支持的也比较多,而且 Kong 的技术栈是 nginx+lua+openresty,从学习成本上来说,由于我们原先的技术栈是 nginx 的,因此选用 Kong 的学习成本会比其他语言的网关低很多,而且在迁移老的 nginx 配置过程中,转化旧配置的 nginx 配置也会比较友好,所以我们最终决定选择 Kong。
2.3 Kong 网关介绍
Kong 是一款基于 OpenResty(Nginx + Lua 模块)编写的高可用、易扩展的,由 Mashape 公司开源的 API Gateway 项目。Kong 是基于 Nginx 和 Apache Cassandra 或 PostgreSQL 构建的,能提供易于使用的 RESTful API 来操作和配置 API 管理系统。
Kong 的优势:
可扩展:数据存储在 PostgreSQL 数据库中,连接相同数据库的节点为同一集群,方便集群的水平扩展。
模块化:可以通过插件功能来扩展 Kong 的功能,官方提供了一些免费的开源插件,而且自定义开发相对来说简单,插件的通过 RestFul 接口进行配置,非常灵活。
可视化:Kong 所有规则对象都提供 RestFul 的接口,这就意味着可以实现配置的可视化管理,开源的工具:Konga。
2.3.1 Kong 的基本概念
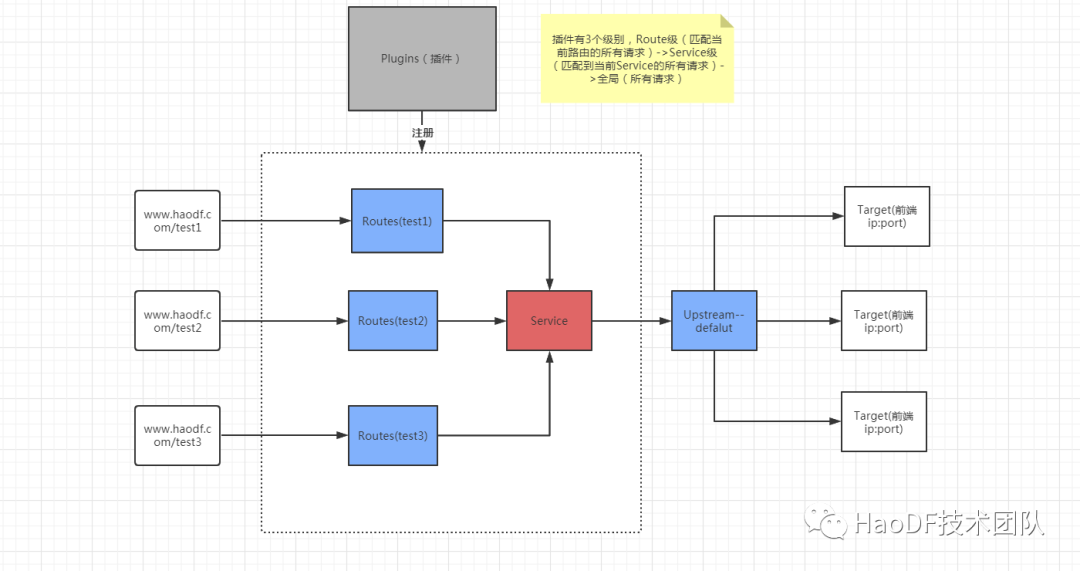
名词解释:
Route 路由通过 host, path, header 等维度匹配客户端 url, 如设置规则 host:www.haodf.com path:/test1 匹配 url: http://www.haodf.com/test1。
Service 服务是对后端服务的抽象。
Upstream 负载均衡对象,用于设置主动或者被动心跳检测机制,负载均衡规则(轮询或者 hash)等。
Target 配置的是后端服务的实际 ip 和端口。
Plugins 插件,附加功能支持身份验证,限流,拦截等,可作用层级 Route,Service,全局。
请求流程简要说明:
当客户端发起请求时流量会先统一打到 Kong,Kong 通过 Route(路由)对象来匹配规则,再通过 Route 去找当前请求对应的 Service 服务,最后通过 Upstream 负载均衡至后端机器。附加功能(身份验证,黑白名单等)通过 Plugins 插件的形式,附加到 Route 或者 Service 上动态加载,作用于 nginx 请求的各个阶段。
2.3.2 Kong 插件加载
Kong 的限流、身份验证等功能都是通过插件来实现的,我们来了解一下 Kong 插件的加载机制。
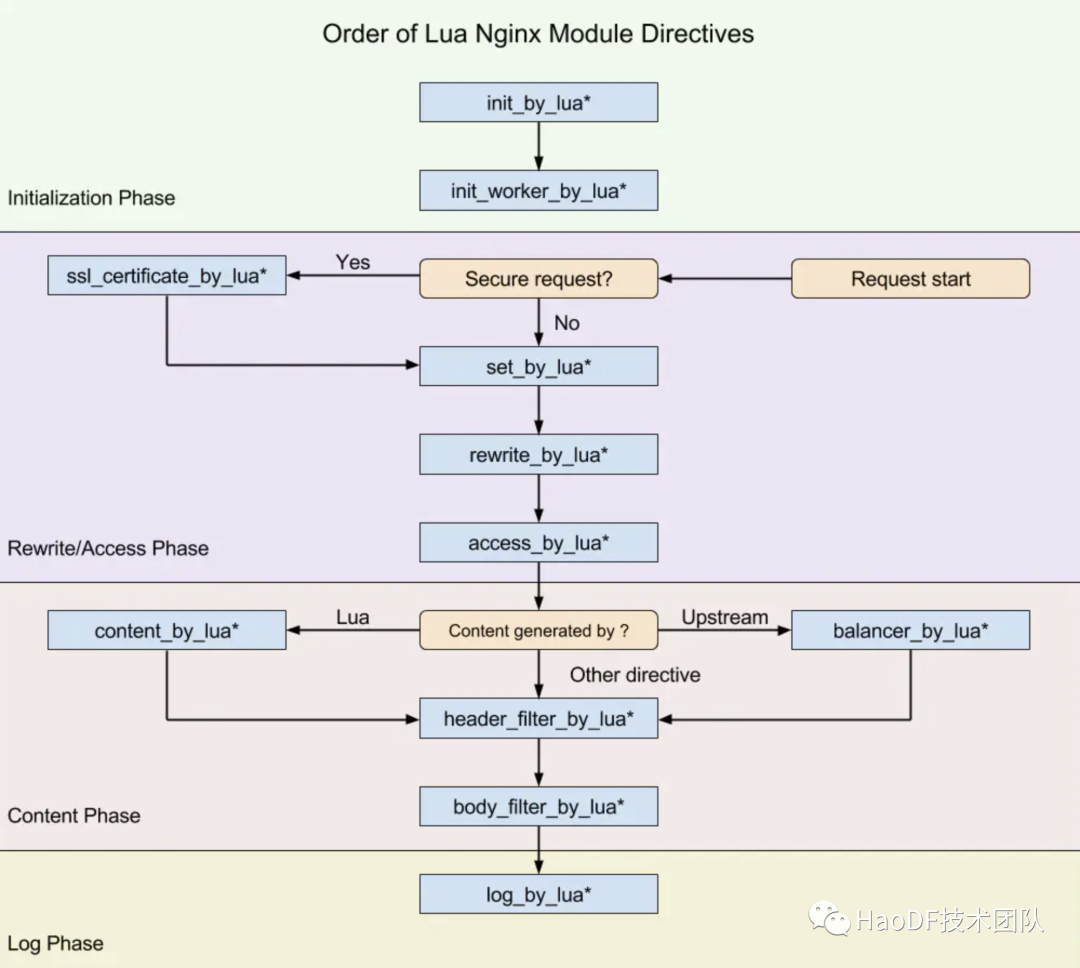
Kong 是 nginx+lua+openresty 的一个实现,上图描述的是 openresty 运行的各个阶段。
init_by_lua 用于加载 nginx master 进程配置,init_worker_by_lua 用于加载 nginx worker 进程的配置,rewrite_by_lua 是用于重写 url 和使用缓存的阶段,access_by_lua 用于权限控制,限流等功能,header_filter_by_lua 用于对 response header 头进行处理,body_filter_by_lua 用于对 respone body 体进行重写,log_by_lua 用于请求的日志记录。
Kong 就是在 openresty 各个阶段加入了 Kong 的 lua 代码来实现一些 Kong 的功能,以下是 Kong 的 nginx 简要配置。
init_by_lua_block { kong = require 'kong' kong.init() // 完成 Kong 的初始化,路由创建,插件预加载等}init_worker_by_lua_block { kong.init_worker() // 初始化 Kong 事件, worker 之间的事件,由 worker_events 来处理, cluster 节点之间的事件,由 cluster_events 来处理,缓存机制}upstream kong_upstream { server 0.0.0.1; balancer_by_lua_block { kong.balancer() //负载均衡 } keepalive 60;}# ... 省略若干location / { rewrite_by_lua_block { kong.rewrite() //插件生效策略的筛选,并执行对应的操作,只能处理全局插件(kong插件级别,全局(作用于所有请求),route(作用于当前路由),service(作用于匹配到当前service的所有请求)),路由匹配未开始。 } access_by_lua_block { kong.access() //1.完成路由匹配,2.确认加载的插件(并加入缓存) 3.进入balancer阶段 } header_filter_by_lua_block { kong.header_filter() //遍历在缓存中的插件列表,并执行 } body_filter_by_lua_block { kong.body_filter() //遍历在缓存中的插件列表,并执行 } log_by_lua_block { kong.log() //遍历在缓存中的插件列表,并执行 }}Kong 插件加载源码
for plugin, plugin_conf in plugins_iterator(singletons.loaded_plugins, true) do plugin.handler:rewrite(plugin_conf)end上述的源码是 Kong 在 rewrite 的阶段执行的,主要工作就是对已加载的插件进行遍历,然后执行各个插件的 rewrite 方法,其他阶段的插件执行基本也都是这个逻辑。因此简单来说,Kong 插件加载就是在 openresty 的各个执行阶段,对符合规则的插件进行遍历,然后执行这个节点插件对应的方法。
2.3.3 好大夫插件功能使用
Kong 原生插件:
rate-limiting 限流插件;
file-log 本地日志存储;
acl 访问控制列表;
key_auth 身份验证;
自定义插件:
灰度发布插件;
rate-limiting-agent 插件;
rate-limiting,rate-limiting-agent 与 key_auth 结合实现按角色进行限流
我们的网站无时不刻的有流量在访问,如果流量远远大于我们系统可承载的范围的话,会导致系统的响应时间变慢,系统的吞吐量下降。因此为了防止这种情况的发生,我们对网站的各个路由都设置了限流规则。
流量划分
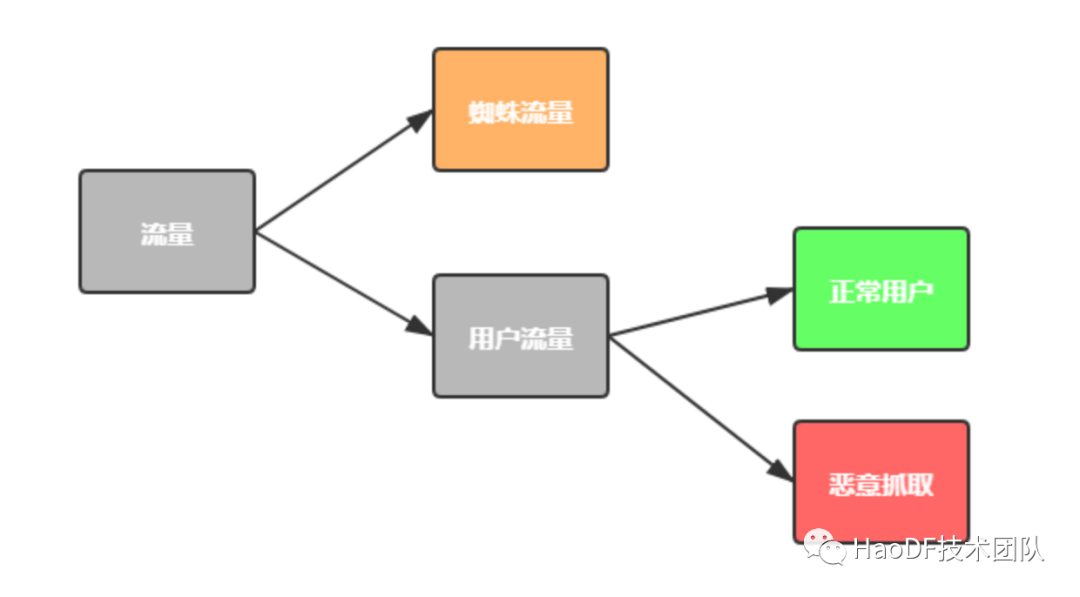
我们将流量区分为:正常用户的流量,蜘蛛流量,恶意抓取的流量。
1.其中蜘蛛流量和用户流量是根据 UA 进行划分的,蜘蛛流量的 UA(User-Agent)上会带有特殊的标识,比方说 spider,bot 等。
2.用户流量中根据访问行为分为了正常用户流量和恶意抓取的流量,对于我们网站而言,恶意抓取的流量的特点在于 ip 很散,但是 UA 不变,而且访问在短时间内突增。
限流流程
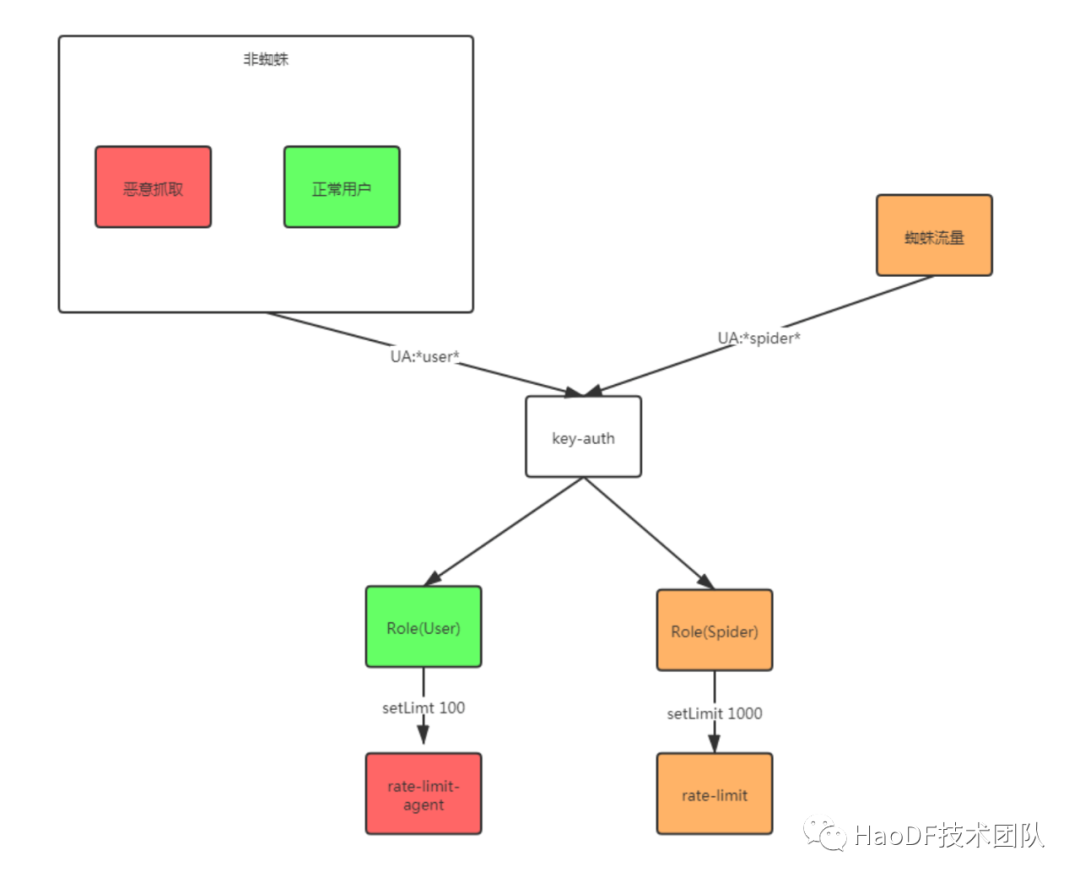
(1)通过 key_auth 插件根据 UA 的特殊标识,将蜘蛛流量和用户流量进行角色上的划分。
(2)在蜘蛛角色的路由上设置 rate-limiting 限流插件,对蜘蛛的流量进行限流,限流值的设定是通过压测以及长期观察前端请求数与后端容量得到的结果。
(3)用户角色中含有正常用户的流量和恶意抓取的流量,我们认为同一个 UA 的请求属于一个用户,而在短时间内同一个 UA 流量突增的请求属于恶意流量,因此对用户角色设置了 rate-limit-agent 限流插件,限制同一个 UA 单位时间的请求量。
告警监控
限流值的设置与调整是一个长期观察的过程,因此我们配套的做了一些监控画像,并在大量限流发生时进行告警。
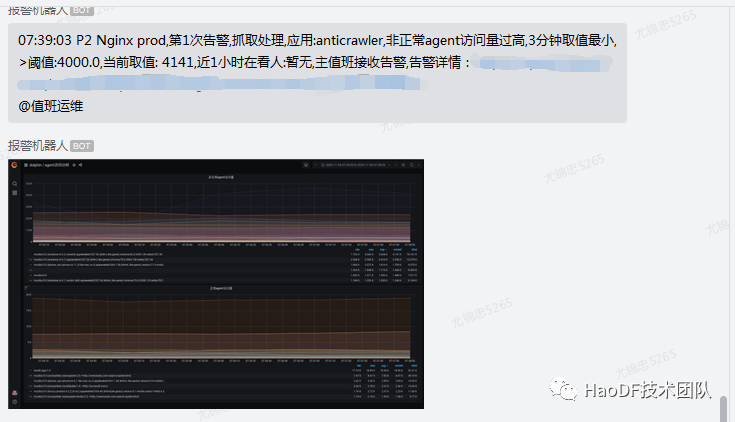
1.非正常 UA 抓取(恶意流量)监控

非正常告警就是恶意流量,从监控图像上我们可以看出当前流量增长的 UA 是哪一个,在极端情况下我们可以对这个 UA 进行封禁(封禁操作可能会“误杀”到正常用户)。并且当抓取流量超过我们设置的阈值时,会触发告警。
2.触发限流的监控
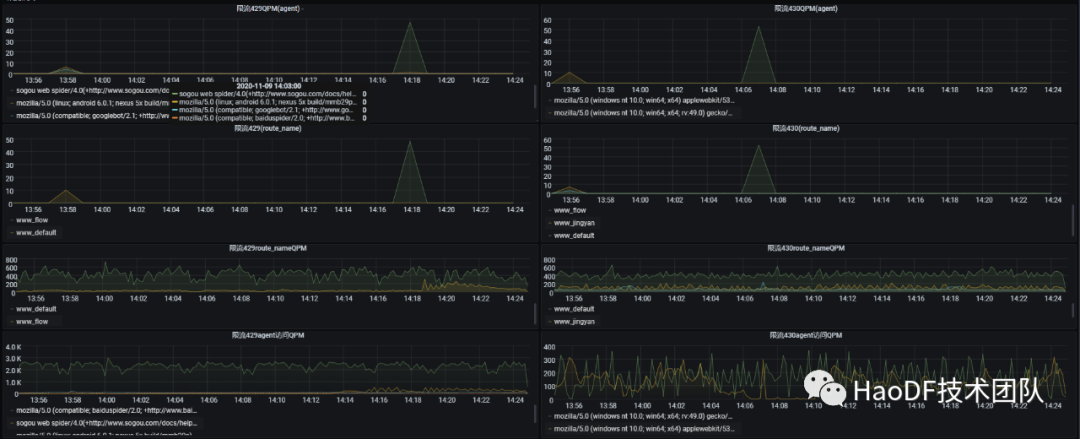
当触发限流告警时,我们可以从监控画像中看出当前限流的 UA 与路由是哪个,以及当前 UA 与路由抓取的频率,同时还可以在触发告警时观察后端系统的容量,吞吐量,响应时间是否达到瓶颈,由此为依据我们就可以知道限流值设置是否合理。
通过 key_auth,acl 和 filelog 实现 kong 集群数据节点和控制节点的分离。
kong 分为 proxy 配置默认监听 8000 端口,用于接收客户端流量。admin 配置默认监听 8001 用于管理 kong 的配置项。
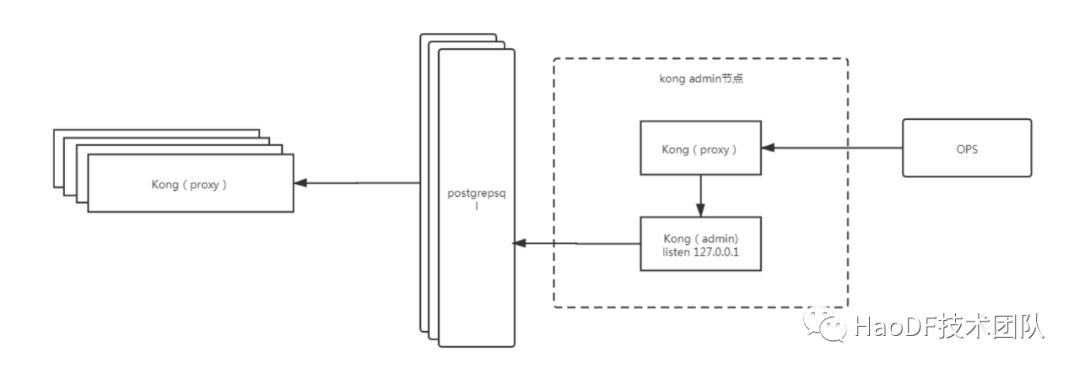
(1)部署上,我们将 Kong 分为 proxy 节点集群和 admin 节点,proxy 节点只用来接收来自客户端的数据,admin 节点用于修改 Kong 的配置(路由规则,Service 规则,插件规则等)。
(2)只有 Kong admin 节点用于做 Kong 规则配置,设置 admin 监听范围为 127.0.0.1 的 8001 接口,缩小 admin 功能的访问范围,只有本机可以访问。
(3)非本机访问的请求只能通过 kong proxy 转发到 kong admin 的本地端口,通过 kong 的 proxy 代理使我们可以对这部分请求附加插件功能来做身份验证。
(4)OPS(好大夫内部的 DEVOPS 平台)调用和其他脚本调用需要加上特殊的 header 头标识用于做角色区分,通过 key_auth 设置角色,并通过 acl 设置黑白名单,来限制访问,最后通过 filelog 记录操作日志。
灰度发布插件
好大夫的容器化正在如火如荼的进行中,所以线上的金丝雀发布需求,理所当然的就由 Kong 来接管了。目前灰度插件支持两个维度的灰度需求:
根据固定 ip 或者 ip 段进行灰度;
根据指定 cookie 进行灰度;
这样我们就可以根据业务需求,将部分流量(如:北京地区 10%的非登录用户)引入指定集群进行灰度测试了。
2.3.4 遇到的问题
nginx filecache 缓存替换的问题
之前,我们的前端缓存使用的是 nginx 自带的 nginx_proxy_cache 模块实现的,是磁盘类型的缓存,按现在的规模单台缓存大概在 200G 左右。在对接 Kong 的过程中,我们调研过两个方案:
Kong 自带的 proxy_cache 插件。这个插件实现的是内存级别的缓存,主要的问题是当 Kong 节点重启时,缓存会被重置,数据需要重新缓存,缓存相当于被穿透,会带来一定的风险。
我们尝试通过自定义 Kong 插件+nginx_proxy_cache 模块来实现与原先逻辑一致的文件缓存,但是遇到一个无法解决的问题:nginx 的 purge_cache_valid 参数不支持变量形式,这个参数是用来设置缓存时间的,无法以变量形式实现,也就意味着缓存只能设置一个通用时间,业务场景会因此受限。
所以,我们的前端缓存处理,目前还是放在 nginx 这一层了。
三、写在最后
本文主要对 API 网关的基本概念,以及 Kong 在好大夫落地的实践做了一些介绍。我们正在继续研究如何使用 Kong 来解决 filecache 的问题,以完全替换前端 Nginx,欢迎有相关经验或者问题的朋友给我们留言,大家一起学习和研究。
作者介绍:
尤锦忠:好大夫在线系统开发工程师,负责底层框架的开发和维护,主导接入层网关 Kong,目前在参与公司容器化落地实施。




