
文 / 张迎
摘要
在作业帮实时计算演进过程中,Flink 起到了重要的作用,特别是借助于 FlinkSQL 极大的提高了实时任务的开发效率。
这篇文章主要分享 FlinkSQL 在作业帮的使用情况、实践经验,以及随着任务规模增长,在从 0 到 1 搭建实时计算平台的过程中遇到的问题及解决方案。
一、发展历程
作业帮主要运用人工智能、大数据等技术,为学生提供更高效的学习解决方案。因此业务上的数据,主要是学生的到课情况、知识点掌握的情况这些。整体架构上,无论是 binlog 还是普通日志,经过采集后写入 Kafka,分别由实时和离线计算写入存储层,基于 OLAP 再对外提供对应的产品化服务,比如工作台、BI 分析工具。
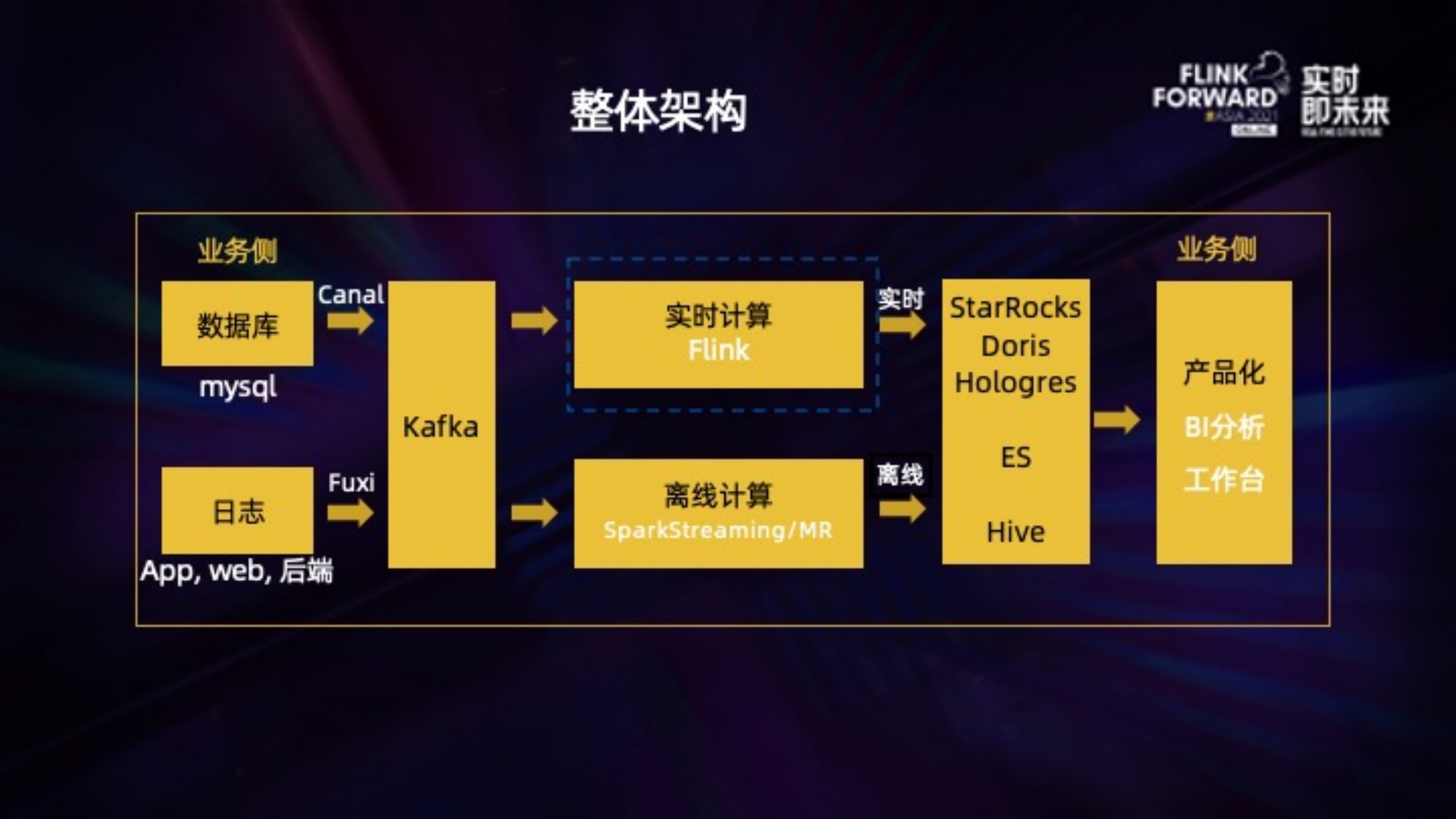
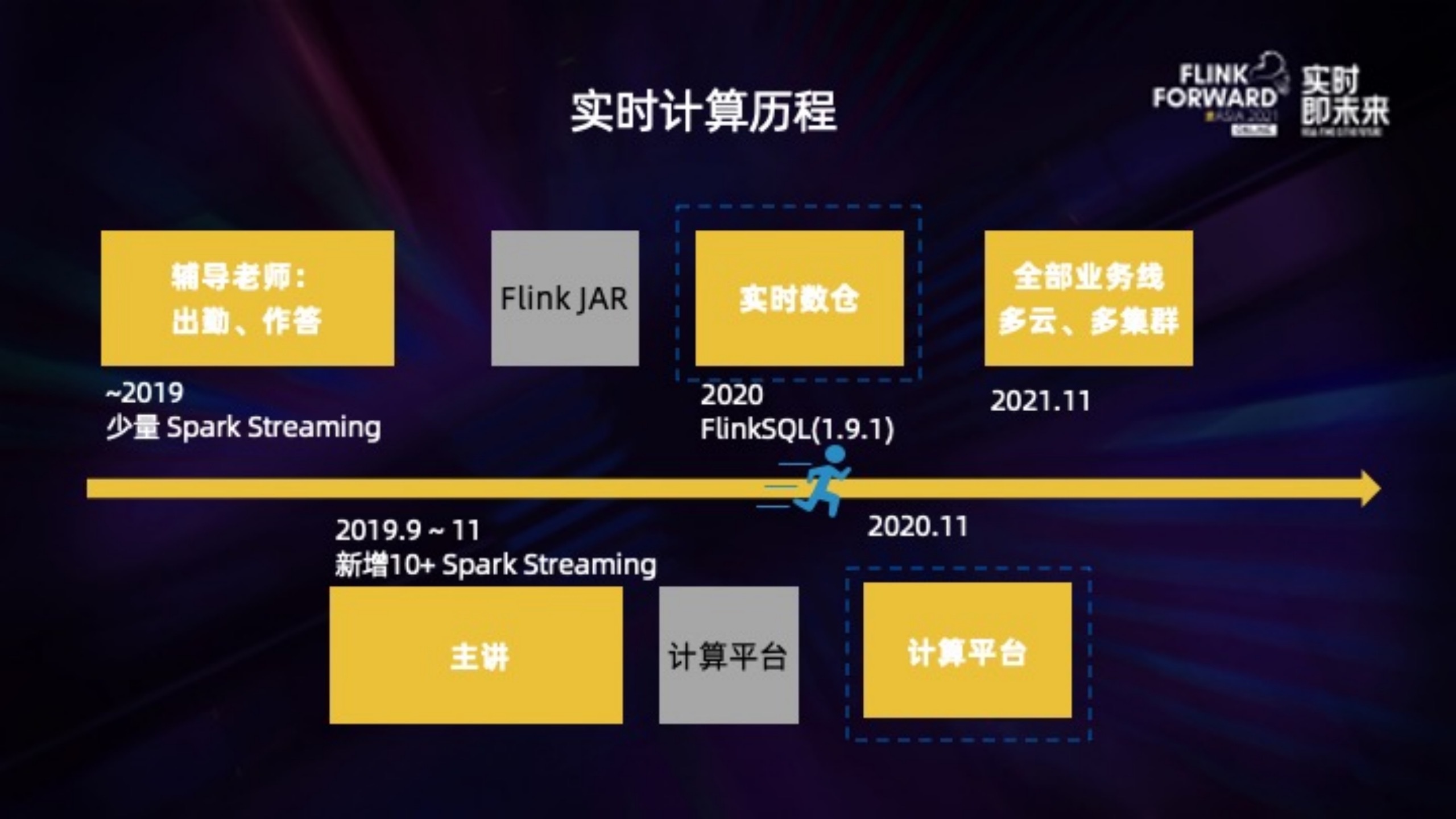
作业帮的实时计算目前基本以 Flink 为主,发展历程大概有三个阶段:
1. 19 年,实时计算包含少量的 SparkStreaming 作业,提供到辅导老师、主讲侧。在解决实时需求的过程中,就会发现开发效率很低,数据几乎无法复用。
2. 之后常规的做法,是在生产实践中逐步应用 Flink JAR,积累经验后开始搭建平台以及应用 Flink SQL.不过在 20 年,业务提出了非常多的实时计算需求,而我们开发人力储备不足。当时 Flink SQL 1.9 发布不久,SQL 功能变化较大,所以我们的做法是直接在实时数仓方向应用 Flink SQL,目前整个实时数仓超过 90% 的任务都是使用 Flink SQL 实现的。
3. 到了 20 年 11 月份,Flink 作业很快增加到几百条,我们开始从 0 到 1 搭建实时计算平台,已经支持了公司全部重要的业务线,计算部署在多个云的多个集群上。
接下来介绍两个方面:
1. FlinkSQL 实践遇到的典型问题以及解决方案
2. 实时计算平台建设过程中的一些思考
二、Flink SQL 应用实践
这是基于 Flink SQL 的完整数据流架构:
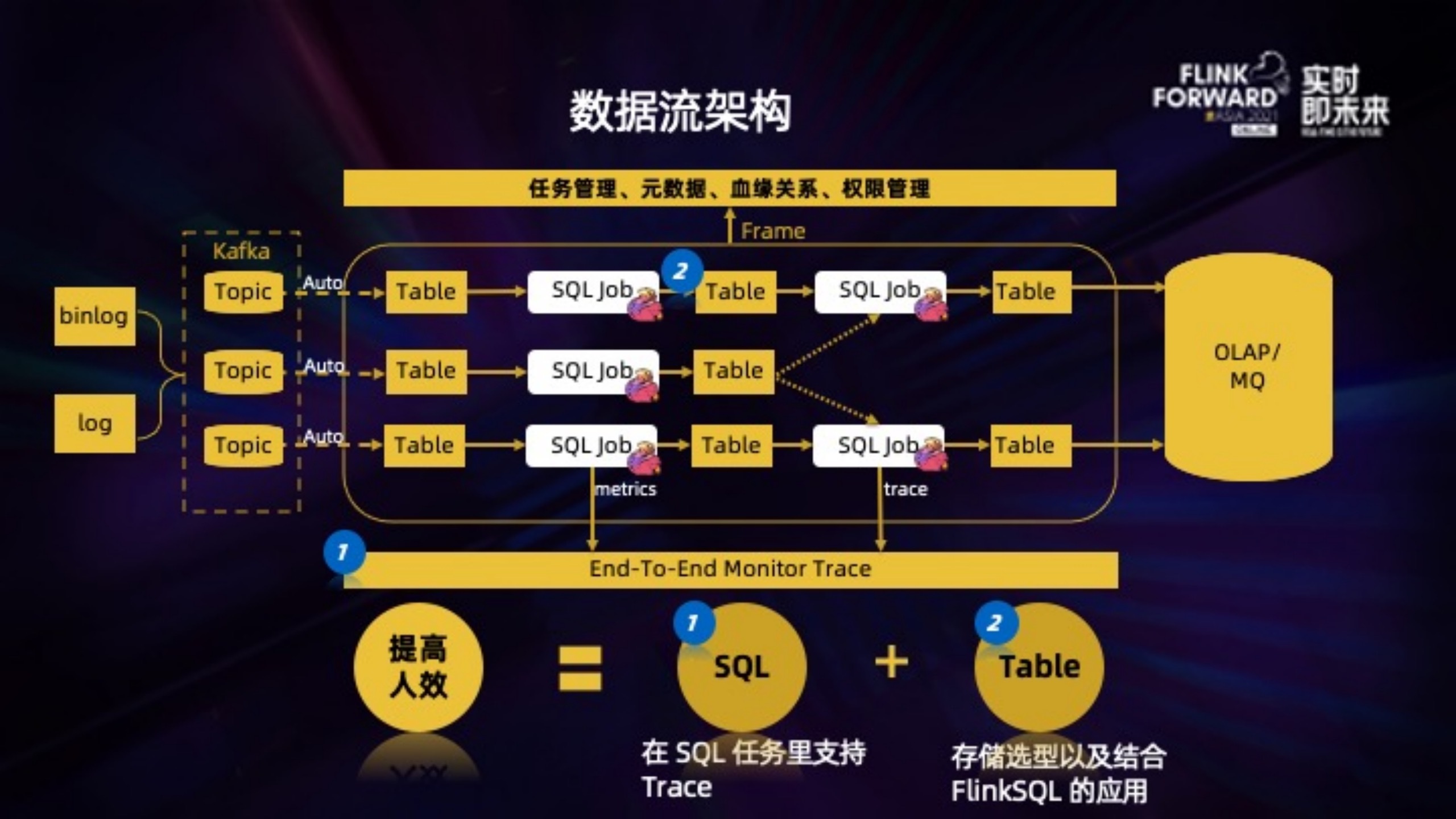
binlog/log 采集写入 Kafka 后,topic 会自动注册成为元数据的一张表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业里使用这个表,而不用定义复杂的 DDL。
同时,考虑实际应用时,也需要在元数据表的基础上,能够对表属性进行新增或者替换:
1. 新增:元数据记录的是表级别的属性,但是 SQL 作业里可能需要增加任务级别的属性。比如对于 Kafka 源表,增加作业的 group.id 来记录 offset 。
2. 替换:线下测试时,在引用元数据表的基础上,只需要定义 broker topic 等属性覆盖源表,这样可以快速的构建一个线下测试表。
框架也需要支持用户的 SQL 作业方便的输出 metrics 以及日志,以做到全链路的监控以及 Trace。
这里主要介绍下 SQL 增加 Trace 功能时 DAG 优化实践,以及我们在 Table 底层物理存储的选型和封装。
2.1. SQL 增加 Trace 功能
SQL 可以提高开发人效,但是业务逻辑的复杂度还在,复杂的业务逻辑写出来的 DML 会很长。这种情况下,会推荐使用视图来提高可读性。因为视图的 SQL 更简短,跟代码规范里单个函数不要太长很像。
下图左边是一个示例任务的部分 DAG,可以看到 SQL 节点很多。这种情况下出了 case 定位比较困难,因为如果是 DataStream API 实现的代码,还可以添加日志。但是 SQL 做不到,用户能够干预的入口很少,只能看到整个作业的输入输出。
类似于在函数里打印日志,我们希望能够支持给视图增加 Trace,方便 case 追查。

但是尝试给 SQL 增加 Trace 时遇到了一些问题,举一个简化后的例子:
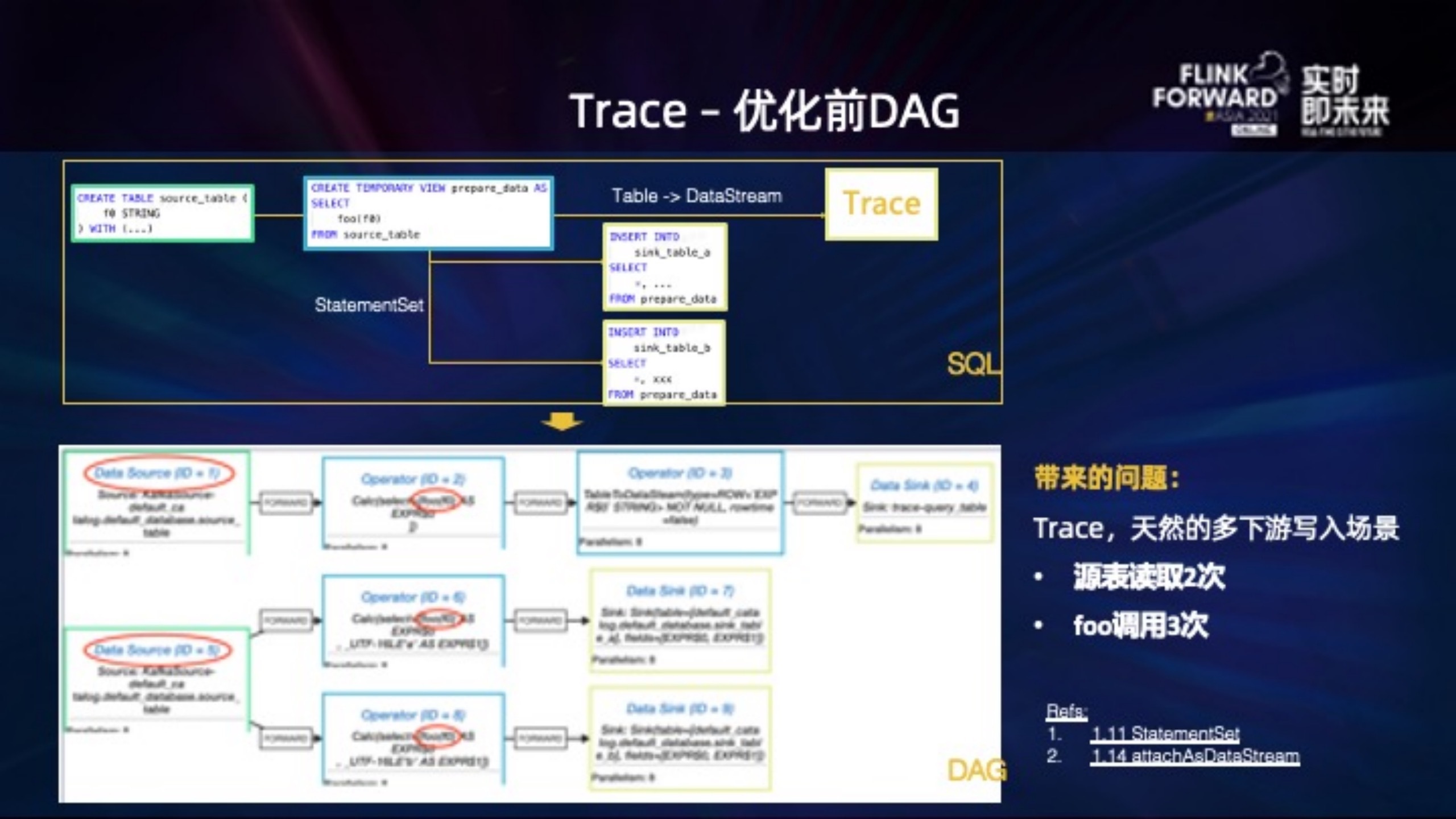
右上角的 SQL 创建 source_table 作为源表, prepare_data 视图读取该表, sql 里调用了 foo udf,然后使用 StatementSet 分别 insert into 到两个下游,同时,将视图转为 DataStream 以调用 TraceSDK 写入 trace 系统。
注:我们当时是基于 1.9 开发的,这里为了讲述清楚,也使用了一些后来加入的 featurehttps://issues.apache.org/jira/browse/FLINK-16361 https://issues.apache.org/jira/browse/FLINK-18840
从上图下方的实际 DAG 看不太符合预期:
1. DAG 被分成了上下不相关的两部分,Kafka 源表也就是 DataSource 部分,读取了两次。
2. foo 方法调用了三次。
数据源压力以及计算性能都需要优化。
解决这个问题需要从几个角度分别优化,这里主要介绍下 DAG 合并的思路,无论是 table 还是 stream 的 env,都会生成对应的 transformation。我们的做法是统一合并到 stream env 下,这样在 stream env 就能拿到一个完整的 transformation 列表,然后生成 StreamGraph 提交。
左下就是我们优化后的 DAG,读取源表以及调用 foo 方法都只有一次:
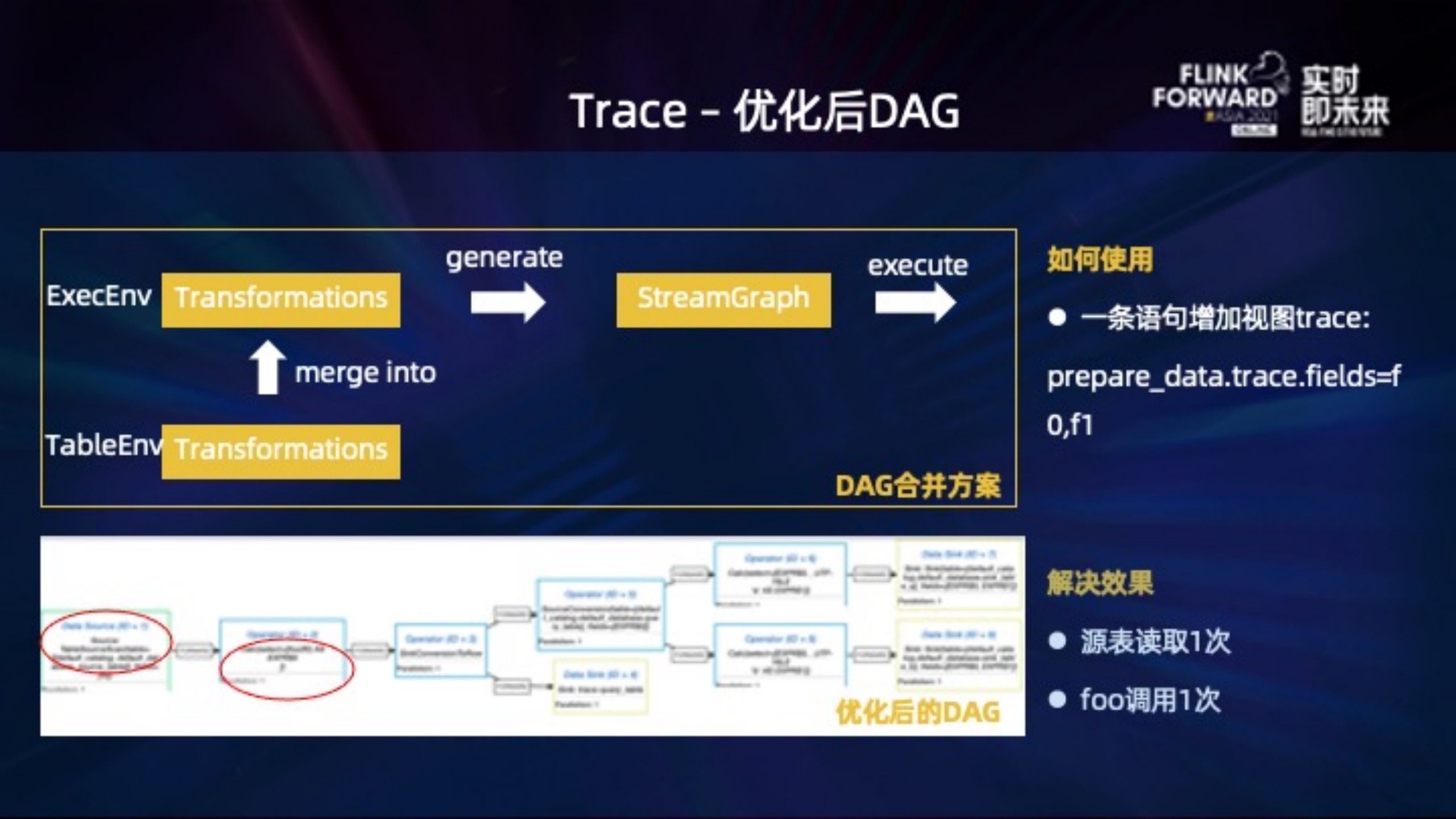
优化后的 DAG 效果跟我们写 SQL 时的逻辑图就非常像了,性能自然也都符合预期。
回到问题本身,业务上可以简单的用一条语句给视图的某些字段增加 trace,例如: prepare_data.trace.fields=f0,f1. 由于 SQL 天然包含了字段名,因此 trace 的数据可读性比普通日志还要高。
2.2. Table 的选型及设计
前面提到我们的首要需求是提高人效,因此需要 Table 有比较好的分层和复用的能力,支持模板化的开发,这样可以快速的串联起来端到端的 N 个 Flink 作业。
我们的解决方案是基于 Redis 实现,首先有几点好处:
1. 高 qps、低延迟:这个应该是所有实时计算都关注的。
2. TTL:用户不用关心数据如何退场,给定一个合理的 TTL 就可以了。
3. 通过使用 protobuf 等高性能且紧凑的序列化方式,以及使用 TTL,存储上整体不到 200G,redis 的内存压力可以接受。
4. 贴合计算模型:计算本身为了确保时序性,会进行 keyBy 的操作,把需要同时处理的数据 shuffle 到同一并发上,因此也不依赖存储过多考虑锁的优化。
接下来我们的场景,主要是解决多索引以及触发消息的问题。
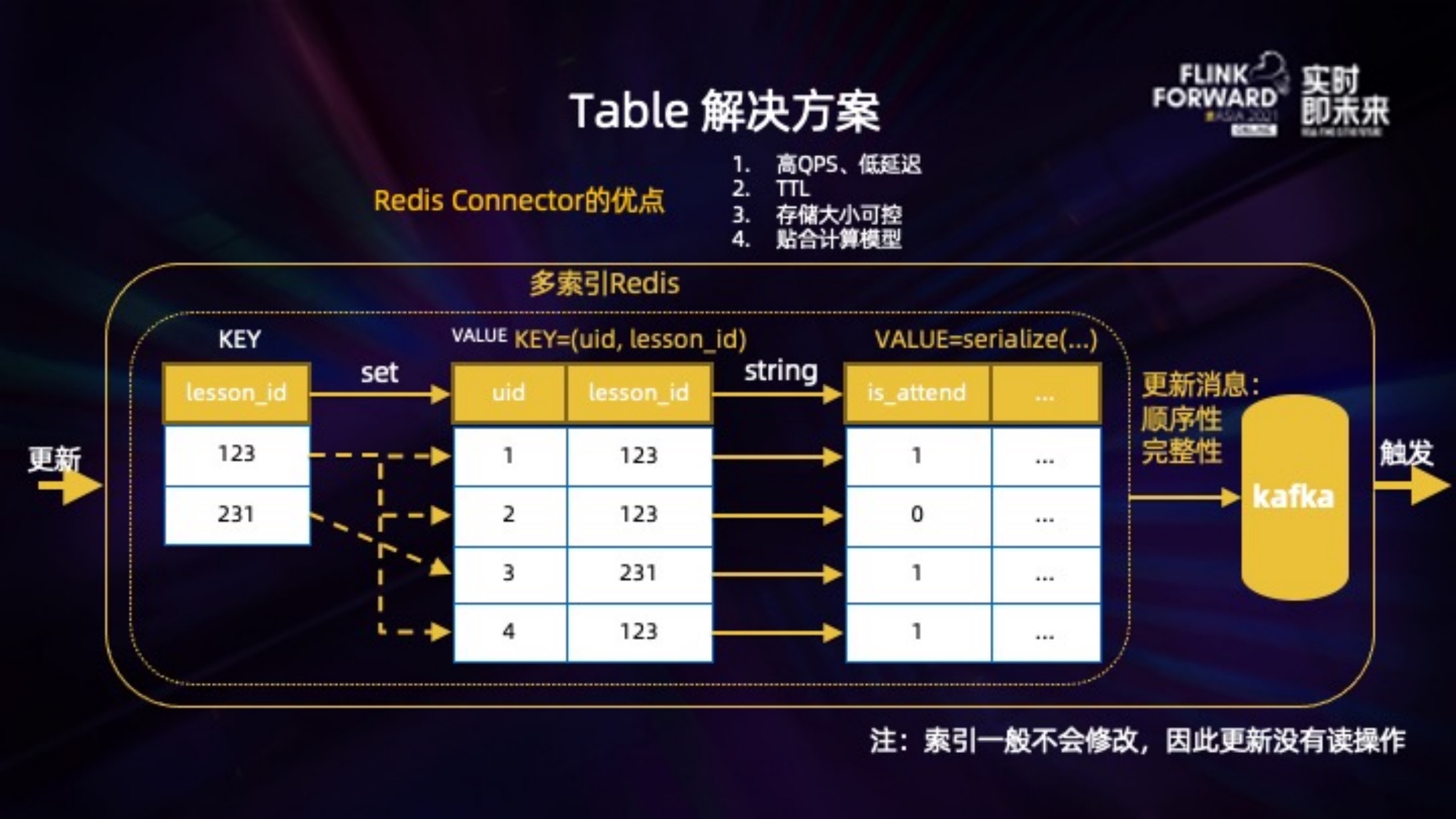
上图举了一个学生在某个章节是否到课的表的例子:
1. 多索引:数据首先按照 string 格式存储,比如 key=(uid, lesson_id), value=serialize(is_attend, ...),这样我们就可以在 SQL 里 JOIN ON uid AND lesson_id 了。如果 JOIN ON 其他字段,比如 lesson_id 怎么办?我们的做法,是会同时写入一个 lesson_id 为 key 的 set,set 里的元素是对应的 (uid, lesson_id)。接下来查找 lesson_id = 123 时,先取出该 set 下所有元素,然后再通过 pipeline 的方式查找到所有的 VALUE 返回。
2. 触发消息:写入 redis 后,会同时写入一条更新消息到 Kafka. 两个存储之间的一致性、顺序性、不丢数据都在 Redis Connector 的实现里保证。
这些功能都封装在 Redis Connector 里,业务上可以简单的通过 DDL 定义这么一个 Table 出来。
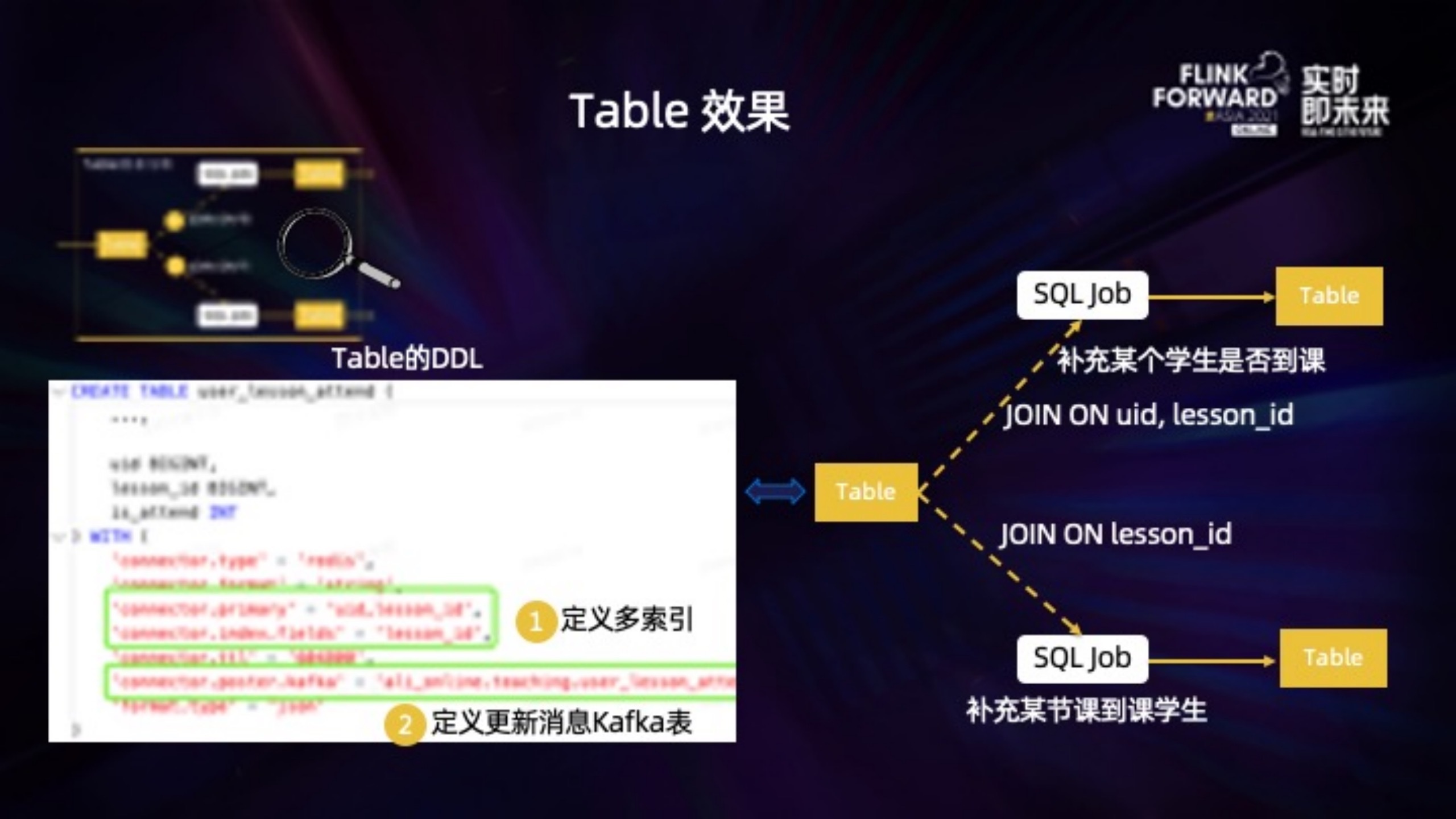
DDL 里几个比较重要的属性:
1. primary 定义了主键,对应 string 的数据结构,例如例子里的 uid + lesson_id 。
2. index.fields 定义了辅助查找的索引字段,例如例子里的 lesson_id;索引也可以定义多个。
3. poster.kafka 定义接收触发消息的 kafka 表,这个表同样定义在了元数据,用户可以在后续的 SQL 作业里无需定义直接读取该表。
因此整个开发模式的复用性很强,用户可以很方便的开发出来端到端的 N 个 SQL 作业,也不用担心 case 如何追查的问题。
三、 平台建设
上面的数据流架构搭建完成后,实时作业数在 2020.11 很快增加到了几百条,相比 19 年快了很多。这个时候我们开始从 0 到 1 搭建实时计算平台,接下来分享在搭建过程中的一些思考。
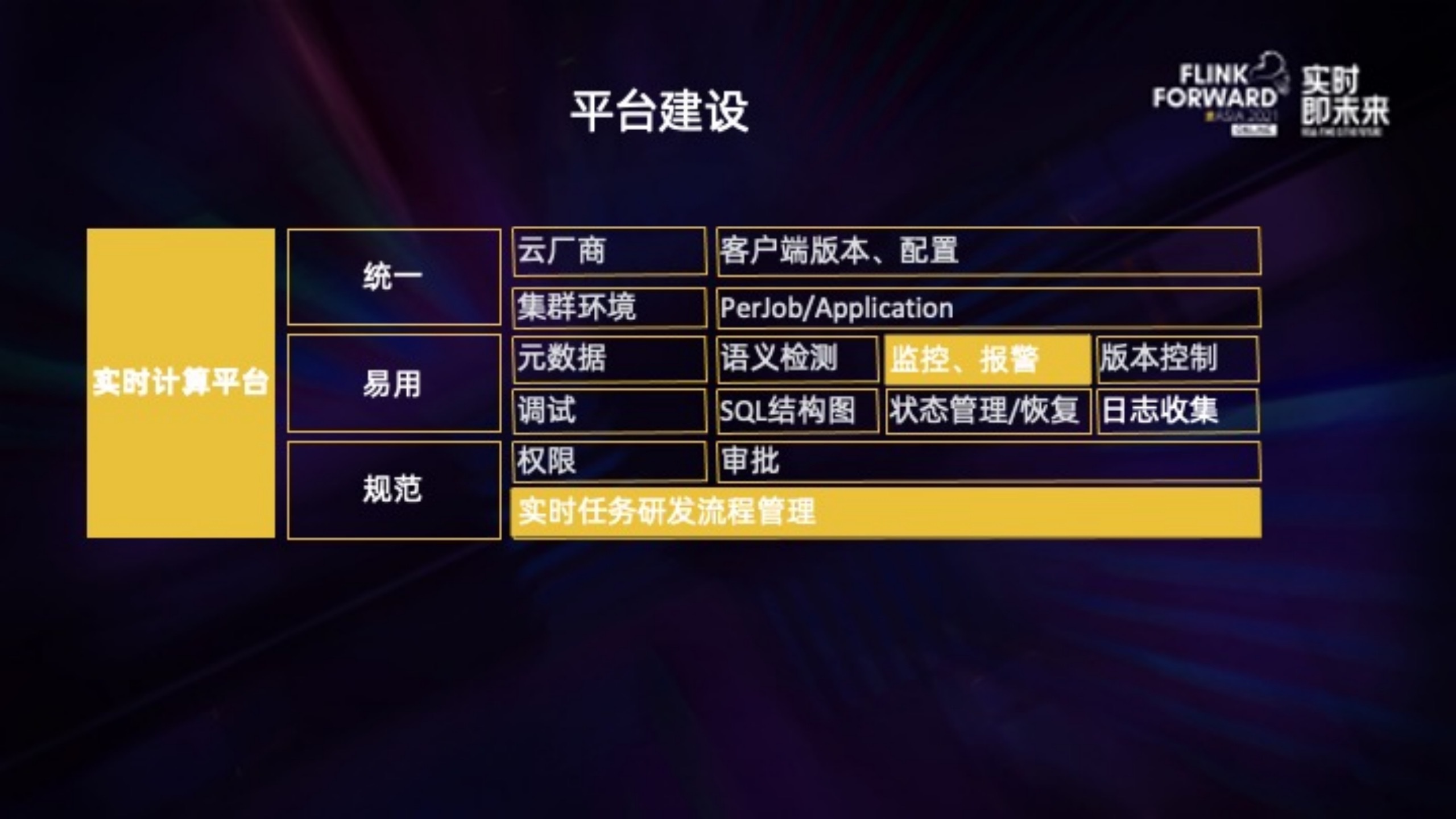
平台支持的功能,出发点主要有 3 个:
1. 统一:统一不同云厂商不同的集群环境、Flink 版本、提交方式等;之前 hadoop 客户端散落在用户的提交机上,对集群数据、任务安全都有隐患,同时增加了集群后续的升级、迁移成本。我们希望通过平台统一任务的提交入口以及提交方式。
2. 易用:通过平台交互能够提供更多易用功能,比如调试、语义检测,这些都能提高任务测试的人效,以及记录任务的版本历史支持方便的上线及回滚操作。
3. 规范:权限控制、流程审批等,类似于在线服务的上线流程,通过平台,能够把实时任务的研发流程规范起来。
3.1. 规范-实时任务流程管理
FlinkSQL 使得开发非常简单高效,但是越简单越难以规范,因为可能写一段 SQL 只用两个小时,但是走一遍规范下来得半天。

但是规范还是要执行,有些问题类似在线服务,实时计算里也会遇到:
1. 记不清:任务在线上跑了一年,最初的需求可能是口口相传,好一点记了 wiki 或者邮件,但是都容易在任务交接中记不清楚。
2. 不规范:UDF 也好,DataStream 的代码也好,都没有遵守规范,可读性差,导致后面接手的同学升级改不动、或者不敢改,没法长久的维护下去。包括实时任务的 SQL 怎么写也应该有规范。
3. 找不到:线上运行中的任务,依赖了某个 jar,对应的是哪个 git 模块的哪个 commitId,出了问题怎么第一时间找到对应的代码实现。
4. 瞎修改:一直正常的任务,周末突然报警了,原因是私自修改了线上任务的 SQL。
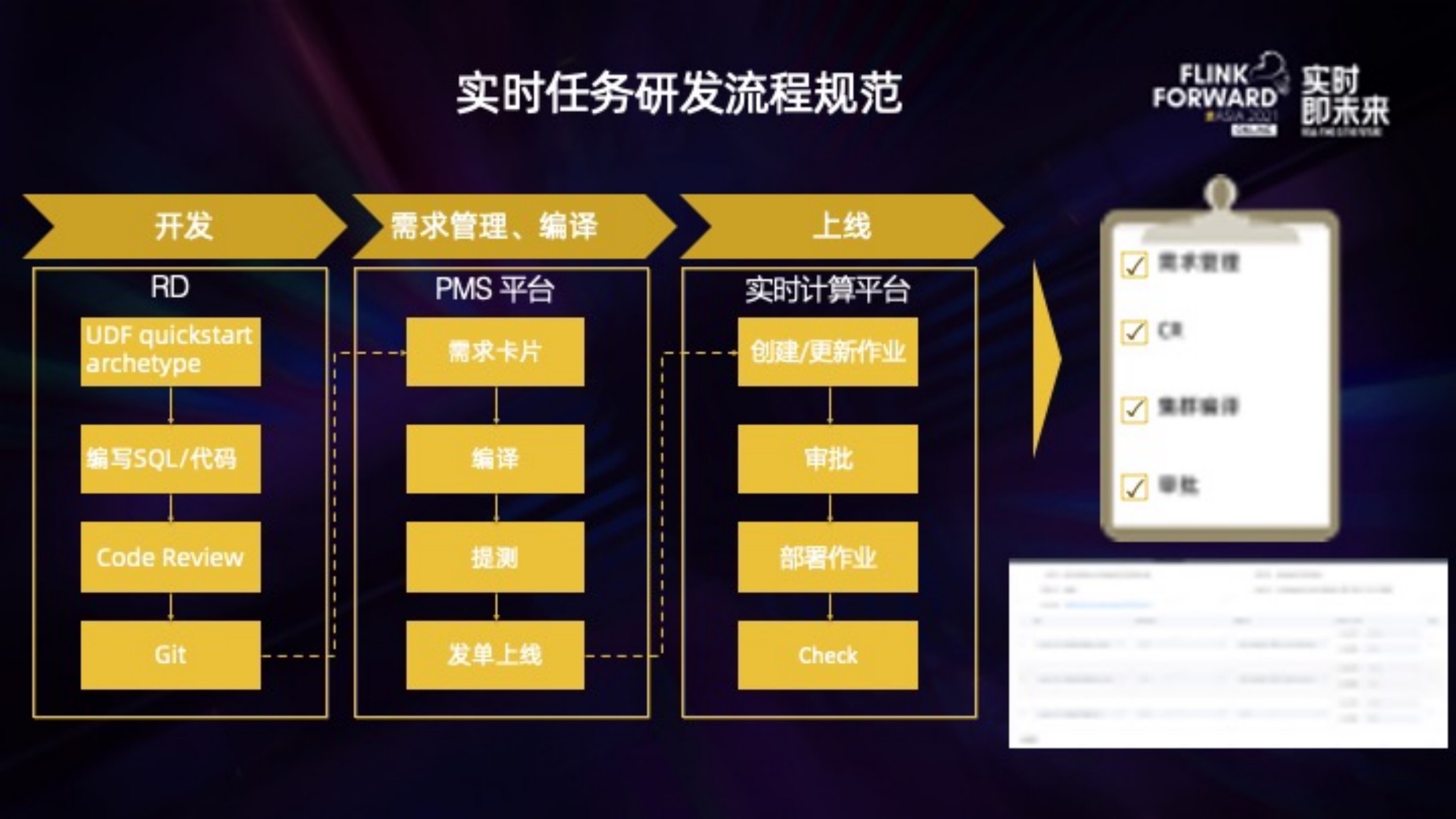
规范主要分为三部分:
1. 开发:RD 可以从 UDF archetype 项目上快速创建一个 UDF 模块,这个是参考了 flink quickstart。创建出来的 UDF 模块可以正常编译,包含了类似 WordCount 这种 udf 示例,也有默认的 ReadMe、VersionHelper 这些辅助方法。按照业务需求修改后,经过 CR 上传到 Git。
2. 需求管理、编译:提交的代码会关联到需求卡片上,经过集群编译、QA 测试,才能发单上线。
3. 上线:根据模块及编译产出,选择更新/创建哪些作业,经过作业 owner 或者 leader 审批后,重新部署。
整个研发流程,是不能从线下私自修改的,比如更换 jar 包或者生效到哪个任务上。一个实时任务,即使运行上几年,也能够从当前任务找到谁上的线、谁审批的,当时的测试记录、对应 Git 代码,以及最最开始谁提出来的实时指标的需求,这样才能将任务长久的维护起来。
3.2 易用-监控
我们目前的 Flink 作业都运行在 Yarn 上。作业启动后,预期是 Prometheus 来抓取 Yarn 分配的 Container,然后对接报警系统,用户就可以基于报警系统配置 Kafka 延迟、Checkpoint 失败这些报警。在搭建这条通路时主要遇到了两个问题:
1. PrometheusReporter 启动 HTTPServer 后,Prometheus 怎么能动态感知;也需要能够控制 metric 的大小,避免采集大量无用数据。
2. 我们 SQL 的源表,基本是以 Kafka 为主。相比第三方的工具,在计算平台上配置 Kafka 延迟报警会更加方便。因为能够天然的拿到任务读取的 topic、group.id,同时也可以跟任务失败使用同一个报警组。再配合上报警模板,配置报警非常简便。
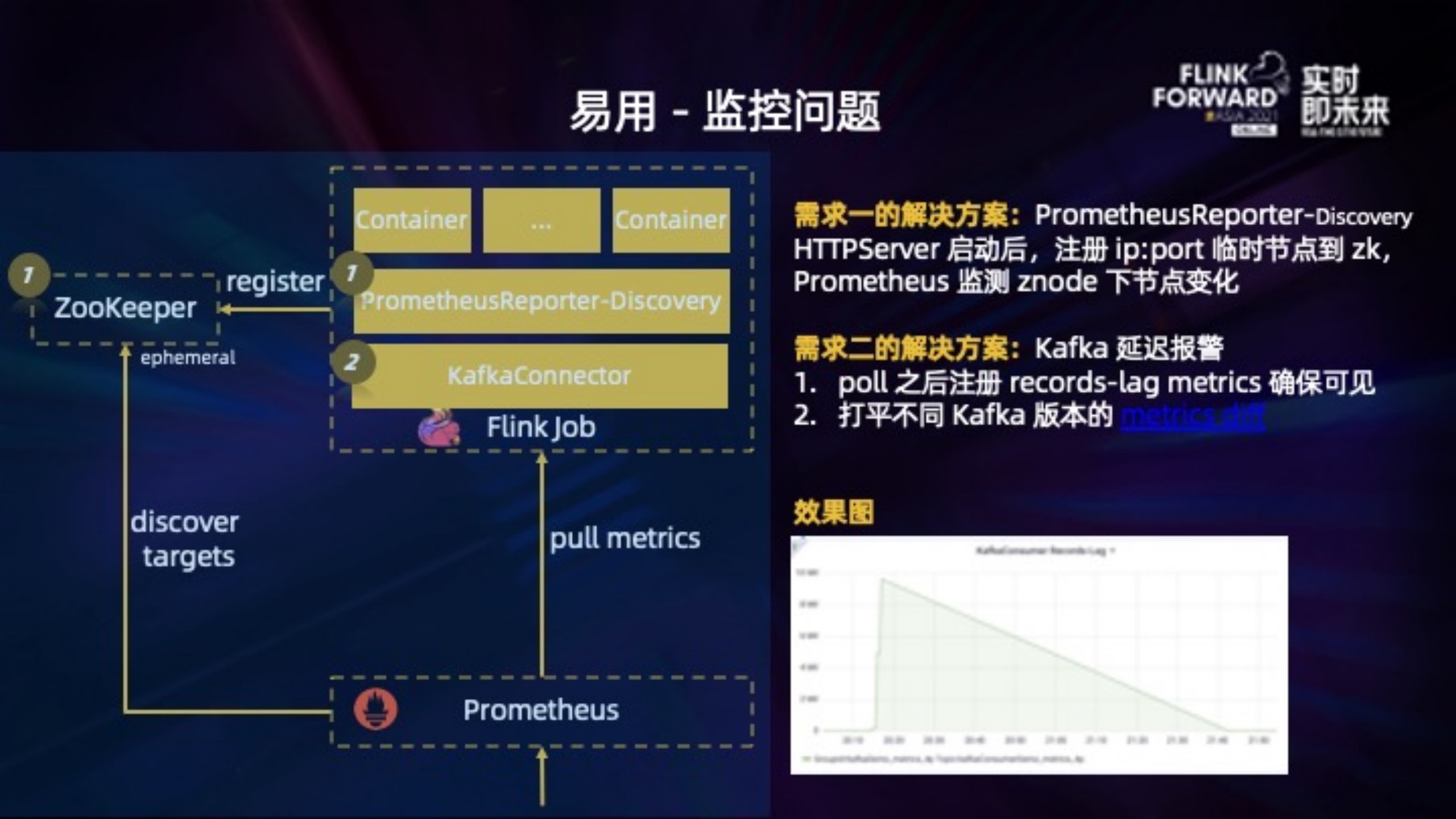
解决方案上:
1. 在官方 PrometheusReporter 的基础上增加了 discovery 的功能。Container 的 HTTPServer 启动后,把对应的 ip:port 以临时节点的形式注册到 zk 上,然后利用 Prometheus 的 discover targets 监听 zk 节点的变化。由于是临时节点,Container 销毁时节点消失,Prometheus 也能够感知不再抓取。这样就很简便的搭建起来 Prometheus 抓取的通路。
2. KafkaConsumer.records-lag 是比较实用、重要的延迟指标,主要做了两个工作。修改 KafkaConnector,在 KafkaConsumer.poll 之后再 expose 出来,确保 records-lag 指标可见。另外在做这个的过程中,发现不同 Kafka 版本的这个指标格式不同(https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=74686649),我们的做法是都打平为一种格式,注册到 flink 的 metrics 里。这样不同版本暴露出来的指标是一致的。
四、总结展望
上一个阶段主要是在应用 Flink SQL 支持快速开发实时作业,以及搭建了实时计算平台,支持了上千条的 Flink 作业。
其中一个比较大的感悟是,SQL 确实简化了开发,但是同时也屏蔽了更多的技术细节。实时作业运维工具的需求比如 Trace,或者任务的规范这些并没有发生变化,甚至对这些的要求反而更加严格。
因为屏蔽细节的同时,一旦出了问题,用户越不知道如何处理。就好像冰山一角,漏出来的越少,沉在水底的越多,你就越需要做好周边体系的建设。
另外一个就是适配现状,先能尽快满足当前需求,比如我们就是提高人效、降低开发门槛。同时也要不断探索更多业务场景,比如使用 HBase、RPC 服务替换 Redis Connector,现在的好处是修改底层存储,用户 SQL 作业感知很小,因为 SQL 作业里基本都是业务逻辑,而 DDL 定义到了元数据。

下一步规划主要分为三部分:
1. 支持资源弹性伸缩,平衡实时作业的成本以及时效性。
2. 我们是从 1.9 开始大规模应用 Flink SQL 的,现在版本升级变化很大,需要考虑如何让业务能够低成本的升级使用新版本里 feature。
3. 探索流批一体在实际业务场景上的落地。
作者介绍
张迎,2019 年加入作业帮大数据中台研发部,负责实时计算相关工作。




