
前不久,百度产业级知识增强大模型“文心”全景图亮相,近日,其中的跨模态生成模型 ERNIE-ViLG 在百度文心官网开放体验入口,并放出了论文。
体验链接:https://wenxin.baidu.com/wenxin/ernie-vilg
论文链接:https://arxiv.org/pdf/2112.15283.pdf

据悉,文心 ERNIE-ViLG 参数规模达到 100 亿,是目前为止全球最大规模中文跨模态生成模型,该模型首次通过自回归算法将图像生成和文本生成统一建模,增强模型的跨模态语义对齐能力,显著提升图文生成效果。
先来体验下文心 ERNIE-ViLG“图像创作”能力。
在文字生成图像上,文心 ERNIE-ViLG 可以根据用户输入的文本,自动创作图像,生成的图像不仅符合文字描述,而且达到了非常逼真的效果。
注意!以下图片都是全新生成,并非可直接搜索到的原图。
文心 ERNIE-ViLG 不仅能创作建筑、动物等单个物体:

还可以创作包含多个物体的复杂场景:

甚至能根据用户输入的文字要求脑洞大开:

对于具有无限想象力的古诗词,文心 ERNIE-ViLG 也能生成恰如其分的画面,并根据不同的图画风格也有所调整:
(油画风格)
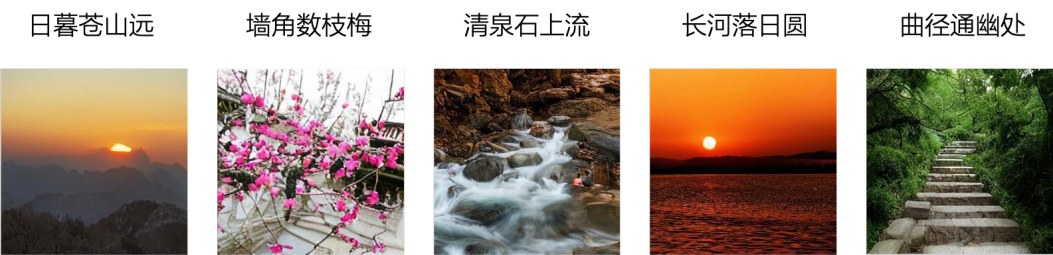
(中国画风格)

(水彩画风格)

此外,还能根据文字提示对图片进行补全:

而在图像到文本的生成上,文心 ERNIE-ViLG 能够理解画面,用简洁的语言描述画面的内容:

不仅如此,文心 ERNIE-ViLG 还能够根据图片中的场景回答相关的问题:

目前文心 ERNIE-ViLG 在百度文心官网开放体验的文本生图像 demo 能够根据古诗词进行作画,增强诗词的画面感。
在这些能力的背后,究竟蕴含着怎样的 AI 技术秘密?
跨模态生成:AI 领域极具挑战性的一道“难题”
跨模态生成,指的是将一种模态 (文本、图像、语音) 转换成另一种模态,同时保持模态之间的语义一致性。
图文生成是跨模态生成的挑战之一。以文本生成图片为例,文本描述概括性强,根据文本生成图片,需要考虑大量文字中未涵盖的细节信息,具有极高的挑战性。例如诗句“春江水暖鸭先知”,仅仅描述了江水、鸭子两个物体和春天这个季节,但没有具体描述鸭子的颜色、江边的桃花以及图中物体之间的位置关系。

春江水暖鸭先知
近些年来,基于生成对抗网络(GAN)的方法在人脸、风景等受限领域的文本到图像生成任务上已取得了不错的效果;DALL-E 通过超大规模的自回归生成模型,在图像片段之间建立了前后依赖的关系,从而具备多样性生成的建模能力,在多样性更强、难度更大的开放领域文本到图像生成上取得了亮眼的效果。
百度文心 ERNIE-ViLG 模型则进一步提出统一的跨模态双向生成模型,通过自回归生成模式对图像生成和文本生成任务进行统一建模,更好地捕捉模态间的语义对齐关系,从而同时提升图文双向生成任务的效果。
文心 ERNIE-ViLG 在文本生成图像的权威公开数据集 MS-COCO 上,图片质量评估指标 FID(Fréchet Inception Distance)远超 OpenAI 的 DALL-E 等同类模型,并刷新了图像描述多项任务的最好效果。此外,文心 ERNIE-ViLG 还凭借强大的跨模态理解能力,在生成式视觉问答任务上也实现了较好表现。
文心 ERNIE-ViLG 技术原理解读:图文双向生成统一建模
百度文心 ERNIE-ViLG 使用编码器-解码器参数共享的 Transformer 作为自回归生成的主干网络,同时学习文本生成图像、图像生成文本两个任务。
基于图像向量量化技术,文心 ERNIE-ViLG 把图像表示成离散的序列,从而将文本和图像进行统一的序列自回归生成建模。在文本生成图像时,文心 ERNIE-ViLG 模型的输入是文本 token 序列,输出是图像 token 序列;图像生成文本时则根据输入的图像序列预测文本内容。两个方向的生成任务使用同一个 Transformer 模型。视觉和语言两个模态在相同模型参数下进行相同模式的生成,能够促进模型建立更好的跨模态语义对齐。
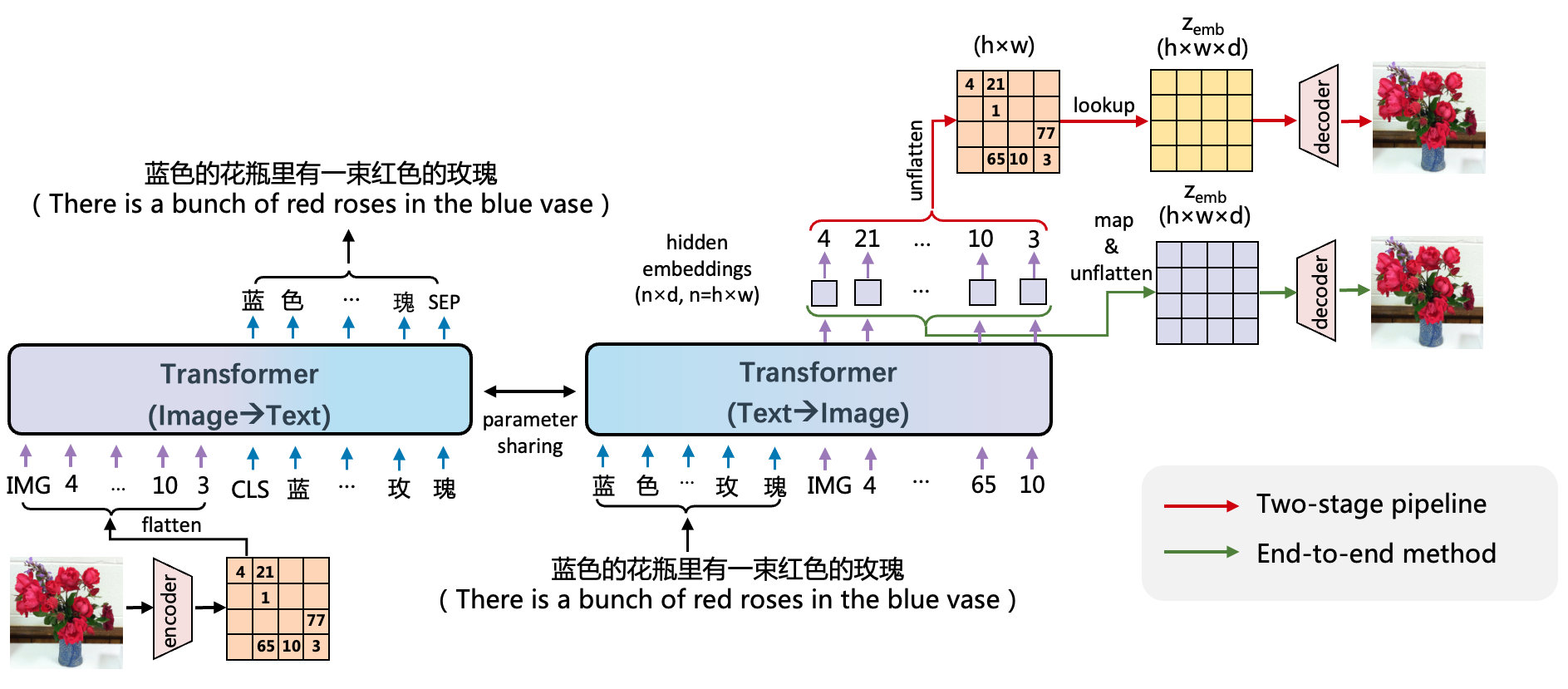
文心 ERNIE-ViLG 图文双向生成统一建模框架
已有基于图像离散表示的文本生成图像模型主要采用两阶段训练,文本生成视觉序列和根据视觉序列重建图像两个阶段独立训练,文心 ERNIE-ViLG 提出了端到端的训练方法,将序列生成过程中 Transformer 模型输出的隐层图像表示连接到重建模型中进行图像还原,为重建模型提供语义更丰富的特征;对于生成模型,可以同时接收自身的抽象监督信号和来自重建模型的原始监督信号,有助于更好地学习图像表示。
文心 ERNIE-ViLG 构建了包含 1.45 亿高质量中文文本-图像对的大规模跨模态对齐数据集,并基于百度飞桨深度学习平台在该数据集上训练了百亿参数模型,在文本生成图像、图像描述等跨模态生成任务上评估了该模型的效果。
文本生成图像(Text-to-image Synthesis)任务效果
文心 ERNIE-ViLG 文本生成图像的能力在开放领域公开数据集 MS-COCO 上进行了验证。评估指标使用 FID(该指标数值越低效果越好), 在 zero-shot 和 finetune 两种方式下,文心 ERNIE-ViLG 都取得了最佳成绩,效果远超 OpenAI 发布的 DALL-E 等模型。
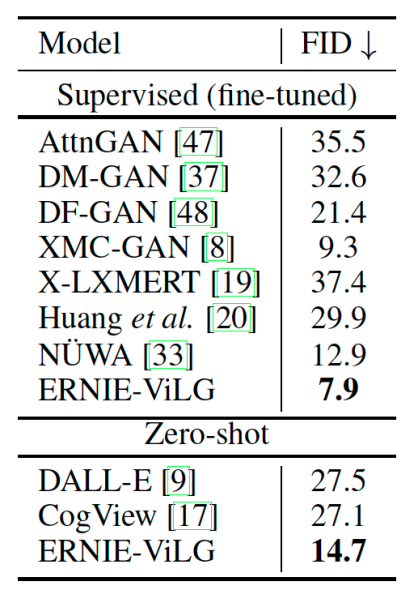
文心 ERNIE-ViLG 在 MS-COCO 数据集上的效果
图像描述(Image Captioning)任务效果
图像生成文本能力上,文心 ERNIE-ViLG 在 COCO-CN、AIC-ICC 两个公开中文图片标题生成数据集上,都取得了最好成绩。

文心 ERNIE-ViLG 在 AIC-ICC 数据集上的效果
生成式视觉问答(Generative VQA)任务效果
在生成式视觉问答方面,文心 ERNIE-ViLG 也展示了不俗的实力。生成式视觉问答要求模型根据图像内容和对应的问题生成答案,模型需要具备深度的视觉内容理解能力和跨模态的语义对齐能力,并需要生成简短的答案文本,难度极高。文心 ERNIE-ViLG 在 FMIQA 数据集上取得了最好的效果,图灵测试的通过率达到了 78.5%,优于当前最好方法 14 个百分点。
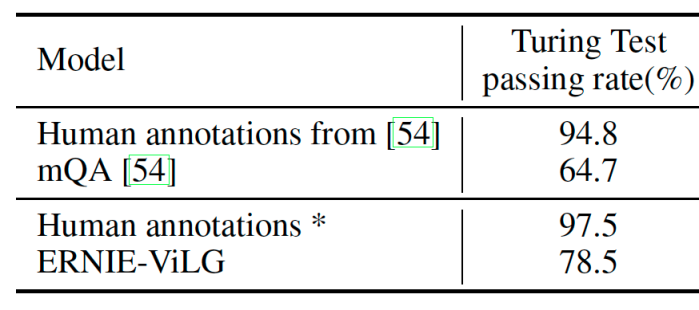
文心 ERNIE-ViLG 在 FMIQA 数据集上的效果
让机器具备跨模态生成能力是人工智能的重要目标之一。在艺术创作、虚拟现实、图像编辑、AI 辅助设计、虚拟数字人等领域,文心 ERNIE-ViLG 这类跨模态大模型有着广泛的应用前景。




