

TTS 是语音合成的一种方式,即文字转语音(Text-To-Speech),早在 17 世纪就有法国人研发机械式的说话装置。直到 19 世纪,贝尔实验室对于电子语音合成技术的研究,才开启近代语音合成技术的发展。贝尔实验室在 1939 年制作出第一个电子语音合成器 VODER,是一种利用共振峰原理所制作的合成器。
1960 年,瑞典语言学家 G. Fant 则提出利用线性预测编码技术(LPC)来作为语音合成分析技术,并推动了日后的发展。后来 1980 年代 Moulines E 和 Charpentier F 提出新的语音合成算法 PSOLA,此技术可以合成比较自然的语音。
在 7 月 9 日阿里巴巴的一场分享会上,达摩院语音实验室高级算法专家雷鸣进行了有关语音合成技术的分享,他认为:“我们目前所处的阶段是一个合成语言大变革的阶段,主要的特点是大家都希望能够提供一个非常接近于真人表现的合成语音,可喜的是,语音合成的质量进步很快。”
阿里巴巴发布的“新一代语音合成技术”KAN-TTS(Knowledge-Aware Neural TTS),由达摩院机器智能实验室自主研发。 阿里方面称,当前业界商用系统的合成语音与原始音频录音的接近程度通常在 85%到 90%之间,而基于 KAN-TTS 技术的合成语音可将该数据提高到 97%以上。
据了解,该技术深度融合了目前主流的端到端 TTS 技术和传统 TTS 技术,从多个方面改进了语音合成。
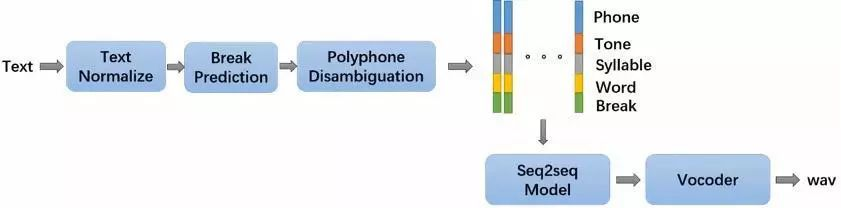
KAN-TTS 的基本框图
传统语音合成定制需要 10 小时以上的数据录制和标注,对录音人和录音环境要求很高。从启动定制到最终交付,项目周期长成本高。
阿里利用 Multi-Speaker Model 与 Speaker-aware Advanced Transfer Learning 相结合的方法,将语音合成定制成本降低 10 倍以上,周期压缩 3 倍以上。也就是说,用 1 小时有效录音数据和不到两个月制作周期,就能完成一次标准 TTS 定制。
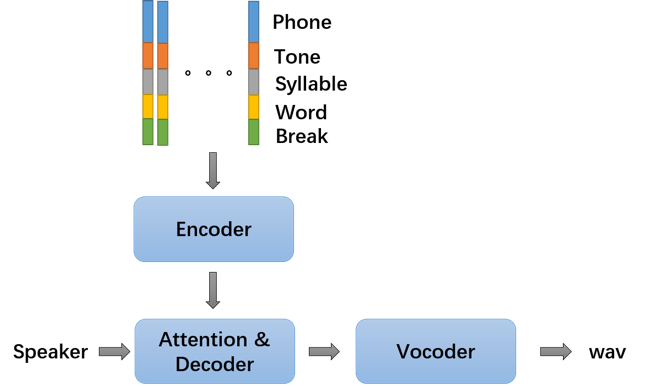
构建多发音人语音合成系统的方式
普通用户定制“AI 声音”的门槛更低。阿里方面介绍称:只需手机录音十分钟,就能获得与录制声音高度相似的合成语音。阿里 AI 做到这一点,主要基于自动数据检查、自动标注方法和对海量用户场景的利用。
据了解,阿里已经对外提供开箱即用的 TTS 解决方案,共有通用、客服、童声、英文和方言 5 个场景的 34 种高品质声音供选择。
基于新一代技术,阿里还提高了设备端离线 TTS 的效果。这在超低资源设备端的 TTS 服务中非常有用,比如当人们驾车行驶于信号微弱区域,阿里技术能避免语音导航“掉线”。

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论