在讨论页面加载性能问题时,我经常听到有人说“HTTP/2 推送可以解决这问题”,但我对这个技术的了解不多,于是打算深入研究一下。
HTTP/2 推送远比我最初想象中更复杂,也更底层,但最让我措手不及的地方在于,这种技术在不同浏览器上的表现竟然有这么大的差别,本来我还觉得这技术已经足够成熟,可以在生产环境中使用了。
本文并不是那种认为“HTTP/2 推送一无是处”的吐槽文。我觉得 HTTP/2 推送真的很强大,以后还会更加完善,但并不算能解决所有问题的万灵药。
完整的 Fetch 路径
在页面和目标服务器间,横亘着一系列可能拦截请求的缓存和其他机制:
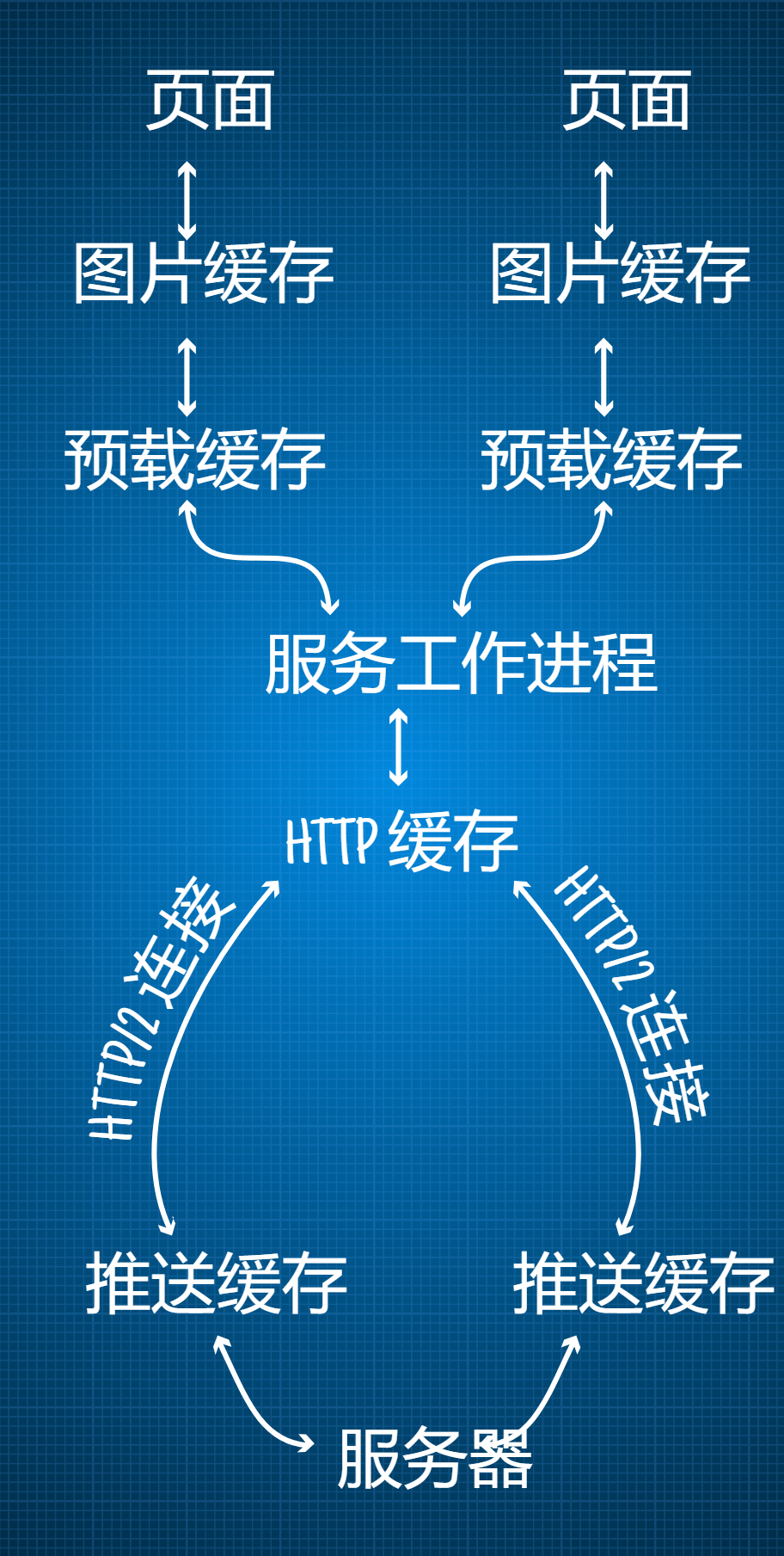
当人们希望尝试或向别人解释 Git 或其他看得见的东西时,通常会使用类似上面这样的流程示意图,在本来就懂的人看来,这样的示意图一目了然,但不懂的人往往会一头雾水。如果你也有这种感觉,那要先说声抱歉了!希望下文能帮你更好地理解。
HTTP/2 推送的工作原理
- 页面:嘿 example.com,能把你的首页让我看一看吗?
- 服务器:没问题!哦,在我给你发送首页的同时,还需要发送一些样式表、图片、JavaScript,以及一些 JSON。
- 页面:额,好的。
- 页面:我已经看到 HTML 了,但貌似还需要一个样式……哦,好像你已经发过来了,酷!
服务器响应请求时,可以顺便包含额外的资源。例如包含一系列请求报头,这样稍后浏览器就知道如何匹配不同报头。这些额外的资源位于缓存中,当浏览器请求的资源与缓存中的匹配时即可直接从缓存中获取。
这种方法可以改善性能,原因在于可以提前发送可能需要的资源,而不需要等待浏览器索取,因此可以提高页面加载速度。
多年来我对 HTTP/2 推送的了解仅限于此,听起来挺简单,但魔鬼往往隐藏在细节中……
任何东西都可以使用推送缓存
HTTP/2 推送是一种底层网络功能,用到网络栈的任何东西都可以使用该功能。但只有确保一致性以及可预测性,才能发挥最大作用。
我试着推送一些资源,并通过下列方式收集:
- fetch()
- XMLHttpRequest




