微博粉丝服务平台在单元化架构方面的实践已经在 QCon 讲过,这次重又写起文章,我想传播知识已经不那么重要(单元化架构不是创新,稍后会详细介绍),更重要的是还是希望能够借此引起诸位的思考,能够在架构层面多投入精力思考和尝试。
为什么要有架构实践?
很多人喜欢的是细节,因为有句名言叫魔鬼在细节里,于是都去细节里寻找魔鬼。但是打败了魔鬼就能看到天使么?未必。细节其实是最容易掌握的部分,细节之外还有很多。就像有了水泥和沙子,你能够做出混凝土,但是离建成高楼大厦还有很长的路要走一样,你要学着去设计架构。
但是事情并没有完,就像没有唯一的真理一样,架构也并不是只有一种。你不可能一朝学会,从此天下无敌。如果要赈灾,你需要的是帐篷,如果要重建,你需要的是瓦房。不同的住所需要的是不同的架构。
不同的服务也需要不同的架构设计,这也就是我们需要架构实践的重要原因。在这之后的原因,是我们做任何服务,都要考虑服务的性能和成本。
但优化有很多方式,为什么是架构呢?诚然,从硬件到操作系统,从共享库到应用软件,从算法到架构,每一层都可以优化,但每一层所做的工作量和收益也都是不同的。架构可能是需要投入最多精力的,但在很多时候却也是很少的可以提供超过数量级的提升方式。
所以,思维方式的转变才是你最应该在意的部分,单元化只是一个例子,而粉丝服务平台只是这个例子的例子,而已。
言归正传,接下来本文将从三个问题来介绍这次实践,单元化是什么,为什么要用以及我们如何做到的。
1. 单元化是什么
单元化架构是从并行计算领域发展而来。在分布式服务设计领域,一个单元(Cell)就是满足某个分区所有业务操作的自包含的安装。而一个分区(Shard),则是整体数据集的一个子集,如果你用尾号来划分用户,那同样尾号的那部分用户就可以认为是一个分区。单元化就是将一个服务设计改造让其符合单元特征的过程。
图 1 :洋葱细胞的显微镜截图,单元化要达到的目的就是让每个单元像细胞一样独立工作
在传统的服务化架构下(如下图),服务是分层的,每一层使用不同的分区算法,每一层都有不同数量的节点,上层节点随机选择下层节点。当然这个随机是比较而言的。
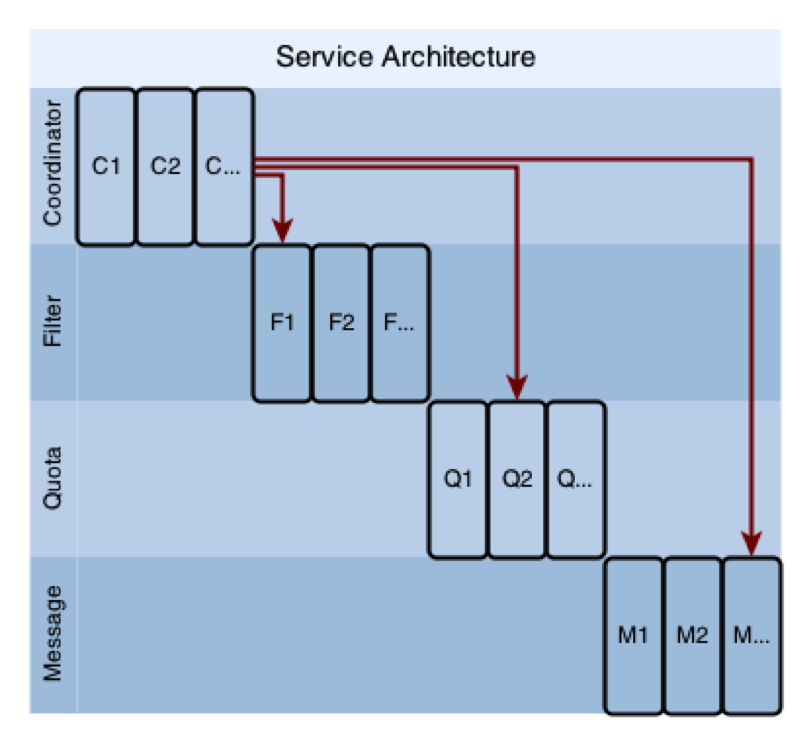
图 2 :传统的服务化架构,为伸缩性设计,上层节点随机选择下层节点
与其不同的是,在单元化架构下,服务虽然分层划分,但每个单元自成一体。按照层次来讲的话,所有层使用相同的分区算法,每一层都有相同数量的节点,上层节点也会访问指定的下层节点。因为他们已经在一起。
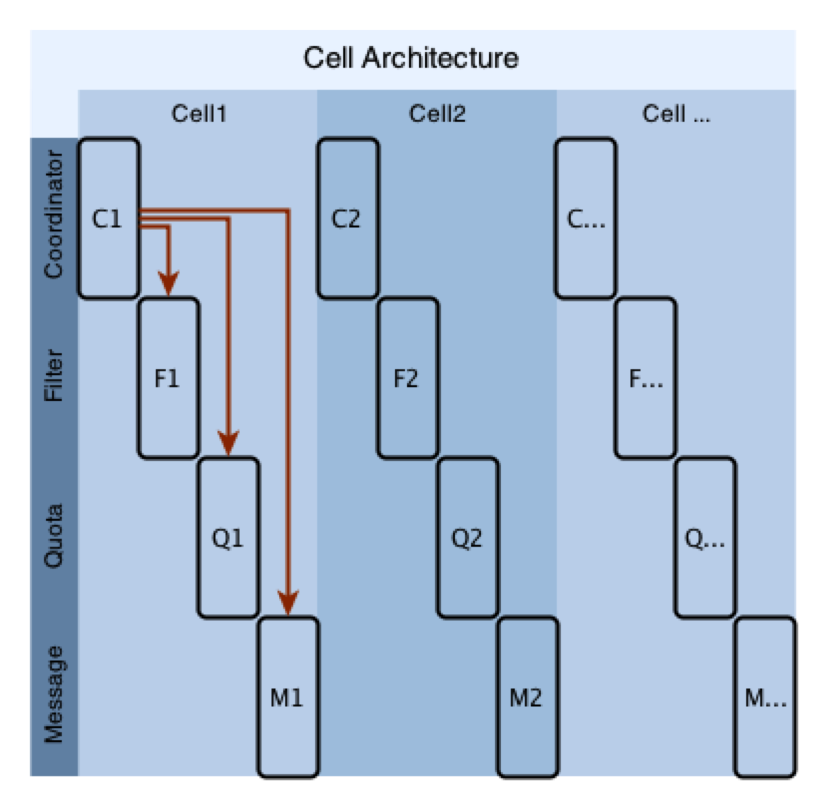
图 3 :单元化架构,为性能和隔离性而设计,上层节点访问指定下层节点
2. 为什么要用单元化
在性能追求和成本限制的情况下,我们需要找到一种合适的方法来满足服务需求。在传统的分布式服务设计,我们考虑的更多是每个服务的可伸缩性,当各个服务独立设计时你就要在每一层进行伸缩性的考虑。这是服务化设计(SOA)流行的原因,我们需要每个服务能够单独水平扩展。
但是在摩尔定律下,随着硬件的不断升级,计算机硬件能力已经越来越强,CPU 越来越快,内存越来越大,网络越来越宽。这让我们看到了在单台机器上垂直扩展的机会。尤其是当你遇到一个性能要求和容量增长可以预期的业务,单元化给我们提供另外的机会,让我们可以有效降低资源的使用,提供更高性能的服务。
总体而言,更高性能更低成本是我们的主要目标,而经过单元化改造,我们得以用更少(约二分之一)的机器,获得了比原来更高(接近百倍)的性能。性能的提升很大部分原因在于服务的本地化,而服务的集成部署又进一步降低了资源的使用。
当然除了性能收益,如果你做到了,你会发现还有很多收益,比如更好的隔离性,包括请求隔离和资源隔离,比如更友好的升级,产品可以灰度发布等。单元化改造后对高峰的应对以及扩容方式等问题,各位可以参考#微博春节技术保障系列#中的单元化架构文章,也不在此一一赘述。
3. 我们如何做到
此次单元化改造基于微博现有的业务,因此这里也先行介绍一下。粉丝服务平台是微博的内容推送系统(代号 Castalia),可为 V 用户提供向其粉丝推送高质量内容的高速通道(单元化之后已到达百万条每秒)。整个服务涉及用户筛选、发送计费、屏蔽检查、限流控制和消息群发等多个子服务。由于改造思想相通,这里以用户筛选和消息群发两个服务为例,下面两图分别为商业群发在服务化思想和单元化思想下不同的架构。
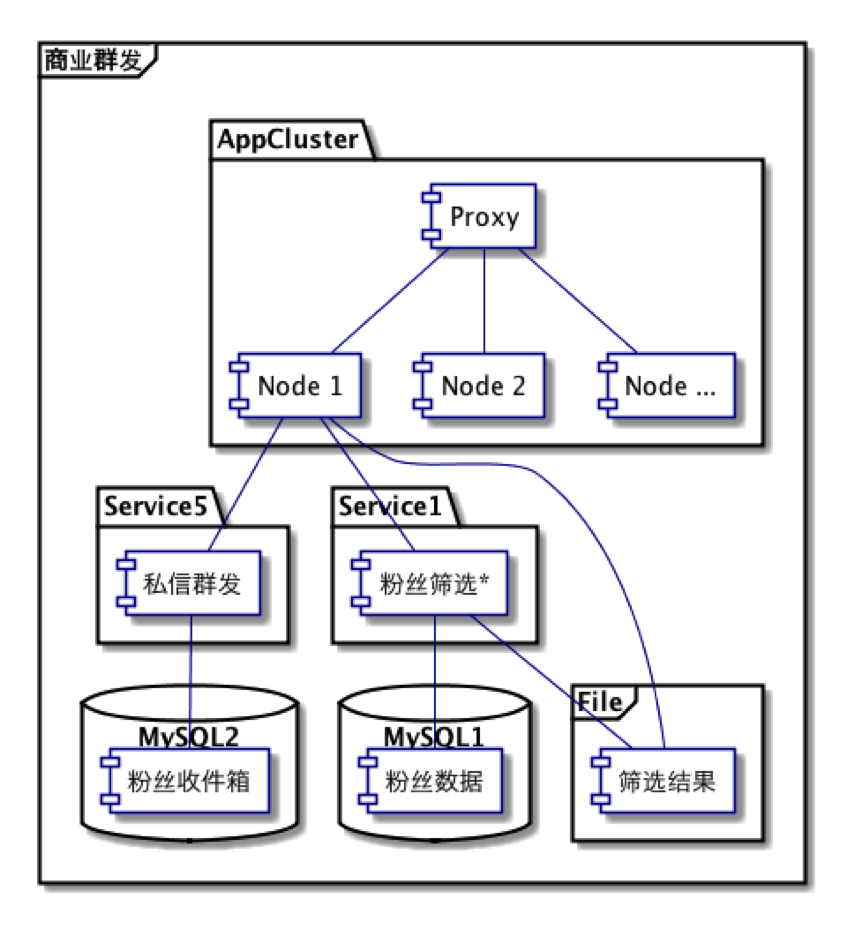
图 4: 服务化思想下的商业群发架构设计(旧版)
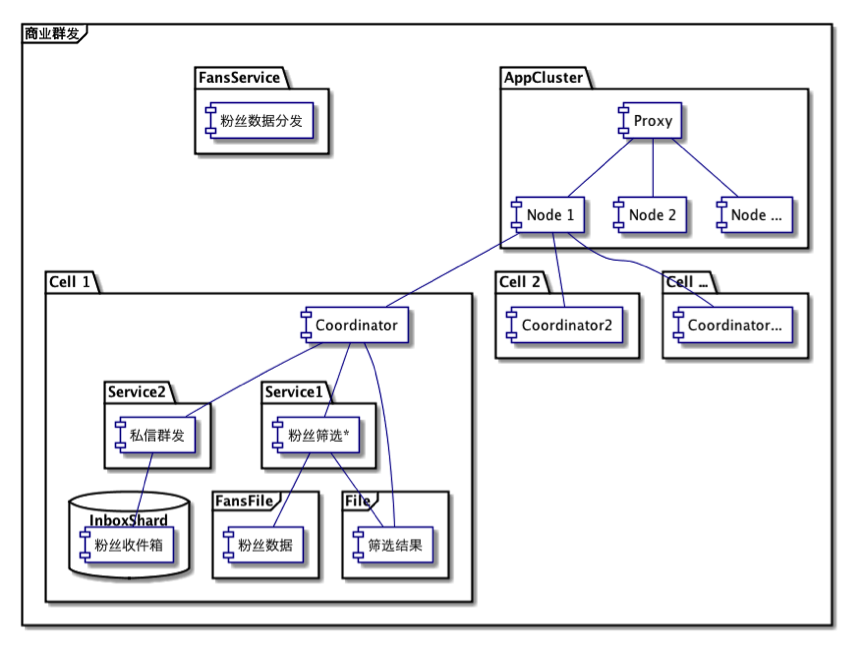
图 5 :商业群发在单元化思想下的架构设计(新版)
对于筛选服务,在服务化架构里,需要去粉丝服务获取粉丝关系,然后去特征服务进行用户特征筛选,最后将筛选结果传输到群发服务器上;而在单元化架构里,粉丝关系直接就在本地文件中,用户特征服务也在本地,最后的筛选结果再不需要传输。服务本地化(粉丝关系和用户特征存储)减去了网络开销,降低了服务延时,还同时提高了访问速度和稳定性,而筛选结果本地存储又进一步节省了带宽并降低了延迟。以百万粉丝为例,每次网络操作的减少节省带宽 8M 左右,延时也从 400ms 降为 0。
群发服务同样如此。由于在服务化架构里,我们使用 MySQL 和 Memcache 的方案,由于关系数据库的写入性能问题,中间还有队列以及相应的队列处理机,所有四个模块都有单独的机器提供服务,而在单元化架构里,四合一之后,只需要一套机器。当然机器的配置可能会有所提升,但真正计算之后你就会发现其实影响微乎其微。原因除了前面介绍的硬件增长空间外,上架机器的基本配置变高也是一个原因。而且,在单元化方案里,当我们把缓存部署在本地之后,其性能还有了额外的 20% 提升。
一些业务特有问题
不过群发这个场景,我们也遇到了一些特定的问题,一是分区问题,一是作业管理。这里也与各位分享下我们的解决方法。
- 分区问题
分区问题其实是每个服务都会遇到的,但单元化后的挑战在于让所有服务都适配同一分区算法,在我们的场景下,我们按照接收者进行了分区,即从底层往上,每一层都来适配此分区算法。
这里有特例的是用户特征和屏蔽服务,由于总体容量都很小,我们就没有对数据进行分区,所有单元内都是同一套全量数据,都是一个外部全量库的从库。不过由于本单元内的上层服务的关系,只有属于本分区的用户数据被访问到。所以,适配同一分区算法在某种程度上讲,可以兼容即可。
2. 作业管理
按照前面的分区方式,将群发服务的整体架构变成了一个类似 Scatter-Gather+CQRS 的方案,因为 Gather 不是一个请求处理的必须要素。也就是说,一个群发请求会被扩散到所有单元中,每个单元都要针对自己分区内的用户处理这个群发请求。
广播方式的引入,使得我们首先需要在前端机进行分单元作业的处理监控,我们在此增加了持久化队列来解决。同时,由于单元内每个服务也都是单独维护的,作业可能在任何时间中断,因此每个作业在单元内的状态也都是有记录的,以此来达到作业的可重入和幂等性,也就可以保证每个作业都可以在任何时间重做,但不会重复执行。
除此之外,我们还对服务器进行了更为精细的控制,使用 CPU 绑定提高多服务集成部署时的整体效率,使用多硬盘设计保证每个服务的 IO 性能,通过主从单元的读写分离来提高整体服务等等。
后记
我平时不善文章,现在要成文发表,还是有一点紧张的。不过想到或许可以抛砖引玉,有机会向各位大牛学习,或者跟各位同学一起交流,内心又有些许期待。关于微博或者其他任何网站的设计,欢迎大家一起探讨,随时在微博恭候。
感谢马国耀对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




