腾讯第一季度的财报显示,腾讯游戏的收入占腾讯总营收的59.4%,很显然,腾讯游戏已经是腾讯最赚钱的部门,当然,腾讯也是国内最大的游戏发行商。游戏行业相对于其他行业来说特点非常明显,一是需要同时运营多款游戏,二是游戏业务的生命周期长短不一。不管是从数量还是周期来看,游戏行业特殊的业务都为技术团队提出了更高的要求。腾讯游戏从2014 年下半年开始就在生产环境中使用Docker,并取得了不错的成果。目前《我叫MT2》等多款重量级游戏都跑在容器中,且整体运行良好。在8 月28 日的 CNUTCon 全球容器技术大会上,腾讯游戏的高级工程师尹烨将会介绍腾讯游戏业务使用 Docker 的进展及收益,并从内核、网络、存储、运营等方面深入探讨腾讯游戏在实践过程中遇到的问题及解决方案,最后还会复盘反思 Docker 对于游戏业务的价值。本文是会前 InfoQ 记者对尹烨的采访。
嘉宾简介
尹烨,腾讯互娱运营部高级工程师。2011 年毕业加入腾讯,现在主要负责 Docker 等相关技术在腾讯游戏业务的实践。主要关注 Linux 内核、虚拟化、存储等领域,给 libcontainer/kubernetes 等开源项目贡献过代码。
InfoQ:腾讯游戏是什么时候开始使用 Docker 的?能介绍下目前的一些应用情况吗?
尹烨:我们是从 2014 年 6 月份开始接触 Docker,那时 Docker 在国内才刚刚开始兴起,了解的人还很少。Docker 让容器的管理变得非常简单,再加上创造性的分层镜像的技术,给人眼前一亮。我们希望通过 Docker,构建腾讯游戏内部的容器平台,一方面通过容器提高资源利用率,另一方面通过镜像分发技术标准化、统一化应用部署流程。
经过半年的调研、各种测试、系统设计和开发,14 年底,整个系统开始上线试运行。但是对于一项全新技术的应用,大家都很谨慎,因为很多游戏业务的在线玩家很多,我们的压力很大。第一个接入我们 Docker 平台的是腾讯的一款游戏,叫《QQ 宠物企鹅》。这款游戏的架构在容灾方面设计得很好,前端可平行扩展,所以就选它作为试金石了。跑了几个星期,运行正常,然后开始慢慢扩展到其它业务。
现在,我们的 Docker 平台上已经跑了数十款端游、页游和手游的各种游戏应用,特别是新上的手游业务,其中,我们代理的一款重量级手游《我叫 MT2》,一个业务就使用了 700 多个容器。现在整个平台总共有 700 多台物理机,3000 多个 Docker 容器。这个数字在业界并不算多,我们自己也没有刻意去追求数量,相对数量,我们更愿意以稳为先。目前,整个平台运行了大半年,整体运行良好。
InfoQ:与其它行业相比,游戏行业有什么特殊性?Docker 在这样的业务中有什么样的优势?它可以发挥怎么样的价值?
尹烨:相比于其它业务,一是游戏业务更加复杂多样,有端游、手游和页游,有的是分区分服,有的是全区全服;另外,我们又分自研和代理游戏,更加增加了复杂性。这也给业务的运维部署带来了许多不便,尽管我们内部有很成熟的部署平台。而 Docker 统一的镜像分发方式,可以标准化程序的分发部署,解放运维的生产力。特别是代理游戏,如果都以 image 方式交付,可以极大提高效率。
另一方面,一般来说,游戏业务的生命周期长短不一,这需要弹性的资源管理和交付。所以,腾讯游戏很早就开始使用 XEN/KVM 等虚拟机技。相比于虚拟机,容器更加轻量,效率更高,资源的交付和销毁更快。另外,还可以通过修改 cgroup 参数,在线调整容器的资源配额,更加灵活弹性。
InfoQ:腾讯游戏的 Docker 应用场景是怎么样的?
尹烨: Docker 开创性的提出了『Build、Ship、Run』的哲学。总的来看,现在主要有两种使用 Docker 的方式。一是基于 Docker 搭建 CI/CD 平台,重点放在 Build 和 Ship 上面,一般用于开发、测试环境;另外就是将 Docker 容器当作轻量级虚拟机,更加关注 Run 的问题,大规模的用于生产环境。个人认为,这两种方式无所谓谁好谁坏,长远来看,二者会渐渐趋于统一。
腾讯内部有很成熟的开发、部署工具和流程,我们作为平台支撑部门,去推动业务开发改变原来的开发模式需要的较长的时间周期。所以,我们现在更多的是将 Docker 容器作为轻量级的虚拟机来使用,我们在 Run 上面花了很多时间和精力。同时,我们也在探索通过 Image 方式去标准化业务部署流程。但是,我们不太会去做 CI/CD 的事情,我们更关注提供一个高效的容器资源调度管理平台,然后以 API 的方式对外,提供给开发和运维同学使用,比如,与互娱的蓝鲸平台打通。
InfoQ:能否介绍下你们线上的 Docker 集群所使用的技术栈?
尹烨:我们的使用 Docker 的初衷是替代虚拟机,所以我们直接将 Docker 跑在物理机上。我们使用 Docker 面临的第一个问题就是操作系统内核的问题。腾讯内部一般使用自己的 OS(tlinux)团队维护的内核,这个内核历史比较久,不支持 Docker,我们就选择了 CentOS 6.5 的内核。实际上,由于 CentOS 的内核不像 Ubuntu,演进得很慢,CentOS 6.5 的内核也很老,但基本能把 Docker 跑起来。但在实际使用过程中遇到了一些内核方面问题,现在 tlinux 团队已经提供了 3.10.x 内核的支持,我们也在逐渐往 3.10.x 的内核迁移。
第二个问题就是容器集群的管理调度,那时候虽然出现一些专门针对 Docker 的容器管理工具,比如 Fig、Shipyard 等,但这些工具无法胜任生产环境大规模集群管理调度。刚好那时 Google 开源了 Kubernetes,它是 Borg 的开源版本实现。源于对 Google 的崇敬,我们研究了一下源码,基于 0.4 版本,针对我们的环境做了一些定制修改,用于我们的集群管理调度。现在我们最大的单个 Kubernetes 集群 700 多台物理机、将近 3000 个容器,生产一个容器只需几秒钟。
容器的监控问题也花了我们很多精力。监控、告警是运营系统最核心的功能之一,腾讯内部有一套很成熟的监控告警平台,而且开发运维同学已经习惯这套平台,如果我们针对 Docker 容器再开发一个监控告警平台,会花费很多精力,而且没有太大的意义。所以,我们尽量去兼容公司现有的监控告警平台。每个容器内部会运行一个代理,从 /proc 下面获取 CPU、内存、IO 的信息,然后上报公司的监控告警平台。但是,默认情况下,容器内部的 proc 显示的是 Host 信息,我们需要用 Host 上 cgroup 中的统计信息来覆盖容器内部的部分 proc 信息。我们基于开源的 lxcfs,做了一些改造实现了这个需求。
(点击放大图像)
这些解决方案都是基于开源系统来实现的,当然,我们也会把我们自己觉得有意义的修改回馈给社区,我们给 Docker、Kubernetes 和 lxcfs 等开源项目贡献了一些 patch。融入社区,与社区共同发展,这是一件很有意义的事情。

InfoQ:在我的印象里,游戏还是相对较保守的行业。你们在内部推进 Docker 过程中遇到过哪些阻力?是如何解决的?
尹烨:首先,我们会在 Docker 新功能接入与业务原有习惯之间做好平衡,尽量降低业务从原来的物理机或虚拟机切换 Docker 的门槛,现阶段业务接入我们的 Docker 平台几乎是“零门槛”。正如前面所述,我们的 Docker 平台上已经跑了数十款端游、页游和手游。
其次,Docker 相对原有的开发部署方式变化很大,与其它新事物一样,让大家全部适应这种方式是需要一些时间,但 Docker 本身的特性是能够在游戏运营的各环节中带来诸多便利,我们的业务主观上对新技术的应用还是欢迎的,双方共同配合,共同挖掘 Docker 在游戏运营的中的优势,所以 Docker 推广目前没有遇到太大的阻力。
InfoQ:应用过程中,哪些问题是 Docker 目前无法解决的?你们的解决方案是怎样的?
尹烨:我们在实践过程中遇到了很多问题,有些是内核的问题,也有些是 Docker 本身的问题。由于篇幅问题,这里仅举一些比较大的问题。详细的分享留到 8 月底的容器技术大会吧。
我们遇到的第一个大的挑战就是网络的问题,Docker 默认使用 NAT 方式,这种方式性能很差,而且容器的 IP 对外不可见。一般来说,游戏业务对网络实时性和性能要求较高,NAT 这种方式性能损失太大,根本不能用于实际业务中。另外,腾讯内部的很多程序对 IP 都是很敏感的,比如只有特定的 IP 才能拉取用户的资料,如果这些服务没有独立的 IP,是无法正常运行的。
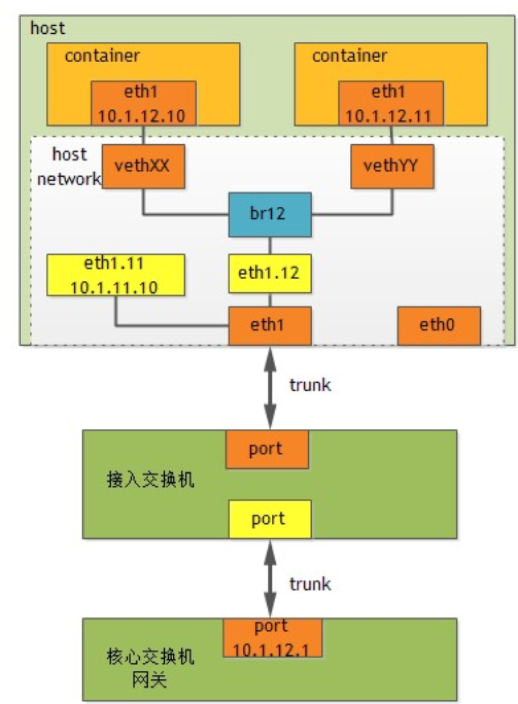
我们针对腾讯的大二层网络环境做了较大的调整,整体架构如下:
整体架构比较简单,与原来虚拟机的网络架构一致。每个容器都有一个独立可以路由的 IP,网络性能大幅提高,基本能满足业务的需求。而且,每个容器都可以携带 IP 在同一个核心交换机下任意漂移,业务通过 IP 漂移可以做很多有意义的事情,比如 Host 故障快速恢复等。
另外,我们针对一些对网络性能要求高的应用,直接使用 SR-IOV,可以完全达到物理机的网络性能。容器相对于虚拟机,有很多优势,但是也有一些劣势,比如安全性、隔离性等。由于我们是内部业务,所以安全性的问题不是那么突出,但隔离性的问题还是给我们带来了很多麻烦。性能监控我们通过 lxcfs 基本解决,但是还是有一些问题无法解决,比如内核参数的问题。很多内核参数没有实现 namespace 隔离,CentOS 6.5 的内核下,在容器内部修改,会影响整个 Host,我们只能在 Host 上设置一个最优的值,然后告诉业务,让他们不要在容器内部修改内核参数。3.10.x 的内核要好一些,对于没有实现 namespace 的参数,在容器内部不可见,这可以防止业务私自修改内核参数,避免对别的业务造成影响。但是,有些业务对内核参数有特殊要求,我们只能让业务选择虚拟机。
再举个例子,一些业务会将程序进行 CPU 绑定,这可以避免 CPU 切换带来的性能损失,由于程序无法获取 cgroup 对容器 cpuset 的限制,绑定会失败,这需要业务程序先获取容器的 cpuset,但还是给业务带来了不便。
再比如,现在 cgroup 对 buffer IO 并不能进行 throttle 限制,不过内核社区已经在解决了,但离生产环境使用,可能还需要些时间。
还有 Docker daemon 进程升级的问题,现有 Docker 实现下,Docker daemon 一退出,所有容器都会停止,这会给大大限制 Docker 本身的升级。但最近社区已经在讨论这个问题,希望这个问题在不久的将来得到解决。
InfoQ:使用过程中有哪些坑?你们有做哪些重点改进?
尹烨:上面已经讨论了很多我们在使用 Docker 遇到的问题,当然还有更多,这里不再一一论述。这里再举个简单的例子吧。Docker daemon 进程在退出时,会给所有的容器的 init 进程发送 SIGTERM 信号,但是如果容器的 init 进程忽略了 SIGTERM 信号,就会导致 daemon 进程一直等待,不会结束。我们修改了 Docker,发送 SIGTERM 信号后,等待一段时间,如果容器还是没有退出,就继续发送 SIGKILL 信号,让容器强制退出。我们将这个修改提交到了 Docker 社区,因为一些原因并没有被接受,不过已经有另外的 PR 解决了。
InfoQ:这么长时间的应用,有做过复盘吗?未来有什么计划?
尹烨:的确,相对于 Docker、Kubernetes 的发展速度,大半年的时间已经很长了。我们使用的 Docker 版本还是基于 1.3.2 的,Kubernetes 的版本是基本 0.4 的,已经很老了,但是基本上是满足我们现在的要求,而且系统运行也很稳定,所以,短时间内不会做大的调整。但是,我们也看到最近 Docker 发布一些非常有意思的变化,比如 network plugin、volume plugin,还实现了默认的 overlay network。Plugin 机制会让 Docker 更加开放,生态圈也会发展得更快。但总体来说,这些新特性还处于 experimental 阶段,等这些特性成熟稳定之后,我们会考虑切换我们的 Docker 版本。
但是,我们也不会坐着等待,也会尝试一些我们需要的东西。比如,最近我们正在实现将 Docker 与 Ceph 结合,我们已经实现了 Ceph rbd graph driver,将 Docker 的 rootfs 跑在了 Ceph 存储集群上面,结合 IP 漂移,可以实现更快的故障恢复。我们也将其实现提交给了 Docker 社区,因为一些技术原因,并没有被社区接受。目前看来,以 plugin graph driver 的方式提供会更好,但是现在 Docker 还不支持 plugin graph driver,不过 Docker 社区正在实现,相信不久就会支持。我们已经在 GitHub 上创建一个开源的 plugin graph driver 项目。
另外,对于 Kubernetes 的应用,我们也还没有完全发挥其优势。Kubernetes 的负责人 Brendan Burns 曾说过,“Make writing BigTable a CS 101 Exercise”,Kubernetes 有很多非常超前的设计思想,当然,也会改变业务原有的一些软件架构,真正应用到实际业务中还需要一些时间。
另外,我们也会继续探索与业务开发、运维的结合方式,进一步发挥 Docker 的优势,提高我们的运营效率,更好的支撑游戏业务的发展。




