
一、ZooKeeper 是什么?
ZooKeeper 是一个开源的分布式服务框架 Hadoop 的一个子项目,Zookeeper 实现诸如数据发布/订阅、统一命名服务、分布式协调/通知、配置管理、分布式锁和分布式队列等功能,通俗的讲 zookeeper 是一个支持增删查改的类似文件系统特点的数据库,按照规则去给节点分配任务。zookeeper 底层实现了存储文件和通知回调功能它的数据结构类似于一个标准的文件系统,相比较文件系统 zk 的每个节点都可以存储数据,但是大小限制为 1M。通常我们在使用 dubbo 的时候会建议使用 zookeeper 作为注册中心,也可以用 redis,eureka 作为注册中心,当然我只用过 zookeeper,dubbo 相当于搭载一个服务框架,zookeeper 则是服务注册的中心。
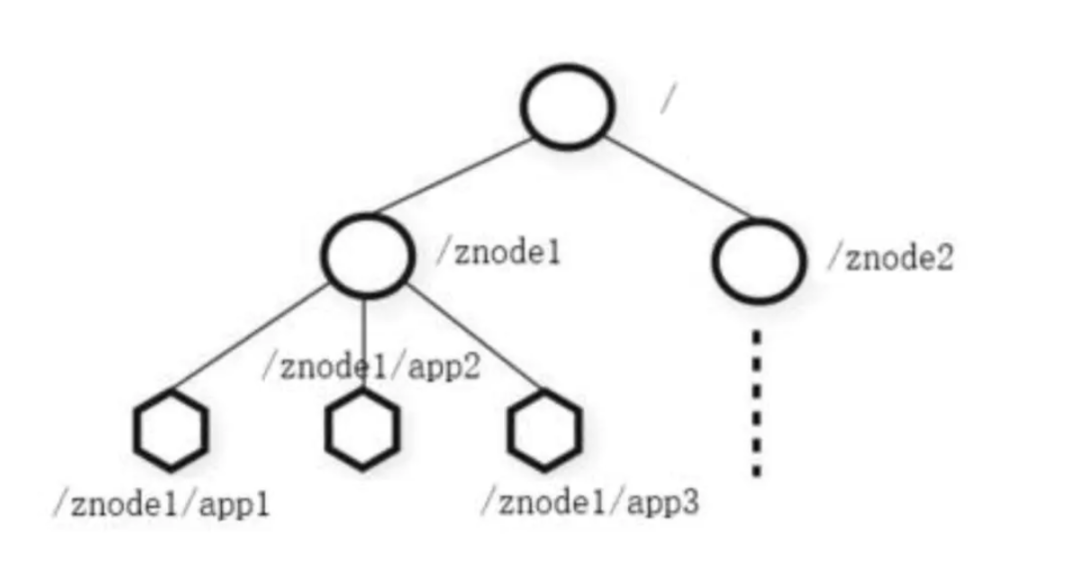
zk 的数据结构
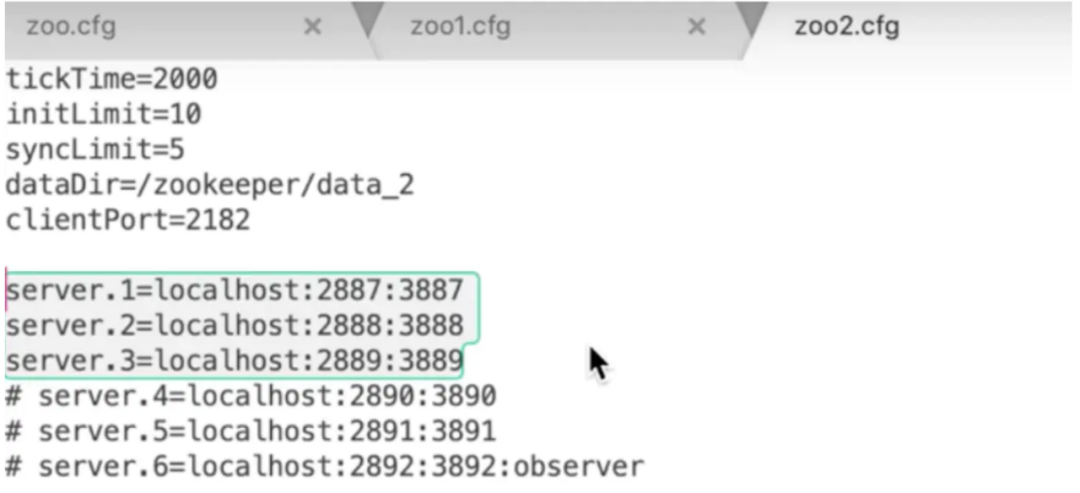
zk 服务的配置文件
上面提到 zk 就是一个数据库那么它的数据就储存在 dataDir 中,上图中的配置是一个集群配置,有 server1,server2,server3 三台服务器,我们这里是一个伪集群(同一台机器启动三个 server),我们可以看到 localhost:A:B,其中 licalhost 是我们的服务 ip,A 是专门用来选举的端口,B 集群进行通信端口,clientPort 是对 client 提供服务的端口。
名词解释:
数据发布/订阅: 初始化节点的时候在服务节点注册一个数据变更 Watcher ,对节点进行变更操作的时候会将数据通知到客户端,客户端接受到变更通知后会重新读取变更后的数据。
统一命名服务: 获得全局的唯一名称,还可以借助 znode 顺序节点的特性产生的节点都会返回顺序编号,在按照给定的名字,生成具有特殊含义的统一名字,所有客户端可创建同一个名字的不同顺序节点。
二、服务器的角色?以及状态
服务器有 Leader、Follower、Observer 三种角色 ;
Leader 是集群内部各个服务的调度者,保证了事务处理的顺序性。
Follower 参与 Proposal 的投票,参与 Leader 选举投票,处理客户端的非事务请求,转发事务请求(增删改,数据变更的操作)给 Leader 服务器。
Observer 不参与投票,在不参与集群事务能力的基础上提升集群的非事务处理能力。
服务器的状态分别为 LOOKING(认为进群中服务器没有 Leader 寻找 Leader 的状态)、FOLLOWING(服务器角色是 Follower 的状态)、LEADING(服务器角色是 Leader 的状)、OBSERVING(服务器角色是 Observer 的状态)。
领导者选举发生的节点有 Leader 挂掉的时候,集群服务器启动的时候,Follower 挂掉后 Leader 发现没有过半的 Follower 跟随了,这三种情况会触发领导者选举。
三、zookeeper 如何解决数据一致性问题?
✨zookeeper server 的启动过程经历了什么?
若要了解 zookeepr 如何解决数据一致性,zookeeper 其实想达到的是强一致性,但是最终达到的是最终一致性,首先我们了解下什么是 CAP?这个大家自行百度,ZK 遵循的是 CP 原则,牺牲了可用性,满足了强一致性。如下图数据库 A 的数据进行了变更为 2 后,在步骤 2 进行读取的时候不能读取到的是 1,那么要求数据库之间同步非常迅速或者在步骤 2 上加上锁待数据同步完成后再读取到结果。
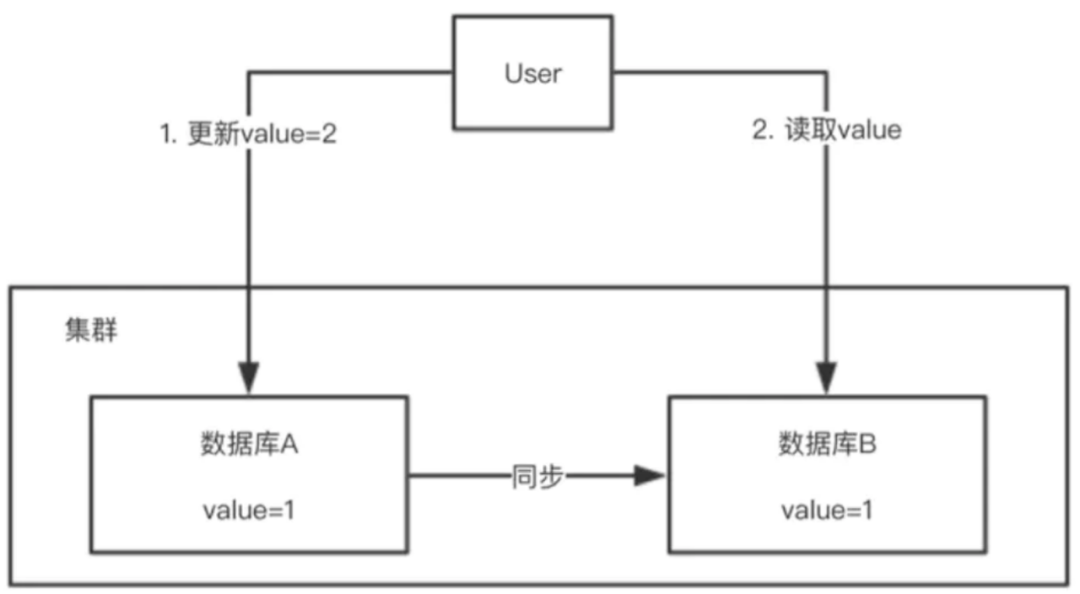
强一致性的例子
我们来大致跟下源码中的选举流程我用的是 git 上的 3.6.1 的版本,找到 zkServer.sh。
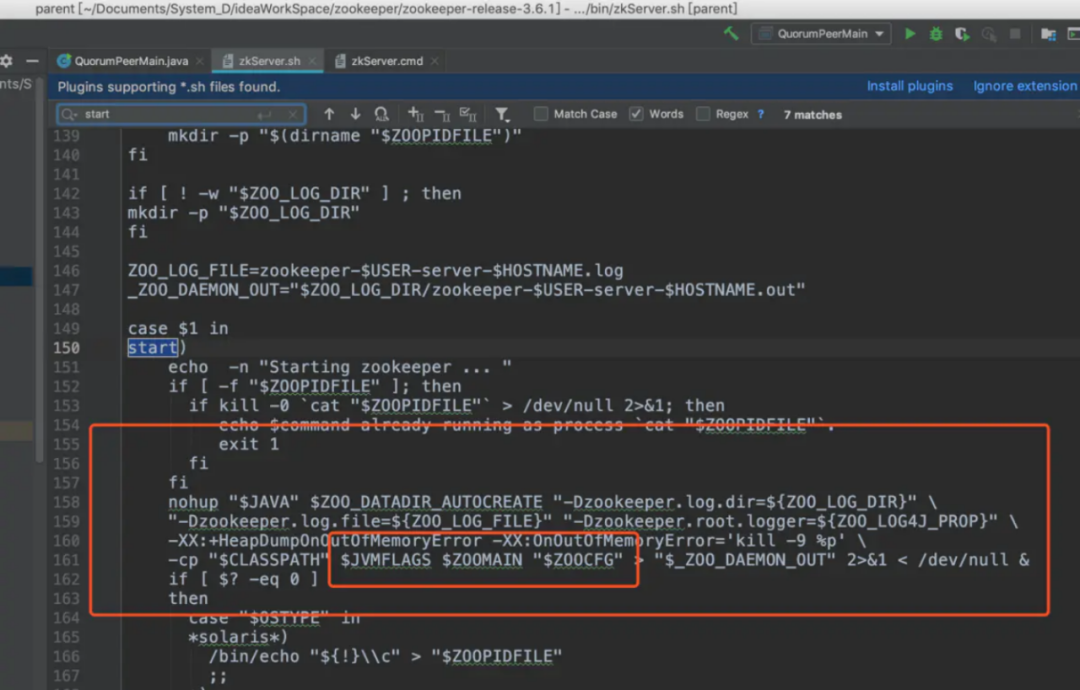
找到守护进程的启动脚本
找到参数中
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain" 对应的这个类就是你查看源码服务的入口了。
在入口 main 方法中有一个初始化方法,main.initializeAndRun(args);这个方法进入以后图中标红的是进入集群模式的方法,我们来看这个方法。
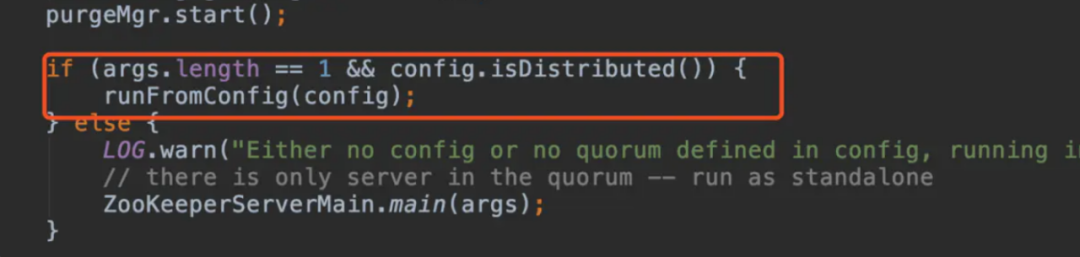
判断为集群模式
进入方法之后你会看到一堆 set,读取配置文件值到 QuorumPeer 这个对象中呢,然后是对象的 start,在启动的时候就进行了调用选举方法。
大家想一下 zookeeper 为何选择奇数服务器?
这个要从 zookeeper 的过半机制说起,假如 6 台机器只最大允许集群中宕掉 2 台机器,5 台机器也是允许宕机两台,从资源利用的角度所以建议选择奇数台服务器。
标红的这块为//投票决定方式,默认超过半数就通过
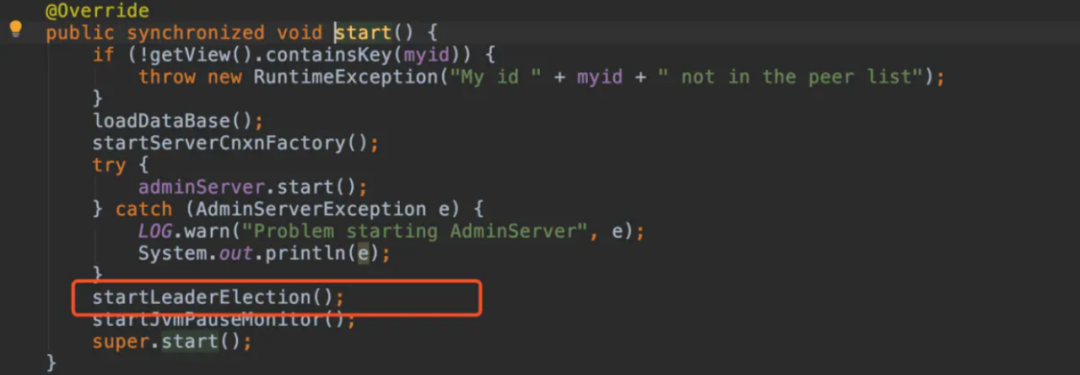
标红的为 leader 选举方法
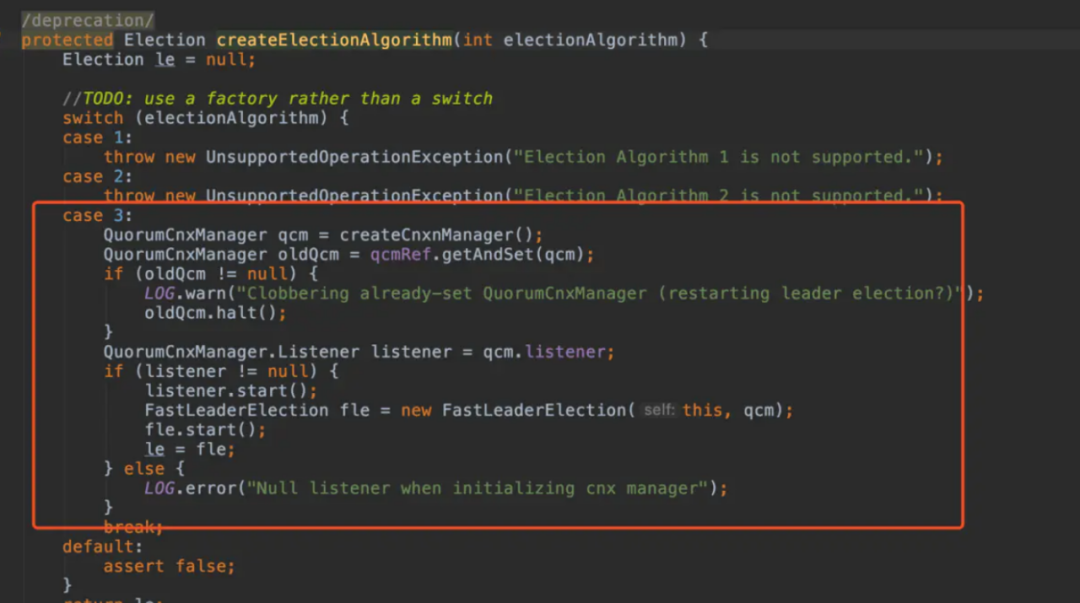
默认 electionAlgorithm 为 3
在 FastLeaderElection 类中 lookForLeader 方法的 case looking 条件下进行投票选举。private boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch)将收到的对方的投票与当前自己的投票对比,判断对方的投票是否优于自己的投票。
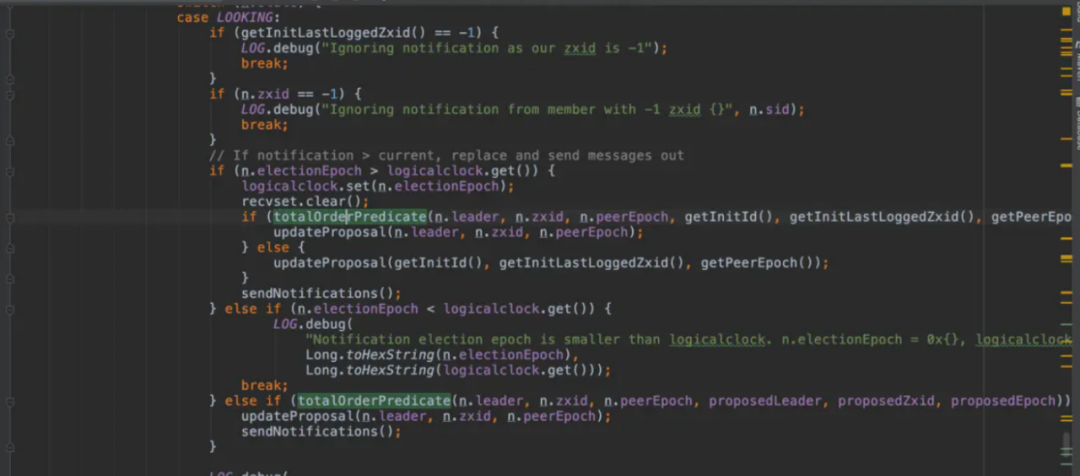
totalOrderPredicate
只要当前服务器状态为 LOOKING,进入循环,不断地读取其它 Server 发来的通知、进行比较、更新自己的投票、发送自己的投票、统计投票结果,直到 leader 选出或出错退出。
选举比重参数
①Serverid: 服务器 ID 比如有三台服务器,编号分别是 1,2,3。编号越大在选择算法中的权重越大。
②Zxid: 事务日志 id,事务请求每次就会生成一条事务日志,服务器中存放的最大数据 ID.值越大说明数据越新,在选举算法中数据越新权重越大。
③Epoch: 逻辑时钟,或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比
集群启动投票流程
①每个 Server 会发出一个投票,因此对于 Server1,Server2 和 Server3 来说,都会将自己作为 Leader 服务器来进行投票,每次投票包含最基本的元素有:所推举的服务器的 myid 和 zxid,我们以(myid,zxid)的形式来表示,即 Server1 的投票为(1,0),Server2 的投票为(2,0),然后各自将这个投票发给集群中其他所有机器。
② 接收来自各个服务器的投票,判断该投票的有效性,包括检查是否是本轮投票,是否来自 LOOKING 状态的服务器。
③ pk 投票,在接收到来自其他服务器的投票后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK:
优先检查 zxid,zxid 比较大的服务器优先作为 Leader。
如果 zxid 相同的话,那么就比较 myid,myid 比较大的服务器作为 Leader 服务器。结果 Server1{(2,0),(2,0)},Server2{(2,0),2,0)}将票投给了 Server2,那么 Server3 也就直接跟随投给了 Sever2,最终确定了 Leader。
本文转载自公众号宜信技术学院(ID:CE_TECH)。
原文链接:




