
本文介绍了 Adobe 公司在使用 Iceberg 时遇到的小文件问题以及高并发写入的一致性问题。针对这两个问题,Adobe 给出了有指导意义的解决方案。
本文最初发表于 Adobe 技术博客(《High Throughput Ingestion with Iceberg》),经 InfoQ 翻译并分享。
企业用户通过使用Adobe Experience Platform对企业数据进行汇集和标准化处理,可以获得企业数据 360 度全方位的展示。我们之前发布了一篇名为《Iceberg at Adobe》的博客,在这个博客中,介绍了我们在海量数据和一致性方面面临的挑战,以及系统向 apache Iceberg 迁移的需求。Adobe Experience Platform 作为一个开放可拓展的平台,面对海量的数据,不仅可以支持低延时的流式计算,也可以高效的对数据进行批处理。
在使用 Iceberg 时,我们遇到了将小文件高频地发送到 Adobe Experience Platform 进行批处理的场景。该场景在大数据行业中被称为“小文件问题”,这是一个常见的典型案例。我们在尝试将这些小文件大规模地提交到 Iceberg 时,该问题很快就暴露出来,我们亟需一个解决方案。本文详细介绍了磁盘缓冲写入模式下,我们是如何通过关键的数据写入方案来解决这个问题的。
数据的流式处理
数据的流式提取允许你将数据从客户端和服务器端实时地发送到 Experience Platform。Adobe Experience Platform 支持将获取的数据转化为流式数据,这些数据会持久化存储在数据湖中支持流式传输的数据集中。在从数据源获取数据时,可以对数据进行自动验证的配置操作,以确保数据来源真实可靠。
负责数据提取的关键组件是 Siphon Stream。它使用了 Apache Spark Structured Streaming流处理框架,该框架是一个分布式可拓展的数据处理引擎,支持多种连接器以及对接多种类型的数据文件。鉴于 Apache Spark 有着丰富的消息处理语义,因此被 Adobe Experience Platform 选为默认的数据处理引擎。
在生产环境下,一般架构下的数据流提取遇到了一些挑战,我们在其他文章中详细介绍了改进措施,具体点击这里可以阅读了解。
数据的批处理
直接数据提取是批处理的一部分。批处理文件将逐批上传到暂存区中,然后进行处理,最后提交到主存储区中。
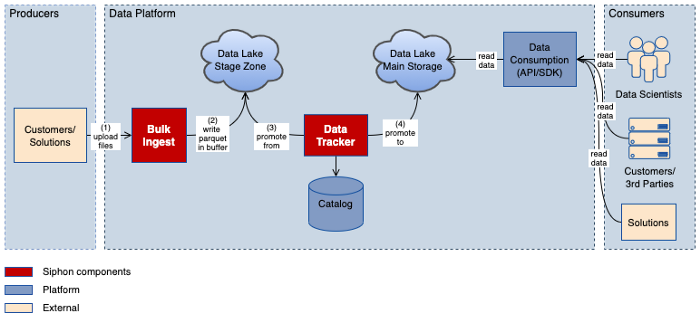
图一:直接数据提取架构
对于数据消费者而言,此过程的优点是数据的抽取速度更快,但是该方案的文件存储方式存在着一些缺点,比如会引起消费者的一些使用问题。
这些缺点主要体现在高吞吐量场景下会引发两个我们熟知的技术问题:
小文件问题
高并发写入导致资源竞争
系统的吞吐量
我们当前所讨论的高吞吐量是以某个数据集每天的文件数来衡量的。我们通常会在时序数据库中看到一些高频小文件,这些文件记录了点击流和其他事件的数据。
通过观察时序数据,我们每天需要处理的数据量统计如下:
总计文件抽取数量在 700,000 左右。
总计数据抽取大小在 1.5 TB 左右。
每个数据集支持的文件吞吐量约为 100,000。
每个数据集支持的吞吐量大小约为 250 GB。
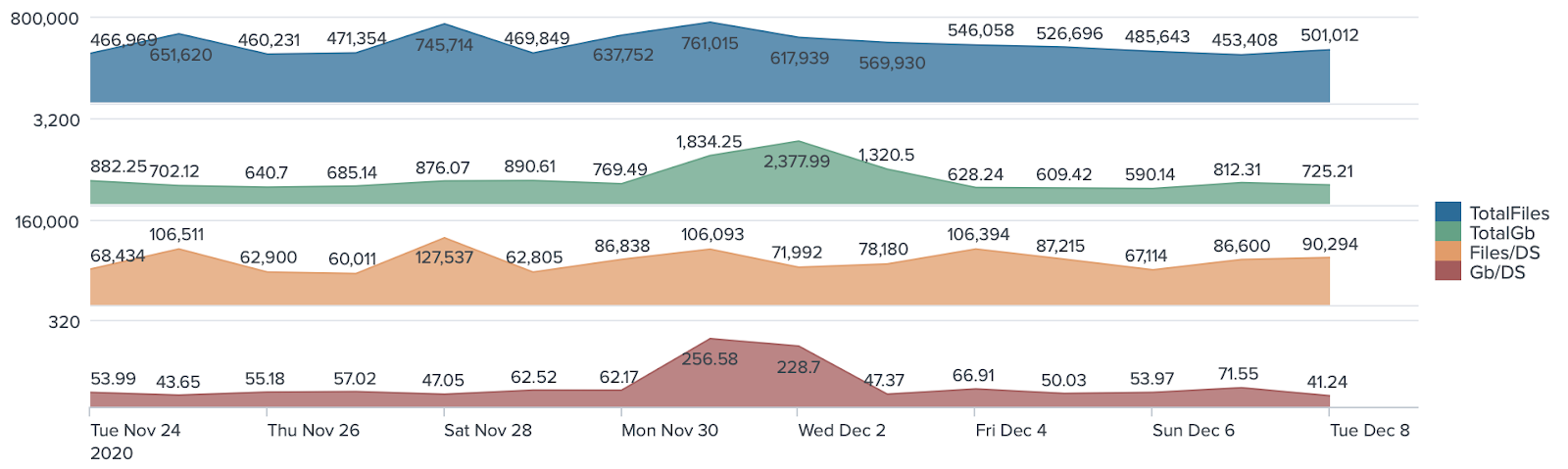
图二:每日数据吞吐量统计
小文件问题
小文件问题是分布式存储中已知的问题。对于 HDFS,当存储多个小于块大小的文件时,就会出现此问题。 HDFS 旨在处理以大文件形式存储的大量数据。
一般情况下,HDFS 中的每个文件,目录和块都表示为 namenode 机器内存中的一个对象,每个对象占用 150 个字节。因此,如果有 1000 万个小文件,每个文件占用一个块,那么总共将占用 3GB 内存。当前的硬件可以毫无压力地支持这个级别的内存。当然,如果有 10 亿个文件的话,硬件上可能就无法很好地进行支持了。
小文件进行读取检索时,通常会导致从一个数据节点到另外一个数据节点的大量查找和跳转,这些都是效率十分低下的数据访问模式。
Iceberg 通过优化文件扫描并更加准确地定位需要加载的文件,实现读取效率的提升。Iceberg 读取器会借助元数据,对分区和列存储数据进行修剪操作。
上面的解决方案在一定程度上会有所帮助,但是在诸如 Adobe Experience Platform 之类的高吞吐量数据抽取系统中,将会遇到在 Iceberg 表中高并发写入的问题。
高并发写入问题
Iceberg 使用乐观锁来处理并发写入问题。当出现数据版本冲突时,Iceberg 会自动重试以确保数据更新成功。 在这种情况下,Iceberg 可能会进行多次重试,以较低的时延高效地进行数据操作。
Iceberg 使用快照在并发写入之间进行隔离,并且这些快照是在 Iceberg 表的每次提交(数据更新或更改)时进行创建。
Iceberg 的初始测试报告显示每个数据集每分钟限制 15 次提交,而我们需要每个数据集每分钟至少处理 30 次以上。 每次提交均从先前的快照开始,并产生一个新的快照。
进行这种限制的原因是,Iceberg 会一直扫描先前快照的元数据文件,并在写入数据后生成新的快照。读取以前的快照然后创建新的快照,这个过程十分耗时,并且耗时会随着元数据增加而增加。
我们需要解决 Iceberg 的这一局限性问题,并在不引入不可预测的数据延迟的情况下,满足我们对数据提取机制的吞吐量期望。
解决方案
我们提出与 Iceberg 集成的策略是在 Adobe Experience Platform 中缓冲我们写入的数据。
缓冲写入是一种批处理模式,可以满足我们的数据需求,因为它可以解决我们在 Adobe Experience Platform 这样的高吞吐量数据处理环境中出现的两个主要问题:
HDFS(Hadoop 分布式文件系统)中已知的小文件问题
Iceberg 表上的高并发写入问题
该解决方案意味着存在一个单独的服务,该服务提供缓冲点,负责确定何时以及如何打包数据,并将数据从该缓冲点迁移到数据湖。
使用单独的服务的有以下优点:
优化写入效率:减少写入次数的同时,增加写入的数据量。
优化读取效率:读取器打开的文件数量进一步缩小。
弹性伸缩:由于缓冲写入使用单独的按需作业,因此该服务可以根据业务需要进行弹性伸缩。
架构介绍
下图说明了在 Adobe Experience Platform 中,从生产者到消费者的数据提取的缓冲写入解决方案。
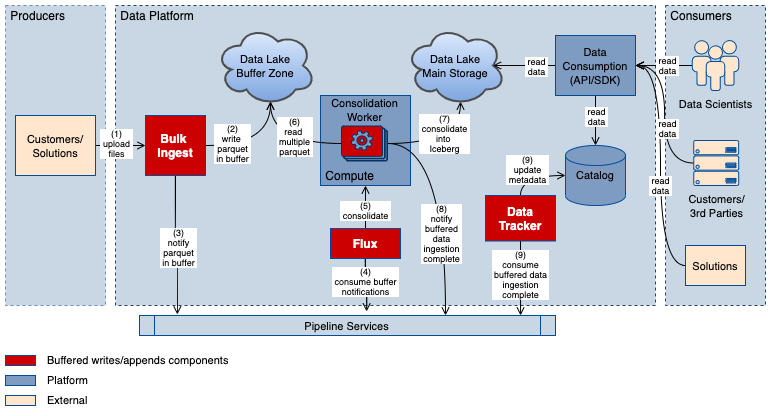
图三: 缓冲写入解决方案架构图
该架构图按照数据处理阶段可以简要概括为三个方面:
生产者:在数据处理的第一阶段,客户端或外部解决方案生成的数据可以是事件、CRM 数据或维度数据,通常这些数据都以文件形式存在。它们将会通过批量提取服务(Bulk Ingest)进行上传或推送。
数据处理平台:这是数据处理的第二阶段,在这里数据会被消费,并以 Parquet 文件写入到缓冲区中,在缓冲区,数据会停留一段时间。此缓冲区是数据提取过程的第一站。此时,Flux 组件将被通知新数据已就绪,并对数据读取以进行合并。根据指定的规则和条件,Flux 会处理一定数量和(或)一定时间的缓冲数据,然后将数据高效地写入用户可以访问的存储当中。数据跟踪器(Data Tracker)会依次负责生成高级元数据和指标数据。
消费者:在数据处理的最后阶段,客户可以使用 Adobe Experience Platform SDK 和 API 高效提取聚合后的数据,以训练他们的机器学习模型,或者运行 SQL 查询,绘制仪表看板和生成报告,丰富统一配置管理数据,对用户群体进行画像和细分等等 。
数据平台包括以下组件:
Bulk Ingest:批量提取模块,负责提取数据并将其保存到缓冲存储中
Data Lake Buffer Zone:数据湖缓冲区,缓冲数据的存储位置
Pipeline Services:数据管道服务,即 Adobe Experience Platform 的 Kafka 中间件,主要用于状态管理
Flux:Spark 状态流应用程序,包含缓冲数据的逻辑处理
Compute:基于 Azure Databricks 构建的 Adobe Experience Platform 计算服务,该服务提供了对 Apache Spark 的支持,可以用于执行短生命周期的作业任务以及长期运行的应用程序
Consolidation Worker:数据合并计算单元,使用 Iceberg 语义处理后将缓冲区存储中的数据分类合并,然后将其写入主存储中
Data Lake Main Storage:数据湖主存储,可对用户提供数据存储和读取服务
Data Tracker:数据跟踪器模块,负责对高级元数据进行管理
Catalog:为用户提供高级元数据服务
数据流
数据平台收集到的文件数据大小不一,并且可能属于不同的数据分区。这些文件在到达数据处理平台时会进行缓冲,然后经过重新组合以写入最少数量的文件,同时生成最少数量的提交。
为了了解其工作原理,接下来逐一介绍两种场景:无缓冲写入和缓冲后写入。
如果不使用任何缓冲写入操作,那么任何新到达的文件都会被立即提取,不会进行任何优化。
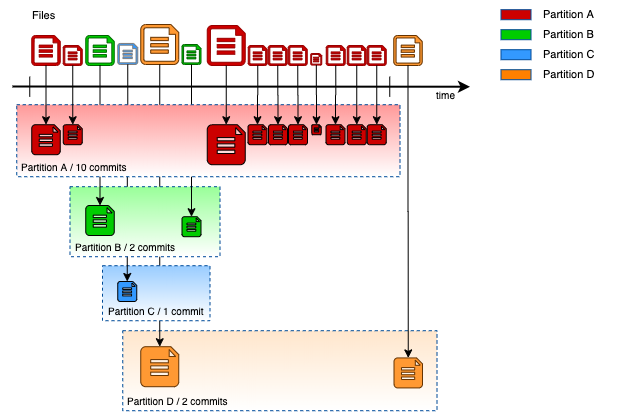
图四:没有使用缓冲写入方案的数据流示意图
从图中可以看出,15 个小文件意味着 15 次的数据提交。
使用缓冲写入方案升级后,数据会一直等待适当的时间来被提取和优化,以使文件和提交的数量最少。
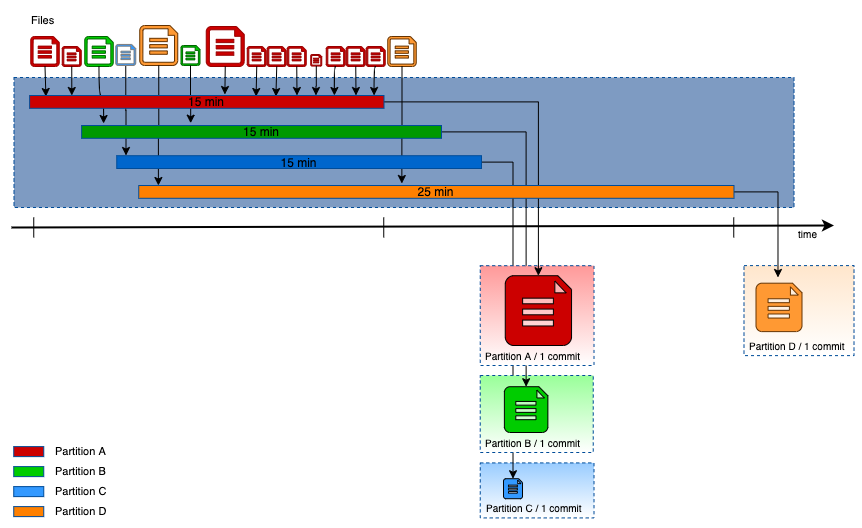
图五:使用缓冲写入方案的数据流示意图
从上图可以看出,使用缓冲写入方案,同样的 15 个小文件,最终合并成了 4 个文件,并且最后只需要 4 次提交操作。
数据合并计算单元
实现缓冲写入的主要组件是“数据合并计算单元(Consolidation Worker)”。这是一个生命周期很短的过程,当缓存了足够的数据并且必须将其写入主存储时会触发该过程。
该计算单元以租户形式工作,并会尝试优化分区内的数据,但功能不仅仅局限于此,它还可以处理跨多个分区的文件数据。
Iceberg 社区帮助我们克服了使用 Consolidation Worker 的两个障碍。首先,通过使用 Apache Iceberg 中已经存在的 Write Audit Publish Flow(WAP)功能,在提交数据时会提供准确一次性语义保证。其次,它降低了由于并行覆写 version-hint.txt 文件而导致的提交错误。对于这些感兴趣的读者,可以阅读一下文章结尾列出的资源链接。
写入审核发布流程 (WAP)
Iceberg 具有“写入审核发布”的功能,该功能为数据存储提供分段提交支持,并保证提交后数据可用。WAP 功能依赖于外部给定的 ID(wapID),之后可以通过该 ID 检索到对应的分段提交。最重要的一个作用是它可以确保分段提交的唯一性——确保两段提交不会存在相同的 ID。
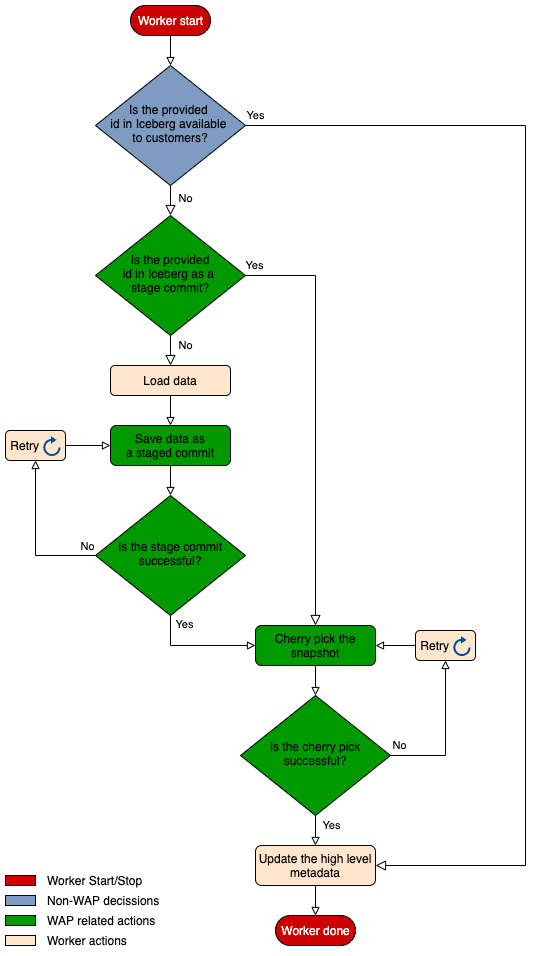
图六:数据合并计算中的写入审核发布流程
WAP 工作流程是在 Consolidation Worker 中实现的:
通过提供的 ID 检查数据是否已经存在于 Iceberg 中,如果是,则只需更新高级元数据
检查数据是否是作为单独的提交缓存,如果是,则将其写入到表中以供用户使用
如果以上两种情况均不存在,那么就加载并使用 WAP 功能写入数据:暂存具有特定 ID 的数据,随后对数据进行选择写入
最后,更新高级元数据存储。
Iceberg 的 version-hint.txt 文件改进
Iceberg 存在高吞吐量并发写入的问题是因为要确保当前正在使用的表是最新版本。在某些情况下,由于已知的非原子性操作,比如重命名或者移动文件操作,会导致提供 Iceberg SDK 当前版本的元文件(version-hint.txt)丢失。
当 Iceberg 提交新版本时,它将通过调用 HDFS CREATE(overwrite = true)API,用新的版本值(当前版本值的增量)替换 version-hint.txt 的当前内容。
而 ADLS(Azure DataLake Store)选择将此 API 实现为 DELETE + CREATE 操作。因此会存在这样一种可能, 在特定的时间内进行提交操作时,version-hint.txt 文件可能会不存在。
由于 Iceberg 读取器和写入器均依赖于版本提示文件 version-hint,在解析并选择要加载适当的元数据版本文件时会引起数据不一致问题。
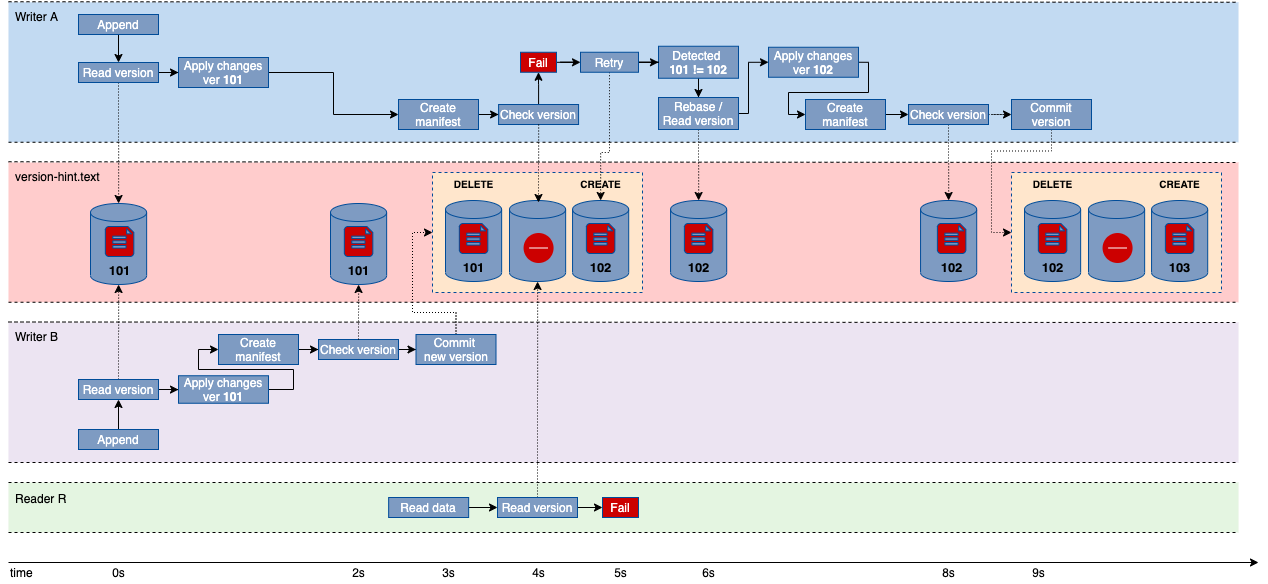
图七: Iceberg 默认的版本文件实现方案
该问题的解决方案依赖于 ADLS 文件系统 API 的一致性保证来持久化表版本,比如 CREATE(overwrite = false)操作的原子性和列表目录的读写一致性。
因此,实现方案是使用目录文件来持久化保存版本信息,因此每个写入都将使用 CREATE(overwrite = false)创建新的文件来标识新版本信息,而读取版本信息时必须列出版本文件目录,并选择此时目录中版本最高的那个值。
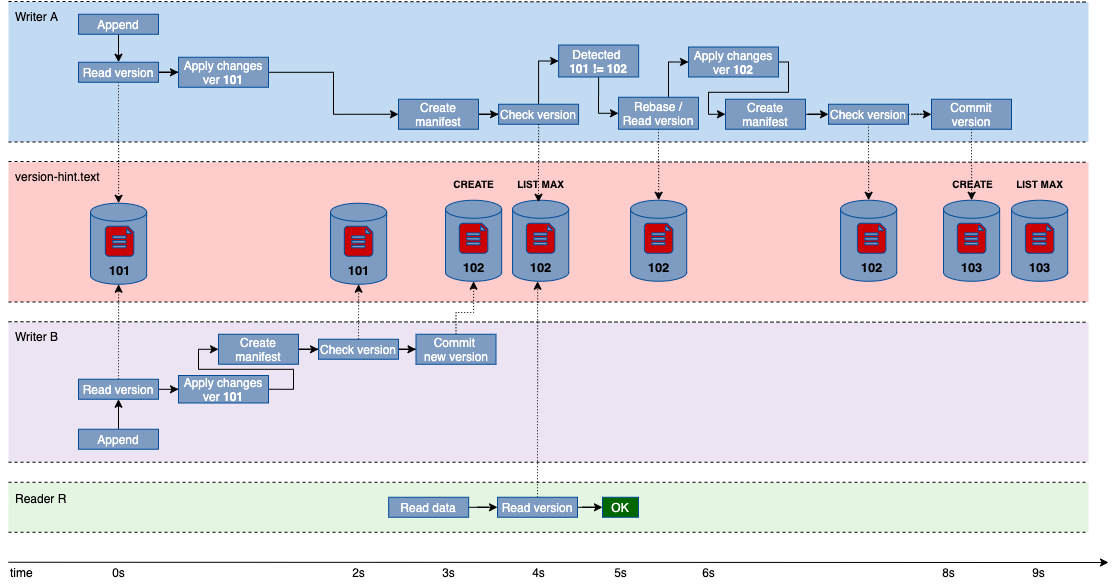
图八:Iceberg 版本文件实现改进方案
该改进是 Adobe 解决一致性问题所采用的方法,我们承认 Iceberg Community 可能会以不同的方法来解决这个问题。
结论
借助缓冲写入解决方案,系统可以远远以超过我们制定的目标吞吐量的负载正常运行。我们进行了一项基准测试,每小时将大约 20 万个小文件提取到单个 Iceberg 表中,最终测试非常成功。此外,我们还可以支持水平扩展以适应未来海量数据处理的需求。唯一的限制就是计算设置的有限的可用资源,这是一个非常值得研究的问题。
在读取数据方面,由于平台已针对读取进行了优化,这完全可以满足我们的业务需求。当读取数据时,Iceberg 本身会带来很多好处,例如矢量化读取,元数据过滤和数据过滤。通过借助其他工具来进一步的优化,还会带来运行时优势。我们将在下一个博客《Taking Query Optimizations to the Next Level with Iceberg》中进一步讨论这些好处。
参考资料
Redesigning Siphon Stream for Streamlined Data Processing (Part 1)
Redesigning Siphon Stream for Streamlined Data Processing in Adobe Experience Platform (Part 2)
Update version-hint.txt atomically (Github ticket discussion)
Core: Enhance version-hint.txt recovery with file listing (Github Pull Request)




