Hadoop 2.3.0 已经发布了,其中最大的亮点就是集中式的缓存管理 (HDFS centralized cache management)。这个功能对于提升 Hadoop 系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
- 用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据,让他们常驻内存而不被淘汰到磁盘。例如在 Hive 或 Impala 构建的数据仓库应用中 fact 表会频繁地与其他表做 JOIN,显然应该让 fact 常驻内存,这样 DataNode 在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于 mixed workloads 的 SLA。
- centralized cache 是由 NameNode 统一管理的,那么 HDFS client(例如 MapReduce、Impala)就可以根据 block 被 cache 的分布情况去调度任务,做到 memory-locality。
- HDFS 原来单纯靠 DataNode 的 OS buffer cache,这样不但没有把 block 被 cache 的分布情况对外暴露给上层应用优化任务调度,也有可能会造成 cache 浪费。例如一个 block 的三个 replica 分别存储在三个 DataNote 上,有可能这个 block 同时被这三台 DataNode 的 OS buffer cache,那么从 HDFS 的全局看就有同一个 block 在 cache 中存了三份,造成了资源浪费。
- 加快 HDFS client 读速度。过去 NameNode 处理读请求时只根据拓扑远近决定去哪个 DataNode 读,现在还要加入 speed 的因素。当 HDFS client 和要读取的 block 被 cache 在同一台 DataNode 的时候,可以通过 zero-copy read 直接从内存读,略过磁盘 I/O、checksum 校验等环节。
- 即使数据被 cache 的 DataNode 节点宕机,block 移动,集群重启,cache 都不会受到影响。因为 cache 被 NameNode 统一管理并被被持久化到 FSImage 和 EditLog,如果 cache 的某个 block 的 DataNode 宕机,NameNode 会调度其他存储了这个 replica 的 DataNode,把它 cache 到内存。
基本概念
cache directive: 表示要被 cache 到内存的文件或者目录。
cache pool: 用于管理一系列的 cache directive,类似于命名空间。同时使用 UNIX 风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1
以上代码表示把 HDFS 上的文件 city(其实是 Hive 上的一个 fact 表) 放到 HDFS centralized cache 的 financial 这个 cache pool 下,而且这个文件只需要被缓存一份。
系统架构与原理

用户可以通过 hdfs cacheadmin 命令行或者 HDFS API 显式指定把 HDFS 上的某个文件或者目录放到 HDFS centralized cache 中。这个 centralized cache 由分布在每个 DataNode 节点的 off-heap 内存组成,同时被 NameNode 统一管理。每个 DataNode 节点使用 mmap/mlock 把存储在磁盘文件中的 HDFS block 映射并锁定到 off-heap 内存中。
DFSClient 读取文件时向 NameNode 发送 getBlockLocations RPC 请求。NameNode 会返回一个 LocatedBlock 列表给 DFSClient,这个 LocatedBlock 对象里有这个 block 的 replica 所在的 DataNode 和 cache 了这个 block 的 DataNode。可以理解为把被 cache 到内存中的 replica 当做三副本外的一个高速的 replica。
_ 注:_centralized cache__ 和 __distributed cache__ 的区别:
distributed cache__ 将文件分发到各个 __DataNode__ 结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上 __distributed cache__ 只做到了 __disk locality_,而 __centralized cache__ 做到了 __memory locality__。_
实现逻辑与代码剖析
HDFS centralized cache 涉及到多个操作,其处理逻辑非常类似。为了简化问题,以 addDirective 这个操作为例说明。
1.NameNode 处理逻辑
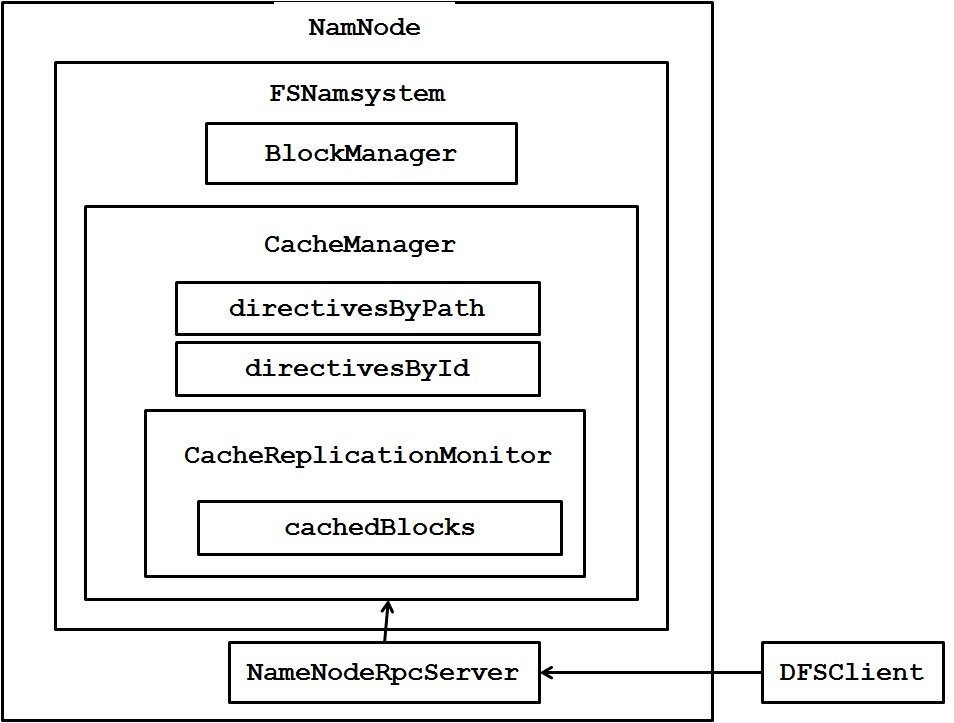
NameNode 内部主要的组件如图所示。FSNamesystem 里有个 CacheManager 是 centralized cache 在 NameNode 端的核心组件。我们都知道 BlockManager 负责管理分布在各个 DataNode 上的 block replica,而 CacheManager 则是负责管理分布在各个 DataNode 上的 block cache。
DFSClient 给 NameNode 发送名为 addCacheDirective 的 RPC, 在 ClientNamenodeProtocol.proto 这个文件中定义相应的接口。
NameNode 接收到这个 RPC 之后处理,首先把这个需要被缓存的 Path 包装成 CacheDirective 加入 CacheManager 所管理的 directivesByPath 中。这时对应的 File/Directory 并没有被 cache 到内存。
一旦 CacheManager 那边添加了新的 CacheDirective,触发 CacheReplicationMonitor.rescan() 来扫描并把需要通知 DataNode 做 cache 的 block 加入到 CacheReplicationMonitor. cachedBlocks 映射中。这个 rescan 操作在 NameNode 启动时也会触发,同时在 NameNode 运行期间以固定的时间间隔触发。
Rescan() 函数主要逻辑如下:
rescanCacheDirectives()->rescanFile(): 依次遍历每个等待被 cache 的 directive(存储在 CacheManager. directivesByPath 里),把每个等待被 cache 的 directive 包含的 block 都加入到 CacheReplicationMonitor.cachedBlocks 集合里面。
rescanCachedBlockMap(): 调用 CacheReplicationMonitor.addNewPendingCached() 为每个等待被 cache 的 block 选择一个合适的 DataNode 去 cache(一般是选择这个 block 的三个 replica 所在的 DataNode 其中的剩余可用内存最多的一个),加入对应的 DatanodeDescriptor 的 pendingCached 列表。
2.NameNode 与 DataNode 的 RPC 逻辑
DataNode 定期向 NameNode 发送 heartbeat RPC 用于表明它还活着,同时 DataNode 还会向 NameNode 定期发送 block report(默认 6 小时)和 cache block(默认 10 秒)用于同步 block 和 cache 的状态。
NameNode 会在每次处理某一 DataNode 的 heartbeat RPC 时顺便检查该 DataNode 的 pendingCached 列表是否为空,不为空的话发送 DatanodeProtocol.DNA_CACHE 命令给具体的 DataNode 去 cache 对应的 block replica。
3.DataNode 处理逻辑
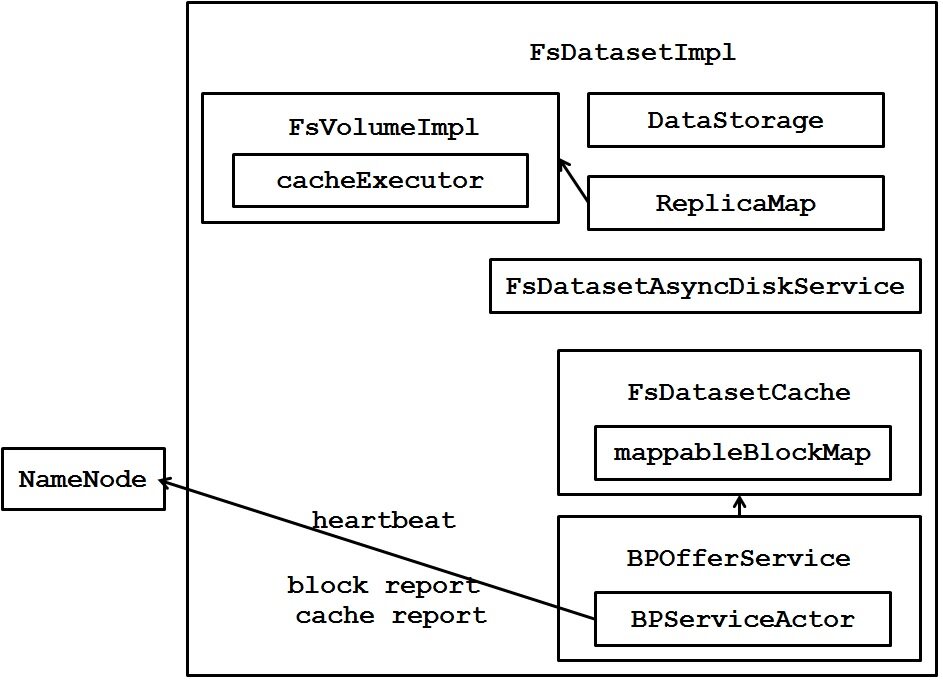
DataNode 内部主要的组件如图所示。DataNode 启动的时候只是检查了一下 dfs.datanode.max.locked.memory 是否超过了 OS 的限制,并没有把留给 Cache 使用的内存空间锁定。
在 DataNode 节点上每个 BlockPool 对应有一个 BPServiceActor 线程向 NameNode 发送 heartbeat、接收 response 并处理。如果接收到来自 NameNode 的 RPC 里面的命令是 DatanodeProtocol.DNA_CACHE,那么调用 FsDatasetImpl.cacheBlock() 把对应的 block cache 到内存。
这个函数先是通过 RPC 传过来的 blockId 找到其对应的 FsVolumeImpl (因为执行 cache block 操作的线程 cacheExecutor 是绑定在对应的 FsVolumeImpl 里的);然后调用 FsDatasetCache.cacheBlock() 把这个 block 封装成 MappableBlock 加入到 mappableBlockMap 里统一管理起来,然后向对应的 FsVolumeImpl.cacheExecutor 线程池提交一个 CachingTask 异步任务 (cache 的过程是异步执行的)。
FsDatasetCache 有个成员 mappableBlockMap(HashMap) 管理着这台 DataNode 的所有的 MappableBlock 及其状态 (caching/cached/uncaching)。目前 DataNode 中”哪些 block 被 cache 到内存里了”也是只保存了 soft state(和 NameNode 的 block map 一样),是 DataNode 向 NameNode 发送 heartbeat 之后从 NameNode 那问回来的,没有持久化到 DataNode 本地硬盘。
CachingTask 的逻辑: 调用 MappableBlock.load() 方法把对应的 block 从 DataNode 本地磁盘通过 mmap 映射到内存中,然后通过 mlock 锁定这块内存空间,并对这个映射到内存的 block 做 checksum 检验其完整性。这样对于 memory-locality 的 DFSClient 就可以通过 zero-copy 直接读内存中的 block 而不需要校验了。
4.DFSClient 读逻辑:
HDFS 的读主要有三种: 网络 I/O 读 -> short circuit read -> zero-copy read。网络 I/O 读就是传统的 HDFS 读,通过 DFSClient 和 Block 所在的 DataNode 建立网络连接传输数据。
当 DFSClient 和它要读取的 block 在同一台 DataNode 时,DFSClient 可以跨过网络 I/O 直接从本地磁盘读取数据,这种读取数据的方式叫 short circuit read。目前 HDFS 实现的 short circuit read 是通过共享内存获取要读的 block 在 DataNode 磁盘上文件的 file descriptor(因为这样比传递文件目录更安全),然后直接用对应的 file descriptor 建立起本地磁盘输入流,所以目前的 short circuit read 也是一种 zero-copy read。
增加了 Centralized cache 的 HDFS 的读接口并没有改变。DFSClient 通过 RPC 获取 LocatedBlock 时里面多了个成员表示哪个 DataNode 把这个 block cache 到内存里面了。如果 DFSClient 和该 block 被 cache 的 DataNode 在一起,就可以通过 zero-copy read 大大提升读效率。而且即使在读取的过程中该 block 被 uncache 了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。
对上层应用的影响
对于 HDFS 上的某个目录已经被 addDirective 缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于 Hive/Impala 式的应用非常有用。
HBase in-memory table:可以直接把某个 HBase 表的 HFile 放到 centralized cache 中,这会显著提高 HBase 的读性能,降低读请求延迟。
和 Spark RDD 的区别:多个 RDD 的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache 中被 cache 的 block 一定是先写到磁盘上的,然后才能显式被 cache 到内存。也就是说只能 cache 读,不能 cache 写。
目前的 centralized cache 不是 DFSClient 读了谁就会把谁 cache,而是需要 DFSClient 显式指定要 cache 谁,cache 多长时间,淘汰谁。目前也没有类似 LRU 的置换策略,如果内存不够用的时候需要 client 显式去淘汰对应的 directive 到磁盘。
现在还没有跟 YARN 整合,需要用户自己调整好留给 DataNode 用于 cache 的内存和 NodeManager 的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
作者简介
梁堰波,北京航空航天大学计算机硕士,美团网资深工程师,曾在法国电信、百度和 VMware 工作和实习过,这几年一直在折腾 Hadoop/HBase/Impala 和数据挖掘相关的东西,新浪微博 @DataScientist 。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




