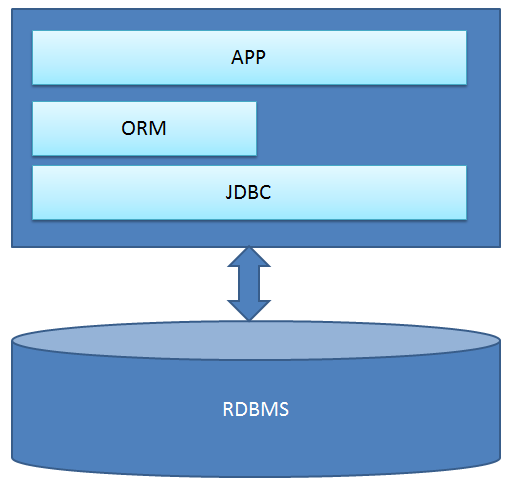
目前企业软件开发占据主流的开发模式为面向对象模式。无论是建立在集合论之上的传统关系型数据库,还是以 CAP 定理 /Hadoop/BigTable 为基石的 HBase,都面临以下的基本问题:
- 如何保存对象到数据存储?
- 如何从数据存储获取对象?
- 如何更新数据存储中的现有数据?数据存储的类型系统和开发语言(Java)的类型系统之间如何相互转换?
简而言之,数据存储如何提供增、删、改、查的服务能力,应用如何方便的使用该能力。关系型数据库给出的答案为 SQL,JDBC 和各种 ORM 框架(典型例子为 Hibernate 和 MyBatis)。
HBase ORM
ORM 即 Object-Relational mapping,对于 HBase 而言不存在 Relational,因此该名称不准确,只是 ORM 做为一个术语使用太过广泛,这里泛指数据存储和 Object 之间的映射。
HBase 的设计和 RDBMS 差异较大,因此除了上一小节的问题外,还需要解决如下问题:
- 如何映射 HTable 的 RowKey?
- 如何映射 HTable 的 bytes 到 Java 类型?
- 如何映射 HTable 的多版本能力?
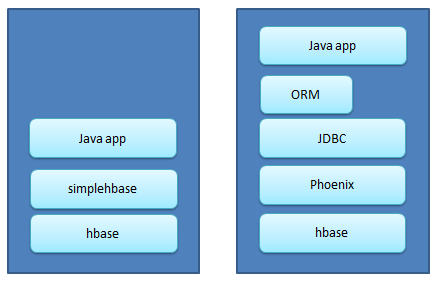
本文着重介绍 HBase ORM SimpleHBase 框架,并和另一个 HBase ORM Phoenix( http://phoenix.incubator.apache.org/ )做比较。
SimpleHBase 简介
SimpleHBase( https://github.com/zhang-xzhi/simplehbase )是 Java 和 HBase 之间的轻量级中间件,主要包含以下功能:
- 数据类型映射:Java 类型和 HBase 的 bytes 之间的数据转换。
- 简单操作封装:封装了 HBase 的 put,get,scan 等操作为简单的 Java 操作方式。
- HBase query 封装:封装了 HBase 的 filter,可以使用 SQL-like 的方式操作 HBase。
- 动态 query 封装:类似于 mybatis,可以使用 xml 配置动态语句查询 hbase。
- insert,update 支持: 建立在 HBase 的 checkAndPut 之上。
- HBase 多版本支持:提供接口可以对 HBase 多版本数据进行查询, 映射。
- HBase 原生接口支持。
- HTablePool 管理。
设计理念
Phoenix 的设计理念为:We put the SQL back into NoSql。该理念的优点如下:
- SQL 做为大众熟悉的 API,用户学习成本较低。
- 减少程序员的代码开发量。
- 性能优化对用户透明。
- 兼容既有的基于 SQL 的工具。
该理念的缺点如下:
- SQL 屏蔽了 HBase 和 RDBMS 设计上的差别,抽象泄露的风险较高。关于抽象泄露参考 http://www.joelonsoftware.com/articles/LeakyAbstractions.html 。
- 为了 SQL 兼容,引入了 JDBC 层。由于 RDBM 和 HBase 的设计与模型本身差异较大,引入 JDBC 后,导致部分 HBase 的特性难以友好的支持。
- 大部分的应用不会直接使用 JDBC,而是使用 ORM,技术栈较深,导致抽象泄露问题更加严重。
SimpleHBase 的设计理念为:贴近 HBase 的 ORM 设计,简化 HBase 之上的 Java app 开发。
该理念的优点如下:
- 设计紧贴 HBase 的逻辑模型,提供一站式 HBase ORM 解决方案。
- 减少程序员的代码开发量。
- 用户友好的 HBase 特征支持。
该理念的缺点如下:
1. 不兼容 SQL,有一定的学习成本。
SimpleHBase 和 Phoenix 的技术栈如下所示。
类型转换
Phoenix 支持如下类型,目前不支持自定义类型。每种类型的序列化 (转化为 bytes 保存到 HBase 中) 和反序列化为固定的方式。
INTEGER
UNSIGNED_INT
BIGINT
UNSIGNED_LONG
TINYINT
UNSIGNED_TINYINT
SMALLINT
UNSIGNED_SMALLINT
FLOAT
UNSIGNED_FLOAT
DOUBLE
UNSIGNED_DOUBLE
DECIMAL
BOOLEAN
TIME
DATE
TIMESTAMP
UNSIGNED_TIME
UNSIGNED_DATE
UNSIGNED_TIMESTAMP
VARCHAR
CHAR
BINARY
VARBINARY
SimpleHBase 支持如下类型。每种类型的序列化和反序列化方式,可以使用 SimpleHBas 提供的默认方式,也可以用户自定义。
boolean
byte
short
char
int
long
float
double
String
Date
Enum
用户自定义类型:
通过 TypeHandler 支持自定义类型扩展。
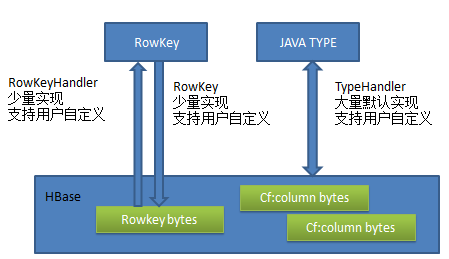
SimpleHBase 的 rowkey 和类型映射如下:
RowKey 支持
Phoenix 把 rowkey 内化为 table 的 PRIMARY KEY 处理。
如
CREATE TABLE IF NOT EXISTS us_population ( state CHAR(2) NOT NULL, city VARCHAR NOT NULL, population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
同时,Phoenix 的 Salted Tables 技术可以解决 region server 的热点问题。
SimpleHBase 认为 rowkey 的设计是 HBase 应用设计中最重要的一环。因此,对于 RowKey 单独建模,给用户提供较高的灵活性。实际上,对于 HBase 而言,任何可以转换为 bytes 的对象都可以做为 rowkey 使用。
简单场景支持
对于简单的 put,scan,delete 场景。
Phoenix 提供的方案为:
Java app -> ORM(可选) -> SQL -> phoenix -> HBase
SimpleHBase 提供的方案为:
Java app -> SimpleHBase-> HBase
无需 SQL 这一层,直接用类似如下代码即可实现。
simpleHbaseClient.putObject(new PersonRowKey(1), person);
Person result = simpleHbaseClient.findObject(new PersonRowKey(1),
Person.class);
简单 SQL 支持
Phoenix 做为 HBase 上面的 SQL 封装,这块的功能比较丰富。SimpleHBase 提供 SQL-Like 方式的查询。支持常见的简单查询场景。目前,SimpleHBase 提供的运算符如下:
lessequal
less
greaterequal
greater
notequal
equal
notmatch
match
in
notin
between
notbetween
isnull
Isnotnull
Ismissing
isnotmissing
and
or
()
复杂 SQL 支持
对于 group by, join 等较为复杂的 SQL 语法,Phoenix 支持,SimpleHBase 目前不支持。
动态 SQL 支持
动态查询可以避免应用代码中大量 if-else 之类的判断,拼接查询条件,提高代码质量。
Phoenix 的方案:
引入其他 ORM 框架 (如 hibernate 或 mybatis)。
Simplehbase 的方案:
类似 mybatis,提供动态查询能力。
目前 simplehbase 提供的动态查询标签如下:
isNull
isNotNull
isEmpty
isNotEmpty
isPropertyAvailable
isNotPropertyAvailable
isEqual
isNotEqual
isGreaterThan
isGreaterEqual
isLessThan
isLessEqual
Dynamic
HBase 时间戳和多版本支持
Phoenix 方案:
时间戳,由 HBase 管理,或在 connection 建立时指定一个时间戳,该 connection 上所有操作就是基于该时间戳。
不支持多版本,只能支持最新值。
Simplehbase 方案:
时间戳可以由 HBase 管理,或者由应用自行指定。版本数,可以选择最新版本,或者多版本支持,由应用指定。
rowkey
timestamp
name
Age
key1
t4
d
key1
t3
c
3
key1
t2
2
key1
t1
a
1
假设 name 和 age 映射为一个 Person 类型对象。SimpleHBase 支持如下映射方式:
-
一个 rowkey 对应的所有最新值映射为一个 object。
例:该数据被映射为 Person(name=d,age=3)。 -
一个 rowkey 对应的时间戳范围内 (由用户指定) 的最新值映射为一个 object (Phoenix 只提供一个时间戳,而不是时间戳范围) 。
例:指定时间戳范围 (左闭右开) 为 [t1,t3),该数据被映射为 Person(name=a,age=2)。 - 一个 rowkey 对应的所有值,以时间戳为维度,映射成一个 object list。
例:指定 maxVersion(控制最大版本数) 为 4, 该数据被映射为一个 person 的列表,按照时间戳排序。 ```Person(name=d)
Person(name=c,age=3)
Person(age=2)
Person(name=a,age=1)
- 一个 rowkey 对应的时间戳范围内的所有值,以时间戳为维度,映射成一个 object list。
例:指定时间戳范围为 \[t1,t3),maxVersion 为 4, 该数据被映射为一个 person 的列表,按照时间戳排序。 ```
Person(age=2)
Person(name=a,age=1)
其他
SimpleHBase 中包含了一些 HBase 特性的封装或增强。
如:
SimpleHBase 支持批量 put 操作,以提升性能。
HTable 的 autoflush 设置为 false,同时,有一个线程定期做 flush。既可以提高应用的吞吐能力,也可以有一定的 flush 保证。
小结
目前,SimpleHBase 已经在阿里的多个项目中得到应用。从设计理念看,SimpleHBase 并不是 Phoenix 的一个重复轮子,而是有着自己清晰的目标。即贴近 HBase 的 ORM 设计,简化 HBase 之上的 Java app 开发。同时,又可以把 HBase 的一些核心概念暴露给用户,方便用户对 HBase 特性的使用。
关于作者:
张信之,支付宝高级工程师,目前负责支付宝消费数据组,西安交通大学计算机科学与技术专业硕士。兴趣广泛,近期工作聚焦在 HBase ORM 框架 Simplehbase 上。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




