
本文由 InfoQ 整理自 OPPO 商业能力中心-工程效能组-高级 DevOps 工程师 冯张弛 在 QCon 全球软件开发大会(北京站)2022 上的演讲《代码快照 x 覆盖率:洞察研发体系的最后 100 米》。
大家好,我是冯张弛,来自 OPPO 商业能力中心-工程效能组。本文主要基于 OPPO 近年在落地持续交付时遇到的一些实际问题,阐述我们是如何利用代码快照技术与传统的代码覆盖率相结合,来定位与解决问题的。希望编译技术在能效领域的应用能给各位带来新的思考与启发。
背景
在进入正文之前,我先介绍下 OPPO 落地持续交付的大致背景,与这个吸睛副标题“研发体系的最后100米”的由来。
持续交付(以正确的速度,做正确的事情,维持正确的质量)一直都是 DevOps 领域的热门话题,也是近年 OPPO 互联网在能效领域的一大目标。高频次的交付对质量团队是一个巨大的考验:如何在成本倍增的回归测试中维持原有的质量?
秉承着“无度量不改善”的原则,我们提出了不少诸如“可体验率”、“24h 内交付”等指标,辅以各类技术指标来拆分与牵引,希望从流程上引导业务团队。在取得一定效果的同时,我们也从指标中看出了一些问题:

我们发现,“提测-验证-打回” 的轮数随着交付频率的变高,成为了我们进一步提速的一大阻碍。为避免用户与平台方之间的认知偏差,我们深度走访了各个一线研发团队去了解其背后根源,可以归纳为三个主要原因:
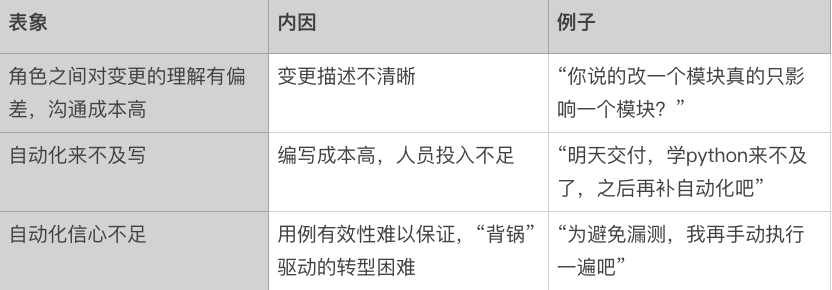
我们可以用信息论来解构这三个矛盾点。比如,需求评审是产品向研发传递需求信息的过程;早会是信息广播的过程;编码是研发向机器传递指令的过程…… 同样的:

用信息传递的方式来描述这个过程的话:
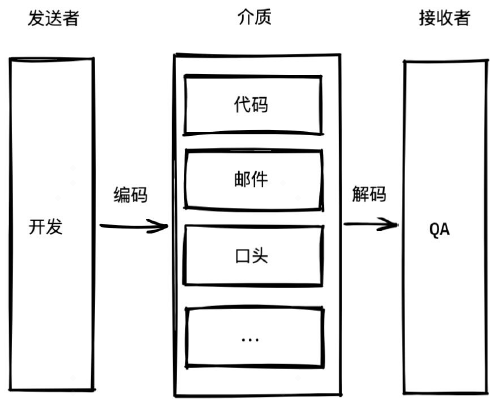
本质上是开发与 QA 之间的信息传递效率问题
无论以何种介质,信息都会经过编解码
编解码因介质的不同,有不同的成本与损失
找到合适的介质将是解决这个问题的关键。而人总是倾向于解决容易解决、收益明确的问题,这类问题因研发环节错综复杂、过于主观、描述模糊等多种限制,往往被我们避而不谈,成为一个灰色地带。

这个深藏在研发流程中的灰色地带被我们称为 “最后一百米“。例如前几年非常流行的送餐机器人,厨师只需要将菜放到机器人上,但最后送餐到桌前时,依旧需要配置人工把餐端到桌上。对应到实际工作中:写了一堆提测文档,最后还是人工指导;写了一堆自动化,最后还是人工点检。这种薛定谔式的提效,就是本文接下来想要讨论与优化的。
01 探索
1.1 覆盖率
刚才提及的三种介质中,相对来说代码是有明确规范、比较客观且可量化的一种。他是开发人员的思路编码,被其他开发人员与 QA 解码并使用。而我们希望将 QA 人员的思路与其相结合,来形成一种复合介质,代码覆盖率是个很自然的选择。
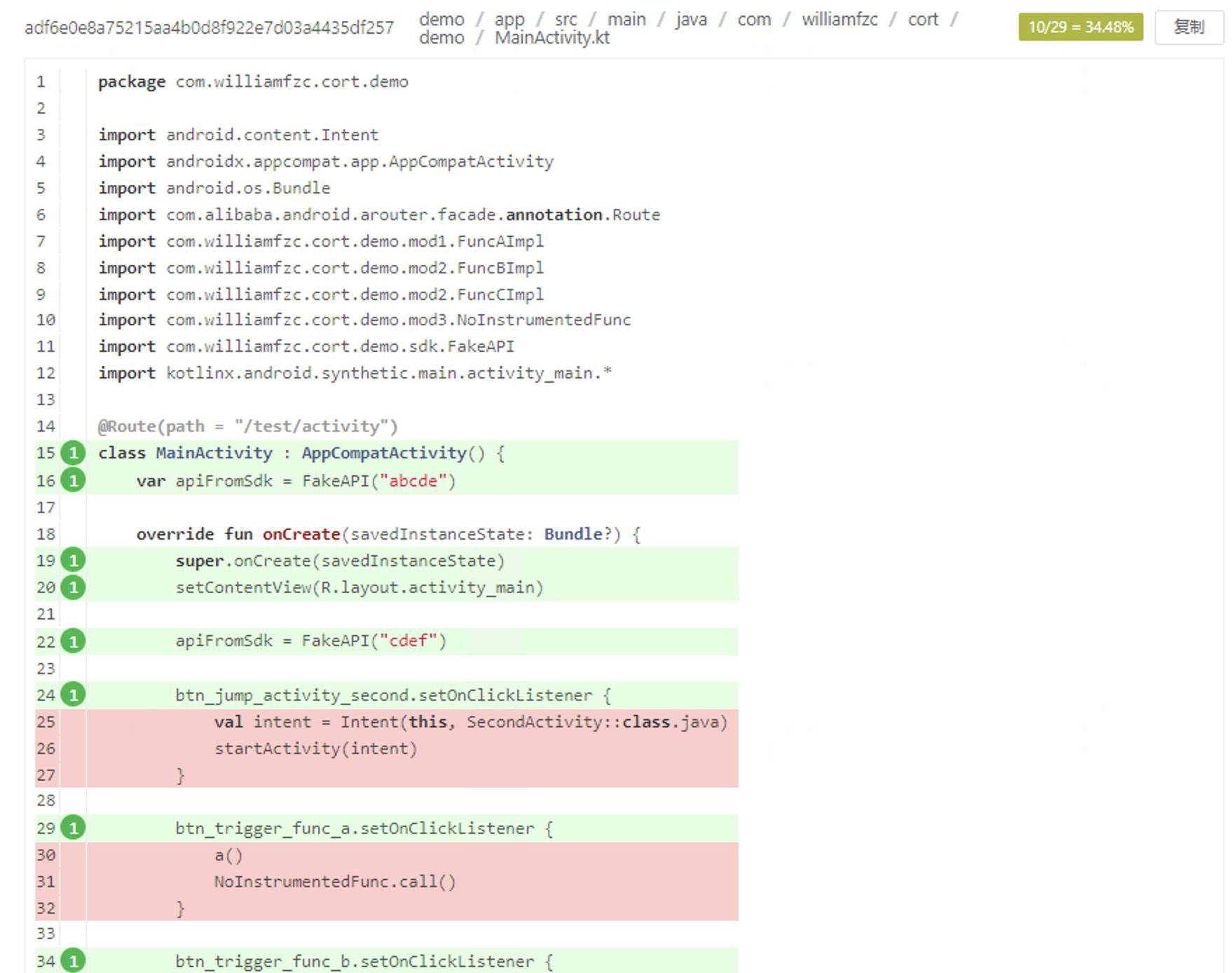
代码覆盖率并不是一个很新鲜的话题,业务也已经有了大量的实践经验,不再过度赘述。简言之,我们可以通过染色(抽象或具象)将 runtime 数据(也就是 QA 侧的行为),与代码绑定在一起呈现。
我们早期在覆盖率上花了不少功夫,总结为:
并在此之上建设了诸如实时染色、多版本聚合、用例绑定等流行的能力,并与流水线做了深度的融合。
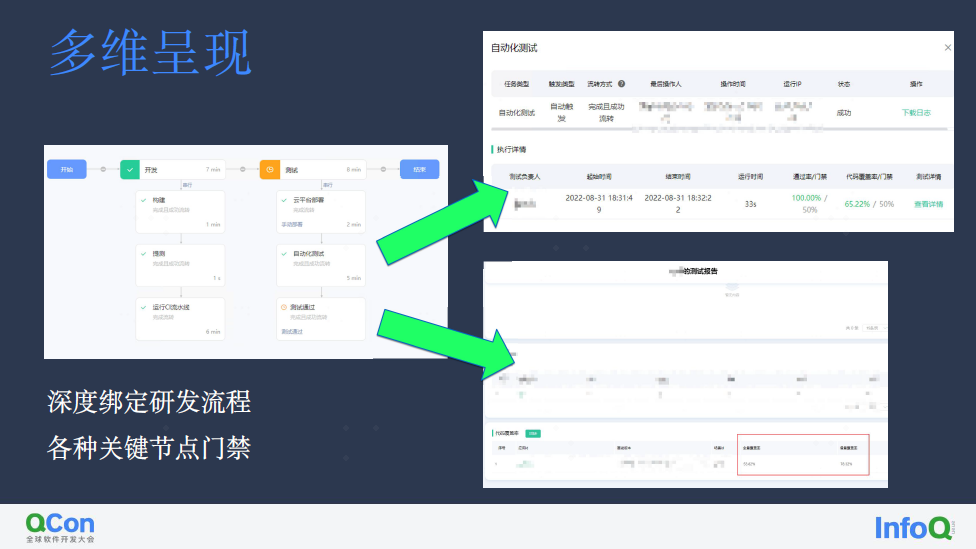
我们一度对此颇为满意,直到持续交付开始。
1.2 指标与问题
持续交付带来了海量的指标,用于把控整套流程的有序性。覆盖率作为一个合适的介质自然也不例外,我们希望业务去观测与优化。
第一个问题是,覆盖率与纠错率是正相关,但又不完全是。严格意义上他只能起到牵引的作用。

常见的开源项目都会以代码覆盖率作为一项关键的质量指标,用于反映整体的置信度。而在这种诉求下,质量反而不是用例需要首要关注的,这催生了不少作弊的乱象:不带断言的用例、无序遍历替代手写等。商业公司当然也不例外,我们在第一轮盘点中就发现了不少没有断言的用例。
机器相关的问题终归是有迹可循的,用例检查、复合指标的方案可以有效地将用例控制起来。而第二个问题则回到人身上,更加棘手。
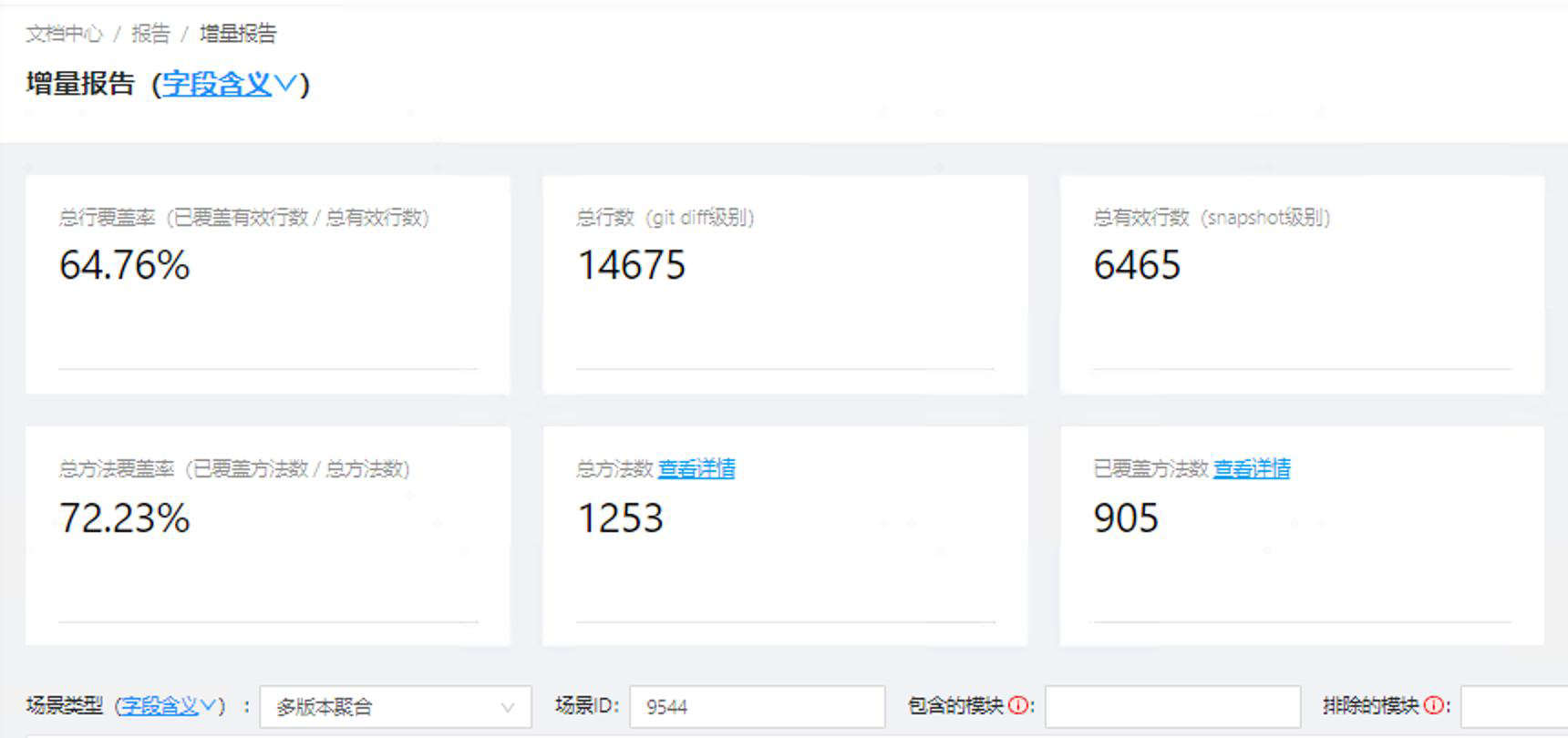
即便将需求拆得更加小,我们的现实状况是,每两次发布之间依旧有动辄万行的增量变更。对于一个外包占比不低的团队,在这种情况下要进一步提速是很困难的:花在理解增量代码上的成本可能比全测一遍还高。在此基础上,业务并没有很强的意愿去做这个事情,尤其是在降本增效的背景下。
1.3 成本与文化
但实际上,我们的指标完成得不错,也确实带来了一些相关度量指标的改善,as usual。他对 “最后一百米” 的解决起到了一定作用,但在以人力为成本。

额外的读码带来的成本是必然的,只不过它是否能被大家看到,不一定。这件事情本身很微妙:
他虽然累但符合所谓的流行趋势,也有一定价值,这使得业务不好意思太抵触;
不抵触,老板自然不会注意到这么微观的问题;
而中台人员自然是更不会关心了,又不用我加班:);
当然,玩笑归玩笑,我们还是希望正视真正的问题,优化真正的成本,而不只是看起来的表象:中台能够不止让老板爽,要让整个团队都爽起来。
第一步当然是搞清楚用户画像与用人成本,这也是中台人员经常忽略的。关注这件事情最初其实是从云成本盘点开始的:当我开始察觉平时跟我打交道的机器们这么贵的时候,我开始注意到工作中跟我们打交道的人也并不便宜。为了评估团队人员结构的健康度,首先需要知道企业真正需要的是什么样的人。
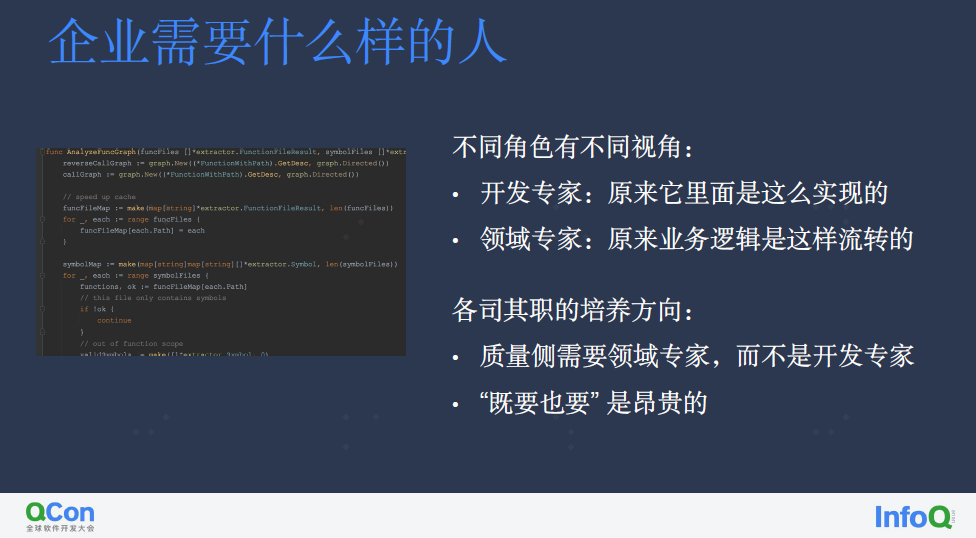
DDD(领域驱动开发)理念中分化出了一个角色:领域专家,他很适合由 QA、项目经理、产品经理来扮演。他强调一个语义上的职责划分:
开发专家关注实现级别的语义
领域专家关注业务级别的语义
通过这种视角:
同一段代码,不同的人会有不同的解读方式,抽取的内容也各不相同
每个人可以只抽取他关注的那部分,而不需要全部
人脑需要解码的信息量变小,心智成本变低
我们也可以从培训体系上配合,打一套组合拳,让团队结构更加合理化:
开发人员
必修能力课程(与工作所需能力相关,例如精通 JAVA 编程、后端架构等)
辅修业务课程(与所在业务领域相关,例如金融则是支付逻辑流转等)
QA 人员
必修业务课程(同上)
辅修能力课程(同上)
值得注意,正如我们对研发人员的两面要求一样,我们也希望 QA 人员能在关注业务逻辑的同时,至少应该看懂 DSL(domain-specific language,下同)级别的代码。所以我们并没有完全放弃对 QA 人员在能力上的培训。
看起来很美好,我们也希望通过这种方式让不同群体能够更加关注、精通属于自己的那部分工作,提升工作效率。

但这本身是个文化布道的问题,涉及文化的事情往往要比技术复杂得多:文化是个抽象的概念,他需要一套大家都能理解的共同语言作为载体来引导,诸如春联与春节,少林寺与中国功夫。一套好的文化需要有载体来建立认知与加深理解。他需要有足够好的可描述与可读性,使得对话双方都能在负载较低的情况下准确地互换信息。代码并不能做到这一点:领域专家需要做一轮解码才能得到领域逻辑,这个过程会有信息损耗。
那么,我们是否能用机器替代这层解码,使得大家通过代码感知到的业务模型都是一致的?
1.4 DSL 与代码快照系统
针对代码,我们可以有如下推论:
代码是编程语言写的
编程语言是语言
语言可以降噪
代码可以降噪

类比到自然语言的对应关系:

而实际上,编译器就是这么 work 的:

那么,我们是否可以,像处理自然语言一样,从冗长的代码中自动抽离出简洁的 DSL 层,作为研发流程中的共同依据?这就是代码快照系统的由来。
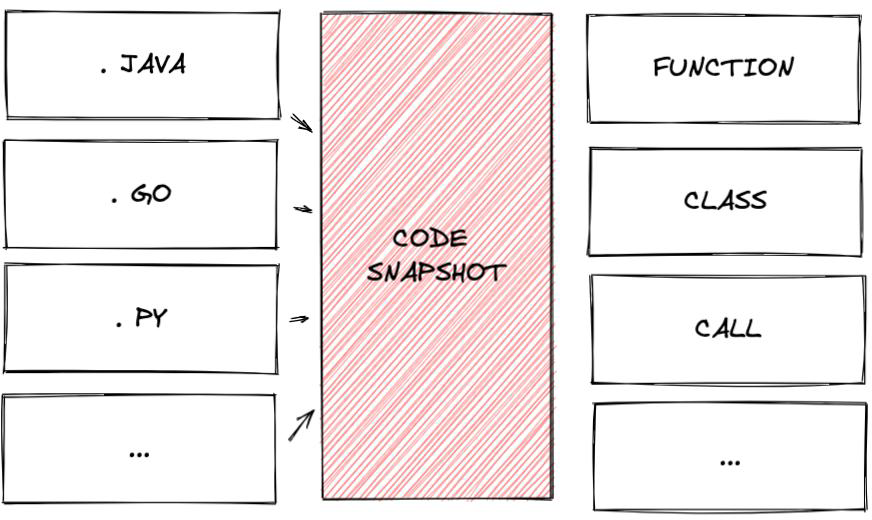
我们通过静态解析,实现了一套多语言统一的、无编译依赖、秒级的代码快照系统。他能够针对不同语言进行不同维度的信息抽取与提炼(例如方法、类、模块等),为 DSL 层提供事实依据。
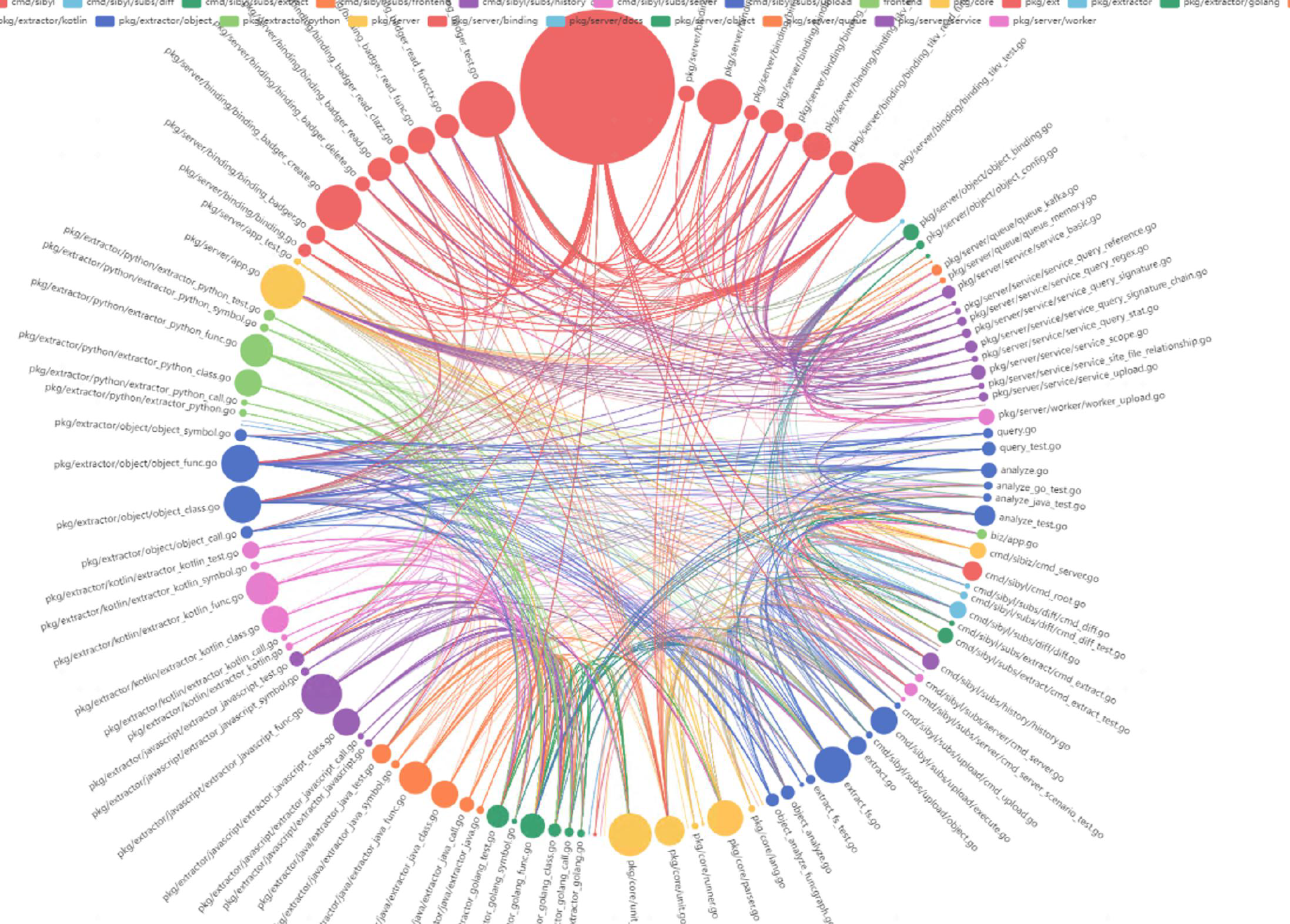
在提交维度上,我们也提供了文件、方法、类等各个维度的上下文推导,组词成句,使得词之间的关系都能够被链接到一起。
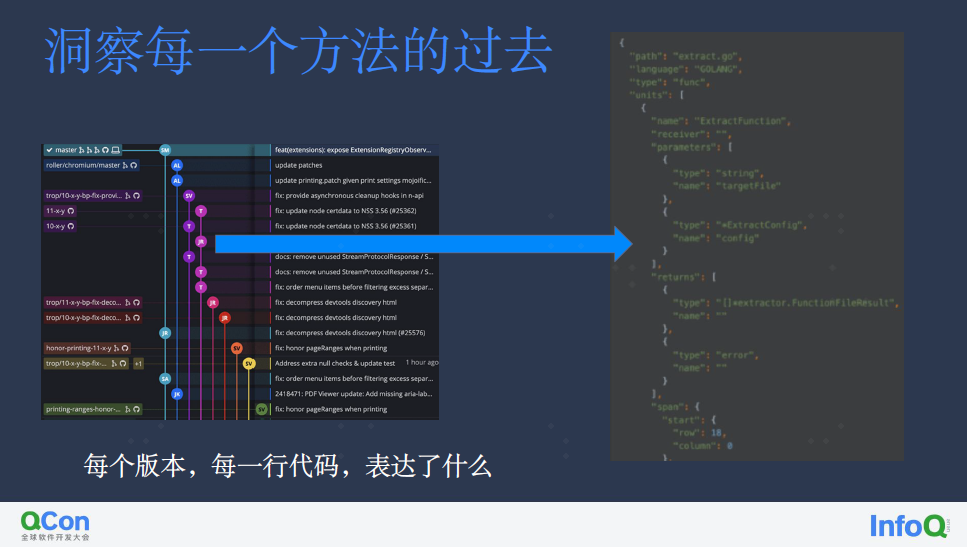
在仓库维度上,依靠高效的处理,我们能够为每一个原生代码仓库同步维持一个对等的快照仓库。结合仓库历史,我们有足够的信息可以知道,在每一个瞬间、每一个文件、每一行代码在逻辑层面上代表着什么,而不再需要(过多的) dive into code。

在体系维度上,我们希望他能提供一个相比原生仓库更加强大的只读层:
逻辑层数据
多语言标准化输出
可控的接入方式
更好的安全性
分担仓库层的计算压力
02 体系
在上一个章节,我们希望通过快照系统作为底层根基,形成研发域内的 DSL。本章节将会展示我们在将其与研发体系绑定之后,一些在此之上孵化的解决方案。
2.1 变更可描述
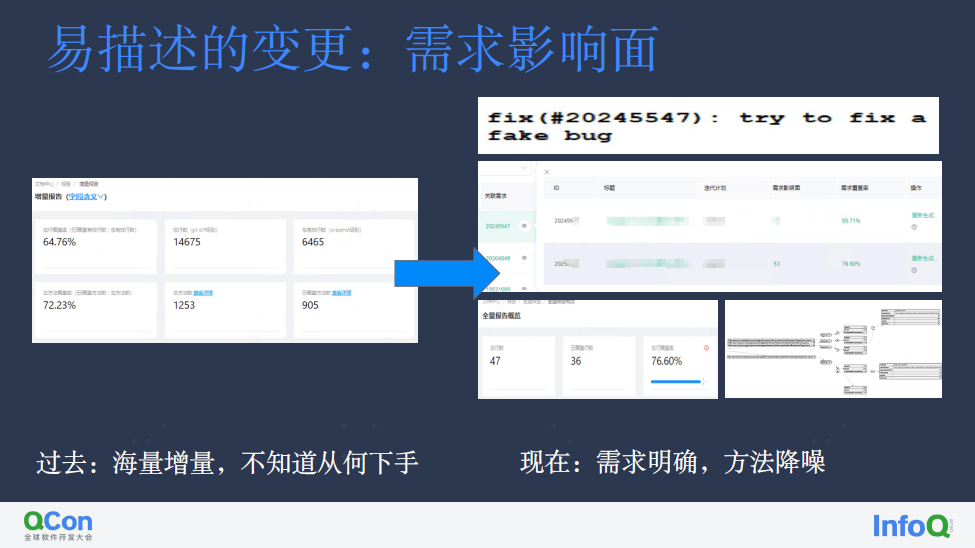
回到刚才我们遇到的增量变更难以描述的问题。
首先做的是结构化拆分,我们通过以下几个维度将迭代引起的变更拆细:
迭代
需求
相关应用
相关提交
相关文件
相关行
相关方法
相关方法上下游
如此做之后,我们可以知悉整个迭代的影响规模,而规模是用规范的 DSL 来描述的,能够被工具、人进行进一步的处理。
其次是范围缩小,万级别代码对应到方法层也会有数以千计的方法量(如果算上上下游则更多),并没有带来本质上的缩减。为此我们开发了冷热方法标记系统,对方法权重进行标记。
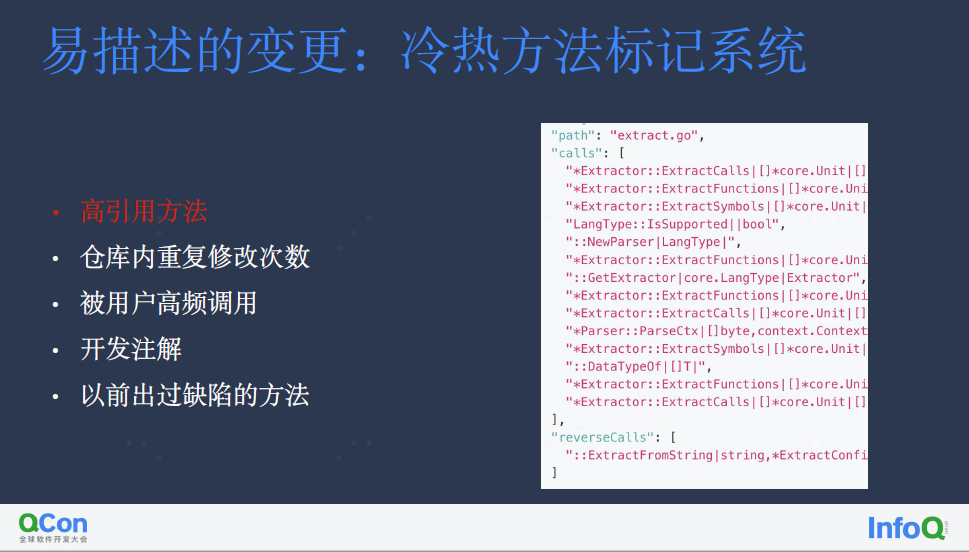
分为五个维度:
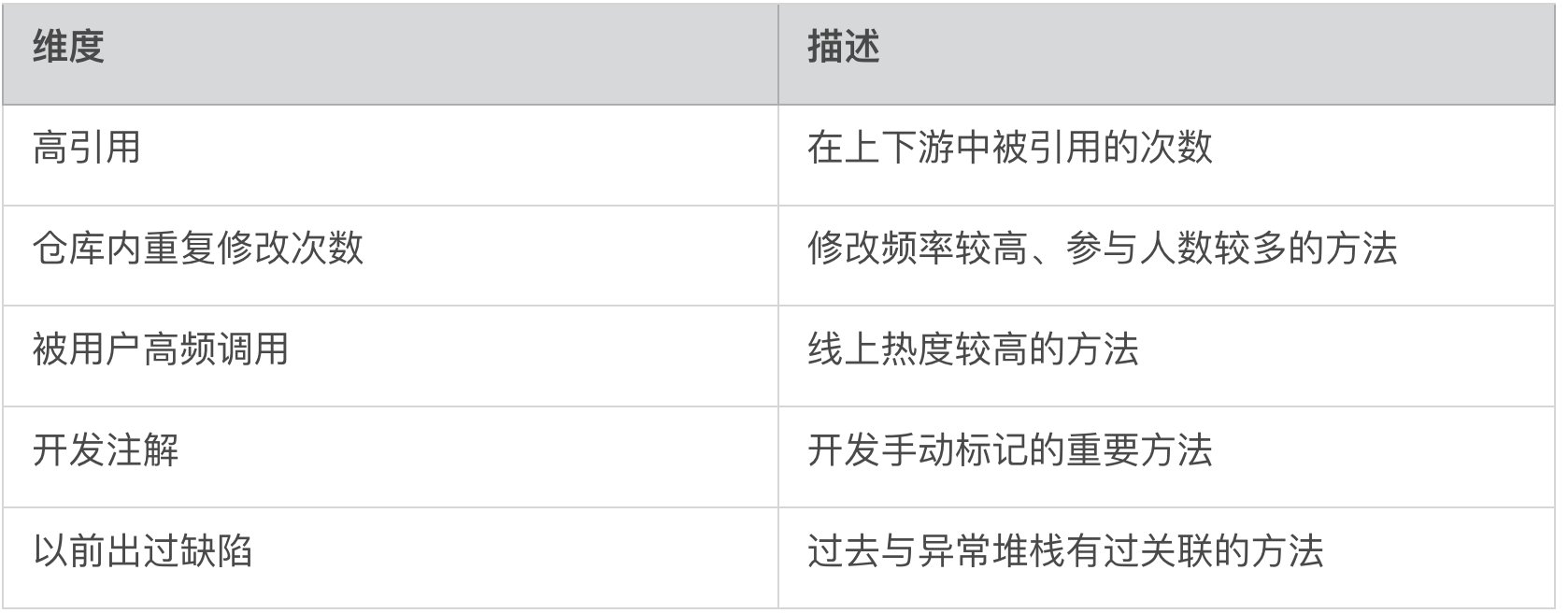
通过加权计算,我们即可为所有方法进行权重分级,提供可视化供快速定位:

最后是覆盖率,既然是 DSL,我们当然希望他是支持双向消息传递的:开发侧信息能被固化为 DSL,那 QA 侧的执行信息也应该能被固化。覆盖率在原生存储结构上与仓库很接近,所以接入也非常方便:

总结来说,对比原有的方案:
多维度划分:不同同学可以关注不同维度的数据;
重要度划分:业务/组织 可以按需决定自己需要关注的层级,范围更小;
染色可视化:剥离了代码层与 DSL 层,领域专家大多数情况下都不需要直接访问代码;
2.2 用例有效性
我们在前面提到了另一个问题,关于自动化用例的有效性不知道如何验证。实际上在质量侧关于用例有效性的讨论已经很多,阻碍我们的主要是开发成本。

前面提到,质量侧的工具没有收到足够的信息做进一步的决策,这迫使工具方只能通过一些诡异的手段(如反编译制品、直接拉原始代码手撸解析等)补齐信息。而随着涉及编程语言种类、对接端增多,工具的兼容成本甚至经常高于功能本身的开发成本。
快照系统的 SDK 优化了工具侧的孵化成本。系统方提供了不同语言的 sdk,工具方可以统一从快照系统中捞取代码元信息,不再需要兼容多种语言,也不再苦恼于如何提取信息。
用例全景看板
自动化用例管理 在大型企业中一直是个比较头疼的问题:
涉及管理平台多且割裂
测试框架多
涉及语言多
同源、非同源情况复杂
…
而在此基础上做一些全局配置与变更则更加痛苦:
想要保证全部用例中都有断言语句
想要查看某个业务名下所有的用例情况
想要查看某个应用的单测做得如何
…
因为用例也是代码,他们自然也会纳入快照管理。所以我们可以很方便地基于仓库维度将所有的用例进行中心化汇总、管理、检查。
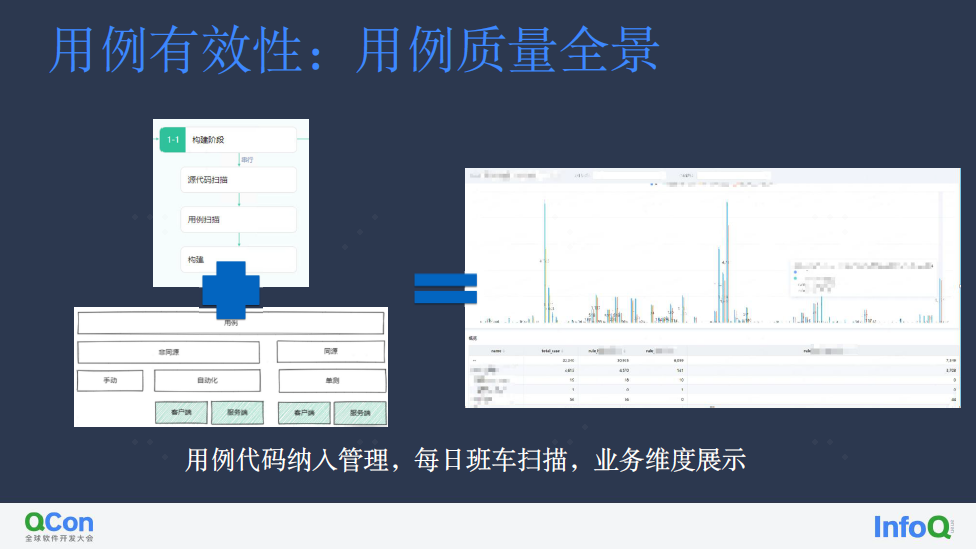
关键方法故障注入
故障注入与发现能力是一项来源于变异测试与混沌工程的实践。他通过给应用注入一些故障,来反向校验用例发现故障的能力。他最大的阻碍有两个:
如何评估注入点
如何制定合理的规则
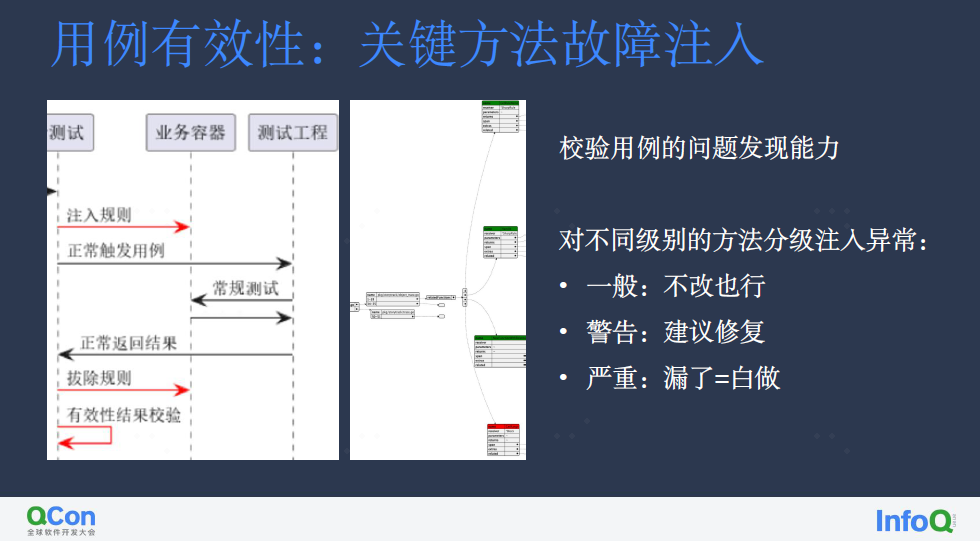
前文说到的冷热方法标记系统,使得我们对于仓库中的每个方法都会有优先级区分。在此基础上,我们设计了三个级别的通用故障规则,只要事先制定好各自规则所关注的方法域,平台可以在无感的情况下自动匹配对应注入点,将预设故障注入业务容器,该容器就可以用于验证用例。
单测辅助生成
与热门的 AI 驱动单测生成不同,我们更希望单测的出入参中带有业务语义,所以我们采用的是真实流量驱动生成的方式。
我们提供了 IDE 插件的形态供业务使用,大部分方法都可以随查随用,简化编写 MOCK、出入参的流程。

而基于快照系统提供的元信息,生成器可以用类似的逻辑处理不同语言,将参数进行反序列化后回填为 DTO,生成不同框架的用例片段,开发人员可以直接复制粘贴使用。
有效性总结
用例有效性一般分为四个领域:
正向:静态扫描(用例全景看板)运行期扫描
反向:变异测试运行时故障注入(关键方法故障注入)
在编写效率上,我们也提供了单测辅助生成插件,用于尽可能缩短新需求自动化测试与研发进度的 GAP。
在用例有效性上的生态孵化是我们一开始没有想到的,其他维度上的建设也正在不断进行中。我们也乐于看到,随着开发门槛因为快照系统的出现而降低,有更多人能够不再被劝退在第一步,愿意参与到效能建设中。
03 效果与展望
从矛盾的维度,前文提到的三大主要矛盾在最后都得到了有效收敛:

从指标的维度,快照系统作为一项偏底层的能力,其相关收益可能较主观而不够准确,仅供参考。

未来我们关注的方向主要有两个,分为能力与生态。
第一个是能力。无论在内部与外部的分享中,我们都会收到一些质疑的声音,这很正常。其中一个很大的点是,调用链这个概念并不新鲜,很多同学不认为它能承担如此大的角色定位。但调用链并不是一个单一概念,他是多元的:

而我们的目标是为海量仓库与海量 commit 建立 DSL,在效率、相关度上都有很高要求,所以在静态层入手更加合适。相对的,快照层的业务关联度最弱,因为实际的代码运行没有发生。
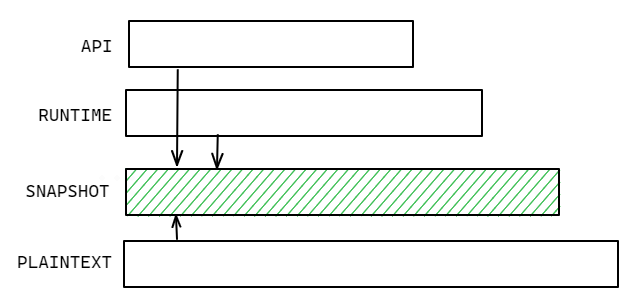
在我们的规划中,他们是逐层叠加的关系。快照层开放了上报接口,支持从其他平台采集到的 RUNTIME 数据的导入,进一步补全 DSL 在业务域信息的不足。
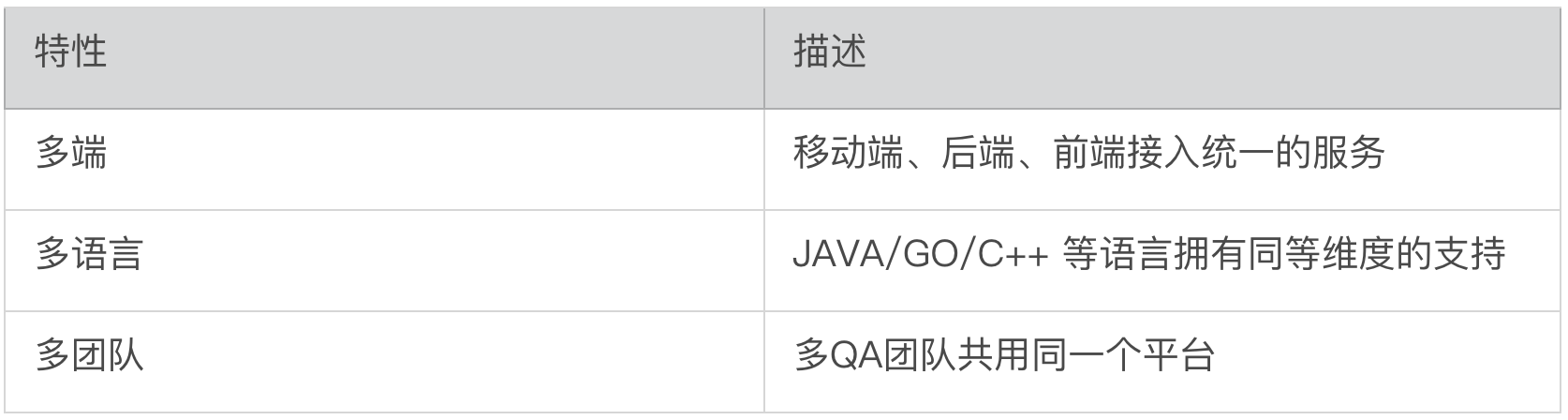
第二个是生态。我们目前开放了多种语言的 sdk,供应用开发者、平台开发者在不同场景下接入使用,简化信息传递成本,与业务携手共建生态,良性生长。
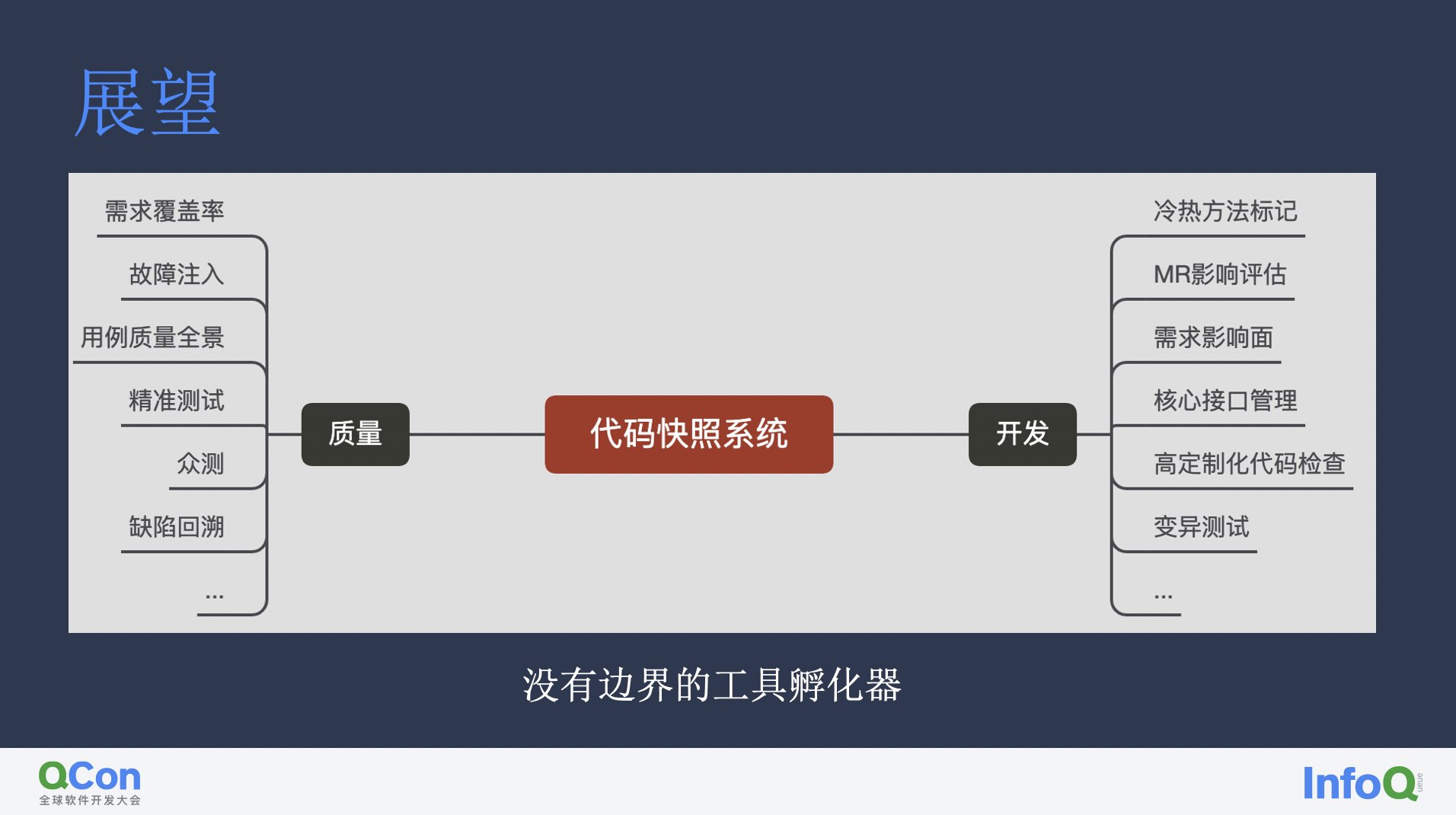
除了提供单独开发的能力,快照也打通了仓库之间的边界,提供了全局逻辑关联的可能性。
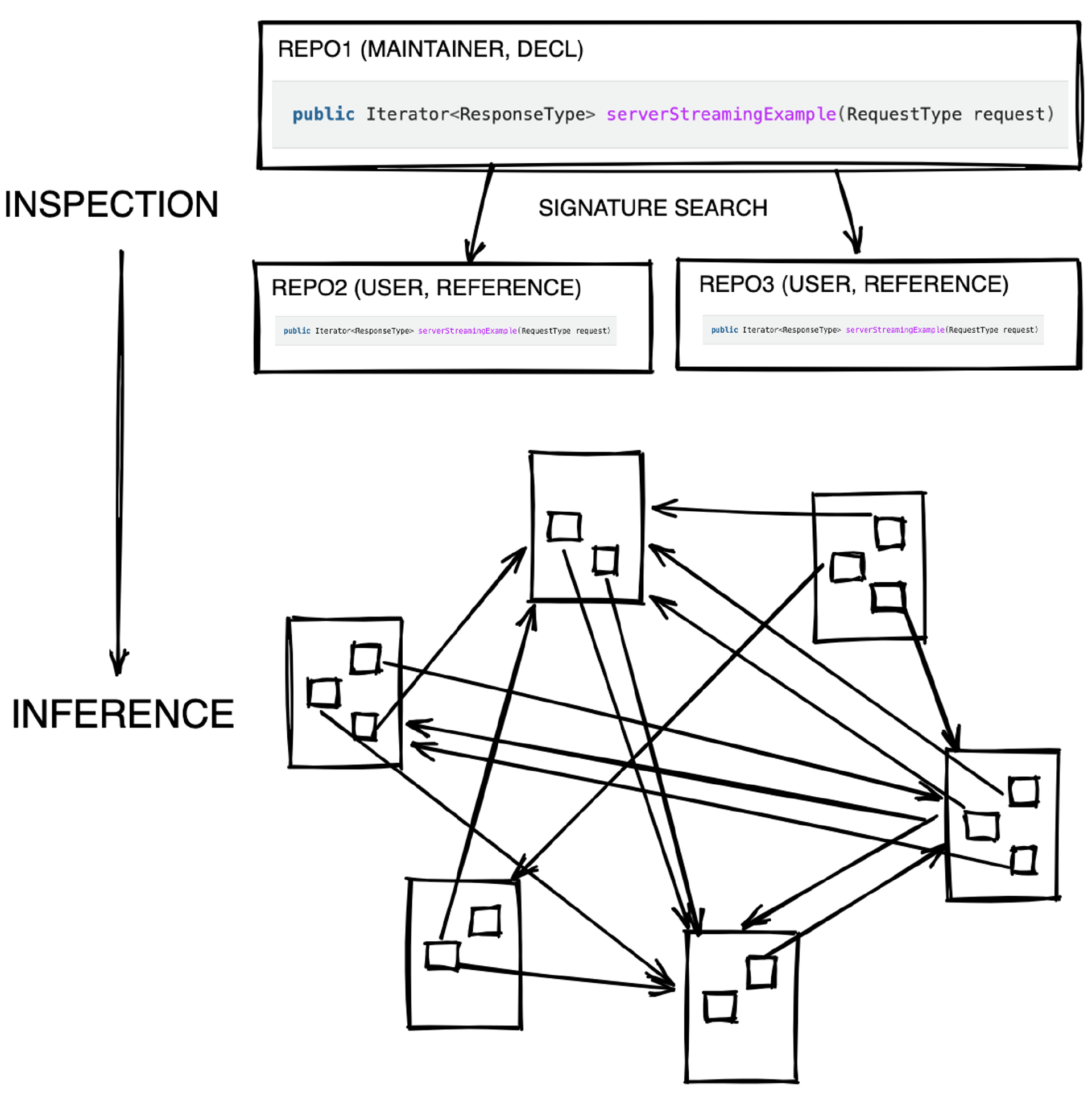
例如跨业务微服务间的接口管理一直是个难题。通常我们会需要利用诸如 IDL 之类的标准化手段来管控接口信息,而这通常滞后且费力,因为规训人往往是最困难的。基于快照,我们可以轻易从不同仓库中抽取符合标准规则的接口 stub 以及 DTO 信息,在业务方无感的情况下形成大型的应用拓扑图。
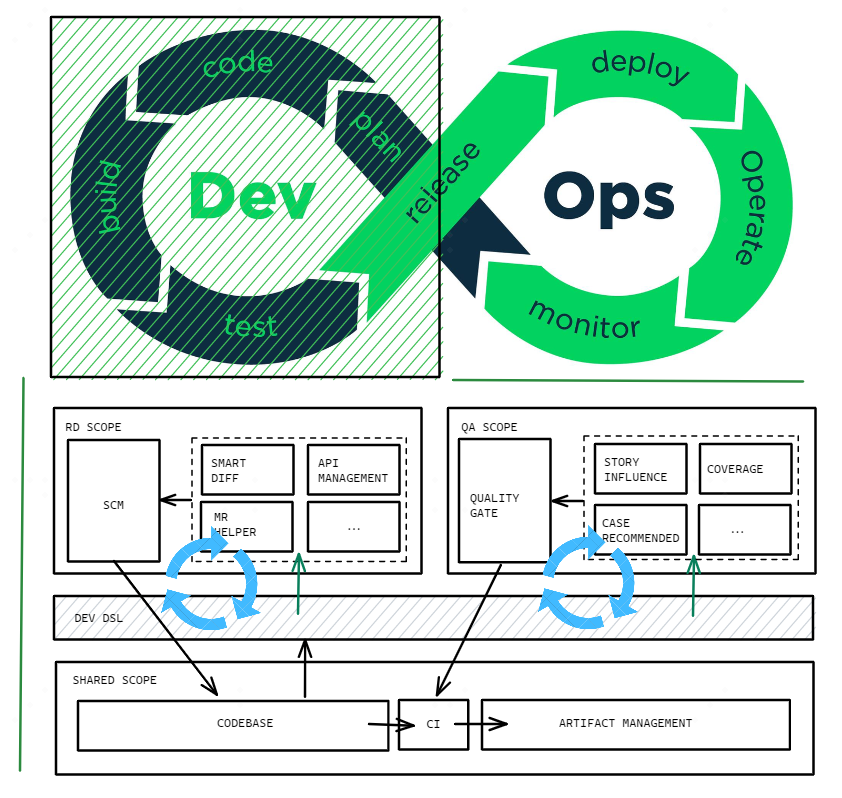
放眼于研发体系,我们希望他能够真正意义上成为贯穿 DevOps 左环的核心组件,构筑 RD 环与 QA 环内高效有序的信息循环。
04 附录
本文是一个传统编译技术在能效领域的应用。在目前的时间点来看,跨界的技术应用是一个不错的新技术产品的孵化方式。就事情本身来说,无论是横向(github)还是垂类(codecov)产品,通过静态代码分析抽取信息进而应用到研发流程,行业也在不断开展新的思考。
感谢前人做出的贡献,感谢开源。
因为内部版本不像 PPT 如此理想化,部分设计与业务系统耦合较深,短期暂无开源计划。感兴趣的同学可以关注下方非官方的开源版本与相关材料:
本文完整演讲幻灯片可至大会官网日程页下载。
作者介绍
冯张弛,OPPO 商业能力中心 工程效能组高级 DevOps 工程师
毕业于中山大学软件工程专业,2018 年加入 OPPO,服务于商业能力中心-互联网测试部-工程效能组,主攻编译流程、基础架构与 DevOps 流程方向的研究。在业务侧到平台侧均有丰富实操经历,视野全面。先后负责过小规模 DevOps 落地、类小程序质量保障、持续性能监控、编译流程改造与插件设计等工作。多年的国外开源项目/社区协作经验,深刻洞察主流研发流程中各个角色的不同需要与痛点。
活动推荐
今年 5 月,QCon全球软件开发大会即将落地广州,从下一代软件架构、研发效能提升、现代编程语言、AIGC、数据驱动业务、金融级分布式数据库、工业互联网、出海的思考、Web3.0 时代的金融系统、大前端架构等角度与你探讨,欢迎你来现场打卡交流~
点击此处直达大会官网,现在购票享 8 折优惠,组团购票还有更多折扣,感兴趣的同学联系票务经理:15600537884(电话同微信)。




