
很多程序员还是一个“小萌新”时就听过这样的说法:写出来的代码必须得“干净”,为此很多人做了大量的阅读和学习。
Redux 作者 Dan Abramov 就曾痴迷于“干净代码”和删除重复代码。多年前他和同事一起开发一个图形编辑器画布,当看到同事提交代码时,他吐槽道,“这些重复代码看起来真的很碍眼。”随后,他自己想办法把重复的代码删掉了。
“夜已深,我把改好的代码提交到 master 分支,然后上床睡觉。因为帮同事把杂乱的代码清理干净了,我心里还引以为豪。”但事实并不像他想象的美好,第二天老板看到后找他谈话,希望他代码回滚回去。
当时的 Dan 很不理解,直到再工作了几年后他才明白,除了团队协作方面考虑,他为了减少重复代码牺牲了灵活性。“这算不上是一个好的权衡。”他坦诚道。
无独有偶,专门从事游戏引擎研发的资深开发者 Casey Muratori 近日也发表文章称,那些所谓“干净”代码的规则“其实挺无所谓的,多数情况下也不太影响代码的实际运行。”
这是 Casey 亲自测试的结果,他表示,“认真分析就会发现,其中很多要求设置得相当随意,难以证实或证伪。但也有一些则非常‘万恶’,确实会影响到代码的运行效果。”我们将 Casey 的测试分享做了翻译,以飨读者。
“干净代码”的性能测试
下面来看几条有代表性的“干净”建议:
• 相较于“if/else”和“switch”,尽量用多态;
• 不要告诉代码它所处理的对象内部;
• 函数应该小一点;函数应该只做一件事;
• “DRY”——别重复自己。
这些要求相当具体,听起来只要照着做了,就让编写出“干净”的代码。但问题是,这样的代码执行起来效果如何?
为了更确切地测试“干净”代码的实际表现,我决定直接用相关文献里列出的示例代码。这样大家就不能说我故意黑了吧,这里只是用人家提供的现成结果来评估“干净”代码到底能不能打。
尽量用多态?
相信很多朋友都见过如下“干净”代码实例:
/* ======================================================================== LISTING 22 ======================================================================== */class shape_base{public: shape_base() {} virtual f32 Area() = 0;}; class square : public shape_base{public: square(f32 SideInit) : Side(SideInit) {} virtual f32 Area() {return Side*Side;} private: f32 Side;}; class rectangle : public shape_base{public: rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {} virtual f32 Area() {return Width*Height;} private: f32 Width, Height;}; class triangle : public shape_base{public: triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {} virtual f32 Area() {return 0.5f*Base*Height;} private: f32 Base, Height;}; class circle : public shape_base{public: circle(f32 RadiusInit) : Radius(RadiusInit) {} virtual f32 Area() {return Pi32*Radius*Radius;} private: f32 Radius;};这是一个基础类,能提供几种特定形状:圆形、三角形、矩形、正方形。之后,它还提供一个用于计算面积的虚拟函数。
跟之前的要求一样,这里用的是多态,函数小而且只做一件事,总之完全符合规定。于是,我们最终得到了非常“干净”的类层次结构。每个派生的类都知道如何计算自己的面积,并存储面积计算所需要的数据。
如果我们想要实际应用这个层次结构,比如想求输入的所有形状的面积总和,那大概应该是这样:
/* ======================================================================== LISTING 23 ======================================================================== */ f32 TotalAreaVTBL(u32 ShapeCount, shape_base **Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += Shapes[ShapeIndex]->Area(); } return Accum;}大家可能注意到了,我在这里没有使用迭代器,因为“干净”规则里并没有建议要使用迭代器。为了避免对编译器的混淆和对性能差异造成的影响,这里我决定不引入任何抽象迭代器。
另外,这个循环还基于一系列指针。这是使用类层次结构所带来的直接结果:我们不知道这些形状在内存里有多大,所以除非添加另外一个虚拟函数调用来获取各形状的数据大小、并引入某种可变的跳过操作,否则就必须要靠指针来找到各个形状的实际起始位置。
这里做的是累加计算,所以会存在循环依赖性,这会导致循环速度下降。为了能随意对累加进行重新排序,我还编写了一个手填版本以确保安全:
/* ======================================================================== LISTING 24 ======================================================================== */ f32 TotalAreaVTBL4(u32 ShapeCount, shape_base **Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; u32 Count = ShapeCount/4; while(Count--) { Accum0 += Shapes[0]->Area(); Accum1 += Shapes[1]->Area(); Accum2 += Shapes[2]->Area(); Accum3 += Shapes[3]->Area(); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}如果只对这两个例程做简单测试,我们就能粗略测量出每个形状完成计算所消耗的 CPU 时钟周期:
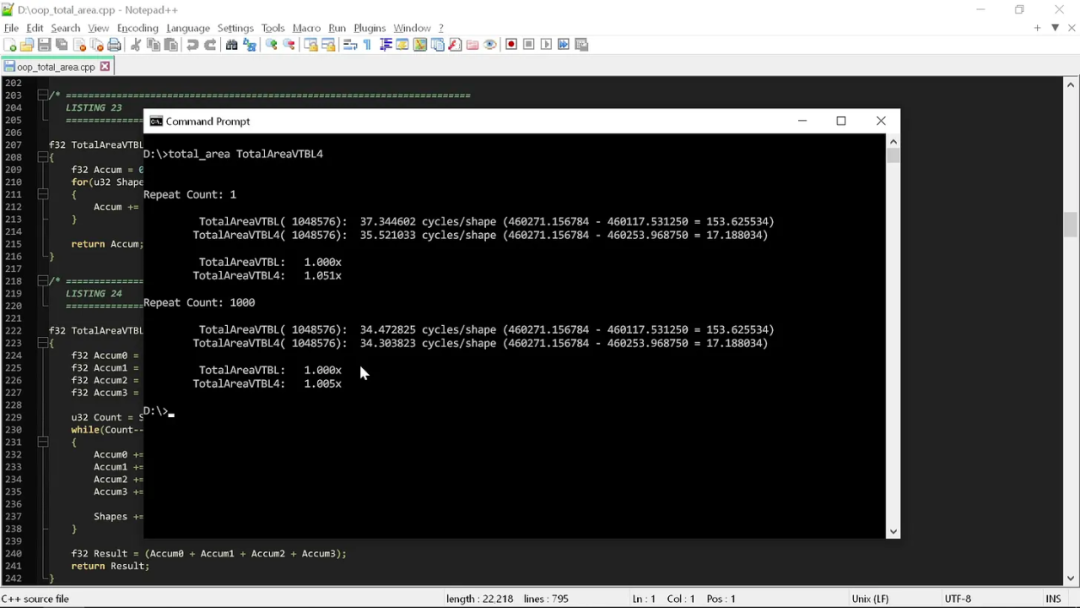
这里用两种不同方式进行代码测试。第一种是仅运行一次,表达“冷”状态下的计算情况——这时数据应存留于 L3 缓存内,但 L2 和 L1 已被刷新清空,而且分支预测变量也尚未在循环中“预演”过。
第二种则是多次运行代码,查看缓存和分支预测变量都“热”着的时候,循环性能如何。请注意,我的这些办法都不是真正的精准测量。大家也能看到,其中的差异如此巨大,压根就没必要使用严肃的分析工具。
从结果来看,这两个例程没有太大区别。“干净”代码在计算形状面积时大概消耗了 35 个计算周期,如果运气好,有时候是 34 个。也就是说,如果严格按照“干净”编程的原则处理,那我们要用掉 35 个计算周期。
可如果不管第一条规矩,结果会怎样?这里我们不使用多态,直接上 switch 语句。
我在这里编写了完全相同的代码,只是不再采取类层次结构的形式(也就是运行时上的 vtable),而是通过枚举和形状类型把所有内容都塞进了单一结构:
/* ======================================================================== LISTING 25 ======================================================================== */ enum shape_type : u32{ Shape_Square, Shape_Rectangle, Shape_Triangle, Shape_Circle, Shape_Count,}; struct shape_union{ shape_type Type; f32 Width; f32 Height;}; f32 GetAreaSwitch(shape_union Shape){ f32 Result = 0.0f; switch(Shape.Type) { case Shape_Square: {Result = Shape.Width*Shape.Width;} break; case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break; case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break; case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break; case Shape_Count: {} break; } return Result;}这就是我们被“干净”代码忽悠之前,那种最老派的编程方式。
请注意,因为这里不再为各种形状变体指定相应的数据类型,所以如果类型不具备所讨论的某个值(例如「高度」),则直接忽略。
现在,这段代码不再从虚拟函数调用中获取面积,而是通过 switch 语句从函数中获取——这跟“干净”编程的原则完全不符。但大家应该看得出来,后面这种更简洁,而且代码并没多大变化。Switch 语句的每种执行情况,都跟类层次结构中的相应虚拟函数有着相同的代码。
至于加和循环本身,跟“干净”版本也几乎相同:
/* ======================================================================== LISTING 26 ======================================================================== */ f32 TotalAreaSwitch(u32 ShapeCount, shape_union *Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += GetAreaSwitch(Shapes[ShapeIndex]); } return Accum;} f32 TotalAreaSwitch4(u32 ShapeCount, shape_union *Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; ShapeCount /= 4; while(ShapeCount--) { Accum0 += GetAreaSwitch(Shapes[0]); Accum1 += GetAreaSwitch(Shapes[1]); Accum2 += GetAreaSwitch(Shapes[2]); Accum3 += GetAreaSwitch(Shapes[3]); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}唯一的区别,就是我们在这里没有调用成员函数来获取面积,而是调用了一个正则函数。就这么点不同。
但很明显,与类层次结构相比,扁平结构是有很多好处的:形状都在矩阵里,根本不需要指针。而且因为所有形状的大小都相同,所以也不需要其他间接转换。
另外,编译器现在可以准确理解我们在循环中的操作,即查看 GetAreaSwitch 函数并查看整个代码路径。这样,编译器就用不着对只向运行时开放的虚拟面积函数做操作猜测。
那这些好处到底会在编译器里转化成怎样的效果?这里我们一口气把运行四种形状,结果是:
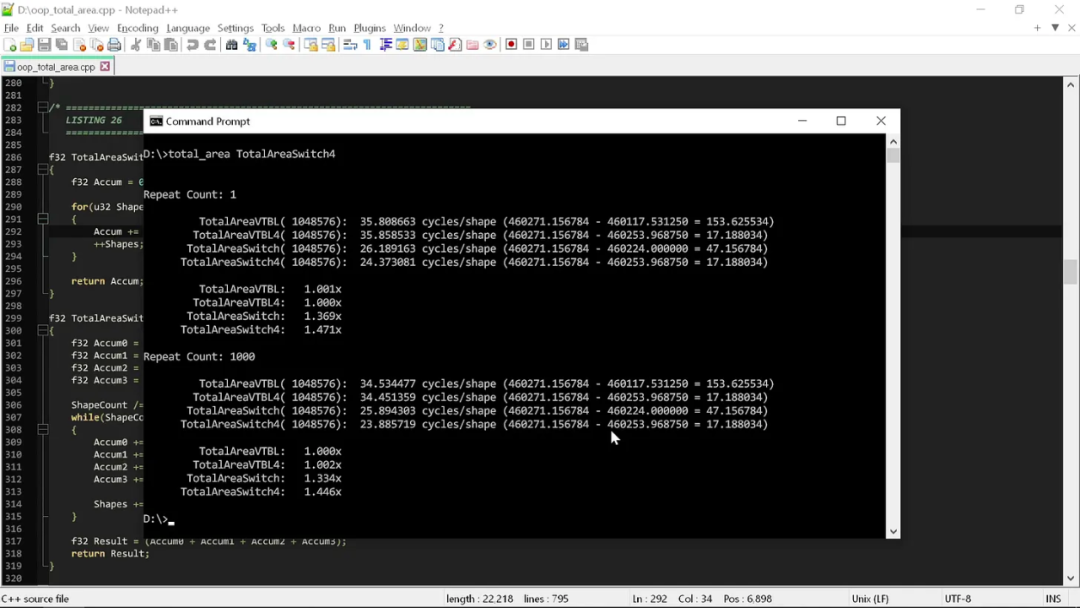
通过观察结果,我们会发现一些很有趣的现象。单单把代码改得“老派”一点,我们就让性能提升了 1.5 倍。是的,别用 C++ 多态这种无关紧要的东西,性能马上就有了改善。
通过违反“干净”代码原则的头一条(也是比较核心的一条),我们把各形状面积计算的时钟周期从 35 个降低到 24 个。如果要拿硬件做比较,就相当于是 iPhone 14 Pro Max 降级成了 iPhone 11 Pro Max。这是三到四年的硬件演化进程,只靠不用多态就给消弭掉了。
但这还只是刚刚开始。
忽略对象内部?
如果我们违反更多规矩,会怎么样?比如说去掉第二条,“忽略对象内部”。我们能不能靠内部知识帮函数提高运行效率?
回顾一下计算面积的 switch 语句,我们会发现所有面积计算用的都是相似的方法:
case Shape_Square: {Result = Shape.Width*Shape.Width;} break; case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break; case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break; case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;也就是都在用高度乘以高度、宽度乘以宽度,需要时再乘个π之类的系数。如果是圆,那就除以 2。
这就是我跟“干净”代码原则最不对付的地方,我觉得 switch 语句很棒!它能向我们清晰地展示这些模式,因为在按操作(而不是按类型)进行代码组织时,可以很直观地发现其中的常规模式。相比之下,再看“干净”编程示例,我们可能永远发现不了这样的模式。那边不仅样板更多,而且倡导者建议把每个类都放进单独的文件里。
所以从结构上讲,我一般不赞成使用类层次结构。总而言之,现在我想强调最重要的一点——我们可以通过观察模式,来大大简化这条 switch 语句。
请记住:这个示例不是我选的。这是“干净”代码自己选的说明示例。而且跟面积计算类似,其他很多任务也有相似的算法结构。要想利用这种模式,我们可以整理一个简单的表,用于说明每种类型所对应的系数。如果我们将圆形和矩形等设定为单参数类型,就可以写出更简单的求面积函数:
/* ======================================================================== LISTING 27 ======================================================================== */ f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};f32 GetAreaUnion(shape_union Shape){ f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height; return Result;}这里的两个求和循环不用做多大修改,除了只能调用 GetAreaUnion(而非 GetAreaSwitch),其余部分完全相同。
下面来看看这个版本的运行性能如何:
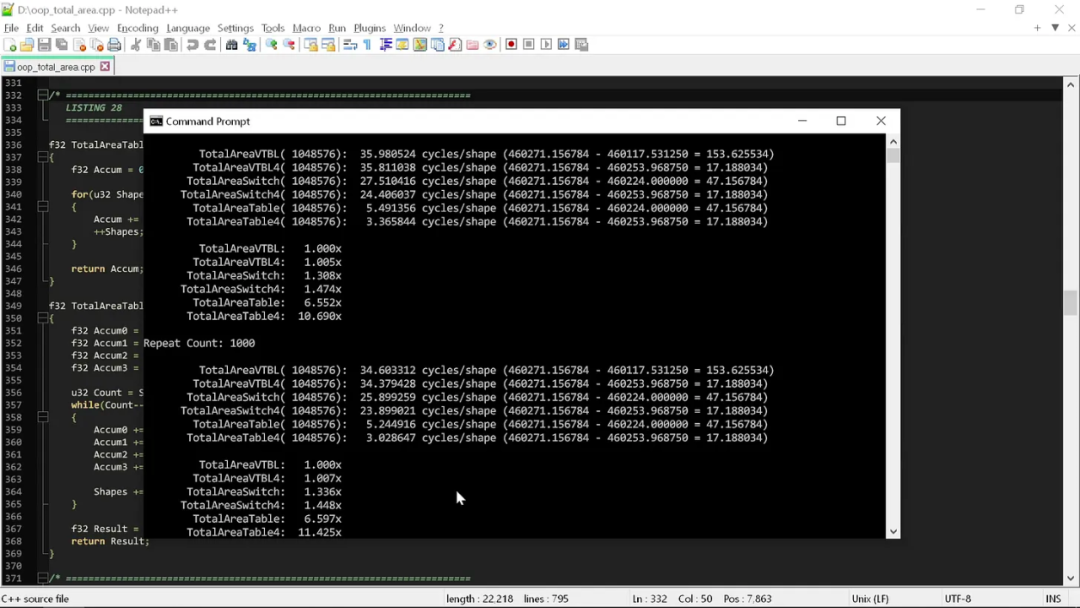
可以看到,通过对实际类型的理解,我们有效将基于类型的思路转换成了基于函数的思路,从而大大提高了速度。跟之前的 iPhone 相比,现在我们的计算速度已经相当于登陆了台式机。
而我们唯一所做的,就是一次表查找加一行代码,没别的了!这样不仅更快,在语义上也更简单。它涉及的 token 更少、操作更少、代码行数也更少。
所以说,我们有必要把数据模型跟计算操作结合起来,而不是要求什么“忽略内部”。现在,我们对每个形状的面积计算只消耗 3.0 到 3.5 个计算周期。
放弃前两条“干净”编程规则,已经让我们的代码性能提升了 10 倍。
10 倍性能提升绝对非同小可,毕竟就连多年之前推出的 iPhone 6(现代性能基准测试所能支持的最老机型),其性能也只是 iPhone 14 Pro Max 的三分之一。
如果用单线程桌面 CPU 性能来比较,那 10 倍的差距就相当于拿现在的 CPU 跟 2010 年的产品对抗。看到了吧,单是前两条“干净”编程规则,就消灭了这 12 年来的硬件演变成果。
函数应该小一点、专一点?
更令人震惊的是,恢复这部分性能的操作如此简单。这里我们没有强调“函数要小”和“函数只做一件事”这两条,毕竟我们这个测试很简单,天然符合这些规定。那么,如果我们在问题里再加个要求,应该就能看到它们的实际影响了吧?
这里,我在原有层次结构之上又添加了一个虚拟函数,用于给出各个形状有几个角:
/* ======================================================================== LISTING 32 ======================================================================== */ class shape_base{public: shape_base() {} virtual f32 Area() = 0; virtual u32 CornerCount() = 0;}; class square : public shape_base{public: square(f32 SideInit) : Side(SideInit) {} virtual f32 Area() {return Side*Side;} virtual u32 CornerCount() {return 4;} private: f32 Side;}; class rectangle : public shape_base{public: rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {} virtual f32 Area() {return Width*Height;} virtual u32 CornerCount() {return 4;} private: f32 Width, Height;}; class triangle : public shape_base{public: triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {} virtual f32 Area() {return 0.5f*Base*Height;} virtual u32 CornerCount() {return 3;} private: f32 Base, Height;}; class circle : public shape_base{public: circle(f32 RadiusInit) : Radius(RadiusInit) {} virtual f32 Area() {return Pi32*Radius*Radius;} virtual u32 CornerCount() {return 0;} private: f32 Radius;};矩形有四个角,三角形有三个角,圆形一个角都没有。之后,我要调整问题的定义,从计算各形状的总面积转为计算各形状的角加权面积和——也就是总面积再加上角总数。
跟总面积一样,算这个角加权面积没有任何实际意义,单纯是为了演示性能差异,用的也是最简单的数学计算。
这里,我用数学计算和其他虚拟函数调用更新了“干净”求和循环:
f32 CornerAreaVTBL(u32 ShapeCount, shape_base **Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += (1.0f / (1.0f + (f32)Shapes[ShapeIndex]->CornerCount())) * Shapes[ShapeIndex]->Area(); } return Accum;} f32 CornerAreaVTBL4(u32 ShapeCount, shape_base **Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; u32 Count = ShapeCount/4; while(Count--) { Accum0 += (1.0f / (1.0f + (f32)Shapes[0]->CornerCount())) * Shapes[0]->Area(); Accum1 += (1.0f / (1.0f + (f32)Shapes[1]->CornerCount())) * Shapes[1]->Area(); Accum2 += (1.0f / (1.0f + (f32)Shapes[2]->CornerCount())) * Shapes[2]->Area(); Accum3 += (1.0f / (1.0f + (f32)Shapes[3]->CornerCount())) * Shapes[3]->Area(); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}基本上就是整体接入另一个函数,添加了新的间接层。同样是出于明确起见,这里不用任何抽象。
在 switch 语句那边,我做的变更也基本相同。先是给角数量添加另一条 switch 语句,跟层次结构版本可以说是完美对应:
/* ======================================================================== LISTING 34 ======================================================================== */ u32 GetCornerCountSwitch(shape_type Type){ u32 Result = 0; switch(Type) { case Shape_Square: {Result = 4;} break; case Shape_Rectangle: {Result = 4;} break; case Shape_Triangle: {Result = 3;} break; case Shape_Circle: {Result = 0;} break; case Shape_Count: {} break; } return Result;}下面看看这两个版本的计算性能差异:
/* ======================================================================== LISTING 35 ======================================================================== */ f32 CornerAreaSwitch(u32 ShapeCount, shape_union *Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[ShapeIndex].Type))) * GetAreaSwitch(Shapes[ShapeIndex]); } return Accum;} f32 CornerAreaSwitch4(u32 ShapeCount, shape_union *Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; ShapeCount /= 4; while(ShapeCount--) { Accum0 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[0].Type))) * GetAreaSwitch(Shapes[0]); Accum1 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[1].Type))) * GetAreaSwitch(Shapes[1]); Accum2 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[2].Type))) * GetAreaSwitch(Shapes[2]); Accum3 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[3].Type))) * GetAreaSwitch(Shapes[3]); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}跟之前的求总面积类似,类层次结构和 switch 两种实现之间的代码基本相同。唯一的区别,就是调用虚拟函数还是使用 switch 语句。
再来看表驱动的示例,这种把计算操作跟数据结合起来办法真的棒。而且这个版本需要修改的只有表里的值。我们甚至不需要获取关于形状的其他信息,只要把角数跟面积系数直接加进表中,就能用几乎相同的代码得出结果:
/* ======================================================================== LISTING 36 ======================================================================== */ f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};f32 GetCornerAreaUnion(shape_union Shape){ f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height; return Result;}如果运行所有“角面积”函数,就能看到第二个形状的属性如何影响其性能:
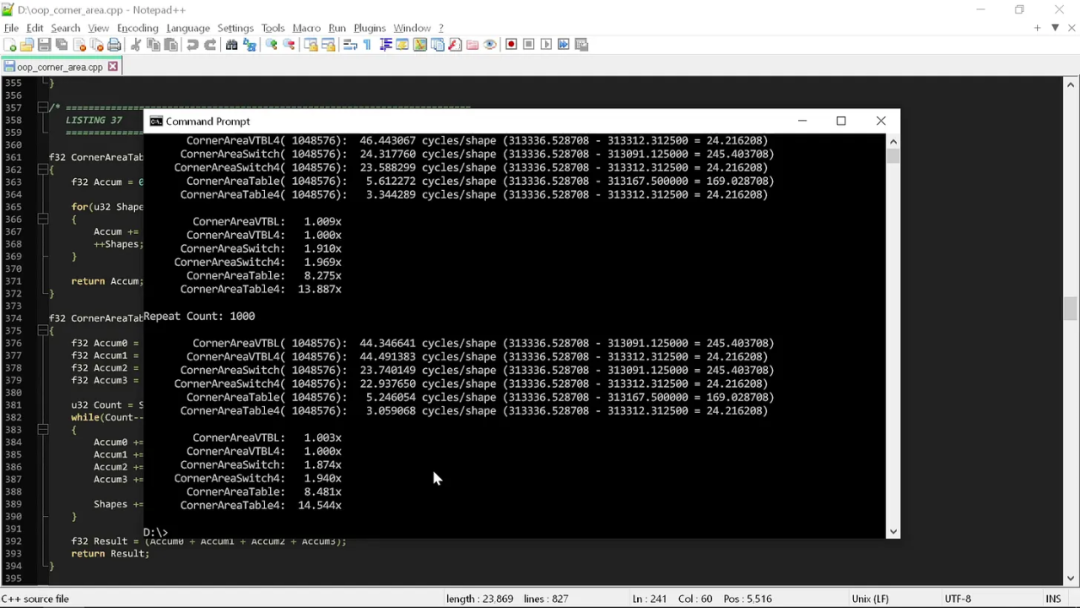
可以看到,这次测试中“干净”代码的表现更差。Switch 语句的性能达到了“干净”版本的 2 倍,而查表版本更是达到后者的 15 倍。
这也凸显出“干净”代码的深层次问题:需求越复杂,这些规矩就越有损性能。当我们把这种“干净”编程方法引入各种真实用例时,最终性能肯定会大打折扣。
而且“干净”代码用得越多,编译器就越理解不了你想干什么。一切都被放进了单独的翻译单元,被藏在虚拟函数调用之后。这样即使编译器再聪明,也难以消化这混乱的实现。
更可怕的是,这样的代码连人看了都会束手无策!从之前的演示中可以看到,如果代码库围绕着函数进行架构设计,那么从表中取值或者删除 switch 语句等需求才会易于实现;而如果是围绕类型进行架构设计,那难度将大大增加。唯一的解决办法,恐怕就只有大规模重写。
总之,只是在形状计算中增加了一个属性,速度差就从 10 倍变成了 15 倍,相当于硬件性能从 2023 年一下子倒退回了 2008 年!一个参数,抹灭 14 年硬件发展,是不是很大胆?而且,咱们还完全没涉及优化呢。
之前的所有演示,都只是在拿循环依赖关系做文章,完全没提有哪些优化空间。下面,我们来看相同计算流程在经过轻度优化后的 AVX 版本:
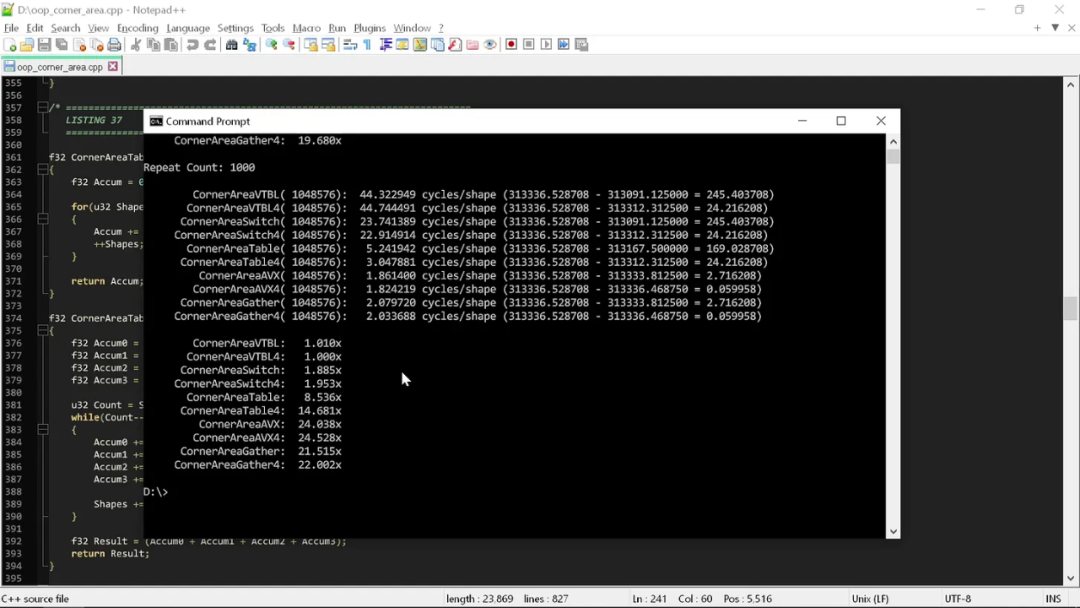
速度差异到了 20 到 25 倍区间。当然,AVX 优化的代码完全不理会“干净”编程的那些奇谈怪论。五大原则已经祛魅了四条,再来看最后一条。
不要重复自己?
老实讲,“不要重复自己”其实是有道理的。我们拿来测试的版本也没有多少重复部分。只有 4 次累加的部分算是重复,但这是为了演示。毕竟如果是在真实应用当中,我们甚至没必要把它分成 2 个例程。
如果把“不要重复自己”说得更具体点,比如不要把相同系数的两个编码版本分别构建成两个表,那我还可以反对一下。毕竟有时候这样能获得更好的性能。但人家没那么讲,只是说别自我重复,那这话还是相当合理的。
最重要的是,我们完全可以在遵循第五条的同时保持合理的代码性能。
结 论
所以我现在给出结论:在这五条原则里,只有最后一条值得遵循,前面四条可以统统无视。为什么?大家可能注意到了,现在的软件运行起来真的越来越慢。跟现代硬件的真实性能相比,软件的运行表现太差了。
要问为什么这么慢,那答案可就多了,而最核心的因素要视实际开发环境和编程方法而定。但至少从特定角度出发,“干净”代码绝对有着不可推卸的责任。虽然其底层逻辑都说得通,但造成的性能负担却是我们难以承受的。
所以面对这种种规矩,尽管有人认为这样能改善代码库的可维护性,但我们至少也该想想背后的代价是什么。
我们真的愿意放弃这十几年的硬件发展,只为让程序员的工作变得更轻松一点吗?我们的职责就是开发出能顺畅在硬件上运行的程序。如果这些原则严重影响了软件的运行效果,那岂不背离了我们的从业初衷?
当然,我们仍然可以继续探索更好的代码组织、维护改进和易读性方法,这些都是非常合理的诉求。但“干净”编程的这些规矩不是,它们根本就不靠谱。我强烈建议他们能用大星号标明“采取这些规则,您的代码性能将缩水十几倍”。
你选择干净的代码还是不错的性能?欢迎在评论区留下你的看法~
原文链接:
https://www.computerenhance.com/p/clean-code-horrible-performance




