
今天是请到阿里的狼叔给大家分享最近他们团队内部开源项目 iMove 基于数据可视化的一些思考。本文详细阐述了 iMove 的可视化编排是如何实现的,以及 iMove 基于 X6+form-render 的思考,整体内容详细且丰富,建议先收藏再看。在今年的 5 月 28-30 日举办的 QCon全球软件开发大会(北京站)上我们也设置了“低代码探索与实践“专题,目前议题征集中,欢迎大家来 QCon 分享。
最近,我们的项目 imove 在 github 上的 star 数增长较快,想必是有值得大家肯定的地方的。设计这款工具的初衷是为了提高开发者的开发效率,通过面向业务逻辑的可视化编排提高逻辑元件(如 ui、 api、 function)的复用能力。我们在双 11 业务中投入使用 imove 进行开发,不仅提高了开发的速度,还积累了许多的逻辑元件,如下图所示:
大家可能会很好奇,我们按照一直习惯的前端开发模式写代码不好吗?根据产品给的需求文档,根据 UI 划分一个个的组件,再一起把 UI 和逻辑实现了不是大功告成吗?为什么要额外引入流程图的绘制,会不会增加工作量?
本文会讲 2 个要点
imove是如何进行开发的,我们为什么要打破以往的开发模式。相比于绘制流程图,
imove更吸引人的是它可以将流程图编译成业务项目中可实际运行的代码。
imove 的可视化编排是如何实现的?
imove 的核心就是基于 x6 协议实现的。
有节点:利用
x6的可视化界面,便于复用和编排。有指向边:即流程可视化,简单直观,边上还可以带参数。
有
function和schema2form,支持函数定义,这是面向开发者的。支持form,让每个函数都可以配置入参,这部分是基于阿里开源的form-render实现的。
整个项目难度不大,基于 x6 和 form-render 进一步整合,将写法规范化,将编排工具化,这样克制的设计使得 imove 具备小而美的特点,便于开发使用。
基于 imove 的开发方式
绘制完流程图
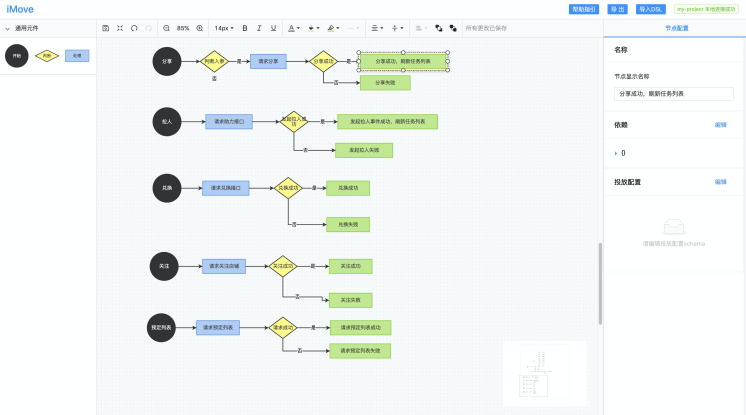
根据你的业务逻辑绘制好流程图,这里的节点包括开始节点(圆形)、分支节点(菱形)和行为节点(矩形)。如下图所示,可以绘制多条执行链,每条执行链都从一个开始节点出发。
完成每个节点的函数编写
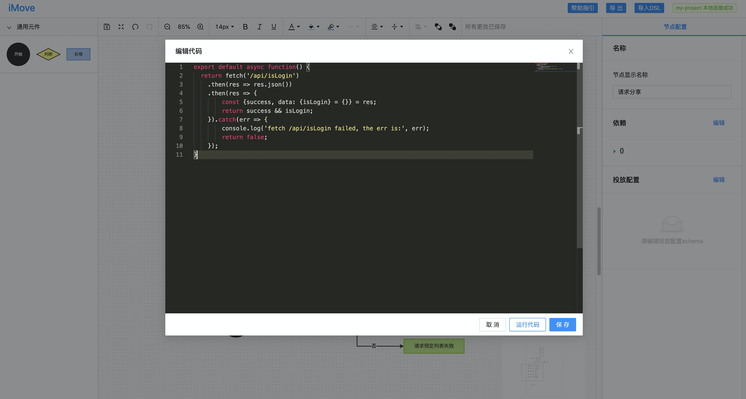
依次双击节点,打开代码编辑框,为每个节点编写代码。
前端 js 代码实现包含了同步逻辑和异步逻辑,大多数可以使用同步逻辑实现,但是涉及到接口请求、定时任务等场景时就需要使用到异步逻辑。因此,在 imove 中我们支持书写同步代码和异步代码,并在编译中考虑了这两种情况。具体写法如下所示。
// 同步代码export default function(ctx) { const data = ctx.getPipe(); return doSomething(data);}// 异步代码// 写法1 使用promiseexport default function(ctx) { return new Promise(resolve => { setTimeout(() => resolve(), 2000); });}// 写法2 使用async awaitexport default async function(ctx) { const data = await fetchData(); return data;}在项目中使用
以上步骤只涉及到绘制流程图、编写节点代码,但是我们需要把这些 js 逻辑代码加入到自己的项目中,才能实现一个完整的项目。为了方便把这些编写的 js 逻辑加入到项目中,我们可以选择以下两种方式引入:1)将 imove 编写的代码在线打包,将打包文件引入到项目中;2)直接在本地启动开发模式 imove -d,可以结合项目进行实时调试,边在 imove 修改边看项目效果。以下介绍两种引入方式的具体步骤:
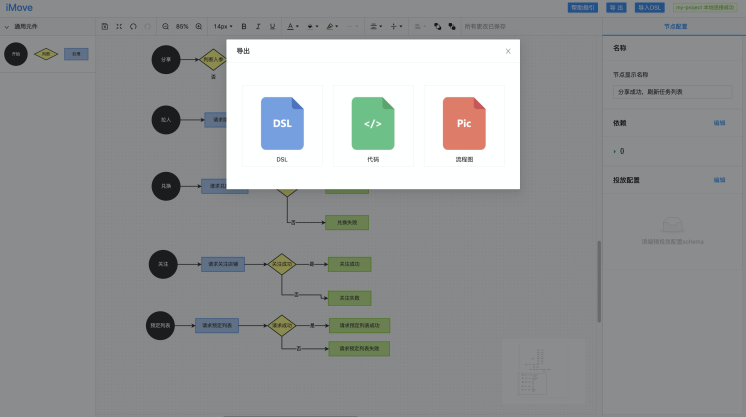
(1)本地打包出码
点击页面右上方的"导出"按钮后,可以在弹窗内选择“导出代码”,此时流程图编译后的代码将以zip包的形式下载到本地,你可以解压后再引入项目中使用。
引入后使用方法如下:
通过
logic.on方法监听事件,事件名和参数与流程图中节点代码的 ctx.emit 相对应通过
logic.invoke方法调用逻辑,事件名与流程图中的开始节点的 逻辑触发名称 相对应,否则会调用失败
import React, {useEffect} from 'react';import logic from './logic';const App = () => { // 引入方法 useEffect(() => { // 事件监听——在节点代码中,通过`ctx.emit('a')`执行a事件,以下是监听此事件的函数 logic.on('a', (data) => { }); // 执行一条流程——触发执行“开始节点”逻辑触发名称为b的那条流程 logic.invoke('b'); }, []); return <div>xxx</div>};export default App;2)本地启动开发模式
安装
@imove/cli
$ npm install -g @imove/cli进入项目根目录,
imove初始化
$ cd yourProject $ imove --init # 或 imove -i本地启动开发模式
$ imove --dev # 或 imove -d本地启动成功之后,可以看到原来的页面右上角会显示连接成功。
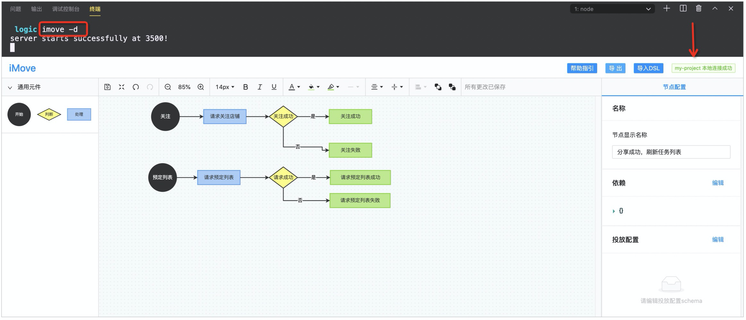
此时页面上触发“保存快捷键 Ctrl + S”时,就可以看到当前项目的 src 目录下会多出一个 logic 目录,这就是 imove 编译生成的代码,此时你只要在你的组件中调用它即可。调用的方法仍然如本地打包出码中演示的一致。
为什么需要使用流程编排
了解了基于 imove 的开发方式,接下来具体讨论一下为什么需要这么做。试想一下,你有没有遇到过以下场景:
UI经常发生变化,但是我想复用以往实现过的逻辑,却不知道代码在哪里,又要重新写一遍产品的需求文档都是文字,我们只好在脑中构思逻辑,边写边想还容易遗漏逻辑,只好写完了代码反复检查
以前做的项目很久没做了,但是最近我想改,但是项目对我来说如此陌生,不知道代码是什么意思,无法快速入手
我要接手一个老项目,但是里面的代码逻辑很复杂,又没有什么注释,不知道如何是好
我是个新人,在做新业务时可能有很多不太清楚的实现逻辑,如关注店铺、判断登录、发送埋点……,没有什么文档参考,师兄又太忙,问起来很花时间
实现某个逻辑 a 时,想参考下以前别人实现的代码,但是大串大串的业务逻辑耦合在一起,不知道哪一部分才是逻辑 a,于是开始自己钻研……
以上这些种种问题,其实是前端开发中或多或少会遇到的痛点。其实,我们可以采用逻辑编排的开发方式,把业务中的一个个功能点按照逻辑顺序组织起来,不仅能够及时检查逻辑漏洞,还能沉淀非常多的业务逻辑,达到参考和复用的效果。以下是总结的采用可视化编排方式进行编程的好处:
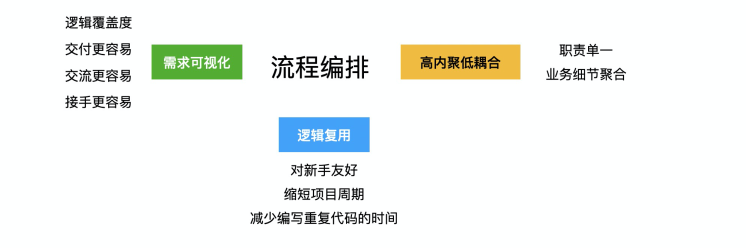
(1)需求可视化
把需求按照流程图的方式展示出来,可视化的流程对于新人以及非开发同学来说是非常容易理解的,对了解业务有很大的帮助。特别是在判别条件非常多、业务身份非常多、业务流程冗长而复杂的场景中,能梳理好全部的需求逻辑,能更好地检查代码是否考虑了全部的需求场景。这使得交付、交流、接手会更容易。
(2)逻辑复用
因为代码是针对于节点粒度的,在做需求时,可以参考和复用已有的节点代码(如判断登录、关注店铺等等),不仅对新人上手非常友好,也节约了反复编写重复代码的时间,能缩短开发周期。随着逻辑节点的不断沉淀,这种优势也会越发明显。
(3)提高代码规范
在现有的开发方式下,随着需求不断迭代,可能有会有越来越多的业务逻辑被分散在各个模块中,很可能会违反职责单一、高内聚低耦合的编程原则。而通过逻辑编排的方式开发,每次只针对一个节点编写代码,能保证各个能力职责单一,最后通过聚合的方式串联起整个业务逻辑。
现在思考一下,使用到逻辑编排后,上述列举出的种种问题,是不是会迎刃而解呢?
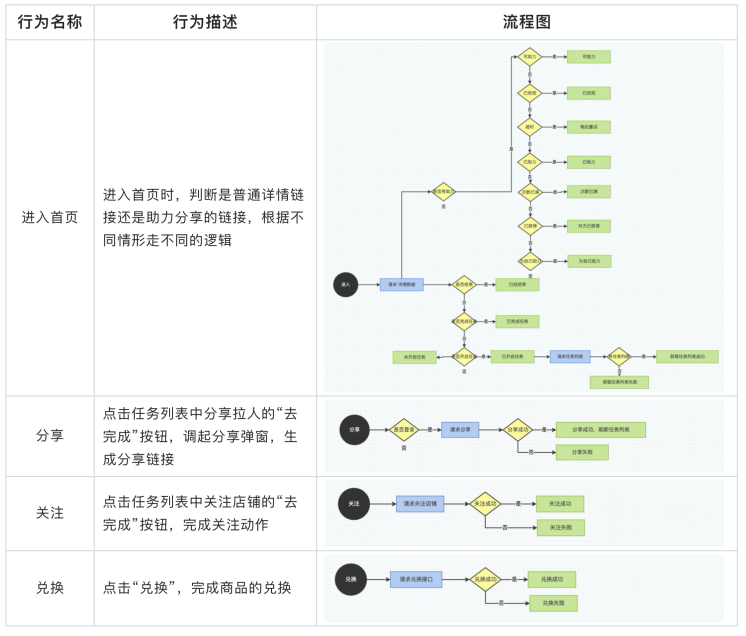
其实逻辑编排不是一种新出现的思想,其实像我们生活中,都有逻辑编排的影子。它只是按照行为逻辑,把一个个单一的业务行为(如限流、限购、加购等等)有序编织为一个完整流程,聚合成一条具有特定业务含义的执行链,每一个完整的流程都会有一个触发点。如下图,就是在业务场景中整理的流程图:
因此,在 coding 中引入逻辑编排的概念是有价值的,我们也正在尝试着使用新的开发模式去提高生产效率。
基于 x6 的流程编排
在上文中详细展示了为什么需要使用到流程编排,下面详细介绍下流程图绘制的原理。 imove 底层采用了蚂蚁团队提供的 antv-X6 图编辑引擎 ,从而实现了流程图绘制的能力。
为什么要选用 antv-x6 作为底层绘图引擎呢?因为它基本能覆盖到流程图绘制的全部需求,内置了图编辑场景的常规交互和设计,能帮助我们快速创建画布、节点和边,能够做到开箱即用,使用是非常方便的。它开放了丰富的定制能力给到开发者,只需简单的配置就能实现想要的效果,其不仅仅支持流程图,还支持 DAG 图、 ER 图、组织架构图等等。在 imove 中我们仅仅使用到了流程图绘制的能力,其实 x6 还有更多的能力值得大家去使用去探索。下面结合 imove 框架的实现,详细介绍下我们实现流程图绘制的具体思路,如何从 0 到 1 实现可用的较为完备的流程图绘制能力。
画布设计
使用 x6 创建画布非常容易,实例化一个 x6 暴露的 Graph 对象即可。以下是画布的具体配置项,包括了一下特性。
节点是否可旋转
节点是否可调整大小
跨画布的复制/剪切/粘贴
节点连线规则配置
画布背景配置(支持颜色/图片/水印等)
网格配置
点选/框选配置
对齐线配置
键盘快捷键配置
撤销/重做能力
画布滚动、平移、居中、缩放等能力
鼠标滚轮缩放配置
……
具体的代码实现如下,注释了各类能力对应的 API 文档,大家有兴趣可以试试~
import {Graph} from '@antv/X6';const flowChart = new Graph({ // 渲染指定 dom 节点 container: document.getElementById('flowChart'), // 节点是否可旋转 rotating: false, // 节点是否可调整大小 resizing: true, // 剪切板,支持跨画布的复制/粘贴(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/clipboard) clipboard: { enabled: true, useLocalStorage: true, }, // 节点连线规则配置(详细文档:https://X6.antv.vision/zh/docs/api/graph/interaction#connecting) connecting: { snap: true, dangling: true, highlight: true, anchor: 'center', connectionPoint: 'anchor', router: { name: 'manhattan' } }, // 画布背景,支持颜色/图片/水印等(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/background) background: { color: '#f8f9fa', }, // 网格配置(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/grid) grid: { visible: true, }, // 点选/框选配置(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/selection) selecting: { enabled: true, multiple: true, rubberband: true, movable: true, strict: true, showNodeSelectionBox: true }, // 对齐线配置,辅助移动节点排版(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/snapline) snapline: { enabled: true, clean: 100, }, // 撤销/重做能力(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/history) history: { enabled: true, }, // 使画布具备滚动、平移、居中、缩放等能力(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/scroller) scroller: { enabled: true, }, // 鼠标滚轮缩放(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/mousewheel) mousewheel: { enabled: true, minScale: MIN_ZOOM, maxScale: MAX_ZOOM, modifiers: ['ctrl', 'meta'], },});完成了画布的开发,接下来在主界面中引入即可。这里我们发现还是存在很多问题:
无法使用键盘快捷键怎么办,比如复制粘贴保存撤销?
想监听一些画布方法怎么办,例如双击节点直接打开编辑框、右键节点打开菜单、右键画布打开另一个菜单?
想实现小地图怎么办?
想把画布信息导出并储存怎么办?
……
仅仅依赖于以上 new Graph 配置的信息是远远不够的,还需要一步步完善起来。
快捷键设置
根据 键盘快捷键 Keyboard 介绍,Graph 实例会暴露一个 bindKey 方法,我们可以用它来绑定快捷键。以使用频率最高的 ctrl + c / ctrl + v 举例,这里定义了一系列的键盘快捷键和 handler 监听函数,如 ctrl + c时获取当前选中的元素,利用 copy() 方法完成复制操作,ctrl + v 时直接使用 paste({offset:xx}) 方法完成粘贴操作。
首选需要在 new Graph 的参数中加入 keyboard 配置项,这里的 global 代表是否为全局键盘事件,设置为 true 时绑定在 Document 上,否则绑定在画布容器上。在这里我们设置为 false,只在画布获得焦点才触发键盘事件。
const flowChart = new Graph({ // 键盘快捷键能力(详细文档:https://X6.antv.vision/zh/docs/tutorial/basic/keyboard) keyboard: { enabled: true, global: false, }});接下来要配置支持的快捷键,如复制、粘贴、保存、撤销、缩放、全选……需要指定对应的按键以及监听函数。感兴趣的朋友可以看下shortcuts.ts。
import { Cell, Edge, Graph, Node } from '@antv/X6';interface Shortcut { keys: string | string[]; handler: (flowChart: Graph) => void;}const shortcuts: { [key: string]: Shortcut } = { // 复制 copy: { keys: 'meta + c', handler(flowChart: Graph) { const cells = flowChart.getSelectedCells(); if (cells.length > 0) { flowChart.copy(cells); message.success('复制成功'); } return false; }, }, // 粘贴 paste: { keys: 'meta + v', handler(flowChart: Graph) { if (!flowChart.isClipboardEmpty()) { const cells = flowChart.paste({ offset: 32 }); flowChart.cleanSelection(); flowChart.select(cells); } return false; }, }, // many funcions can be defined here save: {}, // 保存 undo: {}, // 撤销 redo: {}, // 重做 zoomIn: {}, // 放大 zoomOut: {}, // 缩小 delete: {}, // 删除 selectAll: {}, // 全选 bold: {}, // 加粗 italic: {}, // 斜体 underline: {}, // 下划线 bringToTop: {}, // 置于顶层 bringToBack: {} // 置于底层};export default shortcuts;我们也可以实现快捷键或滚轮放大、缩小的能力,需要自定义每次缩放尺度的改变量,根据当前的缩放尺度去增减这个改变量即可。为了避免用户无限放大或无限缩小带来不好的视觉体验,最好定义一个最大和最小的缩放尺度。
const shortcuts: { [key: string]: Shortcut } = { zoomIn: { keys: 'meta + shift + +', handler(flowChart: Graph) { const nextZoom = (flowChart.zoom() + ZOOM_STEP).toPrecision(2); flowChart.zoomTo(Number(nextZoom), { maxScale: MAX_ZOOM }); return false; }, }, zoomOut: { keys: 'meta + shift + -', handler(flowChart: Graph) { const nextZoom = (flowChart.zoom() - ZOOM_STEP).toPrecision(2); flowChart.zoomTo(Number(nextZoom), { minScale: MIN_ZOOM }); return false; }, }}最后我们把所有的快捷键绑定在 Graph 上,即可完成全部快捷点的配置。
shortcuts.forEach(shortcur => { const { key, handler } = shortcut; graph.bindKey(key, () => handler(graph));});画布方法注册
在当前画布上,我们需要监听一系列常用的方法,如双击节点、画布右键、节点右键等等。在 imove 中,完成了以下的操作:
双击节点打开代码编辑框,想提高交互体验
右键节点打开菜单栏,支持节点复制、删除、编辑文本、置于顶层/底层、编辑代码、执行代码
右键画布打开菜单栏,支持全选和粘贴
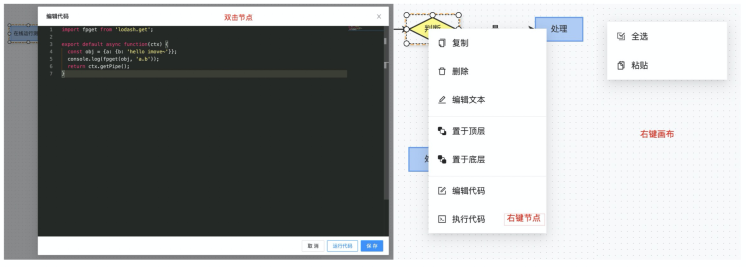
以下是具体的实现方法:
const registerEvents = (flowChart: Graph): void => { // 监听节点双击事件,用于打开代码编辑界面 flowChart.on('node:dblclick', () => { }); // 监听画布右键菜单 flowChart.on('blank:contextmenu', (args) => { }); // 监听节点右键菜单 flowChart.on('node:contextmenu', (args) => { });};创建画布实例
目前已经完成了画布通用配置、快捷键设置、事件绑定,接下来实现一个 createFlowChart 的工厂函数。在工厂函数中,我们创建了画布实例,并为其注册绑定的事件、注册快捷键、注册服务端存储。
// 注册快捷键const registerShortcuts = (flowChart: Graph): void => { Object.values(shortcuts).forEach((shortcut) => { const { keys, handler } = shortcut; flowChart.bindKey(keys, () => handler(flowChart)); });};const createFlowChart = (container: HTMLDivElement, miniMapContainer: HTMLDivElement): Graph => { const flowChart = new Graph({ // many configuration }) registerEvents(flowChart); // 注册绑定事件 registerShortcuts(flowChart); // 注册快捷键 registerServerStorage(flowChart); // 注册服务端存储 return flowChart;};export default createFlowChart;这样,画布的功能越来越完善了,已经支持绘制流程图了。
导出模型
在 imove 中,需要支持绘制的流程图以 DSL 、代码、流程图的导出,这样在真实业务开发中,就可以最大程度的复用节点和流程。为了实现这个功能,我们实现的相关函数如下。
// 导出DSLconst onExportDSL = () => { const dsl = JSON.stringify(flowChart.toJSON(), null, 2); const blob = new Blob([dsl], { type: 'text/plain' }); DataUri.downloadBlob(blob, 'imove.dsl.json');};// 导出代码const onExportCode = () => { const zip = new JSZip(); const dsl = flowChart.toJSON(); const output = compileForProject(dsl); Helper.recursiveZip(zip, output); zip.generateAsync({ type: 'blob' }).then((blob) => { DataUri.downloadBlob(blob, 'logic.zip'); });};// 导出流程图const onExportFlowChart = () => { flowChart.toPNG((dataUri: string) => { DataUri.downloadDataUri(dataUri, 'flowChart.png'); }, { padding: 50, ratio: '3.0' });};节点设计
在 imove 中,我们设计了以下三种节点类型:事件节点(开始节点)、行为节点、分支节点。节点负责处理具体的逻辑流程,以下是三种节点的具体描述:
开始节点:逻辑起始,是所有流程的开始,可以是一次生命周期初始化/一次点击
行为节点:逻辑执行,可以是一次网络请求/一次改变状态/发送埋点等
分支节点:逻辑路由,根据不同的逻辑执行结果跳转到不同的节点(注:一条逻辑流程必须以开始节点为起始)
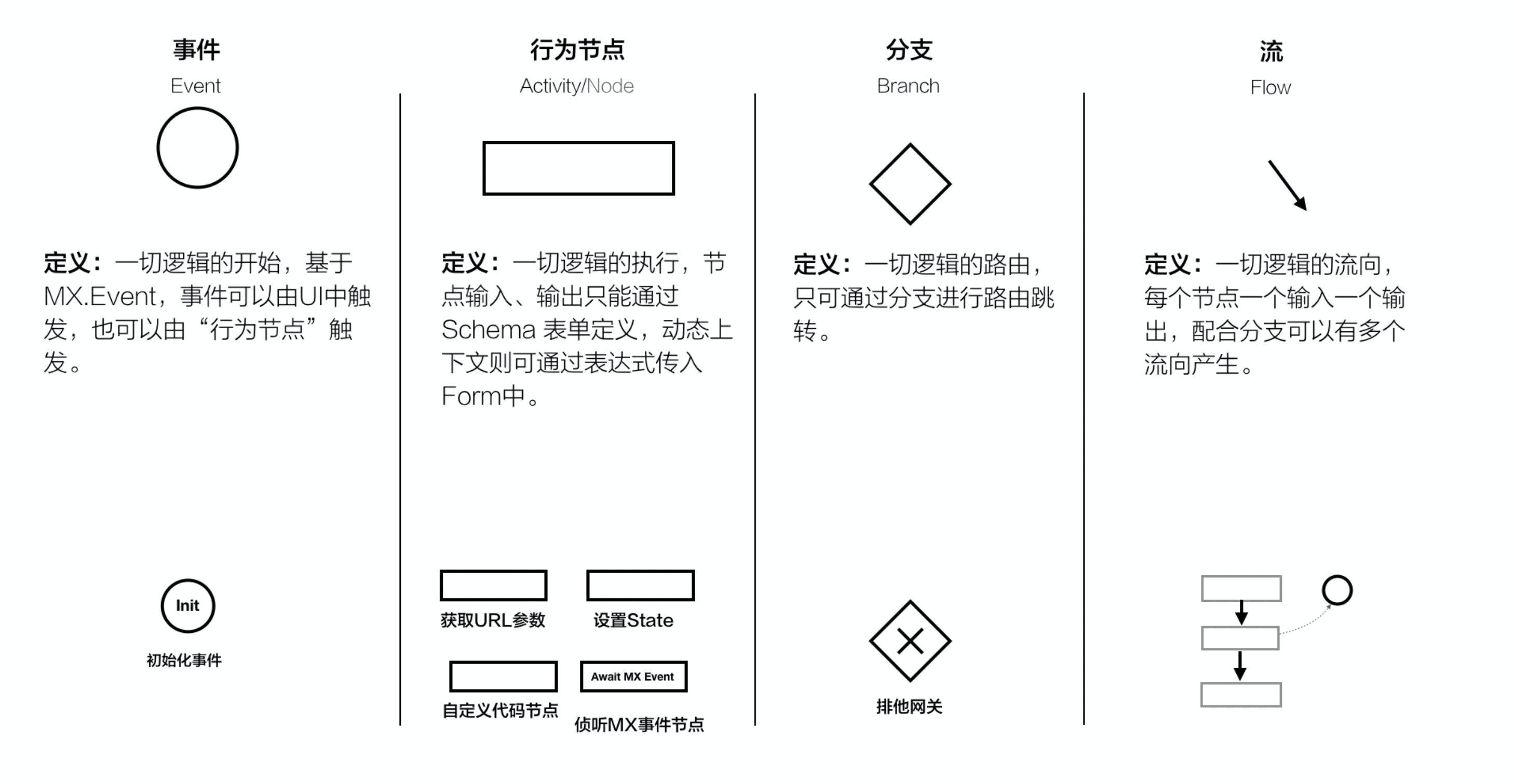
根据上述的规范描述,我们可以绘制出各种各样的逻辑流程图,例如 进入首页 的流程图如下所示:
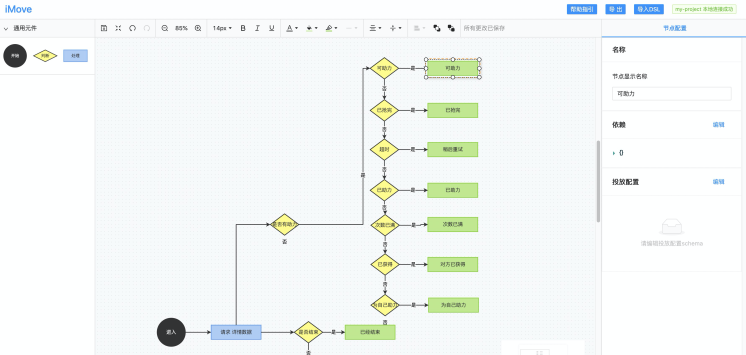
节点属性结构
imove 的流程图节点需要承载了多种属性,如节点文字、代码、投放配置模型、投放配置数据、依赖包等等,但是在 x6 中,节点的基本属性为 id、 shape、 position、 size,主要包括与 x6 图形展示相关的基本数据,简称为图形化数据。因此我们需要扩展节点属性,这些扩展的属性简称为自定义数据。
图形化数据(主要包括与 X6 图形展示相关的基本数据)
id: 32-bit 唯一标识符
shape: 形状
position: {x, y}: 横向/纵向位移
size: {width, height}: 宽高大小
...
自定义数据(扩展的属性)
type: 节点类型
label: 节点展示文案
code: 节点存储的代码
dependencies: js 代码的依赖包
trigger: 触发逻辑开始的事件名(开始节点才有)
ports: 节点出口配置(跳转逻辑,分支节点才有)
configSchema: 投放配置模型
configData: 投放配置数据
version: 版本号
forkId: 复制来源
referId: 引用来源
定义完这些节点属性后,就可以实现节点信息的存储,不至于丢失信息。通常来说,信息配置使用频率最高的有:
显示名称:更改节点名称
逻辑触发名称:开始节点类型专属配置,项目代码使用时根据这个值触发逻辑调用
投放配置
schema:修改投放配置的表单结构
这里编辑的每一条信息,都会保存在节点的属性里。
节点拖拽
单纯有画布是不够的,我们还需支持在画布上添加节点:
可以使用 addNode 和 addEdge 方法来动态添加节点和边:
// 添加起点const source = graph.addNode({ id: 'node1', x: 40, y: 40, width: 80, height: 40, label: 'Hello',});// 添加终点const target = graph.addNode({ id: 'node2', x: 160, y: 180, width: 80, height: 40, label: 'World',});// 连线graph.addEdge({ source, target });然而这种方式并不能达到通过拖拽来生成流程图的要求,不过也不用担心, x6 已经考虑到了这点,封装了 Dnd 类(drag and drop)来解决这个问题。代码如下:
import { Addon, Graph } from '@antv/X6';const { Dnd } = Addon;// 创建主画布const graph = new Graph({ id: document.getElementById('flowchart'), grid: true, snapline: { enabled: true }});// 创建 Dnd 实例const dnd = new Dnd({ target: graph, scaled: false, animation: true});// 创建侧边栏const sideBar = new Graph({ id: document.getElementById('sideBar'), interacting: false});// 侧边栏添加内置节点1sideBar.addNode({ id: 'node1', x: 80, y: 80, width: 80, height: 40, label: 'Hello',});// 侧边栏添加内置节点2sideBar.addNode({ id: 'node2', x: 80, y: 140, width: 80, height: 40, label: 'iMove',});// 监听 mousedown 事件,调用 dnd.start 处理拖拽sideBar.on("cell:mousedown", (args) => { const { node, e } = args; dnd.start(node.clone(), e);});节点样式设置
为了不限制绘制流程图的体验, iMove 工具栏提供了绘制流程图常用到的一些功能(例如修改字号、加粗、斜体、文字颜色、背景颜色、对齐等等),这主要也是得益于 X6 提供了统一修改节点样式的方法。工具栏如下所示:

使用 setAttrs 方法可以配置指定的样式:
// 设置字号cell.setAttrs({ label: { fontSize: 14 } };// 设置字重cell.setAttrs({ label: { fontWeight: 'bold' } });// 设置斜体cell.setAttrs({ label: { fontStyle: 'italic' } });// 设置文字颜色cell.setAttrs({ label: { fill: 'red' } });// 设置背景颜色cell.setAttrs({ body: { fill: 'green' } });// …………节点代码编写
每个节点的代码等价于一个 js 模块,因此你不用担心全局变量的命名污染问题,甚至可以 import 现有的 npm 包,但最后必须 export 出一个函数。需要注意的是,由于 iMove 天生支持节点代码的异步调用,因此 export 出的函数默认是一个 promise。
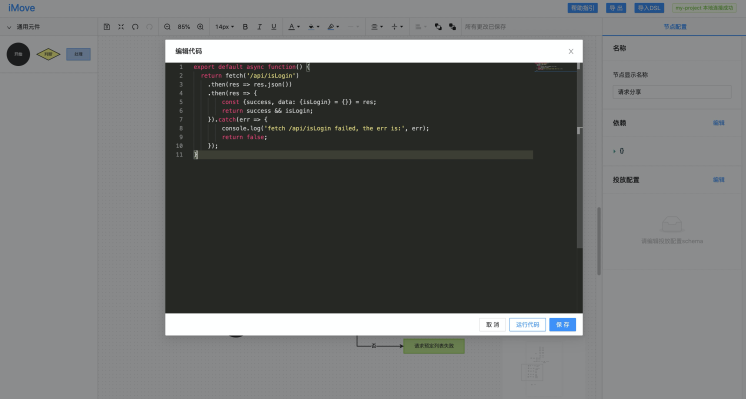
就以 是否登录 这个分支节点为例,我们来看下节点代码应该如何编写:
export default async function() { return fetch('/api/isLogin') .then(res => res.json()) .then(res => { const {success, data: {isLogin} = {}} = res; return success && isLogin; }).catch(err => { console.log('fetch /api/isLogin failed, the err is:', err); return false; });}由于该节点是分支节点,因此其 boolean 返回值决定了整个流程的走向。如果是非分支节点,直接流向下一个连接的节点即可。
节点间数据通信
完成节点代码编写之后,我们再来看下节点之间是如何进行数据通信的。
在 iMove 中,数据是以流(pipe)的形式从前往后进行流动的,也就是说前一个节点的返回值会是下一个节点的输入。不过也有一个例外,由于 分支节点 的返回值会是 boolean 类型,因此它的下游节点拿到的输入必将是一个 boolean 类型值,从而造成数据流的中断。为此,我们进行了一定的改造,分支节点的作用只负责数据流的转发,就像一个开关一样,只决定数据流的走向,但不改变流向下游的数据——流入分支节点后一个节点的数据依然是分支节点前一个节点输出的数据。
因此,以下例子中“请求 profile 接口”和“返回数据“两个节点会成为数据流的上下游关系。
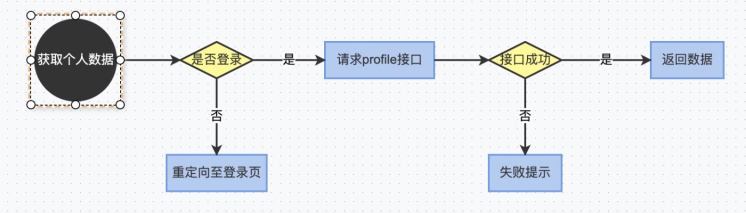
我们再来看下他们之间是如何进行数据通信的:
节点: 请求 profile 接口
export default async function() { return fetch('/api/profile') .then(res => res.json()) .then(res => { const {success, data} = res; return {success, data}; }).catch(err => { console.log('fetch /api/isLogin failed, the err is:', err); return {success: false}; });}节点: 接口成功
export default async function(ctx) { // 获取上游数据 const pipe = ctx.getPipe() || {}; return pipe.success;}节点: 返回数据
const processData = (data) => { // TODO: 数据加工处理 return data;};export default async function(ctx) { // 这里获取到的上游数据,不是"接口成功"这个分支节点的返回值,而是"请求profile接口"这个节点的返回值 const pipe = ctx.getPipe() || {}; // 触发updateUI这个方法更新界面,传入的值为profileData ctx.emit('updateUI', {profileData: processData(pipe.data)});}如上代码所述,每个下游节点可以调用 ctx.getPipe 方法获取上游节点返回的数据流。另外,需要注意的是 返回数据 节点的最后一行代码 ctx.emit('updateUI', data) 需要和项目中的代码配合使用,项目中想监听这个事件,需要执行 logic.on('updateUI',data=>{ //handler })。
边设计
在 imove 中,边的作用被弱化,仅表示图形上的节点连接关系,主要控制流程的走向,使用过程中仅用于连线。因此我们没有额外设计边属性,只采用了 X6 默认的边的属性:id(唯一标识符)、shape(形状)、source(起点)、target(终点)。如下所示:
{ "id": "5d034984-e0d5-4636-a5ab-862f1270d9e0", "shape": "edge", "source": { "cell": "1b44f69a-1463-4f0e-b8fc-7de848517b4e", "port": "bottom" }, "target": { "cell": "c18fa75c-2aad-40e9-b2d2-f3c408933d53", "port": "top" }}除了边属性结构描述外,我们还需要关注边连线实现、样式定制化和代码编译,下面会分别讲一下。
边连线实现
边连线是通过在画布上绑定 edge:connected 事件实现的:
flowChart.on('edge:connected', (args) => { const edge = args.edge as Edge; const sourceNode = edge.getSourceNode() as Node; if (sourceNode && sourceNode.shape === 'imove-branch') { const portId = edge.getSourcePortId(); if (portId === 'right' || portId === 'bottom') { edge.setLabelAt(0, sourceNode.getPortProp(portId, 'attrs/text/text')); sourceNode.setPortProp(portId, 'attrs/text/text', ''); } }});这些 x6 都已经提供好了,开发和定制都是非常简单。
边选中样式定制化
默认的边是没有选中高亮的样式的,这里我们可以直接在画布上绑定边选中的事件,改变边的样式即可:
flowChart.on('edge:selected', (args) => { args.edge.attr('line/stroke', '#feb663'); args.edge.attr('line/strokeWidth', '3px');});如果大家想按照自己的喜好来定制流程图上的边展示,可以非常简单的实现。
基于流程图的代码编译
流程图画好了,我们如何实现完整流程的代码运行呢?其实,流程图对应是的一个 JSON Schema,这样我们就可以根据节点的连接顺序进行编译了:

流程图编译的 Schema 如下所示:
分支节点{ "shape": "imove-branch", "data": { "ports": { "right": { "condition": "true" }, "bottom": { "condition": "false" } }, "code": "export default async function(ctx) {\n return true;\n}" }, "id": "a6da6684-96c8-4595-bec6-a94122b61e30"}连线{ "shape": "edge", "id": "cbcbd0ea-4a2a-4d2a-8135-7b4b7d7ec50d", "source": { "cell": "de868d18-9ec0-4dac-abbe-5cb9e3c20e2f", "port": "right" }, "target": { "cell": "a6da6684-96c8-4595-bec6-a94122b61e30", "port": "left" }}通过流程图 Schema,可以解析到节点属性和节点关系,如开始节点、行为节点如何流向下一个节点,分支节点如何根据运行结果分别流向两条边。具体的编译过程如下所示:
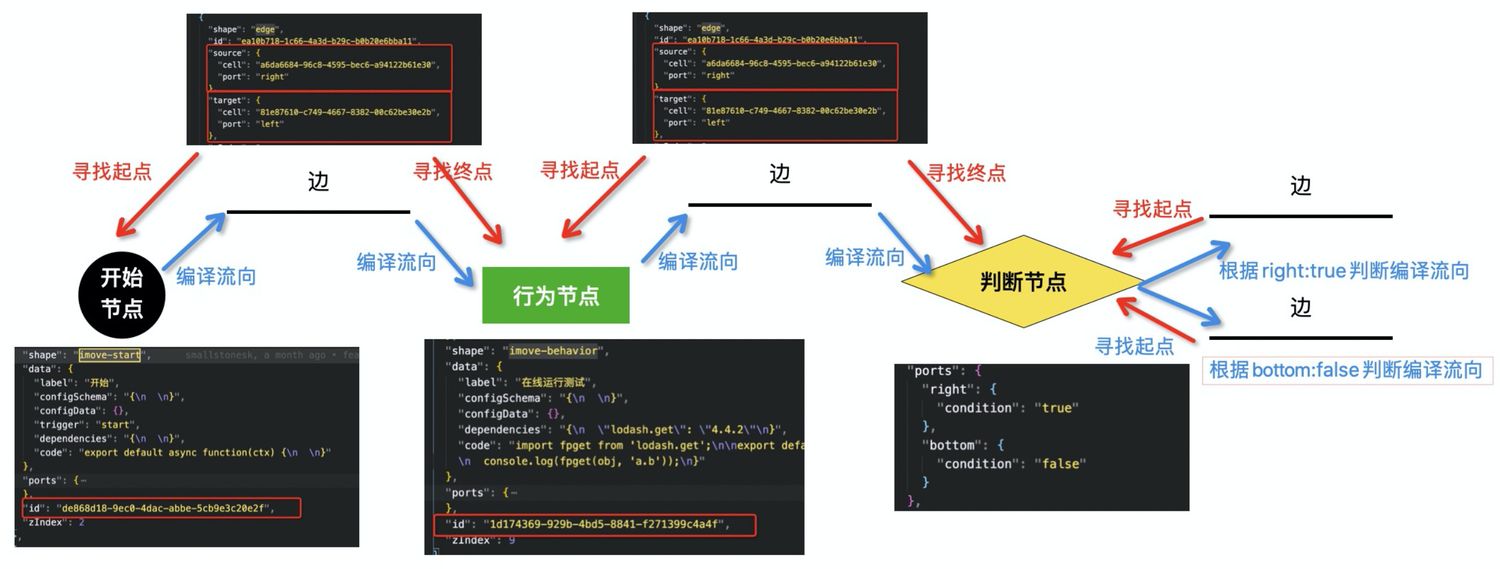
首先根据 DSL 可以获取全部的边(Edge),边的属性上存储了 source 节点和 target 节点的 id 和方向,即起始节点和终点节点的 id 和方向,再根据节点的 id 可以找到全部的节点,于是可以串联起全部的节点和边。这里有几点要注意的是:
节点(Node)和边(Edge)的
id永远都是唯一的,可以根据 id 找到对应的节点/边。方向永远都是从边(Edge)的
source节点流向target节点的,因此节点之间的流动关系也是固定的。判断节点有两个输出方向,需要根据节点输出的 boolean 值去判断走向。其中判断节点记录了两条边对应的方向和
boolean值,在编译时需要考虑。
按照以上分析的思路,找到当前节点的下一个节点代码如下:
// 找到下一个节点const getNextNode = (curNode: Cell.Properties, dsl: DSL) => { const nodes = dsl.cells.filter((cell) => cell.shape !== 'edge'); const edges = dsl.cells.filter((cell) => cell.shape === 'edge'); const foundEdge = edges.find((edge) => edge.source.cell === curNode.id); if (foundEdge) { return nodes.find((node) => node.id === foundEdge.target.cell); }};基于 form-render 的可视化搭建
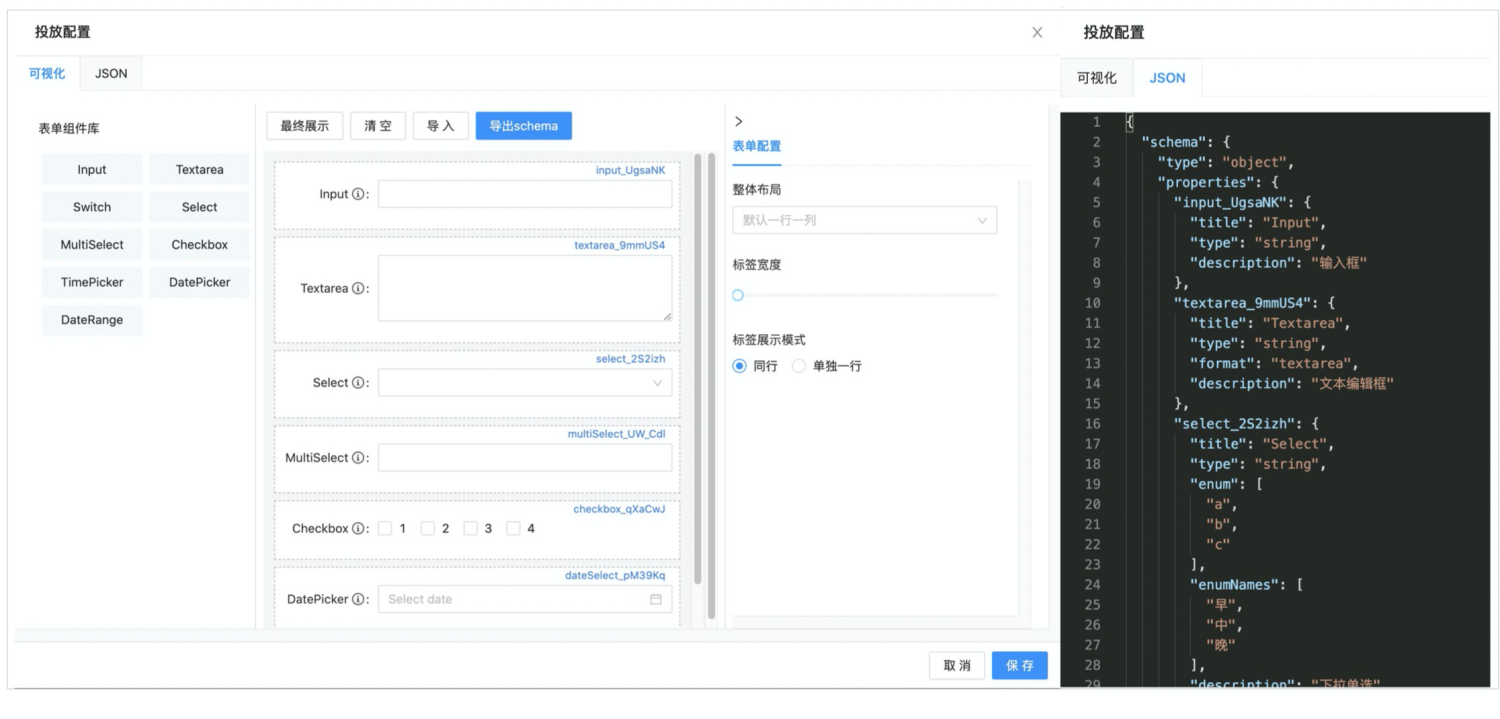
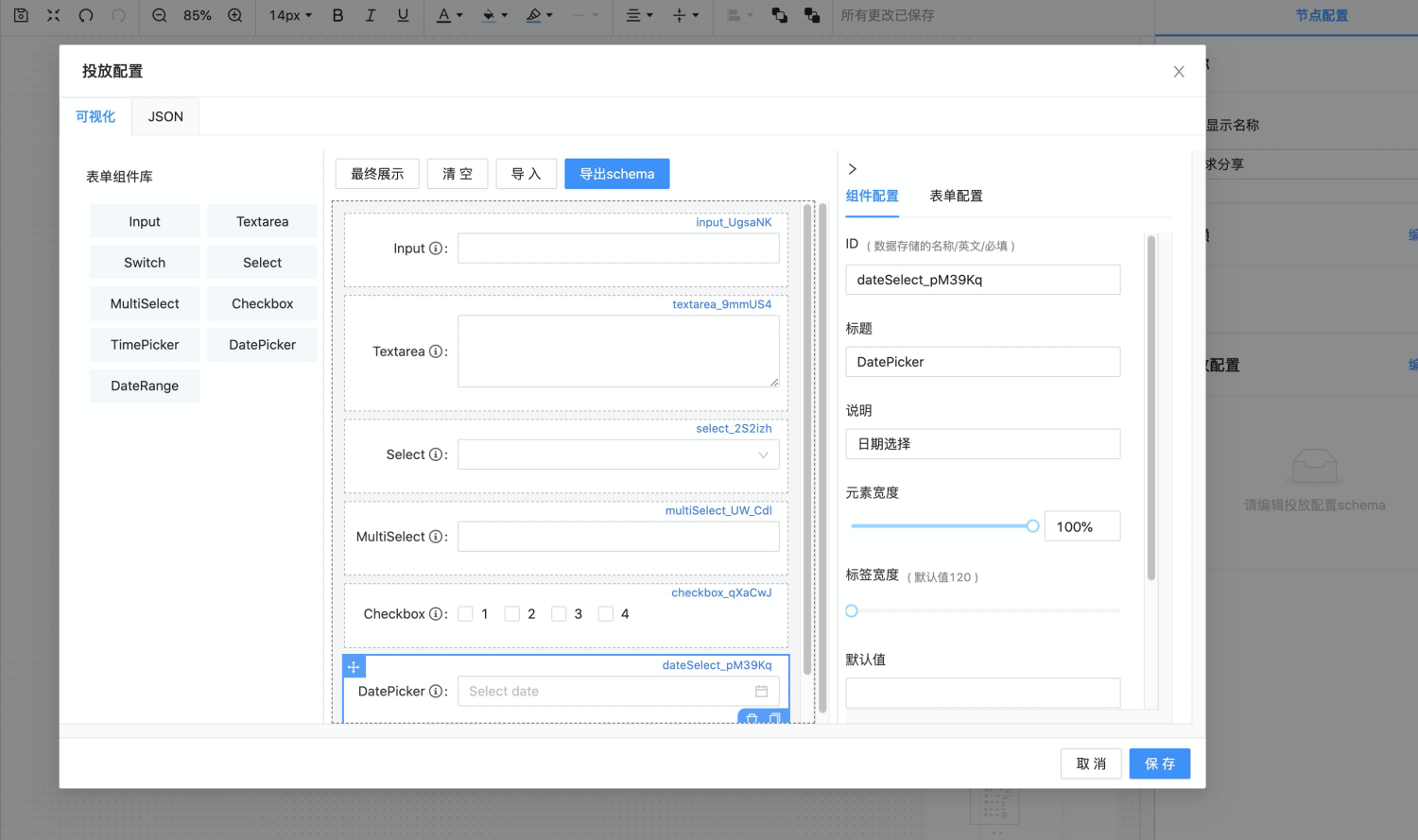
在电商领域,业务场景会时常涉及到营销表单的配置。因此代码中会暴露出一些字段供运营配置,这些字段需要以合适的表单形式呈现,因此涉及到表单 Schema 结构的定义。 iMove 在定义表单 Schema 结构时,是可以使用可视化的方式设计表单结构的,这里得益于 form-render 这个开源项目的优秀设计,我们可以使用其提供的fr-generator库,通过可视化拖拽修改的形式快速生成投放表单结构,方便后续进行数据投放。具体效果如下:
如何做到 Schema to Form
以上提到的fr-generator表单设计器是如何快速地进行表单搭建的呢?这不得不先说一下如何根据规范化 Schema 转化为 Form。知其然知其所以然,接下来我们看看 form-render 是如何实现这一步的:
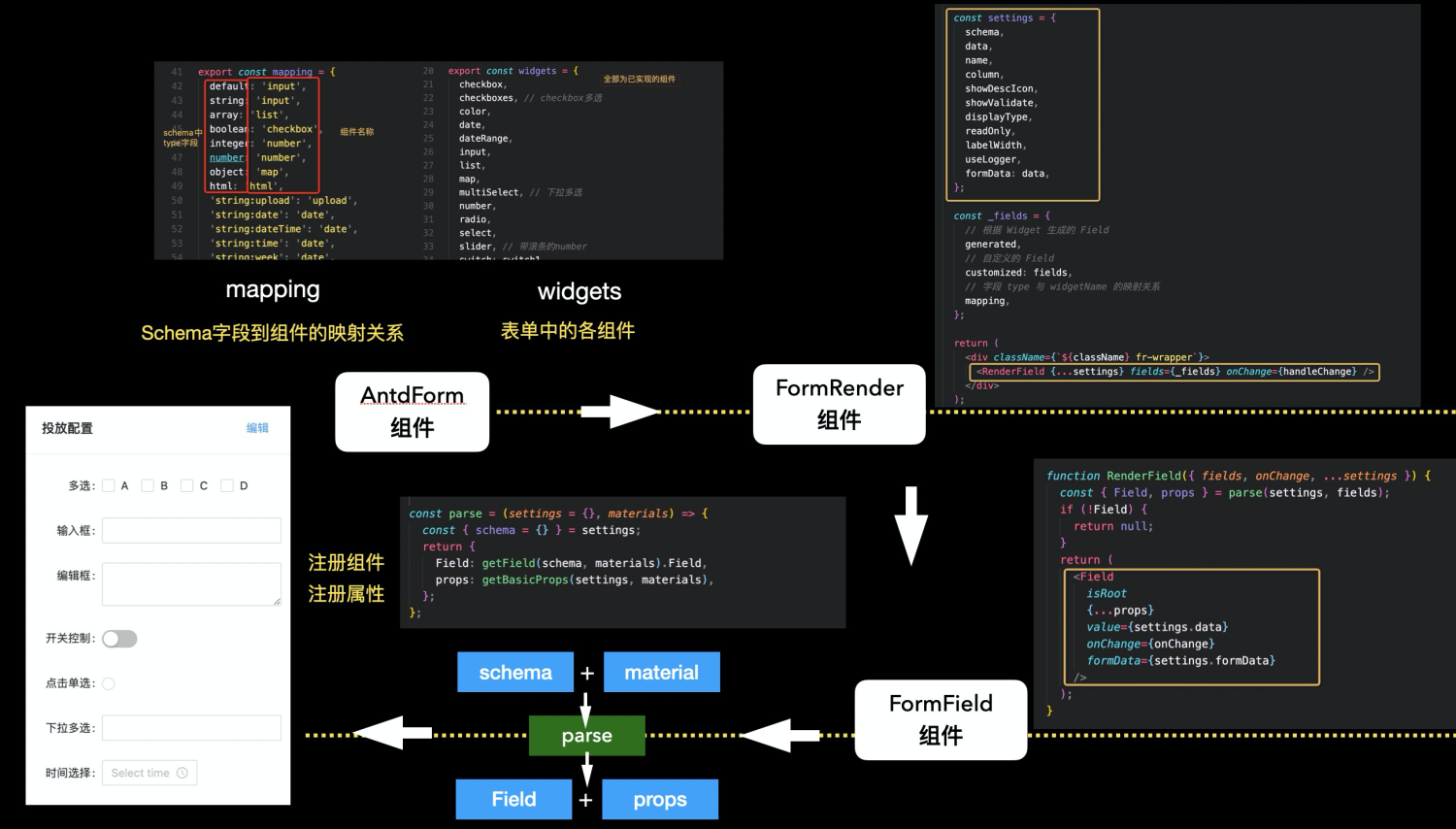
入口是
AntdForm/FusionForm组件(分别兼容antd组件库和fusion组件库)。其中传入widgets参数包含了暴露的所有组件,如checkbox、input、radio、select等,mapping参数包含了schema的type字段与widgetName(组件名)的映射关系。AntdForm/FusionForm组件是由RenderField组件实现的,在这里组合了全部的Widget生成了Field组件(即纯展示的表单组件)。RenderField是由Field组件实现的,在这里将纯展示表单组件和schema的属性结合在一起,转化为真正带有属性的表单组件。转化函数详见parser.js,这里的转化函数是基于form-render设计的 json 规范实现的,使用'ui:className'、'ui:hidden'、'ui:width'等一致的属性命名规范去承载样式数据。
接下来讨论下fr-generator表单设计器的核心操作是什么。点击左侧表单组件,就可以将其加入到表格中:
以下的 Element 组件即代表左侧每一个表单选项,点击左侧表单组件,会调用handleElementClick方法,实际上是调用了 addItem 方法:
const Element = ({ text, name, schema, icon }) => { // ...... const { selected, flatten, onFlattenChange } = useStore(); const handleElementClick = () => { const { newId, newFlatten } = addItem({ selected, name, schema, flatten }); onFlattenChange(newFlatten); setGlobal({ selected: newId }); }; return ( <div ref={dragRef}> <WidgetUI text={text} icon={icon} onClick={handleElementClick} /> </div> );};addItem 对应的代码实现如下,其实是改变了原有的 JSON Schema 数据, JSON Schema 改变了,中间渲染的表单就会跟随发生变化。核心步骤如下:
获取画布中选中的节点(表单项)
获取此节点的父节点 children 属性
找到此节点在 children 数组中的位置
在选中节点后插入新的表单项(其实是在操作父节点的 children 数组)
JSON Schema 结构改变
画布更新
// 点击左侧菜单添加表单结构项export const addItem = ({ selected, name, schema, flatten }) => { // ...... let _name = name + '_' + nanoid(6); const idArr = selected.split('/'); idArr.pop(); idArr.push(_name); newId = idArr.join('/'); const newFlatten = { ...flatten }; try { // 拿到选中的节点 const item = newFlatten[selected]; // 拿到选中节点的父节点children属性 const siblings = newFlatten[item.parent].children; // 找到选中节点在children数组中的位置 const idx = siblings.findIndex(x => x === selected); // 将选中节点后插入新的表单项 siblings.splice(idx + 1, 0, newId); const newItem = { parent: item.parent, schema: { ...schema, $id: newId }, data: undefined, children: [], }; newFlatten[newId] = newItem; } catch (error) { console.error(error); } return { newId, newFlatten };};数据驱动带来的便利性
其实,类似于 form render、 fomily 这样的库,可以通过简单的 JSON Schema 生成表单,都是基于数据驱动的思想实现的。维护自身的一套 schema 规范,按照规范解析 schema 文件可以直接完成表单的渲染。数据驱动为何让开发者如此热衷? react、 vue 等流行框架的底层也是数据驱动的思维,解放了程序员繁琐重复的工作。
就拿 vue 框架来说,以下数据驱动带来的便利性非常受人欢迎:
模板渲染:根据模板生成
AST,最后根据AST树填充数据生成真实DOM数据绑定:可以监听 交互输入/http 请求响应/定时器触发 等行为,当数据发生变化时,做
diff操作,完成DOM的更新路由引擎:根据 host/path/params 等数据,解析对应页面
在数据驱动的场景下,我们只需要完成两步:
将产品、业务、设计进行抽象化,将 UI、交互抽象为数据
将数据用逻辑处理连接起来,通过数据去直接影响结果
数据驱动的思想能够给前端带来很多的便利。以前开发时,我们处理页面元素就会处理 DOM,处理事件逻辑就会处理 JavaScript,处理样式就会处理 CSS。切换为数据驱动的思想之后,我们可以把页面元素、事件逻辑、样式都视为数据,设计好数据与状态之间的转换关系,通过改变数据直接去改变状态。以上介绍的 x6 和 form-render 都是可以通过已有的规范 JSON 数据,直接生成对应的流程图和表单,其实数据和 UI 的转换关系已经隐藏在了框架的内部实现中。
总结
这篇文章主要讨论了 imove 基于X6和form-render背后的思考以及相关的实现原理,主要是在已有开源库的基础上不断去完善,直到满足项目的需求,这样才能做到 ROI 最大化,相互成就。 iMove 做的比较好的是定位,继而将写法规范化,将编排工具化,这样克制的设计使得 iMove 具备小而美的特点,便于开发使用。
我们在初次使用某个开源框架或库时可以根据官方文档提供的示例实现 Demo 效果,由于每个人业务需求都不尽相同,可能需要进行不同的配置甚至进行二次开发才能实现。这时候,可以恰当地使用现有的 API 能力去尽量实现需求,如果没有提供相应的能力,也可以看看有没有提供自定义插件、自定义函数或组件能满足需求。如果还是没有合适的方案,或许可以尝试一下自己实现?如果框架体积非常大但是你只需要使用到其中很小一部分,这时候可以考虑下看看对应的源码,学习下原理尝试自己实现,其实 x6 和 form-render 这种开源基础库在很多场景下都是非常实用的。未来 imove 还会持续迭代,喜欢的朋友们欢迎来踩踩哦~
活动推荐
在今年的 5 月 28-30 日举办的 QCon全球软件开发大会(北京站)我们也设置了“低代码探索与实践“专题,目前议题征集中,欢迎大家来 QCon 分享。此外,QCon 还设置有前端工程化、业务架构、大数据实时计算等技术专场,感兴趣的同学点击官网抢先了解吧。




