
整理 | 华卫
5 月 29 日,由微软支持、估值 60 亿美元的法国 AI 初创公司 Mistral 发布了其有史以来的第一个用于编码的“开放式”生成式 AI 模型,称为 Codestral。
与其他代码生成模型一样,Codestral 旨在通过共享指令和完成 API 端点,帮助开发人员编写代码并与之交互。由于精通代码和英语,它还可用于为软件开发人员设计高级人工智能应用程序。值得一提的是, Codestral 的参数要求很高,还受到一些许可证方面的使用场景限制。
虽然该模型刚刚推出,尚未进行公开测试,但 Mistral 声称,Codestral 在大多数编程语言上已经优于现有的以代码为中心的模型,包括 CodeLlama 70B、Deepseek Coder 33B 和 Llama 3 70B。此外,Codestral 在 Kotlin 语言的表现上似乎还超过了 GPT-4-Turbo 和 GPT-3.5-Turbo。
精通 80+ 编程语言
多个基准测试中名列前茅
首先, Codestral 具备广泛的语言基础,可以在各种编码环境和项目中为开发人员提供帮助。据悉,Codestral 在 80 多种编程语言的不同数据集上进行了训练,其中包括 Python、Java、C、C++、JavaScript 和 Bash 等流行语言。在 Swift 和 Fortran 等更特殊的语言上,Codestral 也表现出色。
而且,Codestral 可以完成编码函数、编写测试和“填写”部分代码,以及用英语回答有关代码库的问题,可为开发人员节省时间和精力。与 Codestral 的互动,将有助于提高开发人员的编码水平,减少错误和 bug 的风险。
性能方面,相比之前其他用于编码的模型,Codestral 作为 22B 的模型,在代码生成的性能/延迟空间方面树立了新的标准。Mistral 介绍,Codestral 拥有 32k 的较大上下文窗口(竞争对手为 4k、8k 或 16k),在代码生成的远程评估 RepoBench 中优于所有其他模型。
同时,Mistral 将 Codestral 与硬件要求更高的现有特定代码模型进行了比较。针对 Python,其使用了四个基准测试:通过 HumanEval pass@1、MBPP sanitised pass@1 来评估 Codestral 的 Python 代码生成能力;CruxEval 来评估 Python 输出预测能力;RepoBench EM 来评估 Codestral 的远程存储库级代码完成能力。
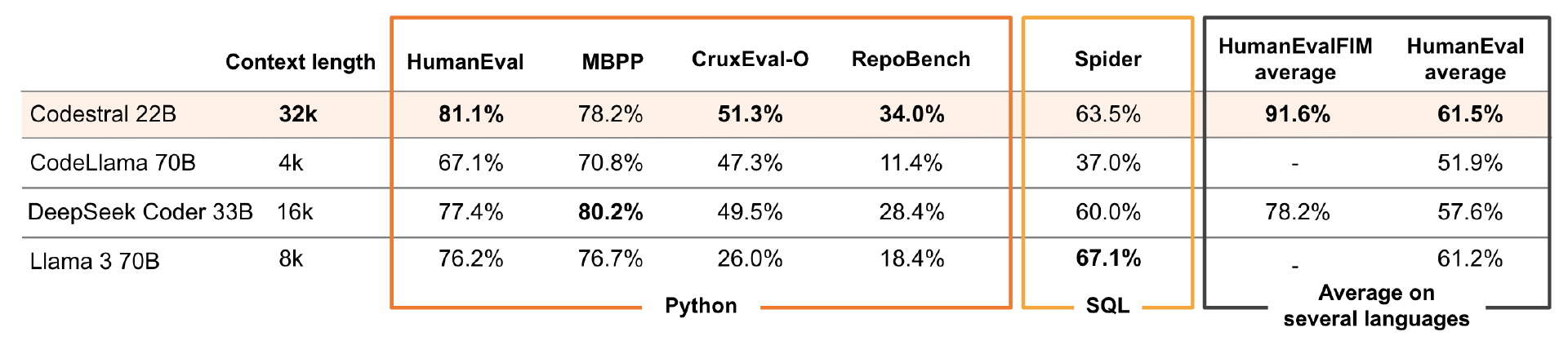
在远程存储库级 Python 代码的完成情况上,Codestral 以 34% 的准确率优于所有三个模型。同样,在评估 Python 代码生成的 HumanEval 和测试 Python 输出预测的 CruxEval 上,该模型分别以 81.1% 和 51.3% 的分数击败了竞争对手。它甚至优于 HumanEval 上用于 Bash、Java 和 PHP 的模型。
为评估在 SQL 方面的性能,Mistral 使用了 Spider 基准,Codestral 以 63.5% 的得分位居第二。除了 Python 之外,Mistral 还评估了 Codestral 在六种不同语言的 HumanEval pass@1 中的表现: C++、bash、Java、PHP、Typescript 和 C#,并计算了这些评估的平均值。值得注意的是,该模型在 HumanEval 的 C++,C 和 Typescript 上的表现不是最好的,但所有测试的平均得分最高,为 61.5%,仅次于 Llama 3 70B 的 61.2%。
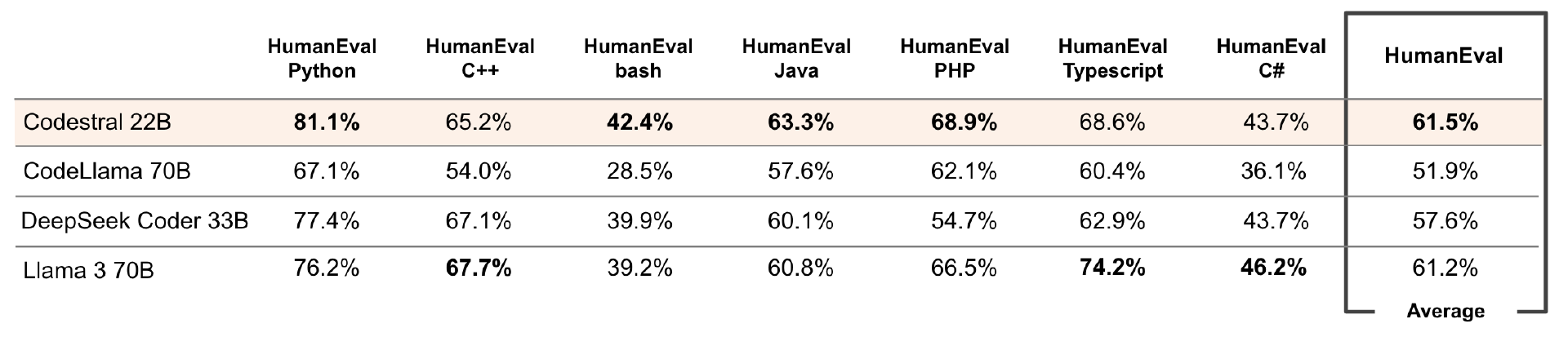
此外,Mistral 使用 Python、JavaScript 和 Java 中的 HumanEval pass@1 评估了 Codestral 的中间填充性能,并将其与 DeepSeek Coder 33B 进行了比较,后者的中间填充能力可立即使用,而 Codestral 的得分比它更高。

在开发者社区的反馈中,JetBrains 研究员 Mikhail Evtikhiev 还表示,“我们使用 Codestral 对 Kotlin-HumanEval 基准进行了测试,结果令人印象深刻。例如,在 T=0.2 的通过率方面,Codestral 获得了 73.75 分,超过了 GPT-4-Turbo 的 72.05 分和 GPT-3.5-Turbo 的 54.66 分。”
220 亿个参数
并不完全对外开放
根据 Mistral 的官方介绍,Codestral 是一个 22B 的开放式模型,采用 Mistral AI 新推出的非生产许可证 (MNPL),允许开发人员将其技术用于研究和测试目的,在 HuggingFace 上可以下载。该公司通过两个 API 端点提供该模型:codestral.mistral.ai 和 api.mistral.ai。
前者专为希望在其 IDE 中使用 Codestral 的 Instruct 或 Fill-In-the-Middle 路由的用户而设计,它带有一个在个人级别管理的 API 密钥,没有通常的组织速率限制,并且可以在八周的测试期间免费使用。后者则是更广泛的研究、批量查询或第三方应用程序开发的常用端点,查询按令牌计费。
但该模型是否真的“完全开放”,还有待商榷。这家初创公司的非生产许可证禁止将 Codestral 及其产出用于任何商业活动,虽然有 “开发 ”的例外,但也有注意事项: 许可证明确禁止 “员工在公司业务活动的背景下进行任何内部使用”。
原因可能是 Codestral 部分训练内容受版权保护,Mistral 在官方博文中没有证实或否认这一点,但这并不奇怪;有证据表明,这家初创公司以前的训练数据集包含受版权保护的数据。
今年 3 月,由前 Meta 研究人员创立的 AI 模型评估公司 Patronus AI 发布了一项研究,展示了 AI 模型制作受版权保护内容的频率,测试的四个模型是 OpenAI 的 GPT-4、Anthropic 的 Claude 2、Meta 的 Llama 2 和 Mistral AI 的 Mixtral。当时,Patronus AI 的联合创始人兼首席技术官 Rebecca Qian 表示,“我们几乎在评估的所有模型中都发现了受版权保护的内容,无论是开源还是闭源。”
不过无论如何,Codestral 的这一问题可能也不值得太麻烦地讨论。据介绍,该模型有 220 亿个参数,需要一台强大的 PC 才能运行。(参数从本质上定义了人工智能模型处理问题的能力,比如分析和生成文本)。从参数规模的使用门槛来说, Codestral 对大多数开发人员来说或许并不实用,在性能提升方面也是渐进式的。
代码模型的使用争议
Codestral 的出现,可能会引发“关于依赖代码生成模型作为编程助手是否明智”的争论。
至少在某些编码任务中,开发人员肯定会采用生成式 AI 工具。在 2023 年 6 月的一次 Stack Overflow 民意调查中,44% 的开发人员表示,他们现在在开发过程中使用 AI 工具,26% 的开发人员计划不久后使用。然而,需要注意的是,这些工具有明显的缺陷。
今年 1 月,GitClear 收集并分析了 2020 年 1 月至 2023 年 12 月期间编写的 1.53 亿行更改的代码。其发现,生成式 AI 开发工具正在导致更多错误代码被推送到代码库中,且这些助手并没有重构代码,而是提供了一键式重复现有代码的“诱惑”。当时,GitClear 指出,2024 年的问题是:谁来收拾残局?“对于代码的长期可维护性而言,也许没有比复制/粘贴代码更大的祸害了。”
2 月,Snyk 的一项新研究警告说,生成式 AI 驱动的编码助手,如 GitHub Copilot 等通常会放大用户代码库中现有的错误和安全问题。“简单地说,当 Copilot 建议代码时,它可能会无意中复制邻居文件中存在的现有安全漏洞和不良做法。这可能导致不安全的编码实践,并为一系列安全漏洞打开大门。”Snyk 的开发者关系和社区主管 Randall Degges 表示,大多数开发人员可能没有意识到 AI 编码助手可以很容易地从用户的代码库和开源项目中复制现有的安全问题。
在 2024 计算机-人机交互会议(CHI 2024)上,普渡大学的一项研究显示,OpenAI 的 ChatGPT 对编程问题给出的答案,有 52%包含错误信息,77%的答案比人类答案更冗长,78%与人类答案存在不同程度的不一致。
但这些研究结果,或许并不能阻止 Mistral 等公司试图用他们的代码模型来赚钱。
现在,Mistral 已经在其 Le Chat 对话式人工智能平台上推出了托管版 Codestral 及其付费 API。Mistral 还表示,将致力于把 Codestral 构建到 LlamaIndex、LangChain、Continue.dev 和 Tabnine 等应用框架和开发环境中。“从我们最初的测试来看,Codestral 是代码生成工作流程的绝佳选择,速度快、具有有利的上下文窗口,且 instruct 版本支持工具使用。”LangChain 首席执行官兼联合创始人 Harrison Chase 在一份声明中表示。
参考链接:
https://mistral.ai/news/codestral/
https://venturebeat.com/ai/mistral-announces-codestral-its-first-programming-focused-ai-model/




