
每次你用汇总统计来简化数据时都肯定会丢失信息。模型精度也不例外。如果你将模型拟合简化为一份汇总统计数据,就没办法再确定性能最低/最高的位置和原因了。
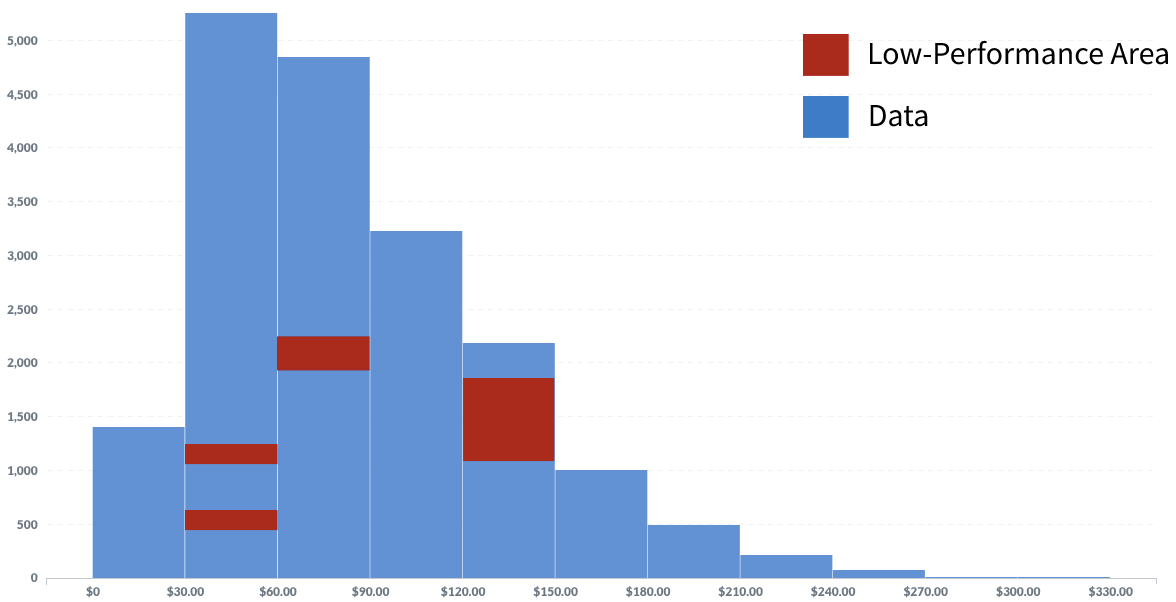
图 1:模型性能较低的数据区域示例。
为了解决这个问题,IBM 的研究人员最近开发了一种称为FreaAI的方法,可以给出模型精度较低位置的可解释数据切片。根据这些切片提供的信息,工程师可以采取必要的步骤来确保模型按预期运行。
不幸的是,FreaAI 不是开源的,但它采用的许多理念都可以在你喜欢的技术栈中轻松实现。下面我们就来深入了解一番。
技术总结
FreaAI 能够在测试数据中发现统计意义上性能显著低下的切片,然后将它们返回给工程师进行检查。方法步骤如下:
使用最高先验后验密度(HPD)方法以低精度查找单变量数据切片。这些单变量数据切片减少了搜索空间,并能揭示出我们的数据更可能出现问题的位置。
使用决策树以低精度查找双变量数据切片。这些双变量数据切片减少了分类预测变量和二阶交互的搜索空间,以揭示我们的数据更可能出现问题的位置。
删除所有不符合特定启发式算法(heuristic)的数据切片。只留下对测试集有最小支持的切片,它们的统计错误率显著升高。
这到底说的是什么意思?
一堆术语太难懂了,所以我们放慢一点,看看到底发生了什么事情......
问题
在开发模型时,我们经常使用“精度”指标来确定拟合。一个例子是均方误差,它用于线性回归,定义如图 2。

图 2:均方误差公式。
但是这个平均误差只告诉了我们平均表现是什么样的。我们不知道我们我们是不是在数据的某些部分表现很好,在其他一些部分表现很差。
这是预测建模中一个长期存在的问题,最近引起了很多关注。
解决方案
一种解决方案就是 FreaAI。该方法由 IBM 开发,旨在找出我们的模型在数据中的哪些部分表现不佳。
它分为两大步骤。第一步是创建数据切片,第二步是确定模型在这些数据切片中是否表现不佳。FreaAI 的输出是我们的数据中模型性能较低的一组“位置”。
2.1 数据切片
组合测试(CT)是一个框架,它按顺序查看所有预测变量组,以发现性能不佳的区域。例如,如果我们有两个分类预测变量——颜色和形状,我们会查看所有可能的组合,看看精度下降的是哪些地方。
然而,想要在大型数据集上利用组合测试在计算上是不可能做到的——随着列数越来越多,我们所需的组合数量会呈指数增长。因此,我们需要定义一种方法来帮助我们搜索特征以找到潜在的低精度区域。
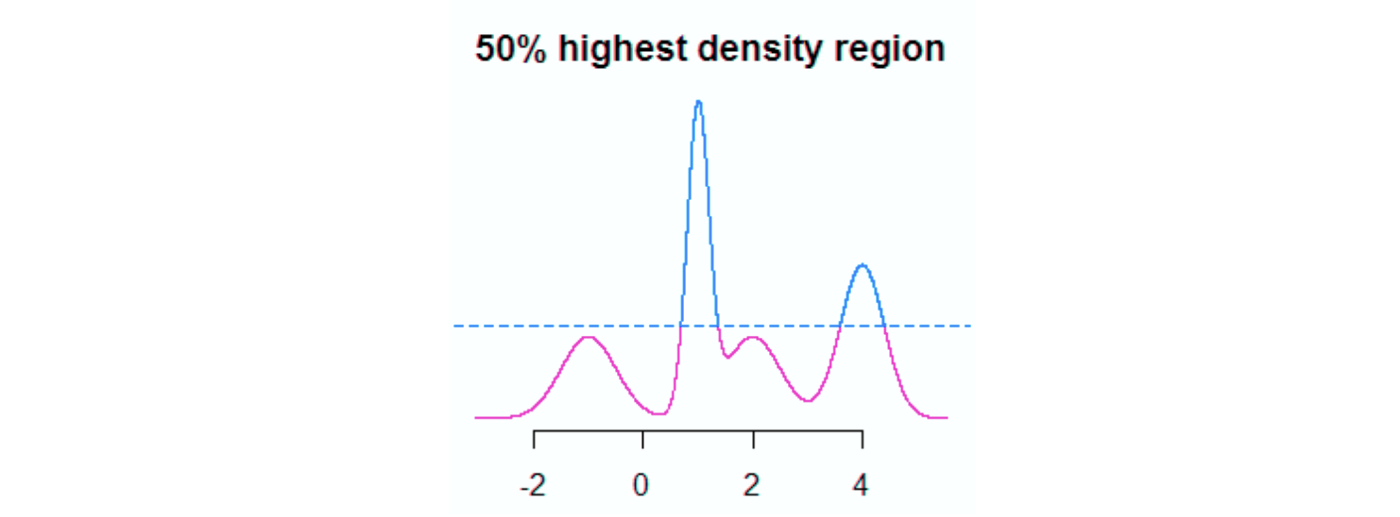
图 3:50%最高密度区域(HDR)的示例,用蓝色表示。
FreaAI 中利用的第一种方法使用称为最高密度区域(HDR)(图 3)。简而言之,HDR 会寻找满足一个数字特征的数据达到一定比例的最小区域,即高密度区域。在图 3 中,该区域由水平蓝色虚线区分——我们 50%的数据位于该线上方。
然后我们迭代地将这个范围减小一个ε值(默认为 0.05),并寻找精度增加的情况。如果在给定迭代中精度确实增加了,我们就知道模型在先前迭代和当前迭代之间的区域中表现是不佳的。
为了找出不能很好满足数值预测变量的区域,我们会对测试集中的所有预测变量迭代运行这个 HDR 方法。
很酷,对吧?
第二种方法利用决策树来处理所有非数字预测变量以及两个特征的组合。简而言之,我们拟合了一个决策树,并寻找这些特征的哪些分割最小化了精度。
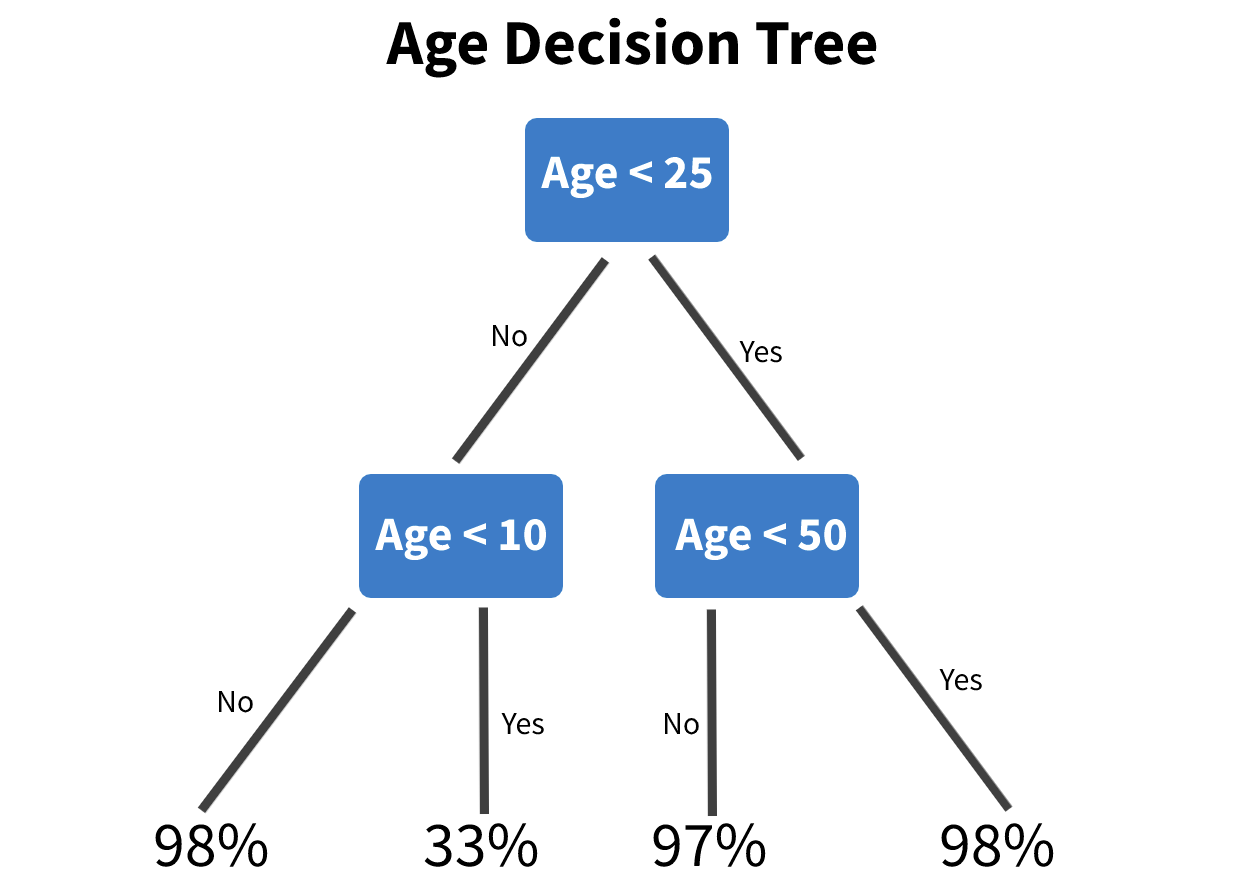
图 4:关于连续单变量预测变量“年龄”的决策树示例
在图 4 中,每个决策节点(蓝色)是我们特征的一个分割(spilt),每个末端节点(数字)是该分割的精度。通过拟合这些树,我们可以真正减少搜索空间并更快地找到性能不佳的区域。此外,由于树对于许多类型的数据都非常稳健,我们可以在分类预测变量或多个预测变量上运行它以捕获交互效应(interaction effects)。
对于所有特征组合以及非数字的单个特征都会重复这种决策树方法。
2.2 数据切片的启发式算法
到目前为止,我们只是在使用精度来开发数据切片,但还有其他启发式算法可以帮助我们找到有用的数据切片:
统计显著性:为了确保我们只查看准确率显著下降的数据切片,我们只保留性能比误差置信区间下限低 4%的切片。这样,我们就能以概率α声明我们的数据切片具有更高的错误率。
可解释性:我们还希望对发现的问题区域采取行动,因此我们在创建组合时只查看两三个特征。将交互限制到较低阶后,我们的工程师就更有可能开发出解决方案。
最小支持:最后,数据切片必须有足够的错误率,值得我们去研究。我们要求必须至少有 2 个错误分类,或者它必须覆盖 5%的测试错误——以较大值为准。
值得注意的是,你可以根据业务需求定制其他启发式算法,精度/召回权衡就是一个例子。
总结和要点
FreaAI 的大致原理就讲这么多。
再次提醒,FreaAI 不是开源的,但将来大概会向公众发布。同时,你可以将我们讨论过的框架应用于你自己的预测模型,找出模型性能不足的位置。
3.1 概括
回顾一下,FreeAI 使用 HDR 和决策树来减少我们预测变量的搜索空间。然后它会反复查看单个特征和组合,以找出性能低下的位置。针对这些低性能区域还会用上一些启发式算法,可确保发现是可操作的。
3.2 这个方法的意义
首先这个框架可以帮助工程师识别模型的缺陷所在,并(希望)可以纠正它们,从而改进模型的预测能力。这种收益对于黑盒模型(例如神经网络)来说尤其有吸引力,因为这种模型中没有能用的系数。
通过隔离表现不佳的数据区域,我们得到了一个窥探黑匣子的窗口。
FreaAI 还有很多有趣的潜在应用场景。一个例子是识别模型漂移,当经过训练的模型随着时间的推移变得效果越来越差时就会发生这种情况。IBM 刚刚发布了一个用于确定模型漂移的假设检验框架。
另一个有趣的应用是确定模型偏见。在这种情况下,偏见是不公平的概念,例如根据某人的性别拒绝向某人提供贷款。通过查看模型性能较低的数据分割,你可以发现存在偏见的区域。
原文链接:
https://towardsdatascience.com/how-to-find-weaknesses-in-your-machine-learning-models-ae8bd18880a3




