
背景
流式布局,这是一种当前无论是前端,还是 Native 都比较流行的一种页面布局。特别是对于商品这样的 Feeds 流,无论是淘宝,京东,美团,还是闲鱼。都基本上以多列瀑布流进行呈现,容器列数固定,然后每个卡片高度不一,形成参差不齐的多栏布局。
对于 Native 来说,无论是 iOS 还是 Android,CollectionView 和 RecyclerView 都能满足我们的绝大部分场景了。不过目前闲鱼很多业务场景都是在 Flutter 上进行实现的,当时 Flutter 官方只提供了 ListView 和 GridView 的实现,没有对瀑布流进行支持。
目前社区中有两个开源的解决方案,分别是 WaterFallFlow 和 FlutterStaggeredGridView。但是在闲鱼的场景中都有一些无法满足的痛点。前者无法支持 RecyclerView 中 StaggeredGridLayoutManager 中 setFullSpan 这样的横跨全屏的横条卡片混排能力能力,后者在不提前预设置卡片高度的情况下有比较严重的性能问题,以及在多 Sliver 的场景下会有滚动错误的功能性问题。而在目前闲鱼的业务中,无论是搜索结果还是首页的同城页面,都会有混排瀑布流的需求。
所以我们决定参考 RecyclerView 中 StaggeredGridLayoutManager 的布局思路实现一套支持普通流式卡片和横跨全屏的横条卡片混排的流式布局,如图所示:
原理分析与布局流程
其实瀑布流布局和 ListView 和 GridView 一样,就是按照不同的策略将多个卡片进行尺寸计算和位置计算,然后将它们排列到一起,组成一个超过一屏,可滚动的布局。所以整个布局策略包括两个过程,首先是对卡片进行尺寸计算,计算结果决定了卡片在滚动布局中的大小。然后卡片进行位置计算,计算结果决定了卡片在滚动布局中的坐标。有了大小和坐标,就可以完成整个滚动容器的布局。下面我会对网格布局(GridView)和瀑布流布局(FlowView)的布局策略进行一个对比,让大家能更清楚的了解布局过程的细节。
Flutter 中网格布局整个布局的源码都在flutter/lib/src/rendering/sliver_grid.dart的 performLayout 方法中,我们下面跟着源码来分析一下整个布局流程。感兴趣的同学也可以结合源码食用本文,风味更佳。
网格布局
尺寸计算过程
我们先来分析一下网格布局的卡片尺寸计算过程。这是一个 GridView 的常用初始化参数,我省略了一些和尺寸计算无关的参数。
GridView.count({ @required int crossAxisCount, double childAspectRatio = 1.0,})影响布局的参数其实就是 crossAxisCount(列数)和 childAspectRatio(卡片纵横比)。有了这两个参数其实卡片的尺寸就很好计算了,首先先用 crossAxisCount 来对屏幕宽度进行等分,确定卡片的宽度,然后我们再根据这个 childAspectRatio 参数来计算得到卡片的高度。网格布局的卡片尺寸就可以确定下来了。计算过程如图所示:

位置计算过程
在端侧,因为一个滚动容器中的卡片数量可能会非常大,所以我们不可能对所有的卡片都进行布局,内存和运算时间都是无法接受的。我们只会布局在屏幕中以及缓存区里的卡片,之外的卡片我们会进行回收。等用户向下滑动的时候,把屏幕下方的卡片创建并布局,然后把已经划出屏幕的卡片进行回收。向上滑动的过程也是一样。所以我们会对从上到下和从下到上的位置计算过程进行分析。
我们先分析从上到下布局的过程。对于网格布局来说,每一个卡片的宽度和高度都是在位置计算流程开始之前就可以提前计算得出的。我们暂且把每个卡片的左上角叫做布局坐标点,我们来分析一下网格布局中这个坐标如何计算得出。
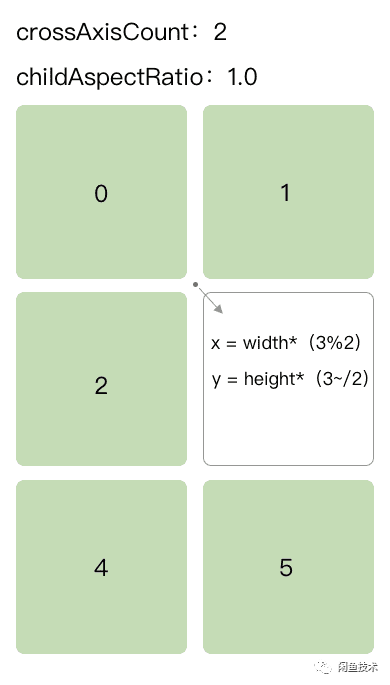
我们先来计算一下纵坐标,我们用卡片的 index 对 crossAxisCount 进行整除,然后再用结果乘上卡片的高度,就可以得到卡片的纵坐标了。
对于横坐标,我们已经根据 crossAxisCount 来对屏幕宽度进行了等分,那么每个卡片的横坐标就很容易得到了,我们用卡片的 index 对 crossAxisCount 进行整除取余,这样就能得到卡片在某一行中的顺序(即第几列),然后再乘上卡片的宽度,这样就可以得到卡片的横坐标了。
例如列数为 2,卡片宽度和高度都为 100 的一个网格布局,那么第四个卡片(index 为 3)的横坐标为(3%2)×100 为 1,纵坐标为 (3~/ 2)×100 为 100,所以坐标为(100,100)。
计算过程如图所示:
整个布局关键源码如下:
// 卡片尺寸计算final double usableCrossAxisExtent = constraints.crossAxisExtent - crossAxisSpacing * (crossAxisCount - 1); final double childCrossAxisExtent = usableCrossAxisExtent / crossAxisCount; final double childMainAxisExtent = childCrossAxisExtent / childAspectRatio;// 卡片坐标计算SliverGridGeometry getGeometryForChildIndex(int index) { final double crossAxisStart = (index % crossAxisCount) * crossAxisStride; //横坐标 return SliverGridGeometry( scrollOffset: (index ~/ crossAxisCount) * mainAxisStride, //纵坐标 crossAxisOffset: _getOffsetFromStartInCrossAxis(crossAxisStart), mainAxisExtent: childMainAxisExtent, crossAxisExtent: childCrossAxisExtent, );} // 对卡片进行遍历布局for (int index = indexOf(firstChild) - 1; index >= firstIndex; --index) { final SliverGridGeometry gridGeometry = layout.getGeometryForChildIndex(index); //获取尺寸和位置信息 final RenderBox child = insertAndLayoutLeadingChild( gridGeometry.getBoxConstraints(constraints), ); //使用计算好的尺寸信息来限制卡片大小 final SliverGridParentData childParentData = child.parentData; childParentData.layoutOffset = gridGeometry.scrollOffset; //卡片的纵轴坐标赋值 childParentData.crossAxisOffset = gridGeometry.crossAxisOffset; // 卡片的横轴坐标赋值 assert(childParentData.index == index); trailingChildWithLayout ??= child; trailingScrollOffset = math.max(trailingScrollOffset, gridGeometry.trailingScrollOffset); }由此可见,网格布局中,每个卡片的位置坐标跟 index 是有一一对应关系的。所以无论是向下滚动对后面的卡片进行布局,还是向上滚动对前面的卡片进行布局。都使用这个策略就可以得出所有卡片的坐标。
瀑布流布局
尺寸计算过程
然后我们对瀑布流布局的卡片尺寸计算过程进行分析,反推出我们需要传入的初始化参数。首先,我们需要考虑到在瀑布流布局中一共有两种卡片,一种是宽度由屏幕宽度被布局列数均分的普通卡片,另一种是宽度充满整个屏幕的特殊卡片,我们后续叫它横条卡片。我们会分别对这两种卡片进行尺寸计算。
普通卡片
首先对于普通卡片来说,卡片的尺寸宽度和网格布局中的卡片一样,是由列数和屏幕宽度决定的,所以我们同样需要 crossAxisCount 这个参数。宽度确定之后,我们需要确定卡片的高度。在瀑布流布局中,每个卡片的高度是不同的,这也是瀑布流布局和网格布局最大的区别。所以我们其实可以由每个卡片自己决定自己的高度,也就是我们不需要在布局初始化的时候传入类似 childAspectRatio 这样影响卡片的参数。不过我们在实际的业务场景中,通常会对某些特殊位置的卡片进行特殊的高度设置,例如两列流中横条卡片上面的两个卡片,UED 会有保证这两个卡片的底部位置一致的需求,不然就会造成卡片之间的裂隙,影响观感。所以我们需要一个定义了一个方法参数 mainAxisExtentBuilder。
typedef double IndexedMainAxisExtentBuilder(int index);这是一个返回值为 double 的方法参数,瀑布流在布局的时候会根据 index 尝试获取开发者在这个方法中的返回值,如果这个返回值为 null,就用卡片自己内部的布局来决定卡片高度,反之就用这个返回值来决定卡片高度。计算过程如图所示:

横条卡片
横条卡片在高度的确定流程上是和普通卡片一致的,只是横条卡片的宽度总是和屏幕宽度一致,不受 crossAxisCount 限制。计算过程如图所示:

所以我们只需要在布局过程中能够区分这两种卡片,就可以用不同的策略对它们的尺寸进行计算。类似于 mainAxisExtentBuilder,我们定义了一个 IndexedFullSpanBuilder 参数。
typedef bool IndexedFullSpanBuilder(int index);这是一个返回值为 bool 的方法参数,瀑布流在布局的时候会根据 index 尝试获取开发者在这个方法中的返回值,如果这个返回值为 null 或者 false,就使用普通卡片的宽度计算策略,反之就使用横条卡片的宽度计算策略。
所以我们就定义好了瀑布流布局初始化中确定布局的三个参数。
FlowView.count({ @required int crossAxisCount, IndexedFullSpanBuilder fullSpanBuilder, IndexedMainAxisExtentBuilder mainAxisExtentBuilder,})这样我们就能够计算出布局中每一个卡片的尺寸了,接下来我们只需要再确定卡片左上角的坐标,这样就可以完成卡片的布局了。
位置计算过程
对于瀑布流来说,位置计算过程会比网格布局复杂得多,我们先来分析一下从上到下布局的过程。之前我们说过,在混排瀑布流布局中会有两种卡片,横条卡片和普通卡片。我们希望卡片的布局中尽量没有间隙。
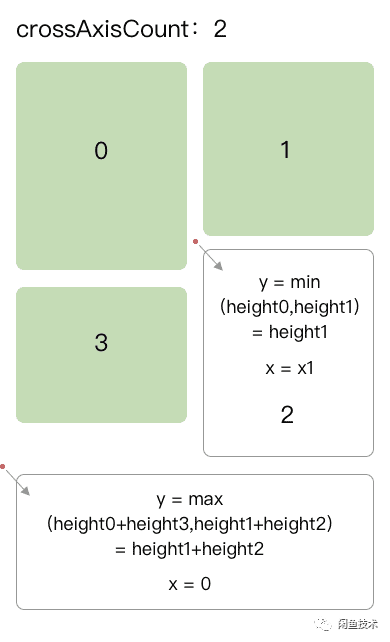
所以对于普通卡片来说,卡片的纵坐标计算过程是这样的。我们需要在已经完成布局的卡片中进行查找,找到其中纵坐标+卡片高度(即卡片 bottom 纵坐标)值最小的卡片,我们把这张卡片叫做最低卡片。然后把下一张卡片布局在最低卡片的正下方,所以下一张卡片的纵坐标就是最低卡片的纵坐标+卡片高度。因为需要布局在最低卡片的正下方,所以横坐标就直接和最低卡片的横坐标保持一致即可。
对于横条卡片来说,因为他的宽度总是和屏幕宽度一致,所以我们只需要计算它的纵坐标。它的横坐标永远是 0,他的纵坐标和普通卡片刚好相反,需要在已经完成布局的卡片中进行查找,找到其中纵坐标+卡片高度(即卡片 bottom 纵坐标)值最大的卡片,我们把这张卡片叫做最高卡片。然后把横条卡片布局在这张最高卡片下面,否则这张横条卡片会遮住其他卡片。在这里我们根据列数生成一个初始值都为 0 的纵坐标列表,每布局一个卡片就把该列的 offset 加上卡片的高度。
计算过程如图所示:
而从下到上的布局过程,瀑布流和 GridView 和 ListView 都不太一样,ListView,上一个卡片的位置可以由下一个卡片布局位置来确定,往上滚动的时候,我们只用把卡片布局在最上面的卡片上面就可以了,GridView 直接根据 index 就可以完成计算了,瀑布流比较特殊,因为卡片的布局依赖于它上面的卡片的布局信息,无法通过后一个卡片的布局信息推断出前一个卡片的布局。在这里,一般有两种处理方式。
维护一个 index 和 crossAxisIndex 一一对应的 Map 关系表
目前 RecyclerView 和 WaterFallFlow 是采用这种方式的,在用户向下滑动时,正常布局,然后记录下每张卡片属于哪一列。然后在用户向上滑动时,对即将进行布局的卡片,先通过这个关系表得到它属于哪一列,然后将它布局在这一列最上面卡片的上方,这样就可以保证卡片的布局对于用户来说始终是一致的。但是这样的方式在混排瀑布流中,需要对横条卡片做特殊处理,因为横条卡片的上一张卡片不一定和横条卡片在布局上是紧贴着的,可能会有间隙。所以我们还需要记录横条卡片跟上一张卡片的间隙,布局的时候再加上这个间隙再布局,这样才能保证正确布局。
使用分页思想,始终从上到下进行布局。
FlutterStaggeredGridView 采用的就是这种方式,而我们实现的混排瀑布流也使用了这样的思路。我们设定一个高度 PageSize,按照这个高度给整个瀑布流布局进行分页,然后维护一个 pageIndex 和 pageInfo 的对应表,每一页里记录着自己的 mainAxisOffsets,以及的 firstChildIndex。
第一页的 mainAxisOffsets 很显然是一个长度为 crossAxisCount,值为 0 的列表。然后从上到下布局时,不断更新这个 mainAxisOffsets,例如第一页在第一列布局了第一个高度为 100 的普通卡片,则 mainAxisOffsets 更新为{100,0}。然后在第二列布局了第二个高度为 150 的普通卡片,则 mainAxisOffsets 更新为{100,150}。后续我们布局了一个高度为 200 的横条卡片,则 mainAxisOffsets 更新为{350,350}。然后横条卡片和第一张卡片之间会有一个 50 的间隙,这个 mainAxisOffsets 就是下一张卡片布局的起始点。然后当有 mainAxisOffsets 都超过 PageSize 时,我们就开始分下一页。下一页的 initialOffsets 就是上一页的 mainAxisOffsets,然后再开始第二页的卡片布局。
这样当我们向上滚动时,当我们需要对上一个卡片进行布局时,我们就会从这个卡片所属的页面的第一个卡片开始布局,这样就瀑布流就始终是从上到下布局的。就能保证布局的正确性。
然后我们按照 RenderSliverGrid 的思路实现了一个 RenderSliverFlow。整个布局的关键的源码如下:
bool isFullSpan = _getIsFullSpan(index); //是否是横条卡片 double maxOffset = startOffsets.reduce(math.max); //最高卡片底部纵坐标 double minOffset = startOffsets.reduce(math.min); //最低卡片底部纵坐标 var scrollOffset = minOffset; var crossAxisIndex = startOffsets.indexOf(minOffset); //属于哪一列 int needCrossAxisCount = isFullSpan ? crossAxisCount : 1; if(isFullSpan){ scrollOffset = maxOffset; crossAxisIndex = 0; } if (reverseCrossAxis) { crossAxisIndex = crossAxisCount - needCrossAxisCount - crossAxisIndex; } var crossAxisOffset = crossAxisIndex * crossAxisStride; var mainAxisExtent = _getChildMainAxisExtent(index); return SliverFlowGeometry( scrollOffset: scrollOffset, //纵坐标 crossAxisOffset: crossAxisOffset, //横坐标 mainAxisExtent: mainAxisExtent, crossAxisExtent: crossAxisStride * needCrossAxisCount - crossAxisSpacing, isFullSpan: isFullSpan, crossAxisIndex: crossAxisIndex, );}内存回收和性能优化
回收机制
前文中我们提到过,在端侧,因为一个滚动容器中的卡片数量可能会非常大,所以我们不可能一次性对所有的卡片都进行布局和绘制,内存和运算时间都是无法接受的。
我们总是希望只布局尽可能少的卡片,我们先来分析一下最晚可以从哪个卡片开始布局。从上文我们知道,我们将整个瀑布流进行了分页,每一页包含着多个卡片,我们记录着每一页的起始 offsets,所以我们需要找可见区域最上方的卡片,把这个卡片的位置标记为 firstIndex,然后从这个卡片所属的页面的第一个卡片开始布局。然后我们再分析一下布局在什么时候结束,因为我们前面的卡片无需依赖后面的卡片,所以我们布局到可视区域之外就可以停止布局了,然后把最后一张卡片的位置标记为 lastIndex。每一次布局都会产生一个 firstIndex 和 lastIndex。
当我们往下滑动的时候,我们会判断 firstIndex 属于哪一页,这就表明这一页此时在最上方,那对这一页之前的 Page 里的卡片我们就可以进行内存回收了。往上滑动的时候,我们把 lastIndex 之后的卡片全部进行回收就好了。
性能优化
这样的分页机制虽然是能够保证布局的正确性,但是其实很多情况下,我们都需要布局缓存区以外的卡片,举个极端情况的例子,可见区域的第一张卡片是属于某一个分页的最后一张卡片,这个时候我们就不得不把这个分页里的全部卡片都进行布局。这其实会对滑动性能造成一些影响,一开始的设计 PageSize 固定为一个屏幕的高度,每一屏分一页。后来进行了性能优化,我们会根据大部分瀑布流的卡片高度得到一个分页值,尽量保证每一次分页所包含的卡片尽可能就是一行的卡片数。这样可见区域的第一张卡片往往就是这个分页的第一张卡片,这样一来就可以减少不必要的布局。
然后我们对 GridView 和 FlowView 进行了性能测试,使用脚本对两个滚动容器分别往下滚动五次,再滚动五次。最后得出性能数据,然后我们主要关注两个数据,分别是最大丢帧数和最差帧耗时,这往往就是最影响体感的两个数据。通过根据平均卡片尺寸高度动态调整分页,最后的性能数据达到了尽可能和 GridView 一致。使用同一机型,性能测试数据如下:

效果与落地
这是目前使用 FlowView 完成的一个 Demo 工程,支持了 Flutter 滚动体系里的各种功能。scrollController(滚动到 offset),reverse(逆序排列),scrollDirection(滚动方向垂直或水平滚动)等。
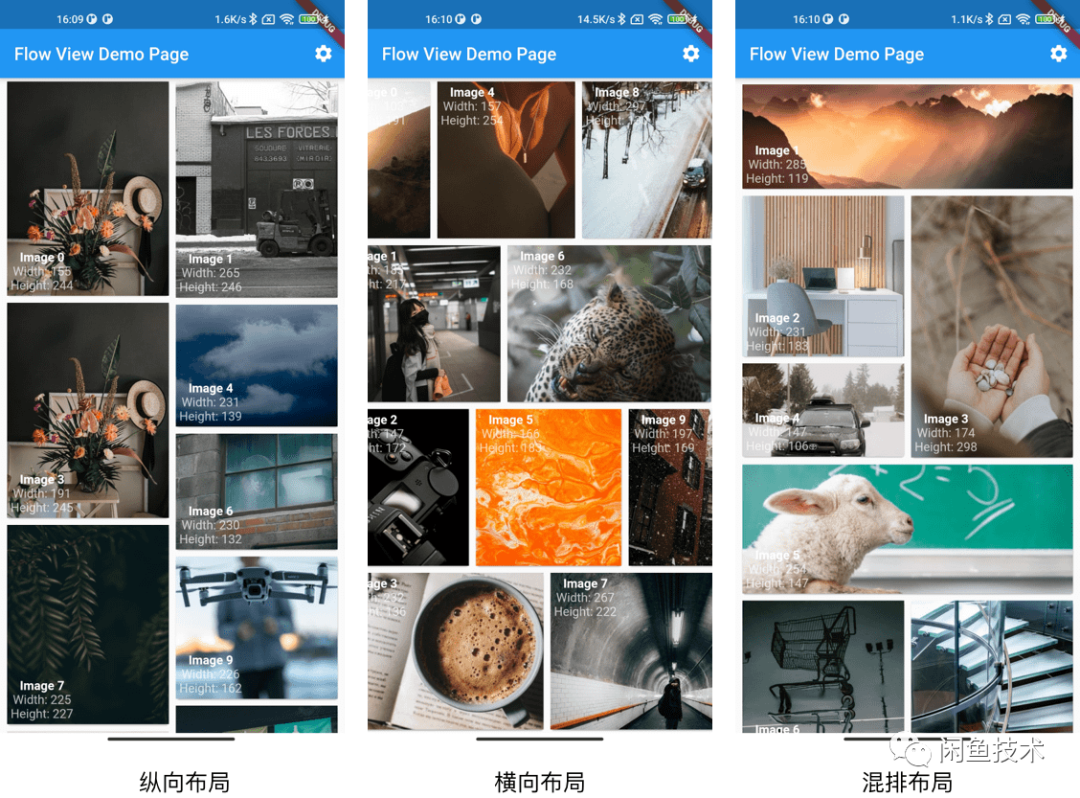
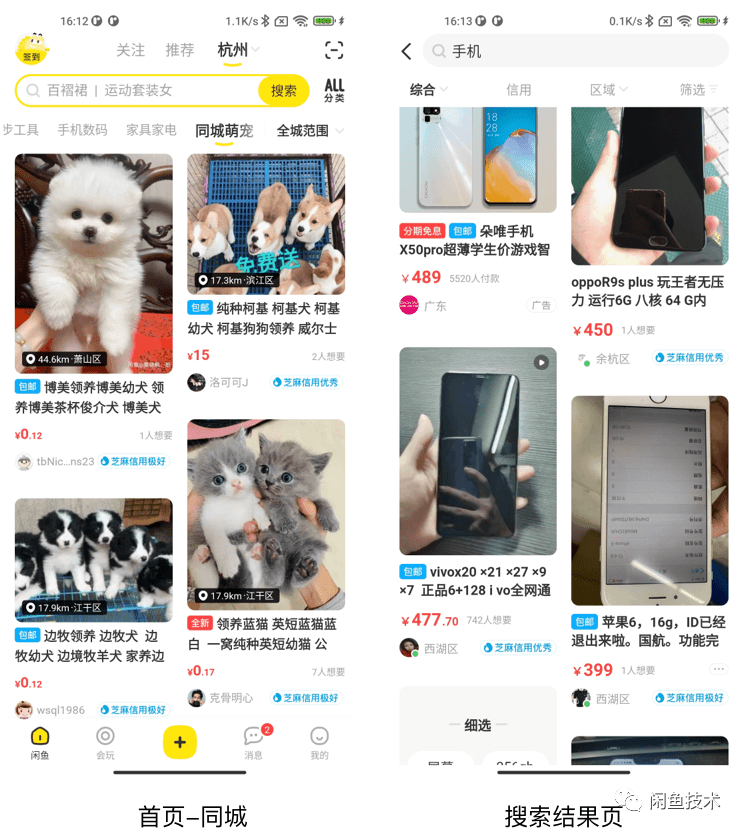
在闲鱼工程中,主要在首页、搜索结果页等进行落地。不过目前 Flutter 首页在线上只是进行了少量的灰度。
总结与展望
整个瀑布流目前结合 PowerScrollView 进行了初步落地,在整个布局的过程中,在功能上可扩展和优化的地方依然存在。
在可扩展的功能方面,未来希望可以在一个布局中完成不同列数的混排,例如一个 Sliver 中可以有一列、两列、三列、甚至六列的混排,类似于 RecyclerView 中的 GridLayoutManager。
然后在性能方面,希望之后能够在布局逻辑中进行优化,尽可能减少不必要的计算和布局。能够在滑动中提供更好的体感。
希望官方之后会对这样比较常用的布局进行支持,这样也可以给后面的布局优化带来思路。
本文转载自:闲鱼技术(ID:XYtech_Alibaba)




