到目前为止,我做过不下于 10 次关于 Go 的讲座,大多数的主题都会与“设计哲学”这样的话题有关。之所以这样,是因为我对自己的定位是 Go 语言的“传教士”,而不是“培训师”。我的出发点在于引起大家对 Go 的关注与兴趣,至于如何去一步步学习 Go 语言的语法知识,我相信兴趣是最好的老师。现今我们学习的平台足够强大,只要你真的很有兴趣,就一定能够学好 Go 语言。
Go 语言是非常简约的语言。简约的意思是少而精。Go 语言极力追求语言特性的最小化,如果某个语法特性只是少些几行代码,但对解决实际问题的难度不会产生本质的影响,那么这样的语法特性就不会被加入。Go 语言更关心的是如何解决程序员开发上的心智负担。如何减少代码出错的机会,如何更容易写出高品质的代码,是 Go 设计时极度关心的问题。
Go 语言也是非常追求自然(nature)的语言。Go 不只是提供极少的语言特性,并极力追求语言特性最自然的表达,也就是这些语法特性被设计成恰如多少人期望的那样,尽量避免惊异。事实上 Go 语言的语法特性上的争议是非常之少的。这些也让 Go 语言的入门门槛变得非常低。
今天我的话题重心是关于 Go 语言编程范式的流派问题。这仍然是关于“设计哲学”方面的。到目前为止,大家可能听过的编程范式主要如下:
- 过程式(代表:C)
- 面向对象(代表:Java、C#)
- 面向消息(代表:Erlang)
- 函数式(代表:Haskell、Erlang)
过程式编程的代表概念是过程(函数)。这是一个非常古老的流派,基本上所有语言都有过程式的影子。但是比较纯粹的过程式的主流语言比较少,通常比较古老,C 是其中最典型的代表。
面向对象编程是目前广为接受、影响极其深远的流派。面向对象有很多概念:如类、方法、属性、重载、多态(虚函数)、构造和析构、继承等等。Java、C#是其中最典型的代表。Go 语言支持面向对象,但将特性最小化。Go 语言中有结构体(类似面向对象中的类),结构体可以有方法,这就是 Go 对面向对象支持的所有内容。Go 语言的面向对象特征少得可怜。结构体是构成复合对象的基础,只要有组合,通常就由结构体,像 C 这样的过程式语言,照样有结构体。所以 Go 身上没有多少面向对象的烙印,Go 甚至反对继承,拒绝提供继承语法。
面向消息编程是个比较小众的编程流派,因为分布式与并发编程的强烈诉求而崛起。面向消息编程的主体思想是推荐基于消息而不是基于锁和共享内存进行并发编程。Erlang 语言是面向消息编程的代表。Go 语言中有面向消息的影子。因为 Go 语言中有 channel,可以让执行体(goroutine)之间相互发送消息。但 channel 只是 Go 语言的基础语法特性,Go 并没有杜绝锁和共享内存,所以它并不能算面向消息编程流派。
函数式编程也是一个小众的流派,尽管历史非常悠久。函数式编程中有些概念如:闭包、柯里化、变量不可变等。Haskell、Erlang 都是这个流派的代表。函数式编程之所以小众,个人认为最重要的原因,是理论基础不广为人知。我们缺乏面向函数式编程的数据结构学。因为变量不可变,数据结构学需要用完全不同思维方式来表达。比如在传统命令式的编程方式中,数组是最简单的基础数据结构,但函数式编程中,数组这样的数据结构很难提供(修改数组的一个元素成本太高,Erlang 语言中数组这个数据结构很晚才引入,用 tree 来模拟数组)。Go 语言除了支持闭包外,没有太多函数式的影子。
Go 语言有以上每一流派的影子,但都只是把这些流派的最基础的概念吸收,这些特性很基础,很难作为一个流派的关键特征来看。所以从编程范式上来说,个人认为 Go 语言不属于以上任何流派。如果非要说一个流派,Go 语言类似 C++,应该算“多范式”流派的。C++ 是主流语言中,几乎是唯一一门大力宣扬多范式编程理念的语言。C++ 主要支持的编程范式是过程式编程、面向对象编程、泛型编程(我们上面没有把泛型编程列入讨论的流派之中)。C++ 对这些流派的主要特性支持都很完整,说“多范式”名副其实。但 Go 不一样的是,每个流派的特性支持都很基础,这些特性只能称之为功能,并没有形成范式。
Go 语言在吸收这些流派精华的基础上,开创了自己独特的编程风格:一种基于连接与组合的语言。
连接,指的是组件的耦合方式,也就是组件是如何被串联起来的。组合,是形成复合对象的基础。连接与组合都是语言中非常平凡的概念,但 Go 语言恰恰是在平凡之中见神奇。
让我们从 Unix 谈起。Go 语言与 Unix、C 语言有着极深的渊源。Go 语言的领袖们参与甚至主导了 Unix 和 C 语言的设计。Ken Thompson 甚至算得上 Unix 和 C 语言的鼻祖。Go 语言亦深受 Unix 和 C 语言的设计哲学影响。
在 Unix 世界里,组件就是应用程序(app),每个 app 可大体抽象为:
- 输入:stdin(标准输入), params(命令行参数)
- 输出:stdout(标准输出)
- 协议:text (data stream)
不同的应用程序(app)如何连接?答案是:管道(pipeline)。在 Unix 世界中大家对这样的东西已经很熟悉了:
app1 params1 | app2 params2
通过管道(pipeline),可以将一个应用程序的输出(stdout)转换为另一个应用程序的输入(stdin)。更为神奇的一点,是这些应用程序是并行执行的。app1 每产生一段输出,立即会被 app2 所处理。所以管道(pipeline)称得上是最古老,同时也是极其优秀的并行设施,简单而强大。
需要注意的是,Unix 世界中不同应用程序直接是松散耦合的。上游 app 的输出是 xml 还是 json,下游 app 需要知晓,但并无任何强制的约束。同一输出,不同的下游 app,对协议的理解甚至都可能并不相同。例如,上游 app 输出一段 xml 文本,对于某个下游 app 来说,是一颗 dom 树,但对 linecount 程序来说只是一个多行的文本,对于英文单词词频统计程序来说,是一篇英文文章。
为了方便理解,我们先尝试在 Go 语言中模拟整个 Unix 的管道(pipeline)机制。首先是应用程序(app),我们抽象为:
func(in io.Reader, out io.Writer, args []string)
我们按下图来对应 Unix 与 Go 代码的关系:
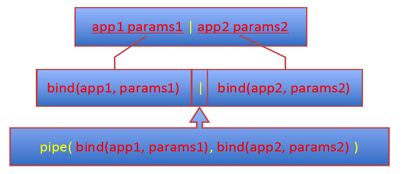
也就是说,Unix 中的
app1 params1 | app2 params2
对应 Go 语言中是:
pipe( bind(app1, params1), bind(app2, params2) )
其中,bind 函数实现如下:
func bind(
app func(in io.Reader, out io.Writer, args []string),
args []string
) func(in io.Reader, out io.Writer) {
return func(in io.Reader, out io.Writer) {
app(in, out, args)
}
}
要理解 bind 函数,需要先理解“闭包”。Go 语言中,应用程序以一个闭包的形式体现。如果你熟悉函数式编程,不难发现,这个 bind 函数其实就是所谓的柯里化(currying)。
pipe 函数如下:
func pipe(
app1 func(in io.Reader, out io.Writer),
app2 func(in io.Reader, out io.Writer)
) func(in io.Reader, out io.Writer) {
return func(in io.Reader, out io.Writer) {
pr, pw := io.Pipe()
defer pw.Close()
go func() {
defer pr.Close()
app2(pr, out)
}()
app1(in, pw)
}
}
要理解 pipe 函数,除了“闭包”外,需要知晓 defer 关键字和 goroutine(go 关键字)。defer 语句会在函数退出时执行(无论是否发生了异常),通常用于资源的清理操作(比如关闭文件句柄等)。有了 defer 语句,Go 语言中的错误处理代码显得非常优雅。在一个正常的函数调用前加上 go 关键字,就会使得该函数在新的 goroutine 中并行执行。理解了这些背景,这个 pipe 函数不难理解,无非是:先创建一个管道,让 app1 读入数据(in),并向管道的写入端(pw)输出,启动一个新 goroutine,让 app2 从管道的读入端读取数据,并将处理结果输出(out)。这样得到的 app 就是 app1 和 app2 的组合了。
你甚至可以对多个 app 进行组合:
func pipe(apps ...func(in io.Reader, out io.Writer)) func(in io.Reader, out io.Writer) {
if len(apps) == 0 { return nil }
app := apps[0]
for i := 1; i < len(apps); i++ {
app1, app2 := app, apps[i]
app = func(in io.Reader, out io.Writer) {
pr, pw := io.Pipe()
defer pw.Close()
go func() {
defer pr.Close()
app2(pr, out)
}()
app1(in, pw)
}
}
return app
}
我们举个比较实际的例子,假设我们有 2 个应用程序 tar(打包)、gzip(压缩):
-
func tar(io.Reader, out io.Writer, files []string)
- ```
func gzip(in io.Reader, out io.Writer)
那么打包并压缩的代码是:
pipe( bind(tar, files), gzip )(nil, out)
通过对管道(pipeline)的模拟我们可以看出,Go 语言对并行支持是非常强大的,这主要得益于 Go 的轻量级进程(goroutine)。
为了体现 Go 语言在连接方式上的特别之处,我准备拿经典的面向对象设计案例(故事名不妨叫 Shape)来比较。
在 Java 中,Shape 这个故事是这样的:
首先定义 Shape 接口:
interface Shape {
double area(); // 为简化,我们只是求面积
}
然后提供各种具体的 Shape 类型:
class Circle implement Shape {
private double x, y, r;
public double area() { return math.Pi/2 * this.r * this.r; }
}
class Rect implement Shape {
private double x, y, w, h;
public double area() { return this.w * this.h; }
}
最后,我们写一个算法,求一系列 Shape 的总面积:
class Algorithm {
static public double area(Shape... shapes) {
double result = 0;
for (Shape shape: shapes) {
result += shape.area();
}
return result;
}
}
在 Java 中,组件 Circle、Rect、Algorithm.area 之间,是通过 Shape 接口串联的。比较麻烦的是,Circle、Rect 都需要显式地声明自己实现了 Shape 这个契约,这加深了组件间的耦合。
我们来看看 Go 语言怎么做:
首先,我们定义各种具体的 Shape 类型:
type Circle struct {
x, y, r float64
}
func (this *Circle) Area() float64 {
return math.Pi/2 * this.r * this.r
}
type Rect struct {
x, y, w, h float64
}
func (this *Rect) Area() float64 {
return this.w * this.h
}
然后我们实现求多个 Shape 总面积的 Area 组件:
type Shape interface {
Area() float64
}
func Area(shapes ...Shape) float64 {
var result float64
for _, shape := range shapes {
result += shape.Area()
}
return result
}
看到这里,你可能误解我在做代码交换的游戏 —— 看起来和 Java 版本的差别只是 Shape 这个 interface 挪了下位置。但这实际上是思维方式的变化。为了凸显这种变化,我把 Area 组件的代码改变下:
func Area(shapes ...interface{ Area() float64 }) float64 {
var result float64
for _, shape := range shapes {
result += shape.Area()
}
return result
}
现在和 Java 版本的差异就很显著了:Shape 接口不见了!!!再独立去看看 Circle、Rect、Area 组件,每个组件都很独立,看不到任何额外的耦合代码。但神奇之处在于他们确实可以工作在一起:
area := Area( &Rect{w: 20, h: 30}, &Circle{r: 20} )
fmt.Println(“area:”, area)
我们再回头看看 Unix 的组件的连接方式,不难发现 Go 和 Unix 类似的地方:组件之间的连接是松散耦合的,彼此之间有最自然的独立性。但 Go 和 Unix 也有不同的地方,Unix 的契约基于文本流来表达,可能出现连接错误(比如上游输出 xml 文本,但下游期望是 json),在运行时才发现。但 Go 语言是静态编译语言,组件间的协议通过 interface 描述,并在编译期进行检查,如果不合适直接编译失败,如:
area := Area( &Rect{w: 20, h: 30}, &Circle{r: 20}, &Foo{} )
fmt.Println(“area:”, area)
如果上面的 Foo 类型没有 Area 方法,则编译不能通过。这种编译期检查是代码品质重要保障。作为对比的是,动态语言如 Python、PHP 等,可以很容易做到类似 Go 语言的松散耦合方式,但是由于没有强制的契约检查,如果误传一个对象实例,就可能出现各种非预期的行为,包括运行时崩溃。
一些面向对象语言的拥护者可能会认为,Java 这种明确指定 implement 的接口,使得程序更规范、在工程管理上更容易受控。但我个人持完全相反的观点,认为这完全是方向性的错误。原因是这种接口定义方式违背了事物的因果关系。举个例子,假设我们实现了一个 File 类,它有 4 个方法:Read、Write、Seek、Close。那么 File 类需要从哪些接口继承呢?Reader(注:我这里是按 Go 语言风格来命名接口,在 Java 中可能会倾向于 Readable,C++ 中则可能会倾向于 IRead 这样的名字)?Writer?Seeker?Closer?ReadWriter?ReadWriteSeeker?ReadWriteSeekCloser?脱离实际需求,这个问题并无正确答案。要满足所有可能的用况,File 类最好从所有这些接口继承,总共需要继承的接口达 24-1 = 15 种。这很恐怖,因为当某个类有 10 个公开方法的时候,需要继承的接口达 210-1 = 1023 种之多!
Go 语言对组件连接方式的调整是革命性的。可以预期的是,它必将慢慢影响目前各种主流的静态类型语言,逐步从错误的方向上修正过来。




