
眼下,在金融行业的数字化浪潮中,大模型技术的崛起为创新提供了新的动力。其通过深度学习和大数据分析,正在重塑风险评估、客户服务和投资策略的方式,助力金融机构在激烈竞争中脱颖而出。然而,这一转型之路并非一帆风顺,如何平衡应用成本与安全风险成为了行业必须面对的挑战。
本文中,中关村科金资深 AI 产品总监曹阳探讨了大模型如何在金融业务中发挥关键作用,并分享自迭代知识助手的创新理念,揭示多模态数据解析与全链路调优工具在提升业务效率方面的重要性。
以下内容源自曹阳在 2024 FCon 全球金融科技大会的演讲(经 InfoQ 进行不改变原意的编辑整理):
大模型在金融领域的应用与挑战
今天我将介绍中关村科金在大模型技术应用,尤其是在金融领域的一些实践和经验。我们相信,随着大模型技术在价格和效果上的持续进步,应用成本将降低,场景将扩展。预计在 2024 年开始的未来一到两年内,大模型在金融领域的应用将快速增长。
金融行业作为数字化转型的先行者,借助大模型技术的引入,将在个性化服务、用户体验、高效客户价值传递以及合规安全、智能决策等方面迎来显著提升。这些变革将对金融行业产生深远的影响,尤其是在客服、营销和基于知识的应用等方向,这些领域在风险、成本和收益方面都是企业可以相对控制和预期的重点。
在大模型应用过程中,我们面临一些关键的考量和挑战。首先,我们需要灵活兼容国内多家厂商快速发布的新版本开源大模型,持续评估不同场景下适合应用的模型,考虑其版本、参数量和效果,同时兼顾企业成本。例如,大参数量模型可能需要高性能硬件支持,导致成本显著上升。
我们还需采用组合式创新方法,将某些效率较低的大模型与小模型结合,以实现优势互补。在传统冷启动情况下,若数据不足,我们需要通过人机协同保障初始落地效果。
同时,在不同场景下考虑经济性,包括时间和金钱的经济性。在金融领域,安全性和可信度至关重要,金融机构必须谨慎对待任何可能引发风险的表述,如“一定可以达到”。因此,在模型生成、预训练及后续小模型质检过程中,我们需保持谨慎。
随着大算力、强算法和大数据的发展,未来可能会推动科技平权,这将涵盖知识的平权、决策的平权和服务体验的平权,预计将对社会产生整体性变革。
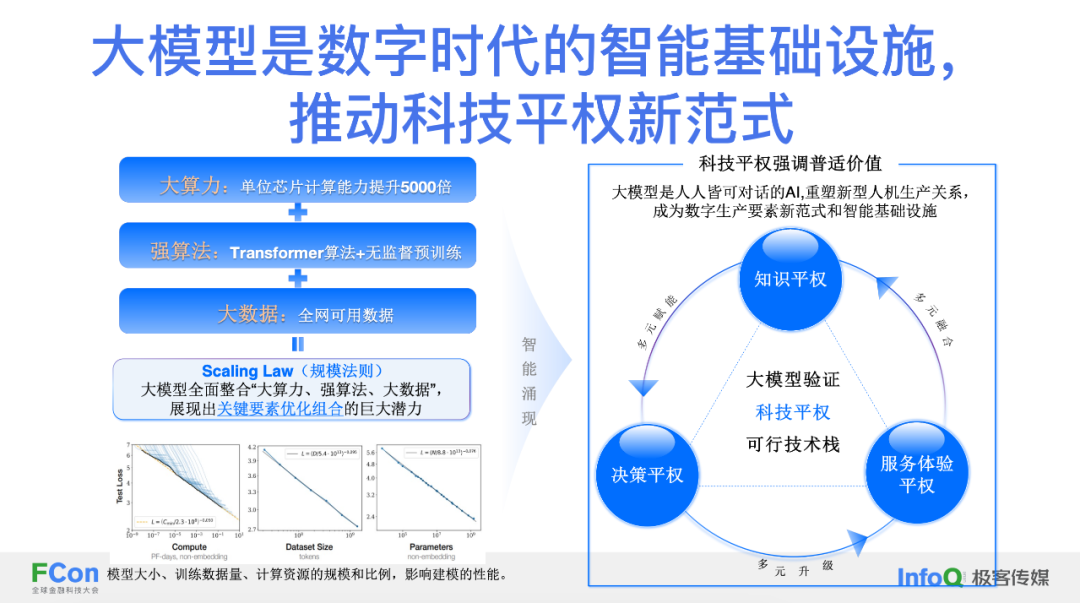
⼤模型与企业知识管理的未来
大模型内部存储了丰富的世界语言和知识,类似于一个知识库,包含事实性知识(例如,北京是中国的首都)和推理性知识(例如,姚明的妻子是叶莉)。此外,大模型还能够处理序列性、指令性和逻辑运算型的信息,这些都能通过参数表示形成记忆。
从人工智能的发展历程来看,我们最初关注词义、语句和语义的理解,随后转向事实的理解,再到过程和目标的理解,甚至心智或灵魂的探讨。目前,我们可能正处于从事实理解向过程理解的转变阶段,这一过程为大模型的应用奠定了基础。
在企业应用方面,大模型能够准确处理事实性知识,使其在知识应用中展现出较高的容错性和专业性,成为企业知识问答的优选方案,尤其是在金融领域。由于企业通常对直接面向客户的大模型应用持谨慎态度,考虑到潜在风险,因此,在企业内部应用大模型,再逐步扩展到外部,可能是更稳妥的策略。
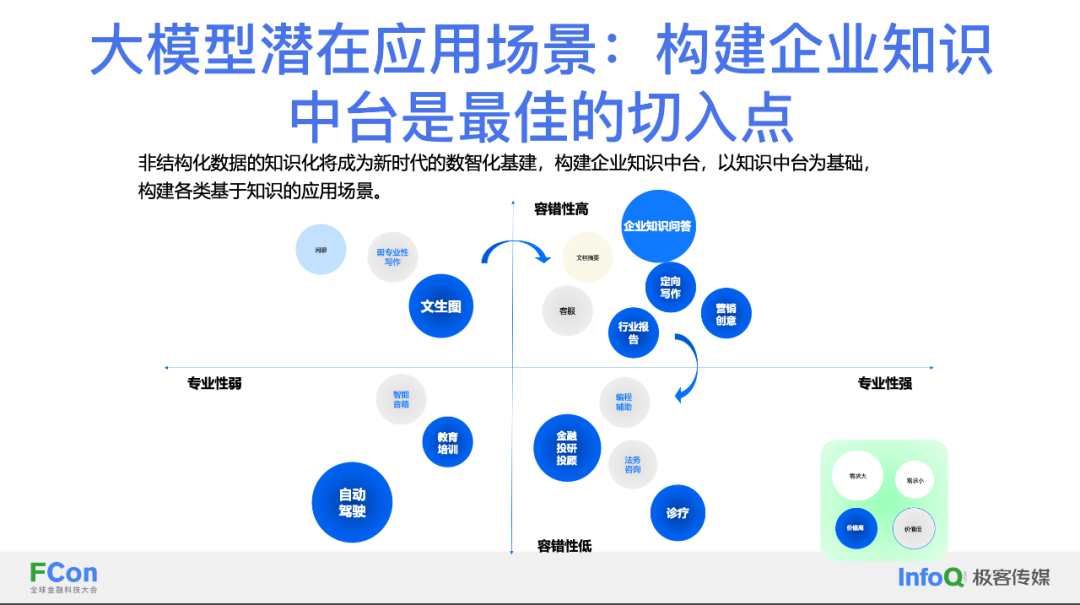
随着互联网的发展,数据量正以指数级增长,给企业带来了许多挑战,特别是内部文档的激增。在这样的背景下,如何高效处理和利用数据,识别有效信息,并提升知识管理的效率与效果,成为关键。大模型的应用可以帮助企业从海量数据中提取有价值的信息,解决知识应用难题。
总体技术框架:三个步骤、两个算法、⼀个平台
在传统应用中,一些常用的工具比如 Wiki、飞书和云文档虽然便利,但在高效知识应用方面仍有提升空间。结合大模型和 RAG 技术,我们期待实现更优的知识应用效果。我们的技术框架主要包括三个步骤、两个算法和一个平台。
三个步骤:提升知识利⽤效率与⾃动更新
涵盖“学、用、教”三个步骤,目的在于提高知识利用效率并辅助知识自动更新。
学:大模型将学习显性知识,涵盖多模态数据如文档、音视频和图片。
用:在应用过程中,专家经验将通过配置或使用记录下来,并通过提示词或调优过程让模型学习这些知识。
教:从用户的行为日志中提取隐性知识,促进模型学习,持续提升使用效果。
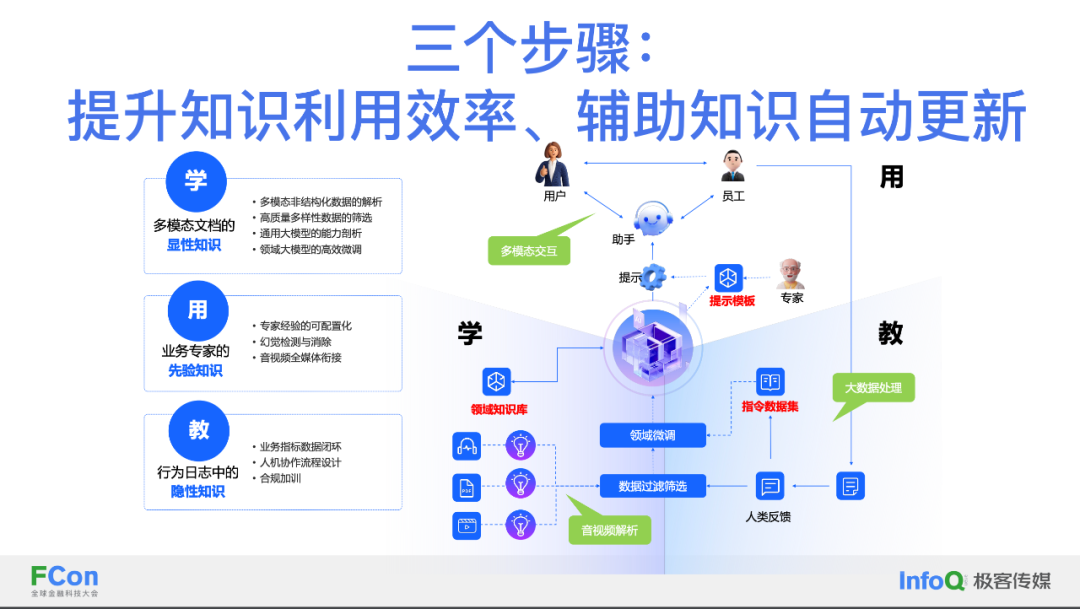
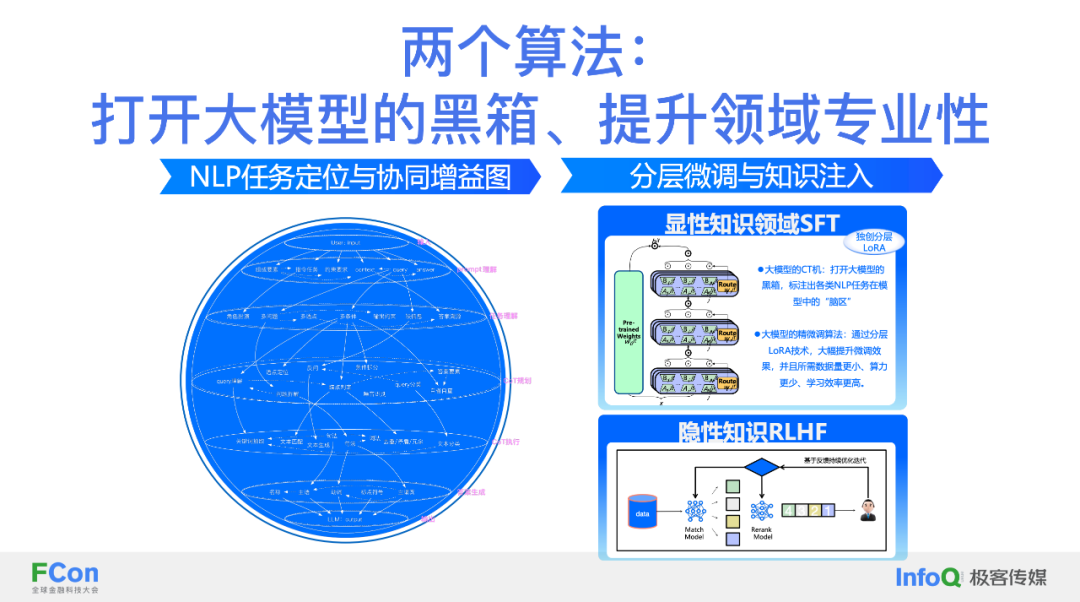
两个算法: 打开⼤模型的⿊箱与提升领域专业性
定位和微调,旨在打开大模型的黑箱并提升领域专业性。
定位:了识别模型的能力区间,例如,了解百川 14B 模型的 40 层神经网络中每层的功能,以评估哪些层在实体识别或信息抽取中发挥关键作用。
微调:通过隐性反馈对模型特定层次进行 LoRA 微调,持续提升模型在实际使用中的表现。
基于⼤模型的企业智能,数据是核⼼资产
在企业智能领域,数据是核心资产,而大模型的应用能够优化这些资产的利用。我们构建了自迭代的知识助手基座,也称为知识引擎基座,整合领域分层 LoRA 微调、RAG 技术以及隐性知识的强化反馈学习。
我们的核心目标是提升客户价值。通过大模型,知识源的覆盖范围将显著扩大,预计可以提升 10 倍以上。传统企业知识库检索通常局限于标题或文本内容的关键词匹配,而我们可以实现对文档、数据库和音视频的全域检索,深入具体内容。
运营成本也将大幅降低,预计可降低 85% 以上。同时,对长尾知识的覆盖能力将提升 10 倍以上,确保不常查询的知识也能有效管理和利用。此外,知识获取的效率也将显著提升。
知识助⼿带来的应⽤新范式, 打通“最后⼀公⾥”
我们的基础产品形态包括智能知识库管理、文档和数据库问答、全域搜索问答及内容抽取。系统能够自动判断在文档、数据库或网络上检索答案。
在大模型应用中,RAG 技术是不可或缺的环节。尽管多模态大模型尚未实现突破,我们仍需依赖 RAG 的 Pipeline 过程,并优化这一过程,以提供更优的输入,获取更准确的输出。
我们将针对不同文档类型和内容进行差异化处理,包括版式识别和小模型微调,以提升特定场景下的应用效果。例如,针对金融财报的表格,我们会解决多跨页的处理问题,以提升模型的表现。
核心关注点在于解析能力和切片构建。以保险条款为例,我们需要构建元数据,让大模型在检索时能识别保险重疾的名称,并通过 Agent 方案获取这些名称。我们将根据不同场景和行业制定差异化方案,提升整体效果。
在客户落地方面,我们会构建完整的知识引擎。市面上的大模型应用开发平台,主要针对通用场景,而我们更专注于与 RAG 相关的应用。我们首先进行高质量的知识管理,允许用户导入相关知识,并基于切片维度进行管理,尤其是在特殊场景下(如保险条款问答)进行快速优化。我们还将构建父子切片维度,结合 OCR 和文档解析能力,对常见文档类型进行高频信息抽取,创建分级索引以实现多维检索,满足企业应用中的多样需求。同时,我们将进行多知识库的管理,确保权限隔离,以适应不同部门和职级员工的数据保护需求。
基于知识助手基座的大模型金融应用实践
我们推出了大模型应用开发平台,支持我们的知识引擎,进一步支撑各类金融应用,包括投顾助手、培训助手、研报助手和质检助手。
智能投顾助手:满足快速增长的需求
应用智能投顾助手是金融行业发展的必然趋势。随着财富管理业务的扩展,投顾人员需要在有限的服务时间内满足更多客户的需求。我们致力于在客户经理的各个服务阶段提供支持,从获客到资产配置,再到个人学习,助力投顾人员提升工作效率。
为实现这一目标,我们融合外部资源,通过知识引擎和大模型应用开发平台构建差异化的应用场景。同时,整合客户、公司产品和员工绩效数据,提供精准个性化服务,帮助客户经理更好地服务客户。
AI 财富助手与智能培训
企业重视金融培训,以实现标准化服务并积累统一的员工画像。在某些项目中,我们的系统自动生成优化投资组合和营销话术,显著提升客户服务满意度(98%)和问题解决率(95%)。
我们的产品面向企业客户(B2B),在回答深度和细致性上明显优于市场上的竞争产品,如知小宝和平安小安。通过基于研报解析的大模型,我们能够提供深入的市场和行业分析,支持投资组合营销和基金产品营销。
智能陪练与知识管理
我们构建的智能陪练系统利用大模型技术,为培训过程提供个性化支持。培训老师可以自定义目标,大模型则生成有针对性的题目和流程,形成闭环反馈。通过小模型处理实时高频场景,而大模型则确保语义分析的全面性。
此外,我们的知识引擎结合 RAG 技术,支持智能问答和对练,帮助员工在重点场景上提升能力,支持语音输入及错题分析。
研报与报告写作
我们的投研助手为市场分析和报告解读提供支持,结合客户需求、市场趋势和产品信息进行深入分析。我们采用定向写作方法,根据用户输入自动生成尽调和投研报告,提高写作效率并减少人为错误。
合规助手:确保安全与合规
在金融领域,合规性至关重要。我们的合规助手结合大模型和小模型,对多模态内容进行提取和质检。系统生成的质检要点可迅速响应客户需求,提升合规检测效率,并根据历史数据进行持续优化。
嘉宾介绍
曹阳,中关村科金资深 AI 产品总监,负责大模型应用产品设计。拥有超过 10 年的 ToB 产品经验,曾任职于阿里、京东、字节跳动、Shopee 等公司,主导多个智能客服产品,对 NLP、智能客服、CRM 相关的技术、产品应用、商业化有着丰富经验。




