
近日,OpenAI 发布的视频生成模型 Sora 成为全球焦点。与以往只能生成几秒钟视频的模型不同,Sora 可生成长达 60 秒的高清视频。
英伟达高级研究科学家 Jim Fan 断言,Sora 是一个数据驱动的物理引擎,是一个可学习的模拟器,或“世界模型”。OpenAI 也声称 Sora 是“扩展视频生成模型是构建物理世界通用模拟器的一条可行之路”。这些说法让很多普通人感到非常恐慌,担心这代表了人工智能已经有能力理解人类真实世界,因此这或许代表着人类末日的开始。
而图灵奖得主 Yann LeCun,作为一位“世界模型”的倡导者,他认为 OpenAI 的 Sora 并不理解物理世界,今天他更是直接说 Sora 对“世界模型”的实现方式,注定是死路一条。

Yann LeCun 火力全开
之前, OpenAI Sora 研发成员 Aditya Ramesh 发布了一个关于一只蚂蚁“在蚁巢内部移动的视角镜头”的视频,但视频里面的蚂蚁只有四条腿。
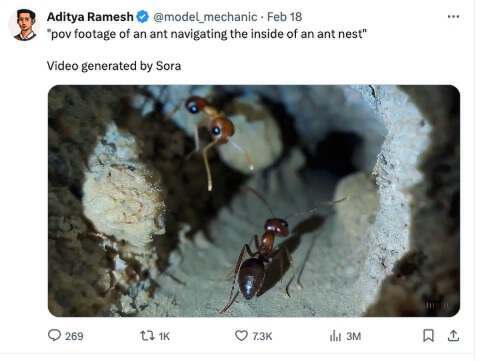
Yann LeCun 随后对其喊话:“Aditya,蚂蚁难道不是有 6 条腿吗?”“作为曾在我实验室待过的学生,我担保他知道蚂蚁有 6 条腿!”
4 条腿的蚂蚁的确不符合真实世界的实际情况,Yann LeCun 也认为根据提示词生成看似真实的视频绝不代表系统真的理解物理世界。
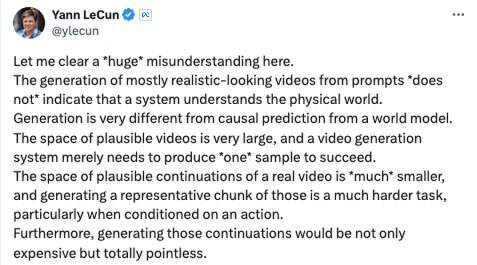
这样的图像生成跟世界模型的因果预测间仍然存在重大差异。或者说,让视频内容看似合理的空间非常大,视频生成系统只需生成其中“一种”样本即可算作成功。但真实视频的合理连续空间要“小得多”,而且生成其中的代表性图块更是一项极为困难的任务,在涉及各种动作的情况下更是如此。
此外,他还强调,这种连续生成不仅成本高昂,而且完全没有现实意义。
Visualization of Slicing Video Temporal Data — Source: kitasenjudesign
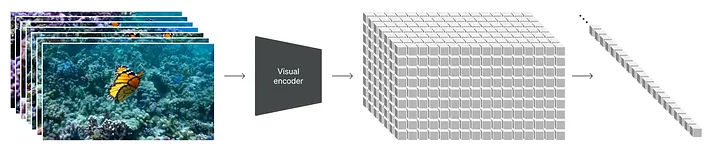
Visualization of Spacetime Patching (Processing) — Credit: OpenAI (Sora)
在今天的推文中,他更是直言 Sora 这种通过生成像素来对真实世界建模“不仅是种浪费,而且注定将要失败”,如同现在已经被基本放弃的“合成分析”技术一样。
Yann LeCun 解释说,几十年前,机器学习领域曾经就生成式方法与判断式分类方法的优劣对比展开过一场大辩论。数学家 Vapnik 等机器学习理论研究者明确反对生成式方法,认为生成模型的训练要比分类模型更困难(从样本复杂性角度出发)。总而言之,整个计算机视觉领域普遍认定像素的生成应该从解释潜在变量入手。毕竟在推理过程中,人类就是在根据观察到的像素推断出反映规律的潜在变量。正确的推理方法还涉及优化部分:比如使用对象的 3D 模型并尝试找到能够重现图像的姿态参数。遗憾的是,这个路子一直没能彻底走通,而且速度非常缓慢。
后来,有些人选择了贝叶斯路线,尝试使用贝叶斯推理来推断潜在变量(例如使用变分近似及/或采样)。非参数贝叶斯与潜在狄利克雷分配都在某种程度上主导过文本建模,有些人开始勇敢尝试借此识别图像中的具体对象。但这同样是一场彻头彻尾的失败!
Yann LeCun 认为,如果现在的目标是训练出用于识别或规划真实世界的模型,那么在像素层面进行预测肯定不是什么好主意。
只能说生成技术恰好适用于文本,因为文本内容属于离散的、数量有限的符号。在这种情况下,预测过程中的不确定性更容易处理。相比之下,对高维连续感官输入中的不确定性进行预测则非常困难。
正因为如此,依靠感官输入的生成模型注定将会失败。
Yann LeCun 认为的更好的办法是什么?
作为人类,我们对周遭世界的了解和大部分知识(特别是在童年时代)主要是依靠观察而来。以牛顿运动定律为例,即使是未经任何引导的幼儿或者小动物,也会在多次触碰并观察之后意识到,一切抛掷的物体终将落向地面。是的,只需一点观察,而非耗费几个小时的指导或者阅读上千本学术著作。我们内心深处的世界模型(基于世界心理模型的情境理解能力)完全可以准确预测结果,而且效率非常高。
所以 Yann LeCun 认为实现“世界模型”的方式,应该是让机器智能像人类般学习、建立起周遭世界的内部模型,从而高效学习、适应并制定计划以完成种种复杂的任务。
这也是他提出的 JEPA(Joint Embedding Predictive Architecture,联合嵌入预测架构)的核心特点所在:它并不是在“生成”,而是在表示空间中进行预测。
在他前几天发布的推文结尾,他又给大家安利了一遍 JEPA 的论文和他们的试验结果表:

截图来源:https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
备受瞩目的视频 JEPA
V-JEPA 是一种非生成模型,通过预测抽象表示空间中视频的缺失/遮蔽部分来进行学习。这种方法与图像联合嵌入预测架构(I-JEPA)对图像抽象表示的比较(而非直接比较像素本身)有异曲同工之妙。不同于尝试填充每个缺失像素的生成式方法,V-JEPA 能够灵活丢弃各种不可预测的信息,从而将训练与采样效率提高 1.5 至 6 倍。
由于 V-JEPA 采用自监督学习方法,因此可以纯依靠未经标注的数据进行预训练。这些标签仅在预训练之后被用于保证模型能够适应特定任务。事实证明,这种类型的架构比以往模型更加高效,不仅训练需要的标注示例更少、在学习未标注数据方面投入的总工作量也更低。借助 V-JEPA,Meta 在这两项指标上均迎来了改进。
使用 V-JEPA,研究团队遮蔽掉了视频中的大部分内容,借此让模型仅能观察到小部分上下文。之后,再要求预测器填补缺失的空白——请注意,填补过程并非根据实际像素,而是依托表示空间中更抽象的内容描述。
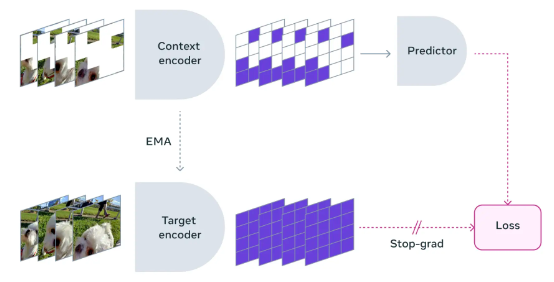
在学习潜在空间中,V-JEPA 通过预测被遮蔽的时空区域来训练视觉编码器。
遮蔽方法
V-JEPA 的这种理解并非来自对某一特定操作类型的训练;相反,它是在一系列视频之上完成了自监督训练,并借此掌握了大量关于真实世界运行规律的知识。
研究团队还认真设计了遮蔽策略——如果不遮挡视频中的大块区域,而是随机在各处覆盖内容,那么任务就会变得过于简单,导致模型学不到真实世界中的任何复杂规律。
另外需要注意的是,在大多数视频中,对象随时间推移的变化其实相对缓慢。如果只遮蔽特定时刻下视频中的某个部分,而模型仍能观察到紧随其前/其后的内容,任务同样会变得过于简单,导致其无法学习到有趣的知识。因此,研究团队采取一种方法,在空间与时间两个维度上遮蔽视频的部分内容,强迫模型学习并加深对于场景逻辑的理解。
保证在抽象表示空间中进行预测同样非常重要,这样模型才能专注于实际视频内容所反映出的更高级别概念信息,而忽略掉那些对于下游任务意义不大的各类细节。举例来说,如果视频画面中是一棵树,那么就并不需要关心每片叶子的细小运动。
高效预测
V-JEPA 是首个擅长“冻结评估”的视频模型,换句话说,模型的编码器与预测器均可实现自监督预训练,研究人员不必再做具体操作。想让模型掌握一项新技能,只需要额外训练一个小型轻量级专业层、或者在其上训练一个小型网络,整个过程更加高效快速。
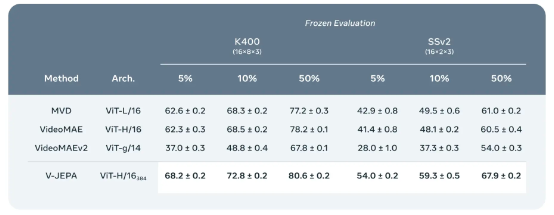
少样本冻结评估:将 V-JEPA 与 Kinetics-400 和 Something-Something-v2 等其他视频模型中的冻结评估进行比较,这里我们改变了每套数据集上可用于训练注意力探针的标注示例百分比。我们在几种少样本设置中进行探针训练:分别对应训练集中 5%、10%和 50%的数据,并在每种情况下进行三轮随机比较以获得更稳健的指标,也就是分别对每套模型进行 9 次不同的评估实验。表中列出了官方验证的 K400 与 SSv2 验证集的平均值与标准差。V-JEPA 的标记效率的确高于其他模型,而且可用标注示例数量越少,V-JEPA 相较于其他模型的性能优势也越明显。
以往的生成式模型要求我们进行全面微调,就是说在模型预训练完成之后,如果希望模型能够真正掌握对细粒度动作的识别能力、利用它来处理实际任务,还需要更新所有模型中的参数或者权重。之后,该模型总体上只能执行一类特定任务,而不再适用于其他任务类型。
如果想要引导模型学会执行多种任务,则需要提供不同的数据,并针对新任务对整个模型进行特化。而正如 Meta 在研究中所演示的那样,使用 V-JEPA,我们可以在没有任何标注数据的前提下对模型进行一次预训练、修复相应问题,然后重复利用模型中的相同部分处理多种不同任务,例如动作分类、识别细粒度对象交互及活动定位等。
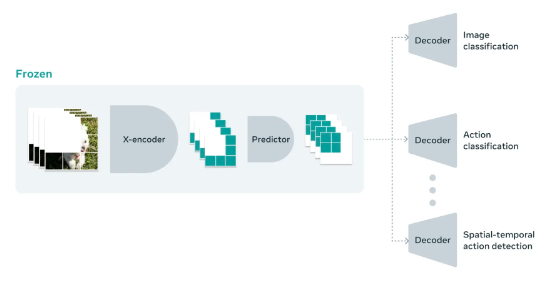
V-JEPA 是一种从视频中学习表示的自监督方法,适用于各类下游图像及视频处理任务,且无需调整模型参数。V-JEPA 在图像分类、动作分类及时空动作检测等任务的冻结评估方面,优于以往的视频表示学习方法。
虽然 V-JEPA 中的“V”代表视频,但并不是说它的适用范围就仅限于视频内容。后续 Meta 还将采用其他多模态方法,并认真考虑将音频与视觉效果结合起来。
虽然目前 V-JEPA 还只能在较短的时间维度上发挥作用——比如在不超过 10 秒的视频片段中准确识别不同对象的行为。但 Meta 接下来的另一项研究重点,在于如何调整模型以在更长的时间范围内实现准确预测。
目前的结果证明,Meta 目前可以直接用视频数据训练 JEPA 模型,而不再需要大量监督和介入。它会像婴儿般从视频中学习,凭借被动观察世界来学习有助于理解内容上下文的背景知识。这样,只须配合少量标注数据,就能让模型快速获得执行新任务、识别各种动作的能力。
参考链接:
https://twitter.com/ylecun/status/1759486703696318935
https://twitter.com/ylecun/status/1758740106955952191
https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/




