图神经网络已经成为分析图结构数据的标准框架。腾讯 AI Lab 正努力探索更加快速、鲁棒、具有可解释性深度图学习方法,以及在生物制药、社交网络分析上的应用。
本文即是其中的一项成果,研究用图信息瓶颈理论识别图结构数据中关键子图,论文已被 ICLR-2021 接收。论文题目是 Graph Information Bottleneck for Subgraph Recognition。该方法能有效识别关键子图,同时滤除噪声与无关结构。该方法在图数据解释,提升图分类结果,以及图去噪等任务上取得了较好的效果。
论文核心信息摘录如下:
一、问题提出
近年来,图神经网络的提出使得图学习领域得到了巨大的发展。在图分类和图数据预测等任务中,图神经网络首先在节点层面上聚合邻居信息得到节点表征,然后通过 readout 函数将所有的节点表征转化为图数据表征。此外,diffpool 等方法通过利用图数据的层级结构,将不规则的图结构数据通过可学习的 pooling 方法得到图数据的表征。虽然现有的方法在图分类等任务上取得了较好的效果,但是由于利用了所有节点的信息,因此容易受到图结构数据中冗余、噪声信息的影响。此外,现有方法无法判断图结构中哪一部分子结构最能影响图属性,例如在药物分子属性预测中,基于图神经网络的预测模型仅能输出药物分子的属性,而无法识别。因此需要在图数据中高效地识别最能影响图属性/类别的子结构,同时滤除冗余和噪声信息,我们称之为子图识别问题。
二、子图识别的难点
子图识别的主要难点是难以获得成对的训练数据。人工标注一方面费时费力,例如 ZINC250K 数据集中有 25 万分子,需要相当长的时间进行标注;另一方面需要相应的专业知识,例如分子数据中官能团的标注需要具备生物化学专业知识的专家。
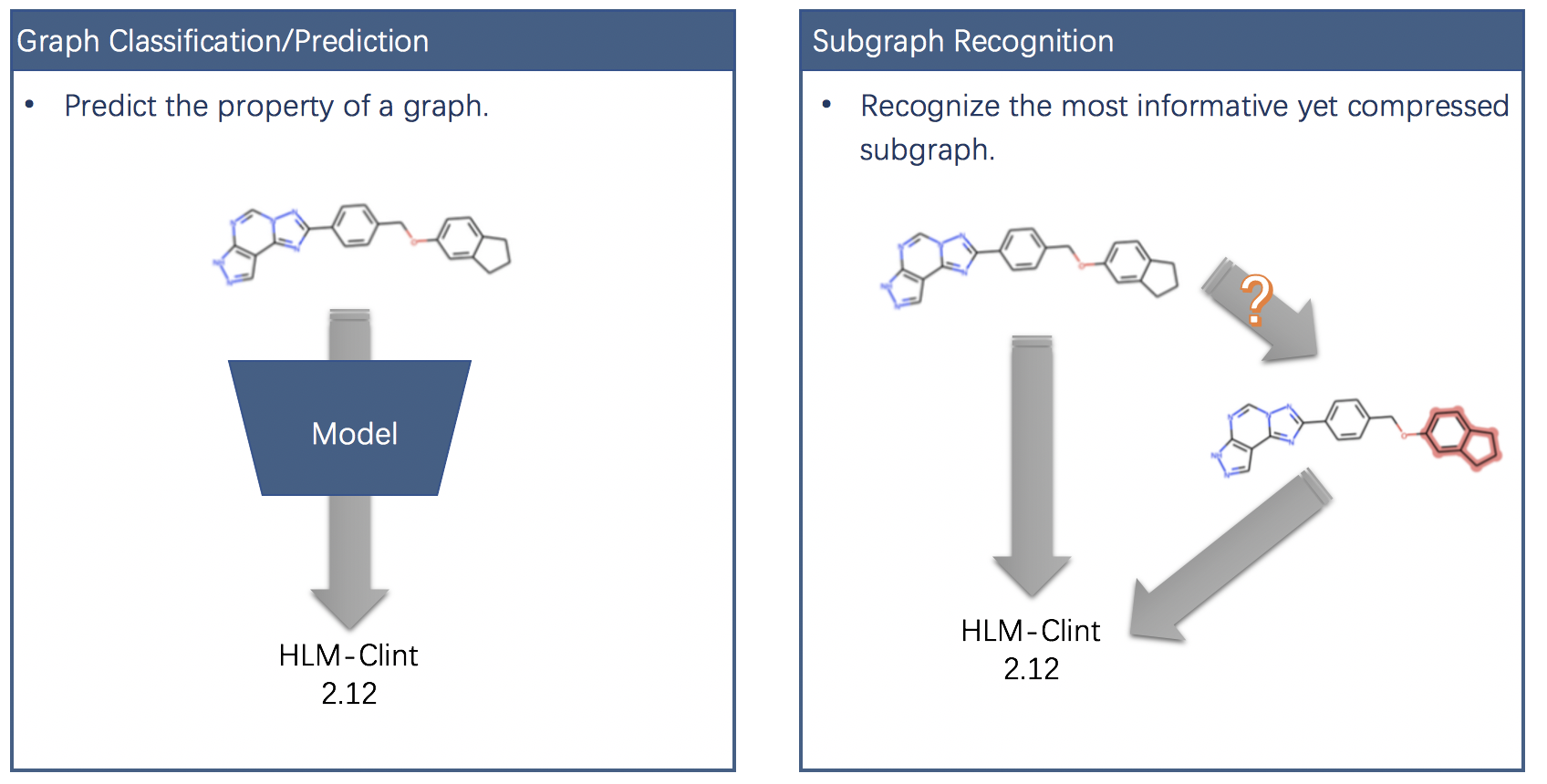
如何在缺少子图标注的情况下有效的识别影响原图属性的子图?
三、图信息瓶颈
子图识别问题虽然缺少直接的子图标注,然而该问题的设置和信息瓶颈理论非常相似。信息瓶颈理论在学习数据的表征时,通过最小化表征与原始数据的互信息,同时最大化表征与数据标签的互信息,能够得到与噪声无关的预测性表征。
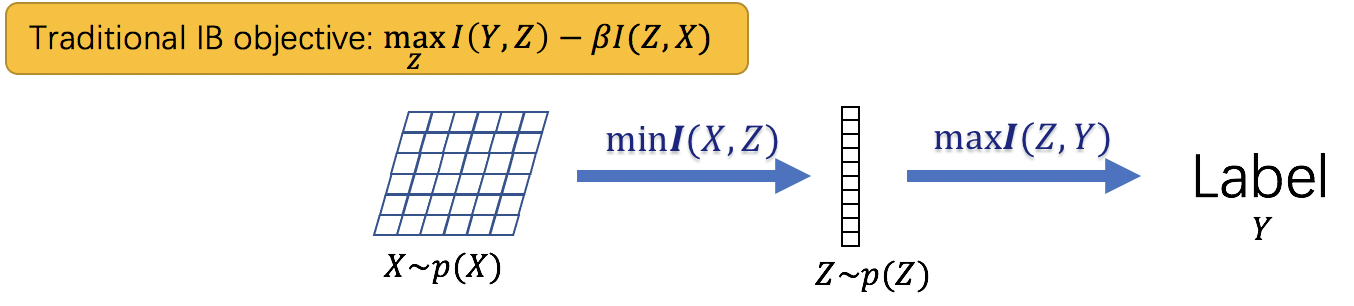
基于信息瓶颈理论,我们提出了图信息瓶颈理论:
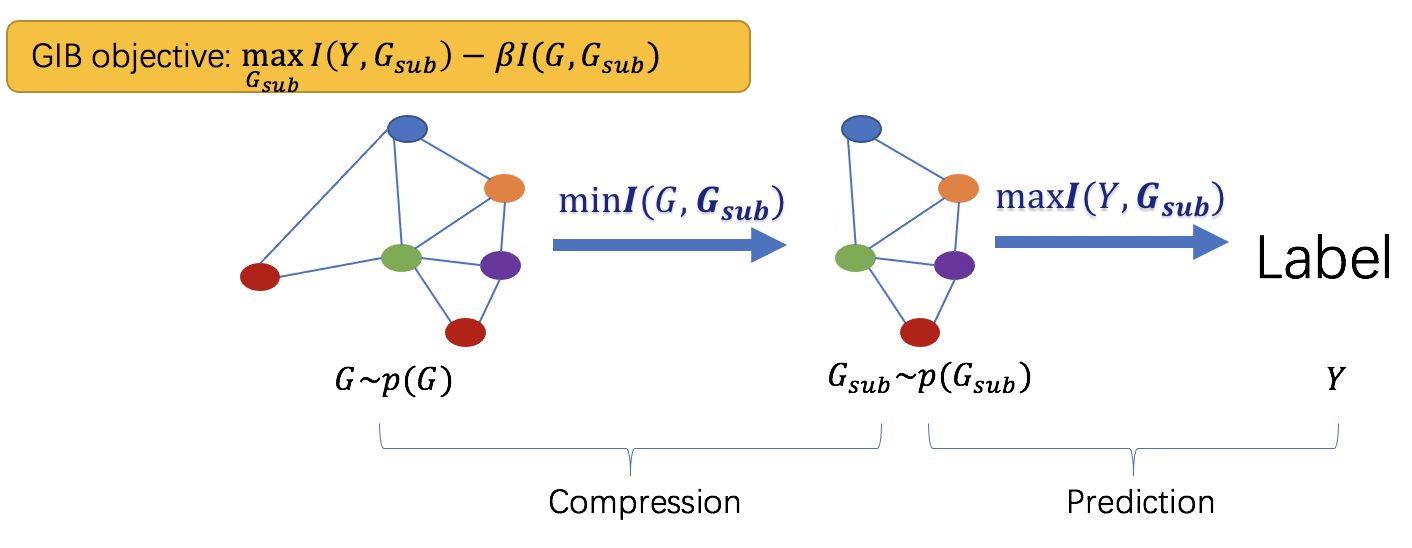
图信息瓶颈最小化输入图与子图的互信息,同时最大化子图与原图标签的互信息,从而得到滤除噪声与冗余信息且最能影响原图属性的子图。我们将这种子图定义为信息瓶颈子图。
四、优化方法
然而,互信息难以直接计算,因此导致了难以直接优化图信息瓶颈的目标函数。对于目标函数中的第一项,我们通过寻找互信息的下界,将互信息的最大化问题转化为分类损失最小化问题:
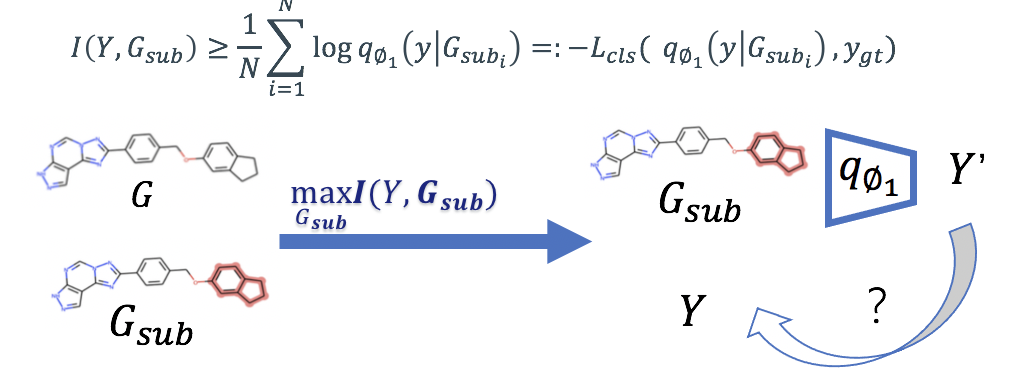
对于目标函数中的第二项,我们需要最小化子图与原图的互信息,[1]在表征学习中通过变分的方式寻找到互信息的一个上界:
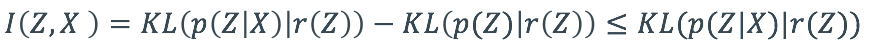
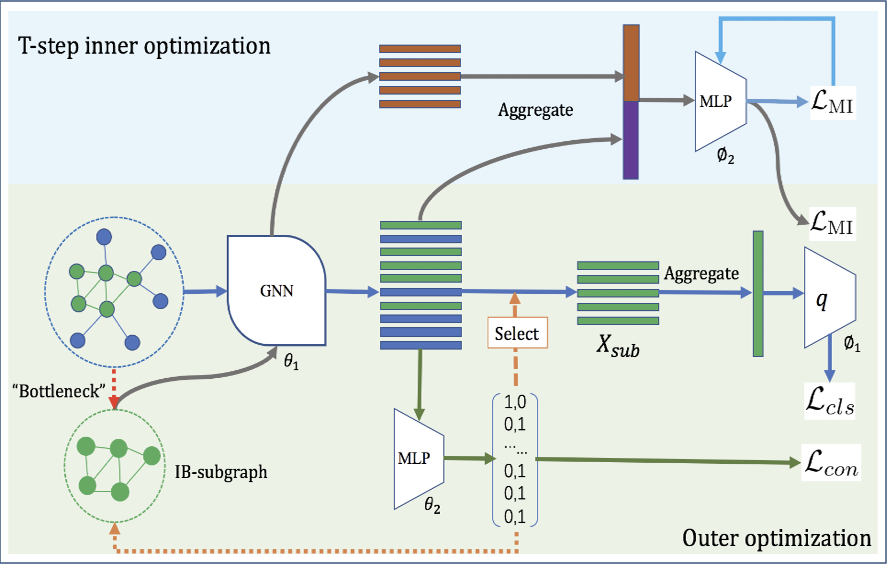
然而,该方法需要假设表征的先验分布,例如[1]中假设表征的先验分布为标准正态分布。然而,在子图识别场景中,我们难以对子图的先验分布给出合理的假设,因此我们采用 bilevel 的优化策略,在内层优化过程中训练参数网络估计子图和原图的互信息,在外层通过更新子图最小化子图和原图的互信息。具体的,在内层优化中,我们首先利用图神经网络得到原图与子图的表征,而后训练参数网络最大化互信息的 Donsker-varadhan 表示形式估计当前训练步数中原图与子图的互信息,随后在外层优化中优化子图最小化子图和原图的互信息。
因此,图信息瓶颈的优化目标为:
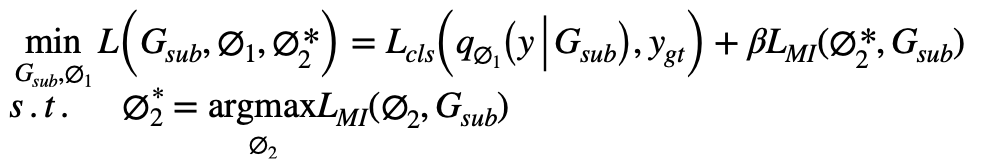
五、连续化松弛
由于子图识别需要选择性删除原图的节点,而节点的删除操作为离散变量,难以直接通过梯度的方式进行优化,因此我们设计了子图生成器并提出了连续化松弛方法。从而能够利用梯度方法优化图信息瓶颈目标函数。子图生成器由一个二层的图神经网络和一个二层的全联接网络组成,图神经网络首先得到每个节点的表征,随后全联接网络通过输出节点分配矩阵判断该节点是否属于信息瓶颈子图。
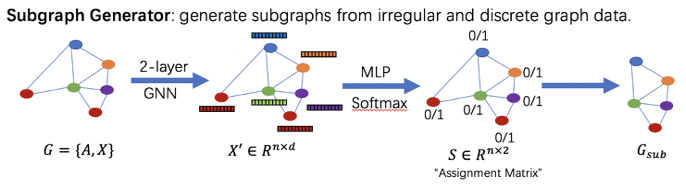
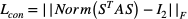
为了使子图更加紧凑并且稳定连续化松弛带来的训练不稳定问题,我们提出了连接损失目标函数。该目标函数可以使节点分配矩阵中的元素趋近于 0 或 1,从而使训练更加稳定,同时也能约束相邻的节点尽可能同时位于信息瓶颈子图内。
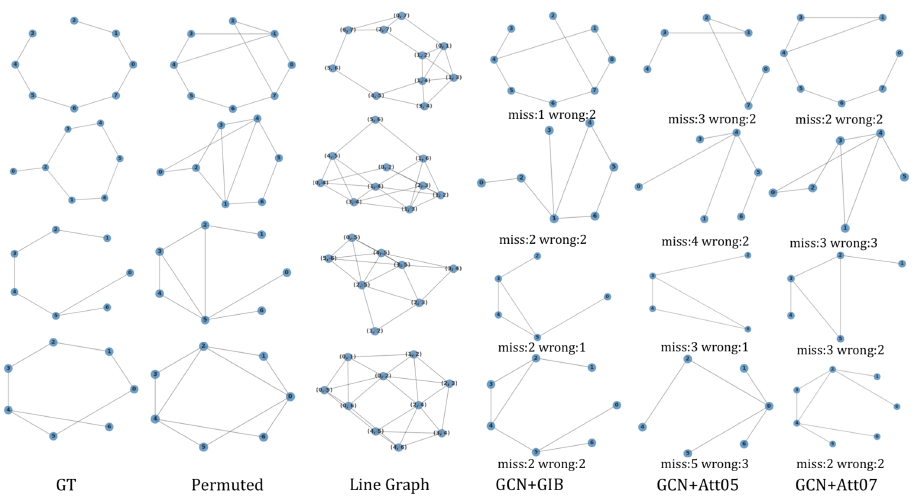
六、实验结果
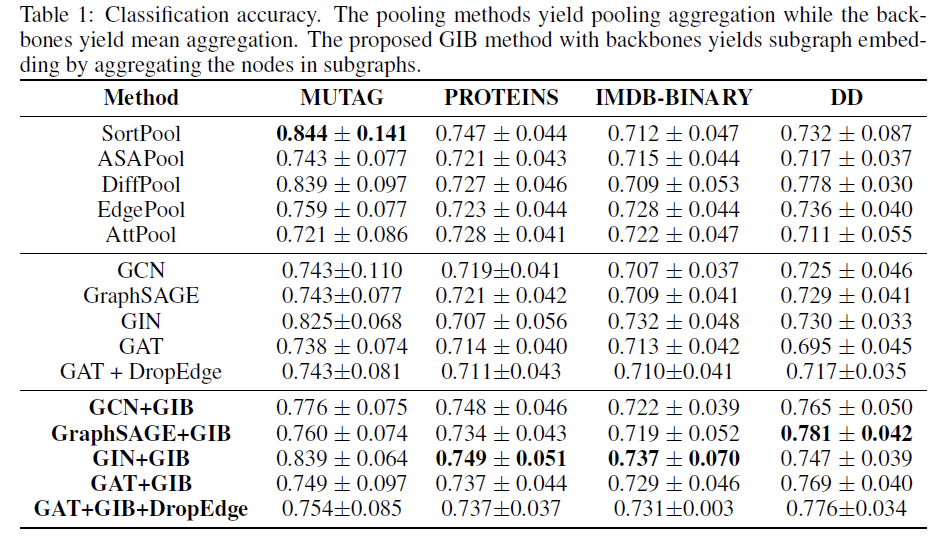
我们首先在四个图分类数据集上进行了图分类实验,相比于 GIB 能够有效的提高 baseline 的分类效果。
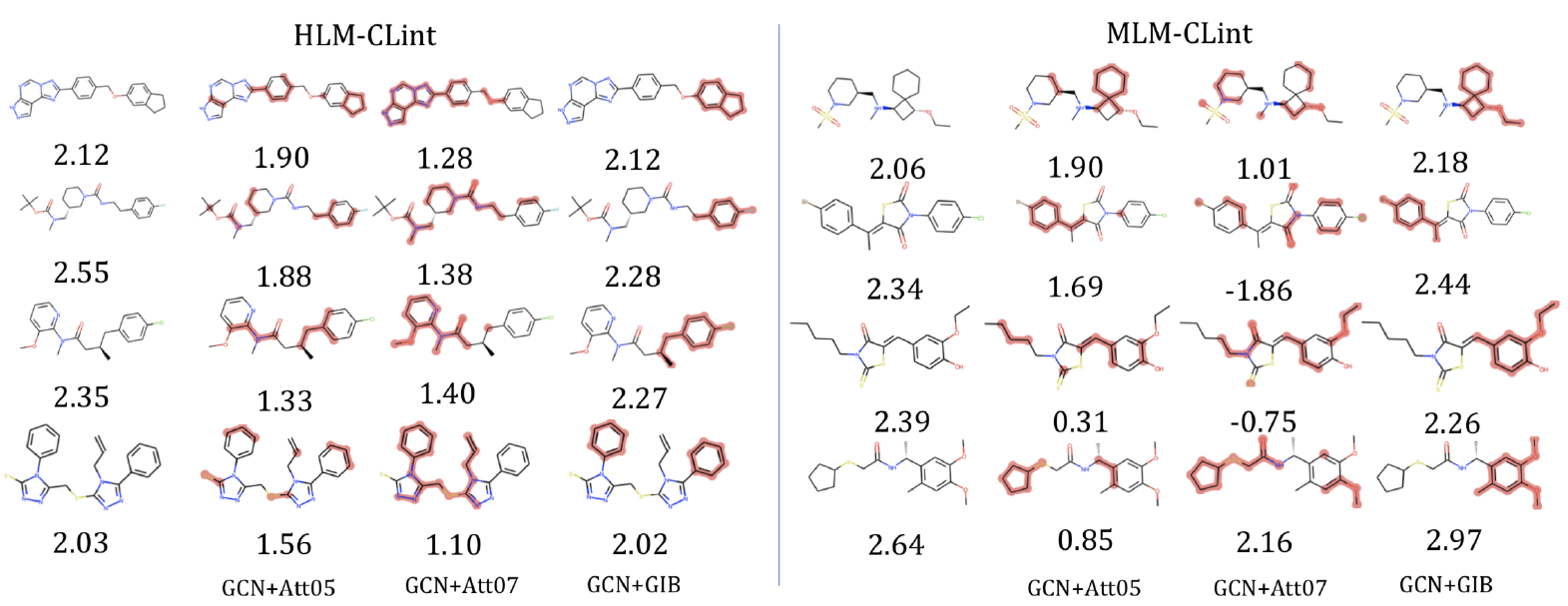
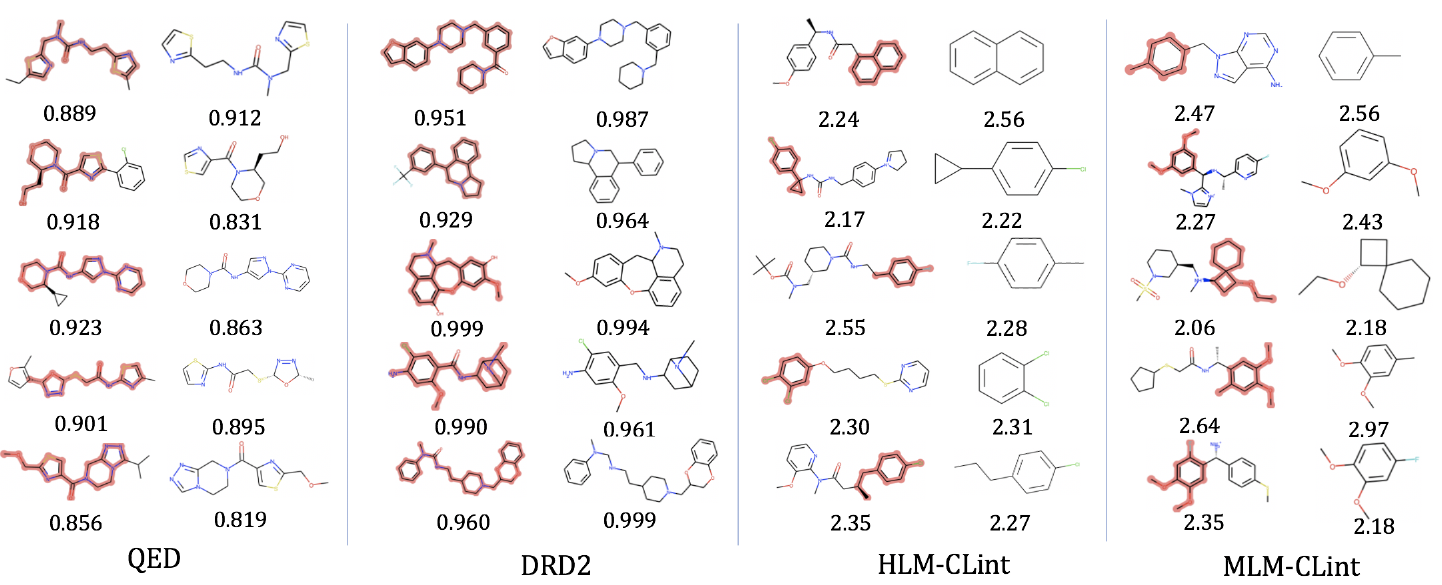
随后,我们在 zinc250k 数据集上进行了图解释实验,即寻找最能体现分子某种属性的子结构,相比于基于注意力机制的方法,GIB 能够更准确的识别决定分子属性的子结构。
最后我们进行了图去噪实验,GIB 能有效的去除图数据中人为添加的噪声边。