
随着越来越多的企业将应用程序迁移到 Kubernetes 平台,它逐渐成为了资源编排和调度的重要入口。众所周知,Kubernetes 会按照应用程序申请的资源配额进行调度,因此如何合理的配置应用资源规格就成为提升集群利用率的关键。这篇文章将会分享如何基于 FinOps 开源项目 Crane 正确的配置应用资源,以及如何在企业内推进资源优化的实践。
Kubernetes 如何管理资源
Pod 资源模型
在 Kubernetes 中可以通过指定 Request/Limit 选择性的为 Pod 设定所需的资源数量。当为 Pod 中的 Container 指定了资源 Request 时, Kube-scheduler 就利用该信息决定将 Pod 调度到哪个节点上。当为 Container 指定了资源 Request 和 Limit 时,kubelet 会通过 Cgroup 参数确保运行的容器可以获取到申请的资源并且不会使用超出所设限制的资源。kubelet 还会为容器预留所 Request 数量的系统资源,供其使用。
以下是一个 Pod 的资源示例:
apiVersion: v1kind: Podmetadata: name: frontendspec: containers: - name: app image: images.my-company.example/app:v4 resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"在明确了资源的申请量后即可推导出应用的资源利用率公式:Utilization = 资源用量 Usage / 资源申请量 。
因此,为了提升 Pod 的利用率我们需要配置合理的资源 Request。
Workload 资源模型
Workload 是在 Kubernetes 上运行的应用程序。它由一组 Pod 组成,例如 Deployment 和 Statefulset 统称为 Workload。Pod 的数量称为 Workload 的副本数。
Workload 的资源利用率公式:Workload Utilization = (Pod1 Usage + Pod2 Usage + ... PodN Usage)/ (Request * Replicas)
从公式可知提升 Workload 利用率不仅可以降低 Request,也可以降低 Replicas。
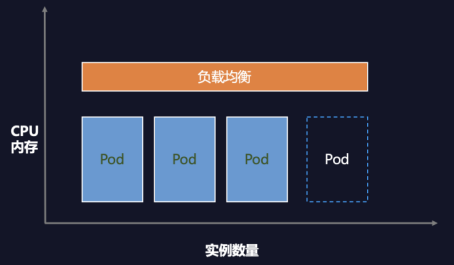
常见的资源配置问题
加拿大软件公司 Densify 在《12 RISK OF KUBERNETES RESOURCE MANAGEMENT》[1]中总结了常见的资源配置问题。在下表中我们在它的基础上增加了副本数维度的分析。
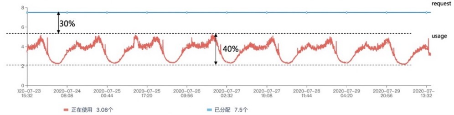
大家可以发现资源设置过小会引发稳定性问题,而相比之下资源设置大一些“仅仅”会导致资源浪费,在业务快速发展时期这些浪费是可以接受的。这就是许多企业上云后资源利用率普遍偏低的主要原因。下图是一个应用的资源用量图表,该 Pod 的历史用量的峰值与它的申请量 Request 之间,有 30%的资源浪费。
应用资源优化模型
掌握了 Kubernetes 的资源模型后,我们可以进一步推导出云原生应用的资源优化模型:
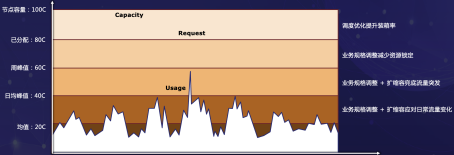
图中五条线从上到下分别是:
1. 节点容量:集群中所有节点的资源总量,对应集群的 Capacity。
2. 已分配:应用申请的资源总量,对应 Pod Request。
3. 周峰值:应用在过去一段时间内资源用量的峰值。周峰值可以预测未来一段时间内的资源使用,通过周峰值配置资源规格的安全性较高,普适性更强。
4. 日均峰值:应用在近一天内资源用量的峰值。
5. 均值:应用的平均资源用量,对应 Usage。
减少资源浪费的原理就是让 Capacity、Request、Usage 更加接近。模型中针对如何一步步减少浪费提供了四个步骤,从上到下分别是:
1. 提升装箱率:提升装箱率能够让 Capacity 和 Request 更加接近。手段有很多,例如:Crane 的动态调度器[2]、腾讯云原生节点的节点放大功能[3]等
2. 业务规格调整减少资源锁定:根据周峰值资源用量调整业务规格使的 Request 可以减少到周峰值线。本文重点介绍的 Crane 推荐框架就是基于此原理实现。
3. 业务规格调整+扩缩容兜底流量突发:在规格优化的基础上再通过 HPA 兜底突发流量使的 Request 可以减少到日均峰值线。此时 HPA 的目标利用率偏低,仅为应对突发流量,绝大多数时间内不发生自动弹性。
4. 业务规格调整+扩缩容应对日常流量变化:在规格优化的基础上再通过 HPA 应用日常流量使的 Request 可以减少到均值。此时 HPA 的目标利用率等于应用的平均利用率。
开源项目 Crane[4] 基于这套模型,提供了动态调度、推荐框架、智能弹性、混部等技术能力,实现了一站式的 FinOps 云资源优化平台。本文我们将重点介绍推荐框架部分。
通过 Crane 推荐框架优化资源配置
开源项目 Crane 推出了推荐框架(RecommendationFramework)自动分析集群的各种资源的运行情况并给出优化建议。推荐框架通过分析过去一段时间的 CPU/Memory 监控数据,基于资源推荐算法给出资源配置的建议,企业可以基于建议配置进行决策。
下面我们通过一个例子介绍如何快速开始一次全集群的资源推荐。
在开始降本之旅之前,您需要在环境中安装 Crane,请参考文档:
创建 RecommendationRule
下面是一个 RecommendationRule 示例: workload-rule.yaml。
apiVersion: analysis.crane.io/v1alpha1kind: RecommendationRulemetadata: name: workloads-rule spec: runInterval: 24h # 每24h运行一次 resourceSelectors: # 资源的信息 - kind: Deployment apiVersion: apps/v1 - kind: StatefulSet apiVersion: apps/v1 namespaceSelector: any: true # 扫描所有namespace recommenders: # 使用 Workload 的副本和资源推荐器 - name: Replicas - name: Resource在该示例中:
每隔 24 小时运行一次分析推荐,runInterval 格式为时间间隔,比如: 1h,1m,设置为空表示只运行一次。
待分析的资源通过配置 resourceSelectors 数组设置,每个 resourceSelector 通过 kind,apiVersion,name 选择 k8s 中的资源,当不指定 name 时表示在 namespaceSelector 基础上的所有资源
namespaceSelector 定义了待分析资源的 namespace,any: true 表示选择所有 namespace
recommenders 定义了待分析的资源需要通过哪些 Recommender 进行分析。目前支持的类型:recommenders
资源类型和 recommenders 需要可以匹配,比如 Resource 推荐默认只支持 Deployments 和 StatefulSets,每种 Recommender 支持哪些资源类型请参考 recommender 的文档
1. 通过以下命令创建 RecommendationRule,刚创建时会立刻开始一次推荐。
kubectl apply -f workload-rules.yaml这个例子会对所有 namespace 中的 Deployments 和 StatefulSets 做资源推荐和副本数推荐。
2. 检查 RecommendationRule 的推荐进度。通过 Status.recommendations 观察推荐任务的进度,推荐任务是顺序执行,如果所有任务的 lastStartTime 为最近时间且 message 有值,则表示这一次推荐完成
kubectl get rr workloads-rule3. 通过以下命令查询推荐结果:
kubectl get recommend可通过以下 label 筛选 Recommendation,比如 kubectl get recommend -l analysis.crane.io/recommendation-rule-name=workloads-rule
根据优化建议 Recommendation 调整资源配置
对于资源推荐和副本数推荐建议,用户可以 PATCH status.recommendedInfo 到 workload 更新资源配置,例如:
patchData=`kubectl get recommend workloads-rule-replicas-rckvb -n default -o jsonpath='{.status.recommendedInfo}'`;kubectl patch Deployment php-apache -n default --patch "${patchData}"Recommender
目前 Crane 支持了以下 Recommender:
资源推荐: 通过 VPA 算法分析应用的真实用量推荐更合适的资源配置
副本数推荐: 通过 HPA 算法分析应用的真实用量推荐更合适的副本数量
HPA 推荐: 扫描集群中的 Workload,针对适合适合水平弹性的 Workload 推荐 HPA 配置
闲置节点推荐: 扫描集群中的闲置节点
本文重点讨论 Workload 的资源配置优化,因此下面重点介绍资源推荐和副本推荐。
资源推荐
以下是一个资源推荐结果的样例:
status: recommendedInfo: >- {"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"150m","memory":"256Mi"}}}]}}}} currentInfo: >- {"spec":{"template":{"spec":{"containers":[{"name":"craned","resources":{"requests":{"cpu":"500m","memory":"512Mi"}}},{"name":"dashboard","resources":{"requests":{"cpu":"200m","memory":"256Mi"}}}]}}}} action: Patch conditions: - type: Ready status: 'True' lastTransitionTime: '2022-11-29T04:07:44Z' reason: RecommendationReady message: Recommendation is ready lastUpdateTime: '2022-11-30T03:07:49Z'recommendedInfo 显示了推荐的资源配置,currentInfo 显示了当前的资源配置,格式是 Json ,可以通过 Kubectl Patch 将推荐结果更新到 TargetRef
计算资源规格算法
资源推荐按以下步骤完成一次推荐过程:
1. 通过监控数据,获取 Workload 过去一周的 CPU 和 Memory 历史用量。
2. 基于历史用量通过 VPA Histogram 取 P99 百分位后再乘以放大系数
3. OOM 保护:如果容器存在历史的 OOM 事件,则考虑 OOM 时的内存适量增大内存推荐结果
4. 资源规格规整:按指定的容器规格对推荐结果向上取整
基本原理是基于历史的资源用量,将 Request 配置成略高于历史用量的最大值并且考虑 OOM,Pod 规格等因素。
副本推荐
以下是一个副本推荐结果的样例:
status: recommendedInfo: '{"spec":{"replicas":1}}' currentInfo: '{"spec":{"replicas":2}}' action: Patch conditions: - type: Ready status: 'True' lastTransitionTime: '2022-11-28T08:07:36Z' reason: RecommendationReady message: Recommendation is ready lastUpdateTime: '2022-11-29T11:07:45Z'recommendedInfo 显示了推荐的副本数,currentInfo 显示了当前的副本数,格式是 Json ,可以通过 Kubectl Patch 将推荐结果更新到 TargetRef
副本推荐按以下步骤完成一次推荐过程:
1. 通过监控数据,获取 Workload 过去一周的 CPU 和 Memory 历史用量。
2. 用 DSP 算法预测未来一周 CPU 用量
3. 分别计算 CPU 和 内存分别对应的副本数,取较大值
计算副本算法
以 CPU 举例,假设工作负载 CPU 历史用量的 P99 是 10 核,Pod CPU Request 是 5 核,目标峰值利用率是 50%,可知副本数是 4 个可以满足峰值利用率不小于 50%。
replicas := int32(math.Ceil(workloadUsage / (TargetUtilization * float64(requestTotal) )))和社区的差异
由资源优化模型可知,推荐框架能够将应用的 Request 降低到周峰值,并且推荐框架只做规格推荐,不执行变更,安全性更高、适用于更多业务类型。如果需要进一步降低 Request,可以考虑通过 HPA 等方案实现。
最佳实践
FinOps 建议采用迭代方法来管理云服务的可变成本。持续管理的迭代由三个阶段组成:成本观测(Inform)、 成本分析(Recommend)和 成本优化(Operate)。下面我们将基于这三个阶段+腾讯内部的实践经验介绍如何使用 Crane 实现 K8S 资源的配置管理。
成本观测--计算成本/收益
成本观测是降本之旅的核心关键。只有明确了目标,降本优化才会有的放矢。因此,用户需要建立集群资源的监控观测系统,来评估是否需要进行降本增效。例如,集群的装箱率是多少?集群的平均/峰值利用率是多少?Namespace 的资源用量分布,Workload 的平均/峰值利用率是多少?
腾讯内部在推进降本之前就通过建立观测系统获得了线上集群的资源大图:
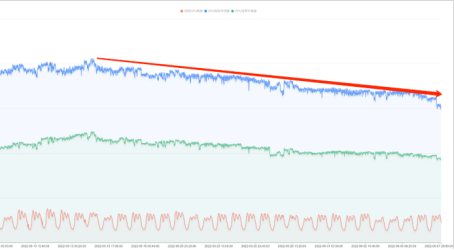
通过上图可以得知集群的利用率偏低,资源配置优化预计可节省多少资源。通过演算降本的成本(推进降本需要多少人力,多长时间)/收益(可节省多少 CPU/钱)可以帮助公司决策:是否要开始降本项目。
成本分析--建立系统
Crane 的推荐框架提供了一整套分析优化的工具对集群资源进行全方位的分析,并且将推荐结果记录到 CRD 和 Metric,方便业务系统集成。
腾讯内部的实践是:
1. 通过 RecommendationRule 对集群中所有的 Workload 进行资源和副本推荐,每 12 小时更新一次
2. 在管控界面单独展示完整的推荐结果
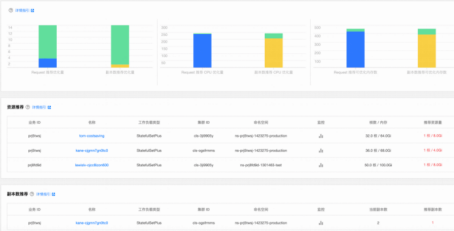
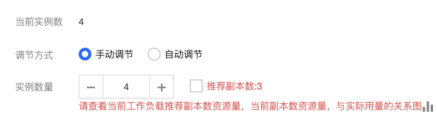
3. 在 Workload 数据展示页面展示资源/副本推荐
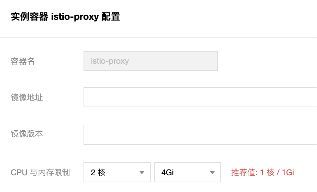
4. 在 Grafana 图表中展示 Workload 的观测数据
5. 提供 OpenAPI 让业务方获取推荐建议,按业务需求进行优化
成本优化--渐进式推进
FinOps 基金会定义了关于 FinOps 的“爬、走、跑”的成熟度方法,使企业能够从小处着手,并在规模、范围和复杂性上不断扩大。同样的,降本的前提是稳定性保证不受影响,资源配置的变更发布和不合理的配置可能会影响业务稳定性,用户的优化过程也要遵循同样的方式:
1. 先在 CI/CD 环境验证配置的准确性再更新生产环境。
2. 先优化浪费严重的业务,再优化已经比较低配置的业务
3. 先优化非核心业务,再优化核心业务
4. 根据业务特征配置推荐参数:线上业务需要更多的资源 buffer 而离线业务则可以接受更高的利用率。
5. 发布平台通过提示用户建议的配置,让用户确认后再更新以防止意料之外的线上变更。
6. 部分业务集群通过自动化工具自动依据推荐建议更新 Workload 配置以实现更高的利用率。
在介绍 FinOps 的书籍《Cloud FinOps》中它分享了一个世界 500 强公司通过自动化系统进行资源优化的例子,工作流如下:
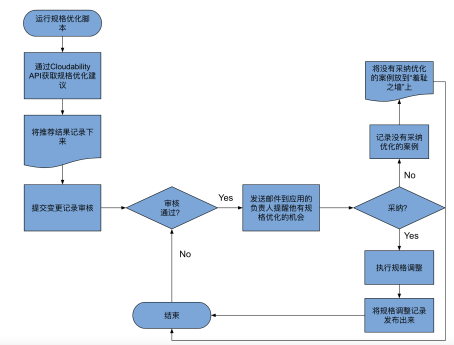
自动的配置优化在 FinOps 中属于高级阶段,推荐在实践 FinOps 的高级阶段中使用。不过至少,你应该考虑跟踪你的推荐,并且让对应的团队手动执行所需的变更。
展望未来
无论是否需要资源优化,当你希望实践 FinOps 时,Crane 都可以作为尝试对象。你可以首先通过集群的成本展示了解当前的 Kubernetes 集群的现状,并根据问题所在选择优化的方式,而本文介绍的资源配置优化是最直接和最常见的手段。
未来 Crane 的推荐框架将朝着更准确、更智能、更丰富的目标演进:
集成 CI/CD 框架:相比手动更新,自动化方式的配置更新能进一步提升利用率,适用于对资源利用率更高的业务场景。
成本左移:在 CI/CD 阶段通过配置优化尽早的发现资源浪费并解决它们。
基于应用负载特征的配置推荐:基于算法识别负载规律型业务和突发任务型业务,并给出合理的推荐。
任务类型的资源推荐:目前支持的更多是 Long Running 的在线业务,任务类型的应用也可以通过资源推荐优化配置。
更多 Kubernetes 闲置资源类型的分析:扫描集群中闲置的资源,例如 Load Balancer/Storage/Node/GPU。
附录
1. The Top 12 Kubernetes Resource Risks: K8s Best Practices: Top 12 Kubernetes Resource Risks
2. 动态调度器:Crane-scheduler:基于真实负载进行调度
3. 原生节点节点放大:容器服务产品介绍-云原生资产管理平台-文档中心-腾讯云
4. Crane:https://github.com/gocrane/crane
作者简介:
胡启明,腾讯云专家工程师,开源项目 Crane 的 Founder 和负责人。




