
数据做为企业的关键资产,日益用于赋能数字化产品、辅助决策制定并驱动创新。掌握数据的健康状态和可靠性,业已成为企业的立基之本。数十年来,各组织的数据治理一直依赖于数据编目系统。但这是否就足够了呢?
本文邀请了 Debashis Saha 和 Barr Moses,探讨数据编目系统无法满足现代数据栈需求的原因所在,以及做为新方法的数据发现(data discovery)是如何为元数据管理和数据可靠性提供了必要的便捷途径。Saha 是 AppZen 的工程副总,曾任职于 eBay 和 Intuit;Moses 是 Monte Carlo 公司联合创始人兼 CEO。
众所周知,要理解数据对业务的影响,需掌握数据的具体位置和访问情况。事实上,成功地构建一个数据平台,关键在于对数据做好集中的组织管理,同时提供便利的访问方式。
数据编目(data catalogs)可类比为实体图书馆书籍编目,它充当元数据的存放地,并向用户提供获取数据可访问性、健康和位置等内容所需的必要信息。在当前的自助式商业智能(SSBI,self-service business intelligence)时代,数据编目同样提供了强大的数据管理和数据治理工具。
由此,建立数据编目是大多数数据负责人的当务之急。
数据编目系统至少需具备解决如下问题的能力:
数据应从何处查找?
数据是否重要?
数据表示了什么?
数据的相关性和重要性?
数据如何使用?
但是,随着数据操作的日益成熟,以及数据流水线的日益复杂,传统的数据编目显露出不足,通常难以满足上述需求。
这也是为什么一些优秀的数据工程团队正持续创新自身的元数据管理方法。下面介绍他们的做法。
数据编目的不足之处
数据编目提供为数据建立资料的功能,但对于支持用户“发现”并实时洞悉数据真实状况这一根本性问题,数据编目在很大程度上依然无能为力。
我们所知的数据编目未能实现与时俱进,原因主要可归为三点:一是缺失自动化机制,二是难以随着数据栈的增长和多样化而扩展,三是不支持分布式格式。
对自动化的需求与日俱增
传统数据编目和治理方法,通常依靠数据团队手工完成繁重的数据录入工作,并负责根据数据资产的变化情况相应地更新编目。该做法不仅非常耗时,而且需要大量的人工操作。如果能自动执行上述操作,那么就可腾出数据工程师和分析人员的时间,让他们聚焦于真正具有产出的项目。
掌握数据的状态,是数据专业人士的常态化工作。这意味着行业需要更加强大、更具定制能力的自动化技术。下面的实例有一定借鉴意义:
为了厘清当前的报告或模型是由哪些数据集提供的信息,你是否常常在利益相关方开会之前疯狂翻阅聊天记录。为了搞清楚生成某个关键报告的数据究竟为什么会在上周停止更新,你和团队是否会聚在一起在白板上梳理上游和下游的全部连接情况?
忽略细节信息,问题可能会是下图这样。对所有人而言,数据世系看起来就是一团乱麻。

注:图片由 EgudinKa 发布在 Shutterstock:http://www.shutterstock.com/
发生在你身上的此类情况并非孤例。许多需要解决这团乱麻的公司,已耗费数年时间手工厘清自身的数字资产。有些公司投入资源使问题得到了短期解决,或是使用内部工具去搜索和浏览数据。即便最终达到了目标,这些措施也已经给组织带来沉重的负担,耗费了数据工程团队的时间和资金。而这些时间和资金本来可以用于产品研发和数据使用等方面。
随数据变化而扩展的能力
数据编目非常适用于结构化数据。但时至 2020 年,数据并非完全是结构化的。随着机器生成数据的不断增加,以及企业在机器学习项目上的投资,非结构化数据越来越成为常态,已超过所有新生成数据的 90%。
结构化数据 通常使用数据湖存储,并不具有预定义的模型,必须经过多次转换才能使用。非结构化数据是完全动态的,在经历转换、建模和聚合等各处理阶段后,数据的形态、来源和意义会随时发生变化。对非结构化数据的转换、建模、聚合和可视化等处理方式,导致难以在“期望的状态”下对数据进行编目。
对于数据消费者,编目不仅需要给出对所访问和使用的数据的基本描述,而且更重要的是需根据使用者的意图和目的给出对数据的理解。数据生产者对资产所做的描述,可能会与数据消费者对其功能的理解大相径庭。甚至在两位不同的数据消费者之间,对数据含义的理解上也可能存在着巨大的差异。
例如,对于一个从 Salesforce 中抽取的数据集,在数据工程师和销售团队人员看来可能意义迥异。尽管数据工程师能理解“DW_7_V3”字段的含义,但销售团队则会抓狂,难以确定 Salesforce 数据集是否与他们的“2021 年收入预测”仪表盘相关。此类例子不胜枚举。
对数据做静态描述本身就存在局限性。时至 2021 年,要真正地理解数据,我们必须接受并适应数据的动态发展和推陈出新。
数据呈分布态,但编目并非如此
现代数据架构正向分布式发展(参见“the data mesh”一文),半结构化和非结构化数据也在成为常态,但大多数的数据编目系统依然将数据视为一维实体。经聚合和转换后的数据在流经数据栈的各个部分时,非常容易发生难以文档化的问题。

图释:传统数据编目获取数据时生成元数据,即用于描述数据的数据。但数据是持续变化的,导致难以把握在流水线中变化的数据健康状态。图片由本文作者 Barr Moses 提供。
当前,自描述 已成为数据发展趋势,即在数据中打包了数据本身以及描述数据格式和意义的元数据。
由于传统的数据编目并非分布式的,很难做为数据的单一事实来源(SSOT,single source of truth)。随着从 BI 分析师到运营团队等更广泛用户群体对便捷访问数据的需求增加,以及支持机器学习、运营和分析的数据流水线越来越复杂,该问题只会愈加严重。
现代数据编目需要跨域整合数据的含义。数据团队应该理解数据域间的相互关联,以及在哪些方面上需要使用聚合视图。需要以一定程度上聚合的方式,才能作为一个整体回答呈分散态的问题。换句话说,需要分布式的联邦数据编目。
建立更好的数据平台,需要自一开始就采用正确的方法构建数据编目。进而帮助团队实现数据民主化(democratize)、简化数据探索、聚合重要的数据资产、尽量充分发挥数据的潜能。
数据发现:新版的数据编目
为确保数据编目正常工作,需建立严格的模型。但随着数据流水线变得越来越复杂,以及非结构化数据大行其道,我们对数据的作用、用途和使用方式的理解可能未能反映现实的情况。
我们认为,新一代数据编目系统需具备数据的学习、理解和推理能力,支持用户自助地使用数据洞察力。但应该如何实现?
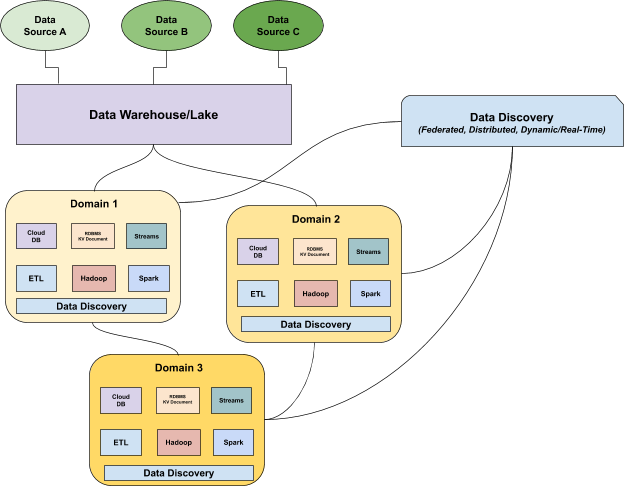
图释:数据发现在遵守着同一套中央治理标准的同时,为不同领域的数据提供了分布式实时洞悉。图片由本文作者 Barr Moses 提供。
不仅是数据编目,元数据和数据的管理策略也必须结合数据发现。数据发现是一种实时了解分布式数据资产运行状况的新方法,借鉴了 Zhamak Deghani 提出的分布式面向领域架构,以及 Thoughtworks 的 数据网格模型。数据发现提出,各数据所有者应对数据负起产品责任,推动分布于不同位置的数据间的通信。数据一旦提供给特定的域,并在域中加以转换后,域数据的所有者就可将数据用于满足自身的运营或分析需求。
数据发现根据一组特定使用者对数据的获取、存储、聚合和使用方式,动态地给出在特定域中对数据的理解,可替代数据编目。和使用数据编目一样,治理标准和工具同样是跨域联合的,以支持更大的可访问性和互操作性。不同于数据编目所给出的数据理想状态或“编目”状态,数据发现可实时了解当前数据状态。
数据发现不仅能回答数据理想状态的相关问题,而且能回答涉及不同域中的当前数据状态:
哪些数据集是最新的?哪些数据集可被禁用?
某个表的最新更新时间?
数据域在特定领域中的意义?
谁访问了该数据?该数据的最新使用时间和使用者?
数据的上游和下游依赖情况?
数据质量是否达到生产环境要求?
数据是否满足特定领域业务需求?
用户对数据有哪些要求?这些要求是否可满足?
我们认为,新一代数据编目(即数据发现)应具备如下功能:
自助式的发现和自动化
即便没有专门的团队支持,数据团队也能轻松地使用数据编目。自助服务、自动化和工作流程编排等数据工具,避免在数据流水线的各阶段及过程中产生孤岛,使人们更容易理解和访问数据。更好的可访问性,自然会增加对数据的采用,从而降低数据工程团队的负担。
随数据演进的可扩展性
随着公司获取的数据越来越多,并且非结构化数据已成为常态,满足需求的可扩展能力对于数据项目的成功是至关重要的。针对数据规模的扩展,数据发现利用机器学习技术获得整体视图,确保用户对数据的理解能适应数据的发展。这样,数据使用者就能做出更明智适时的决策,避免了依赖于过时的文档(也就是说,描述数据的元数据过时了!),或是更糟糕的是感情用事做出决策。
数据世系(Data lineage)的分布式发现
数据发现在很大程度上依赖于数据世系。数据世系自动形成表和字段级的世系关联,用于映射数据资产间的上游和下游依赖。世系给出了显示特定时间上的正确信息,这是数据发现的一项核心功能。世系还可以给出数据资产间的关联关系,便于用户更好地排查数据流水线管道发生中断问题的时间。随着现代数据栈为适应更复杂用例而不断改进,出现问题已变得越来越普遍出现。
数据可靠性是确保数据随时可用的黄金准则
事实上,你的团队可能已经在某种程度对数据发现做了一定的投入,无论团队是通过手工验证数据,由工程师编写自定义的验证规则,还是仅仅基于数据损坏或未被察觉的错误而制定决策成本。从数据质量监视,到更为强大的可监视并告警数据流水线中问题的端到端 数据可观察性平台,现代数据团队已开始使用自动化方法,确保流水线各阶段的数据是高度可信的。一旦数据中断,此类解决方案会通知用户,以便第一时间定位致因,进而快速地解决问题,防止进一步发生宕机。
使用数据发现,数据团队可确认自身对数据的设想是符合现实的,从而跳出特定域的局限,实现整个数据基础架构中的动态发现和高可靠性。
展望未来
不好的数据要比没有数据更糟糕。同样,不具备数据发现的数据编目系统,要比完全没有数据编目更糟糕。为了获得真正可发现的数据,重要的是不仅是“编目”数据,而且要做到使用的数据是准确的、整洁的并完全可观察的。换句话说,编目是可靠的。
要实现强有力的数据发现,需依赖于自动、可扩展并符合数据系统分布式新本质的数据管理。因此,要真正实现组织中的数据发现,我们需要重新考虑如何实现数据编目。
只有了解自身数据在整个生命周期中跨各域的状态及使用情况,才能去信任数据。
作者简介
Barr Moses,Monte Carlo 公司 CEO,联合创始人。Monte Carlo 的宗旨是通过与数据社区广泛合作,发挥数据的全部潜力,帮助企业兑现数据价值,致力于使数据可靠,并简化客户运行复杂度。
原文链接:
https://towardsdatascience.com/data-catalogs-are-dead-long-live-data-discovery-a0dc8d02bd34




