
随着 Uber 的业务持续增长,我们用了 5 年时间扩展 Apache Hadoop(本文中称为“Hadoop”),部署到了 21000 多台主机上,以支持多种分析和机器学习用例。我们组建了一支拥有多样化专业知识的团队来应对在裸金属服务器上运行 Hadoop 所面临的各种挑战,这些挑战包括:主机生命周期管理、部署和自动化,Hadoop 核心开发以及面向客户的门户。
随着 Hadoop 基础设施的复杂性和规模越来越大,团队越来越难以应对管理如此庞大系统时需要承担的各种职责。基于脚本和工具链的全系统规模运营工作消耗了大量的工程时间。损坏的主机越来越多,修复工作逐渐跟不上节奏。
在我们继续为 Hadoop 维护自己的裸金属部署时,公司的其他部门在微服务领域取得了重大进展。容器编排、主机生命周期管理、服务网格和安全性等领域的解决方案逐渐成型,让微服务管理起来更加高效和简便。
2019 年,我们开始了重构 Hadoop 部署技术栈的旅程。两年时间过去了,如今有超过 60%的 Hadoop 运行在 Docker 容器中,为团队带来了显著的运营优势。作为这一计划的成果之一,团队将他们的许多职责移交给了其他基础设施团队,并且得以更专注于核心 Hadoop 的开发工作。
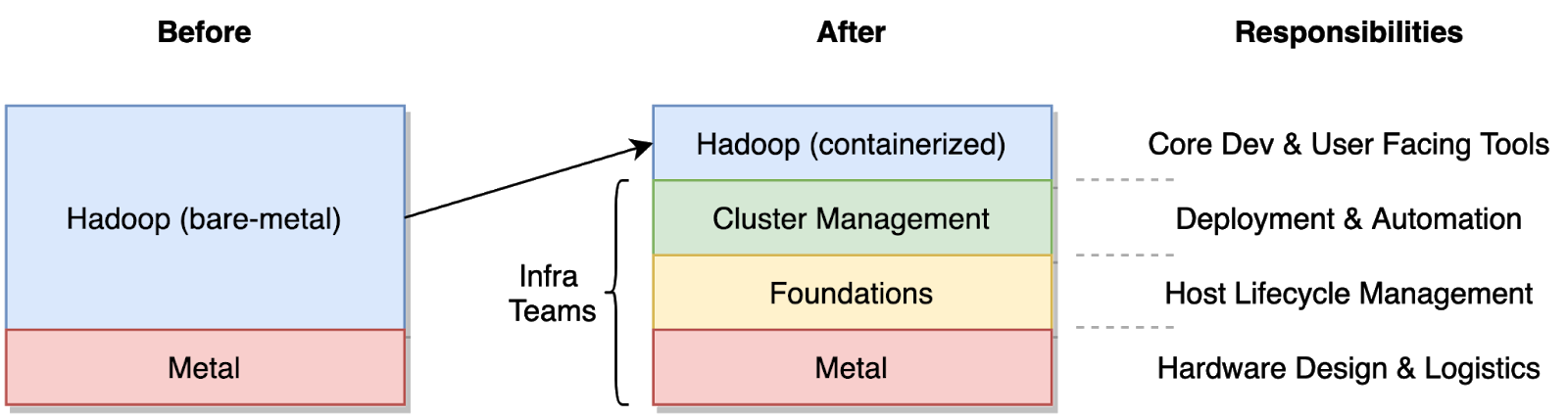
图 1:团队职责转移
本文总结了这一过程中我们面临的各种问题,以及我们解决这些问题的方法和途径。
回顾过去
在具体分析架构之前,有必要简要介绍一下我们之前运维 Hadoop 的方法及其缺陷。彼时,几个互相分离的解决方案协同工作,驱动 Hadoop 的裸金属部署。这些方案包括:
让主机设置就地突变的自动化方案
手动触发和监控,基于非幂等动作的脚本
松散耦合的主机生命周期管理解决方案
在底层,它们是通过几个 Golang 服务、大量 Python 和 Bash 脚本、Puppet 清单和一些 Scala 代码实现的。早期我们使用了 Cloudera Manager(免费版)并评估了 Apache Ambari。然而,由于 Uber 使用了自定义部署模型,这两个系统都被证明是不够用的。
我们旧的运维方法遇到了一些挑战,包括但不仅限于以下方面:
生产主机的手动就地突变导致了许多漂移,后来这让我们感到很惊讶。工程师经常就部署过程发生争论,因为在事件响应期间某些更改没有经过审查和识别。
全系统范围的更改需要漫长的时间来做手动计划和编排。我们上次的操作系统升级被推迟了,最终花了 2 年多的时间才完成。
几个月后,管理不善的配置导致了诸多事故。我们错误地配置了 dfs.blocksize,最终导致我们的一个集群中的 HDFS RPC 队列时间降级。
自动化与人类交互之间缺乏良好的契约,这会导致一些意想不到的严重后果。由于一些主机意外退役,我们丢失了一些副本。
“宠物”主机的存在和越来越多的“宠物”所需的人工处理过程导致了一些影响严重的事件。我们的一次 HDFS NameNode 迁移引发了一起影响整个批处理分析栈的事件。
我们在重构期间仔细考虑了从以前的经验中吸取的各种教训。
架构
开始设计新系统时,我们遵循以下原则:
对 Hadoop 核心的更改应该保持在最低水平,以免同开源代码分道扬镳(例如用于安全性的 Kerberos)
Hadoop 守护进程必须容器化,以实现不可变和可重复的部署
必须使用声明性概念(而不是基于动作的命令式模型)来建模集群运维
集群中的任何主机都必须在发生故障或降级时易于更换
应尽可能重用和利用 Uber 内部的基础设施,以避免重复
以下部分详细介绍了定义新架构的一些关键解决方案。
集群管理
我们之前使用命令式、基于动作的脚本来配置主机和运维集群的方法已经到了无以为继的地步。鉴于负载的有状态(HDFS)和批处理(YARN)性质,以及部署运维所需的自定义部分,我们决定将 Hadoop 纳入 Uber 的内部有状态集群管理系统。
集群管理系统通过几个基于通用框架和库构建的松散耦合组件来运维 Hadoop。下图代表了我们今天所用的架构的简化版本。黄色组件描述了核心集群管理系统,而绿色标记的组件代表了专门为 Hadoop 构建的自定义组件。
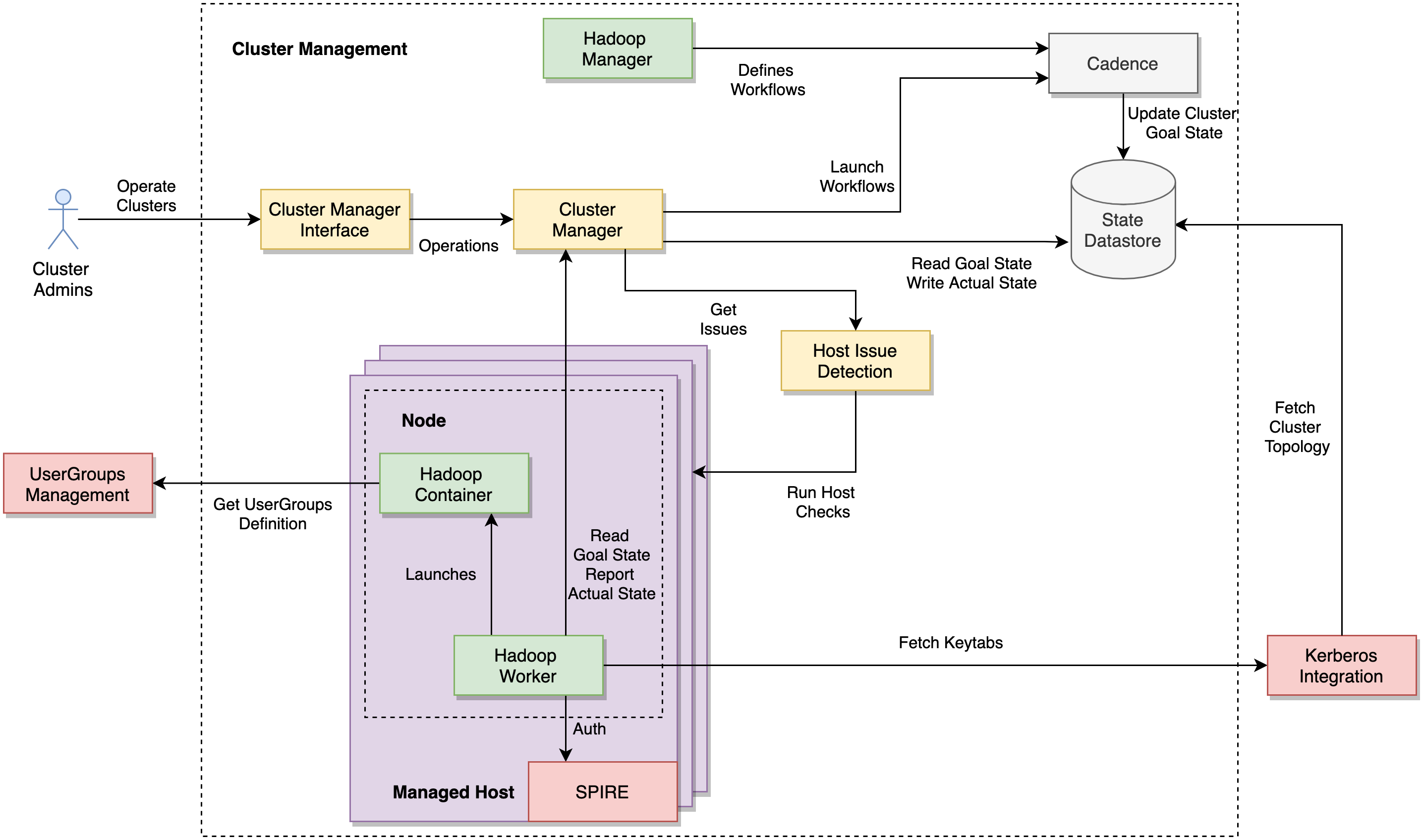
图 2:集群管理架构
集群管理员(Cluster Admin)与集群管理器界面(Cluster Manager Interface)Web 控制台交互,来触发对集群的运维操作。管理员的意图被传播到集群管理器(Cluster Manager)服务,然后触发突变集群目标状态(Goal State)的Cadence工作流。
集群管理(Cluster Management)系统维护预配置的主机,称为托管主机(Managed Hosts)。一个节点(Node)代表一组部署在一个托管主机上的 Docker 容器。目标状态定义了集群的整个拓扑结构,包括节点位置信息(主机位置)、集群到节点的归属、节点资源(CPU、内存、磁盘)的定义及其环境变量。一个持久数据存储负责存储目标状态,使集群管理系统可以从非常严重的故障中快速恢复。
我们非常依赖 Uber 开发的开源解决方案 Cadence 来编排集群上的状态变化。Cadence 工作流负责所有运维操作,诸如添加或停用节点、升级整个队列中的容器等等。Hadoop 管理器(Hadoop Manager)组件定义了所有工作流。
集群管理器(Cluster Manager)不了解 Hadoop 的内部运维操作以及管理 Hadoop 基础设施的复杂性。Hadoop 管理器实现了自定义逻辑(类似于K8s Custom Operator),以在 Hadoop 的运维范围内以安全的方式管理 Hadoop 集群和模型工作流。例如,我们所有的 HDFS 集群都有两个 NameNode;而 Hadoop 管理器组件内有一些相关的防护措施,例如禁止同时重启这两个 NameNode。
Hadoop Worker 是在分配给 Hadoop 的每个节点上启动的第一个代理(agent)。系统中的所有节点都在SPIRE注册,SPIRE 是一个开源身份管理和负载证明系统。Hadoop Worker 组件在容器启动时使用 SPIRE 进行身份验证,并接收一个SVID(X.509 证书)。Hadoop Worker 使用它与其他服务通信,以获取其他配置和密钥(例如 Kerberos 密钥表)。
Hadoop 容器(Hadoop Container)代表在 Docker 容器中运行的任何 Hadoop 组件。在我们的架构中,所有 Hadoop 组件(HDFS NameNode、HDFS DataNode 等)都部署为 Docker 容器。
Hadoop Worker 定期从集群管理器中获取节点的目标状态,并在节点本地执行各种动作以实现目标状态(这是一个控制循环,也是 K8s 的核心概念)。该状态定义要启动、停止或停用的 Hadoop 容器以及其他设置。在运行 HDFS NameNode 和 YARN ResourceManager 的节点上,Hadoop Worker 负责更新“主机文件”(例如dfs.hosts和dfs.hosts.exclude)。这些文件指示需要包含在集群中或从集群中排除的 DataNodes/NodeManager 主机。Hadoop Worker 还负责将节点的实际(Actual)状态(或当前状态)回报给集群管理器。集群管理器在启动新的 Cadence 工作流时,根据实际状态和目标状态将集群收敛到定义的目标状态。
一个与集群管理器良好集成的系统负责持续检测主机问题。集群管理器能做出很多智能决策,例如限制速率以避免同时停用过多的损坏主机。Hadoop 管理器在采取任何行动之前会确保集群在不同的系统变量下都是健康的。Hadoop 管理器中包含的检查可确保集群中不存在丢失或复制不足的块,并且在运行关键运维操作之前确保数据在 DataNode 之间保持均衡,并执行其他必要检查。
使用声明式运维模型(使用目标状态)后,我们减少了运维集群时的人工操作。一个很好的例子是系统可以自动检测到损坏主机并将其安全地从集群中停用以待修复。每退役一台损坏主机,系统都会补充一个新主机来保持集群容量不变(维持目标状态中所定义的容量)。
下图显示了由于各种问题在一周时间段内的各个时间点退役的 HDFS DataNode 数量。每种颜色描绘了一个 HDFS 集群。
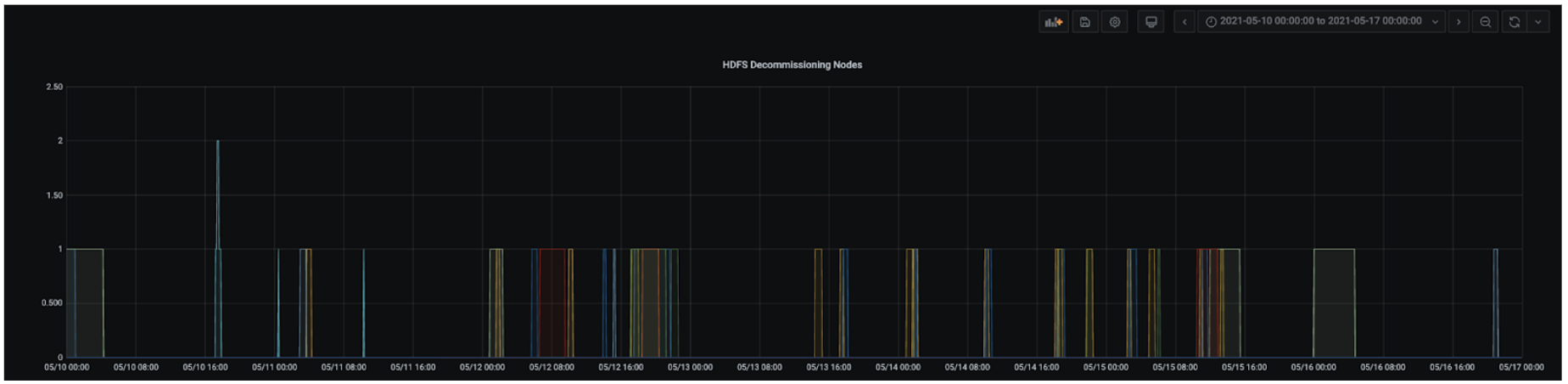
图 3:自动检测和停用损坏的 HDFS 数据节点
容器化 Hadoop
在过去,我们基础设施的内在可变性曾多次给我们带来了意想不到的麻烦。有了新架构后,我们得以在不可变 Docker 容器中运行所有 Hadoop 组件(NodeManager、DataNode 等)和 YARN 应用程序。
当我们开始重构时,我们在生产环境中为 HDFS 运行的是 Hadoop v2.8,为 YARN 集群运行的是 v2.6。v2.6 中不存在对 YARN 的 Docker 支持。鉴于依赖 YARN 的多个系统(Hive、Spark 等)对 v2.x 存在紧密依赖,将 YARN 升级到 v3.x(以获得更好的 Docker 支持)是一项艰巨的任务。我们最终将 YARN 升级到了支持 Docker 容器运行时的 v2.9,并从 v3.1 向后移植了几个补丁(YARN-5366、YARN-5534)。
YARN NodeManager 运行在主机上的 Docker 容器中。主机 Docker 套接字挂载到 NodeManager 容器,使用户的应用程序容器能够作为兄弟容器启动。这绕过了运行Docker-in-Docker会引入的所有复杂性,并使我们能够在不影响客户应用程序的情况下管理 YARN NodeManager 容器的生命周期(例如重启)。
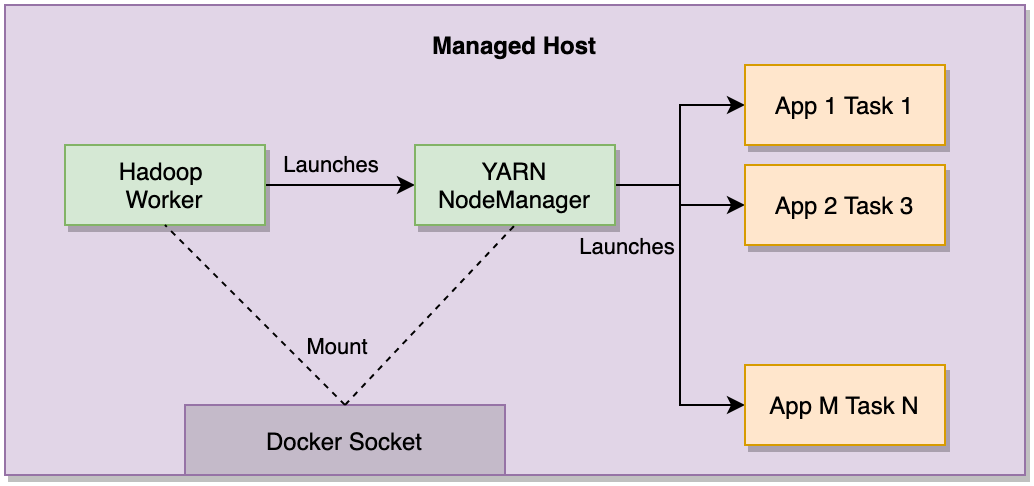
图 4:YARN NodeManager 和应用程序兄弟容器
为了让超过 150,000 多个应用程序从裸金属 JVM(DefaultLinuxContainerRuntime)无缝迁移到 Docker 容器(DockerLinuxContainerRuntime),我们添加了一些补丁以在 NodeManager 启动应用程序时支持一个默认 Docker 镜像。此镜像包含所有依赖项(python、numpy、scipy 等),使环境看起来与裸金属主机完全一样。
在应用程序容器启动期间拉取 Docker 镜像会产生额外的开销,这可能会导致超时。为了规避这个问题,我们通过Kraken分发 Docker 镜像。Kraken 是一个最初在 Uber 内部开发的开源点对点 Docker 注册表。我们在启动 NodeManager 容器时预取默认应用程序 Docker 镜像,从而进一步优化了设置。这可确保在请求进入之前默认应用程序 Docker 镜像是可用的,以启动应用程序容器。
所有 Hadoop 容器(DataNode、NodeManager)都使用卷挂载(volume mount)来存储数据(YARN 应用程序日志、HDFS 块等)。这些卷在节点放在托管主机上时可用,并在节点从主机退役 24 小时后删除。
在迁移过程中,我们逐渐让应用转向使用默认 Docker 镜像启动。我们还有一些客户使用了自定义 Docker 镜像,这些镜像让他们能够带来自己的依赖项。通过容器化 Hadoop,我们通过不可变部署减少了可变性和出错的几率,并为客户提供了更好的体验。
Kerberos 集成
我们所有的 Hadoop 集群都由 Kerberos 负责安全性。集群中的每个节点都需要在 Kerberos(dn/hdfs-dn-host-1.example.com)中注册主机特定服务主体 Principal(身份)。在启动任何 Hadoop 守护程序之前,需要生成相应的密钥表(Keytab)并将其安全地发送到节点。
Uber 使用 SPIRE 来做负载证明。SPIRE 实现了SPIFFE规范。形式为 spiffe://example.com/some-service 的SPIFFE ID用于表示负载。这通常与部署服务的主机名无关。
很明显,SPIFFE 和 Kerberos 都用的是它们自己独特的身份验证协议,其身份和负载证明具有不同的语义。在 Hadoop 中重新连接整个安全模型以配合 SPIRE 并不是一个可行的解决方案。我们决定同时利用 SPIRE 和 Kerberos,彼此之间没有任何交互/交叉证明。
这简化了我们的技术解决方案,方案中涉及以下自动化步骤序列。我们“信任”集群管理器和它为从集群中添加/删除节点而执行的目标状态运维操作。
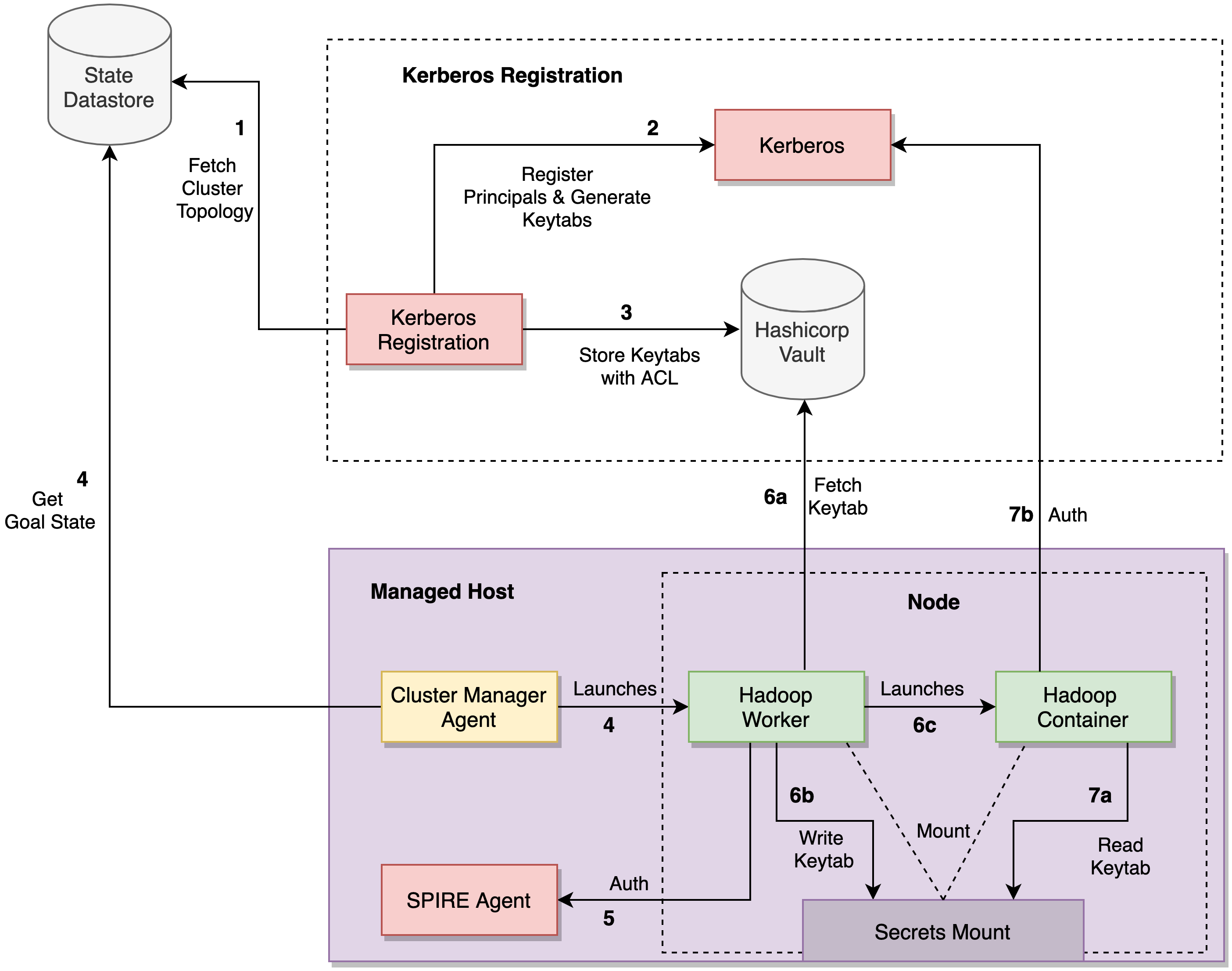
图 5:Kerberos 主体注册和密钥表分发
使用位置信息(目标状态)从集群拓扑中获取所有节点。
将所有节点的对应主体注册到 Kerberos 中并生成相应的密钥表。
集群管理器代理获取节点的目标状态并启动 Hadoop Worker。
Hadoop Worker 由 SPIRE 代理验证。
Hadoop Worker:
获取密钥表(在步骤 2 中生成)
将其写入 Hadoop 容器可读的一个只读挂载(mount)
启动 Hadoop 容器
Hadoop 容器(DataNode、NodeManager 等):
从挂载读取密钥表
在加入集群之前使用 Kerberos 进行身份验证。
一般来说,人工干预会导致密钥表管理不善,从而破坏系统的安全性。通过上述设置,Hadoop Worker 由 SPIRE 进行身份验证,Hadoop 容器由 Kerberos 进行身份验证。上述整个过程是端到端的自动化,无需人工参与,确保了更严格的安全性。
用户组管理
在 YARN 中,分布式应用程序的容器作为提交应用程序的用户(或服务帐户)运行。用户组(UserGroup)在活动目录(Active Directory,AD)中管理。我们的旧架构需要通过 Debian 包安装用户组定义(从 AD 生成)的定期快照。这导致了全系统范围的不一致现象,这种不一致是由包版本差异和安装失败引起的。
未被发现的不一致现象会持续数小时到数周,直到影响用户为止。在过去 4 年多的时间里,由于跨主机的用户组信息不一致引发的权限问题和应用程序启动失败,让我们遇到了不少麻烦。此外,这还导致了大量的手动调试和修复工作。
Docker 容器中 YARN 的用户组管理自身存在一系列技术挑战。维护另一个守护进程SSSD(如 Apache 文档中所建议的)会增加团队的开销。由于我们正在重新构建整个部署模型,因此我们花费了额外的精力来设计和构建用于用户组管理的稳定系统。
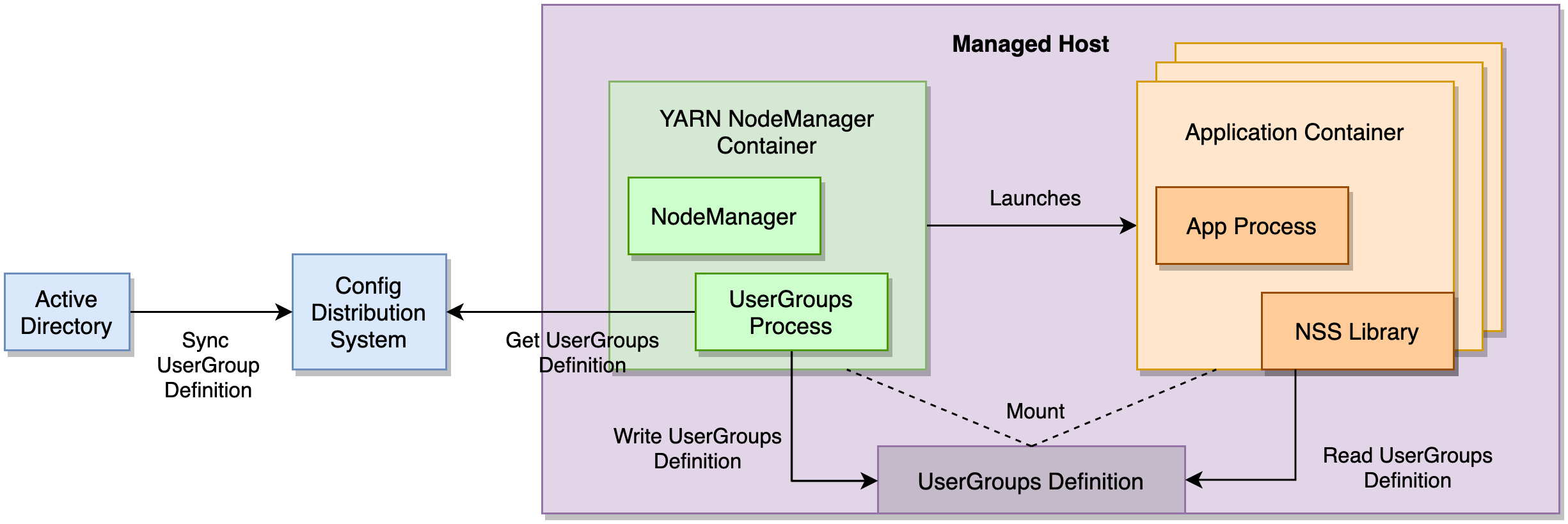
图 6:容器内的用户组
我们的设计是利用一个经过内部强化、信誉良好的配置分发系统(Config Distribution System)将用户组定义中继到部署 YARN NodeManager 容器的所有主机上。NodeManager 容器运行用户组进程(UserGroups Process),该进程观察用户组定义(在配置分发系统内)的更改,并将其写入一个卷挂载,该挂载与所有应用程序容器(Application Container)以只读方式共享。
应用程序容器使用一个自定义NSS库(内部开发并安装在 Docker 镜像中)来查找用户组定义文件。有了这套解决方案,我们能够在 2 分钟内实现用户组在全系统范围内的一致性,从而为客户显著提高可靠性。
配置生成
我们运营着 40 多个服务于不同用例的集群。在旧系统中,我们在单个 Git 存储库中独立管理每个集群的配置(每个集群一个目录)。结果复制粘贴配置和管理跨多个集群的部署变得越来越困难。
通过新系统,我们改进了管理集群配置的方式。新系统利用了以下 3 个概念:
针对.xml 和.properties 文件的 Jinja 模板,与集群无关
Starlark 在部署前为不同类别/类型的集群生成配置
节点部署期间的运行时环境变量(磁盘挂载、JVM 设置等)注入
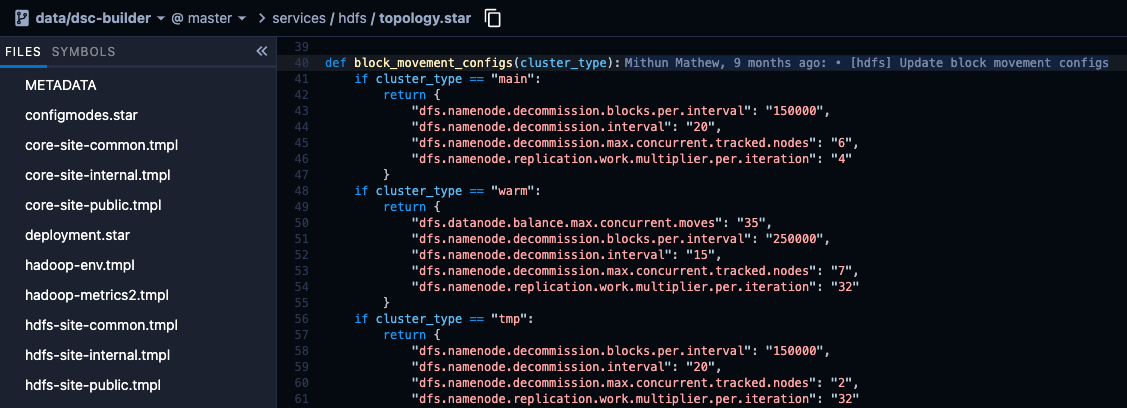
图 7:Starlark 文件定义不同集群类型的配置
我们将模板和 Starlark 文件中总共 66,000 多行的 200 多个.xml 配置文件减少到了约 4,500 行(行数减少了 93%以上)。事实证明,这种新设置对团队来说更具可读性和可管理性,尤其是因为它与集群管理系统集成得更好了。此外,该系统被证明有利于为批处理分析栈中的其他相关服务(例如 Presto)自动生成客户端配置。
发现与路由
在以前,将 Hadoop 控制平面(NameNode 和 ResourceManager)移动到不同的主机一直是很麻烦的操作。这些迁移通常会导致整个 Hadoop 集群滚动重启,还需要与许多客户团队协调以重启相关服务,因为客户端要使用主机名来发现这些节点。更糟糕的是,某些客户端倾向于缓存主机 IP 并且不会在出现故障时重新解析它们——我们从一次重大事件中学到了这一点,该事件让整个区域批处理分析栈降级了。
Uber 的微服务和在线存储系统在很大程度上依赖于内部开发的服务网格来执行发现和路由任务。Hadoop 对服务网格的支持远远落后于其他 Apache 项目,例如 Apache Kafka。Hadoop 的用例以及将其与内部服务网格集成所涉及的复杂性无法满足工程工作的投资回报率目标。取而代之的是,我们选择利用基于 DNS 的解决方案,并计划将这些更改逐步贡献回开源社区(HDFS-14118、HDFS-15785)。
我们有 100 多个团队每天都在与 Hadoop 交互。他们中的大多数都在使用过时的客户端和配置。为了提高开发人员的生产力和用户体验,我们正在对整个公司的 Hadoop 客户端进行标准化。作为这项工作的一部分,我们正在迁移到一个中心化配置管理解决方案,其中客户无需为初始化客户端指定典型的*-site.xml 文件。
利用上述配置生成系统,我们能够为客户端生成配置并将配置推送到我们的内部配置分发系统。配置分发系统以可控和安全的方式在整个系统范围内部署它们。服务/应用程序使用的 Hadoop 客户端将从主机本地配置缓存(Config Cache)中获取配置。
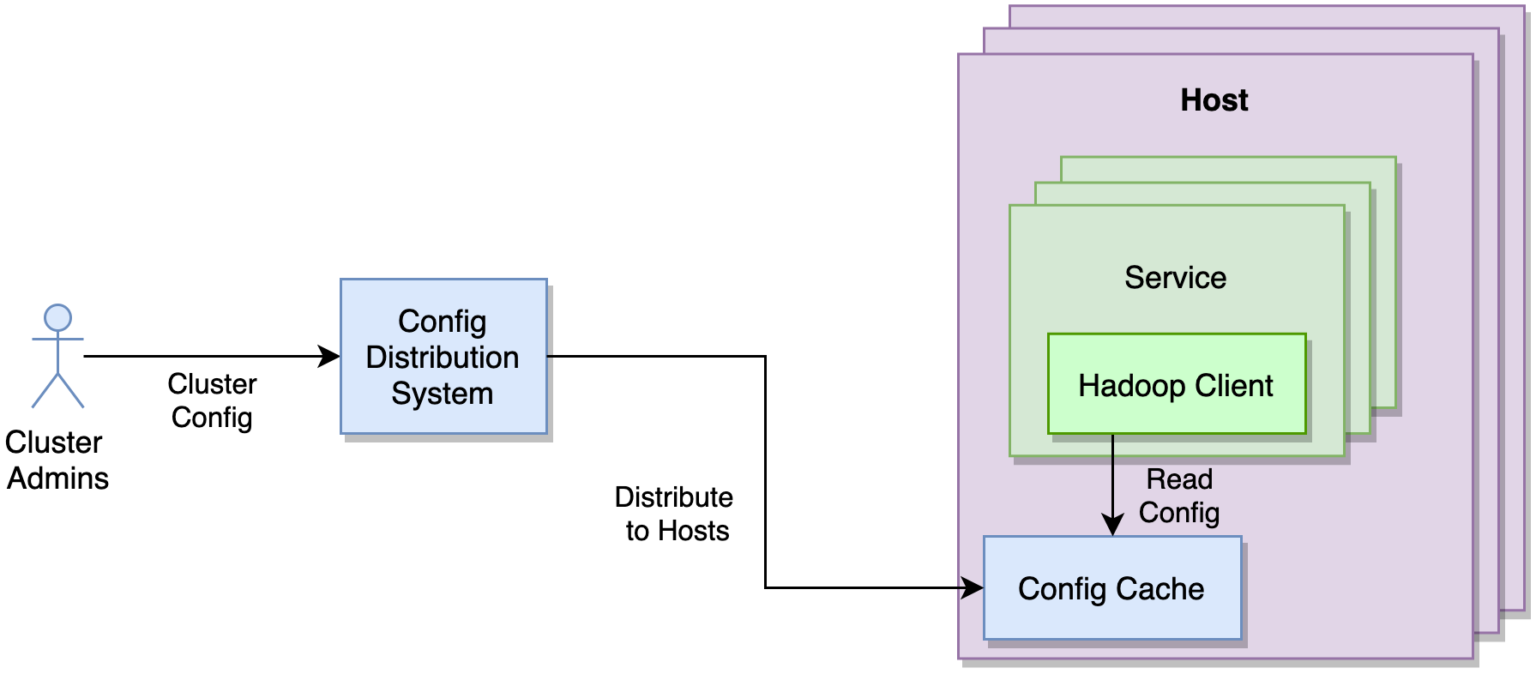
图 8:客户端配置管理
标准化客户端(具有 DNS 支持)和中心化配置从 Hadoop 客户那里完全抽象出了发现和路由操作。此外,它还提供了一组丰富的可观察性指标和日志记录,让我们可以更轻松地进行调试。这进一步改善了我们的客户体验,并使我们能够在不中断客户应用程序的情况下轻松管理 Hadoop 控制平面。
心态的转变
自从 Hadoop 于 2016 年首次部署在生产环境中以来,我们已经开发了很多(100 多个)松散耦合的 python 和 bash 脚本来运维集群。重新构建 Hadoop 的自动化技术栈意味着我们要重写所有这些逻辑。这一过程意味着重新实现累积超过 4 年的逻辑,同时还要保证系统的可扩展性和可维护性。
对 21,000 多台 Hadoop 主机大动干戈以迁移到容器化部署,同时放弃正常运维多年的脚本积累,这样的方案在一开始招致了不少怀疑声。我们开始将该系统用于没有 SLA 的新的开发级集群,然后再用于集成测试。几个月后,我们开始向我们的主要集群(用于数据仓库和分析)添加 DataNodes 和 NodeManagers,并逐渐建立了信心。
我们通过一系列内部演示和编写良好的运行手册帮助其他人学会使用新系统之后,大家开始意识到了转移到容器化部署的好处。此外,新架构解锁了旧系统无法支持的某些原语(提升效率和安全性)。团队开始认可新架构的收益。很快,我们在新旧系统之间架起了几个组件,以搭建一条从现有系统到新系统的迁移路径。
搬运猛犸象
我们新架构采用的原则之一是机群中的每一台主机都必须是可更换的。由旧架构管理的可变主机积累了多年的技术债务(陈旧的文件和配置)。作为迁移的一部分,我们决定重新镜像我们机群中的每台主机。
目前,自动化流程在编排迁移时需要的人工干预是极少的。宏观来看,我们的迁移流程是一系列 Cadence 活动,迭代大量节点。这些活动执行各种检查以确保集群稳定,并会智能地选择和停用节点,为它们提供新配置,并将它们添加回集群。
完成迁移任务的最初预期时间是 2 年以上。我们花了大量时间调整我们的集群,以找到一个尽量提升迁移速度,同时不会损害我们 SLA 的甜点。在 9 个月内,我们成功迁移了约 60%(12,500/21,000 台主机)。我们正走在快车道上,预计在接下来的 6 个月内完成大部分机群迁移工作。
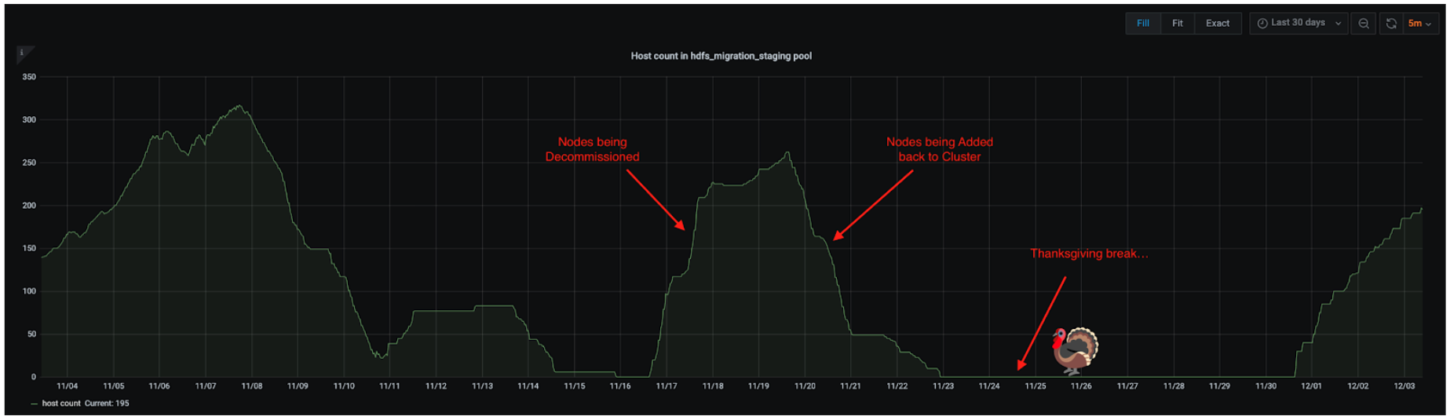
图 9:在大约 7 天内迁移 200 多台主机
要记住的伤疤
如果我们声称我们的迁移非常平滑,那肯定是在撒谎。迁移的初始阶段非常顺利。然而,当我们开始迁移对更改更敏感的集群时,发现了很多意想不到的问题。
丢失块和添加更多防护措施
我们的一个最大的集群有多个运维工作流同时执行。一个集群范围的 DataNode 升级与集群另一部分发生的迁移一起触发了 NameNode RPC 延迟的降级。后来发生了一系列意外事件,我们最后输掉了战斗,导致集群中丢失了一些块,我们不得不从另一个区域恢复它们。这迫使我们为自动化和运维程序设置了更多的防护措施和安全机制。
使用目录遍历进行磁盘使用统计
集群管理器代理定期执行磁盘使用情况统计以备使用率分析,并将其提供给公司范围的效率计划。不幸的是,该逻辑意味着“遍历”存储在 DataNode 上的 24x4TB 磁盘上的所有 HDFS 块。这导致了大量的磁盘 i/o。它不会影响我们不太忙的集群,但对我们最繁忙的一个集群产生了负面影响,增加了 HDFS 客户端读/写延迟,这促使我们增强了这一逻辑。
要点和未来计划
在过去 2 年中,我们对 Hadoop 的运行方式做出了巨大的改变。我们升级了我们的部署,从一大堆脚本和 Puppet 清单转向了在 Docker 容器中运行大型 Hadoop 生产集群。
从脚本和工具过渡到通过成熟的 UI 运维 Hadoop,是团队的重大文化转变。我们花在集群运维上的时间减少了 90%以上。我们让自动化操作控制来整个系统的运维、更换损坏主机。我们不再让 Hadoop 来管理我们的时间了。
以下是我们旅途中的主要收获:
如果没有先进的卓越运维技术,Hadoop 可能会变成一个难以驯服的庞然大物。组织应该定期重新评估部署架构并定期偿还技术债务,以免亡羊补牢。
大规模基础设施的重构需要时间。组织应该为此建立强大的工程团队,专注于进步而不是追求完美,并随时准备好应付生产环境中出现的问题。
感谢所有参与各个架构团队的工程师,我们的架构非常稳固。建议与 Hadoop 领域之外的人们合作以收集不同的观点。
随着我们的迁移任务逐渐步入尾声,我们正在将重点转移到更多令人兴奋的工作上。利用底层容器编排的优势,我们为未来制定了以下计划:
单击一次开通多集群和一个区域内跨多个专区的集群平衡
主动检测和修复服务降级和故障的自动化解决方案
通过桥接云和本地容量来提供按需弹性存储和计算资源
作者介绍
Mithun Mathew 是 Uber 数据团队的二级高级软件工程师。 他之前作为 Apache Ambari 的开发人员参与 Hadoop 部署工作。他目前在 Uber 专注于数据基础设施的容器化。
Qifan Shi 是 Uber 数据基础设施团队的高级软件工程师,也是 Hadoop 容器化的核心贡献者。他一直在参与能够高效编排大规模 HDFS 集群的多个系统的研发工作。
Shuyi Zhang 是 Uber 数据基础设施团队的高级软件工程师。她是 Hadoop 容器化的核心贡献者。她目前专注于 Uber 的计算资源管理系统。
Jeffrey Zhong 是 Uber 数据基础设施团队的二级工程经理,负责管理数据湖存储(Hadoop HDFS)和批量计算调度(Hadoop YARN)。在加入 Uber 之前,他曾参与 Apache HBase 和 Apache Phoenix 的工作。




