
JMeter和Gatling是性能测试工具中的佼佼者。现在已经有很多关于比较这两个工具的文章,那么为什么我还要再这篇文章呢?我将从一个不一样的角度来比较这两个工具。这两个工具我都用了很长一段时间了,我想是时候总结一下我的经验了。
完美的性能测试应该是怎样的
从开发人员的角度来看,测试应用程序的性能是开发人员的职责。因此,让一个从未接触过应用程序源代码的测试团队来测试应用程序的性能,这种方法是行不通的。我并不是说测试人员就无法进行良好的性能测试,我想强调的是,如果我们有专门的性能测试人员,那么从一开始就应该让测试人员和开发人员进行密切的合作。
随着时间的推移,越来越多的责任会转移到测试团队,但开发人员仍然需要对结果进行分析。当结果与我们最初的预期不同时,就尤为如此。当然,这对开发人员来说是有好处的,因为它创建了一个与解决方案质量相关的反馈循环,类似于单元测试、集成测试或端到端(E2E)测试。
性能测试无疑是软件开发当中成本最高的一种测试。测试人员或开发人员需要花宝贵的时间创建它们,除此之外,它们还需要一个专门的(如果可能的话)测试环境。应用程序的变化非常频繁,性能测试需要跟踪这些变化,并保持最新,这比最初创建测试时的成本更高。
基于上述原因,关于性能测试,我的第一个建议是用长期的思维来考虑整个测试过程。理想情况下,性能测试应该是持续部署(CD)的一部分。但这并不一定总能实现,也并不一定是有意义的。然而,根据我的观察,在一开始的性能测试中走捷径可能会让我们在未来付出更大的代价。
如何选择性能测试工具
选择性能测试工具是第一个难题,我希望本文能够帮助你做出正确的选择。
从开发人员的角度来看,一个好的性能测试工具应该具备以下四个主要属性。
可读性;
可组合性;
正确的指标;
分布式负载生成。
你可能会说:“就这样?”是的。这些是在选择工具时最重要的考虑因素。当然,还有很多其他特定的功能,尽管大多数工具在创建测试场景、模拟流量等方面提供了或多或少类似的选项。所以,在选择一个既方便又可维护的工具时,我会把重点放在这些要点上。
只有当一个工具满足了这四个基本要求,我们才能继续了解它提供的其他功能。否则,如果只是受到一些有趣功能的诱惑,从长远来看,这些功能可能既不有趣也不是很有用,它将变成一个不那么好的工具。
可读性
我们先从第一点开始。比较带有 GUI 的应用程序的可读性是一种非常不寻常的方法,我们来看看它会产生怎样的结果。JMeter 中的一个简单的业务流程可能如下所示。
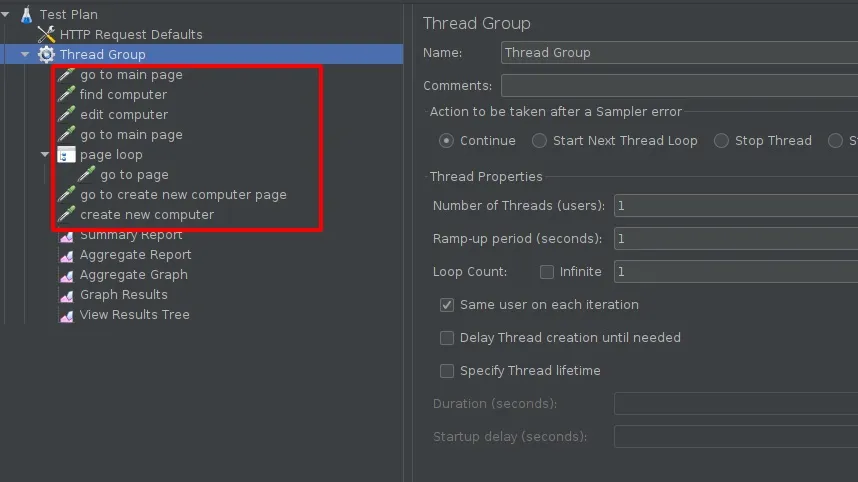
乍一看,相当不错。一切都很清楚,我们很容易就可以理解测试的是什么。问题是,随着我们开始扩展场景,添加新的测试步骤,参数化当前步骤或改变它们的行为,那么很快,我们就会得出这样的结论:这是一项非常乏味的工作。你必须经常使用鼠标,知道什么东西藏在哪里,更糟糕的是,你需要记住各个查询之间的隐式连接(例如,共享变量)。
根据我的经验,在 GUI 上编辑测试用例迟早会变得不那么令人感到愉快,我们将切换到编辑 XML 格式的源代码,而 XML 格式的源代码(通常是 XML 格式)可读性很差。在 XML 中,我们能够做的就是使用最基础的基于字符串的编辑技术,例如“替换”等。
<?xml version="1.0" encoding="UTF-8"?><jmeterTestPlan version="1.2" properties="5.0" jmeter="5.3"></jmeterTestPlan> <hashTree></hashTree> <TestPlan guiclass="TestPlanGui" testclass="TestPlan" testname="Test Plan" enabled="true"></TestPlan> <stringProp name="TestPlan.comments"></stringProp> <boolProp name="TestPlan.functional_mode">false</boolProp> <boolProp name="TestPlan.tearDown_on_shutdown">True</boolProp> <boolProp name="TestPlan.serialize_threadgroups">false</boolProp> <elementProp name="TestPlan.user_defined_variables" elementtype="Arguments" guiclass="ArgumentsPanel" testclass="Arguments" testname="User Defined Variables" enabled="true"></elementProp> <collectionProp name="Arguments.arguments"></collectionProp> </elementProp> <stringProp name="TestPlan.user_define_classpath"></stringProp> ... That's a very, very long XML. ...
完整的 XML 代码在这里。
在 Gatling 中,同样的场景看起来像这样。
val scn = scenario("Example scenario") .exec(http("go to main page").get("/")) .exec(http("find computer").get("/computers?f=macbook")) .exec(http("edit computer").get("/computers/6")) .exec(http("go to main page").get("/")) .repeat(4, "page") { exec(http("go to page").get("/computers?p=${page}")) } .exec(http("go to create new computer page").get("/computers/new")) .exec( http("create new computer") .post("/computers") .formParam("name", "Beautiful Computer") .formParam("introduced", "2012-05-30") .formParam("discontinued", "") .formParam("company", "37") )
它与 JMeter 非常相似,也就是说,你可以看到正在测试的内容以及整体流程。不过,我们不要忘了,这段源代码的可读性几乎和普通语句一样。我们首先会想到的是,既然是源代码,那么我们就可以使用所有已知的重构方法来扩展场景或提高其可读性。
Scala(Gatling 中使用的是 Scala)是一种高度类型化的语言,构造场景的大多数问题将在编译代码时被发现。而在 JMeter 中,只有当场景启动时才会检查错误,这肯定会降低结果反馈循环的速度。
源代码的另一个好处是,测试的版本管理将变得非常容易,并且可以让其他程序员(甚至是来自不同的团队)评审它们。如果你不得不面对数千行 XML,那么只能祝你好运。
可组合性
如果我们需要创建多个共享某些逻辑的性能测试,例如身份验证、用户创建等,可组合性是至关重要的。在 JMeter 中,我们只能通过非常快速的复制粘贴来编辑这些测试。即使是这个简单的测试也存在重复的片段。
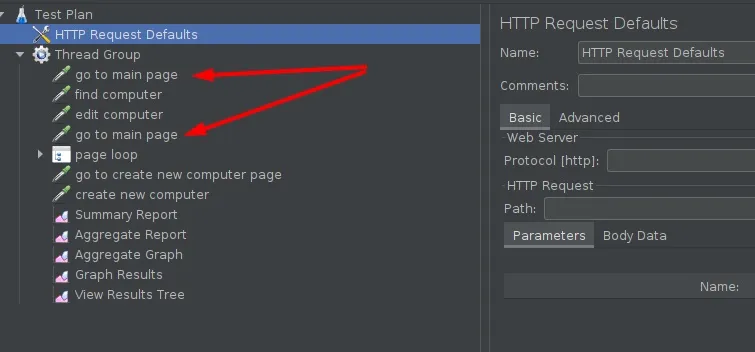
随着时间的推移,需要重复的地方会越来越多。不仅是单个请求,整个业务逻辑片段都需要被复制。你可以使用Module Controller来解决这个问题,或者用 Groovy 或 BeanShell 创建自己的扩展。从我的经验来看,这样做非常不方便而且容易出错。
在 Gatling 中,构建可重用的片段基本上只受编程技能的限制。第一步是提取出一些可以被多次使用的方法。
private val goToMainPage = http("go to main page").get("/") private def findComputer(name: String) = http("find computer").get(s"/computers?f=${name}") private def editComputer(id: Int) = http("edit computer").get(s"/computers/${id}") private def goToPage(page: Int) = http("go to page").get(s"/computers?p=${page}") private val goToCreateNewComputerPage = http("go to create new computer page").get("/computers/new") private def createNewComputer(name: String) = http("create new computer") .post("/computers") .formParam("name", name) .formParam("introduced", "2012-05-30") .formParam("discontinued", "") .formParam("company", "37") val scn = scenario("Example scenario") .exec(goToMainPage) .exec(findComputer("macbook")) .exec(editComputer(6)) .exec(goToMainPage) .exec(goToPage(1)) .exec(goToPage(1)) .exec(goToPage(3)) .exec(goToPage(10)) .exec(goToCreateNewComputerPage) .exec(createNewComputer("Awesome computer"))
接下来,我们可以将场景划分为更小的片段,然后组合它们并创建出更复杂的业务流程。
val search = exec(goToMainPage) .exec(findComputer("macbook")) .exec(editComputer(6)) val jumpBetweenPages = exec(goToPage(1)) .exec(goToPage(1)) .exec(goToPage(3)) .exec(goToPage(10)) val addComputer = exec(goToMainPage) .exec(goToCreateNewComputerPage) .exec(createNewComputer("Awesome computer")) val scn = scenario("Example scenario") .exec(search, jumpBetweenPages, addComputer)
如果我们需要长期维护性能测试,那么毫无疑问,与其他工具相比,高可组合性将是一个优势。根据我的观察,似乎只有那些支持通过源代码来编写测试用例的工具,例如 Gatling 和 Scala、Locust和 Python、WRK2和 Lua 符合这个标准。如果测试用例是用 XML、JSON 等文本格式保存的,那么可组合性总是会受到这些格式的限制。
正确的指标
每一个性能测试人员应该都听到过这个说法:“谎言、该死的谎言和统计数据。”如果他们还没听到过,那么他们肯定会以一种非常痛苦的方式学上一课。我们可以用一整篇文章来讨论为什么这句话会成为性能测试领域的咒语。简而言之:中位数、算术平均值、标准偏差在这个领域是完全无用的指标(你只能把它们当作额外的见解)。你可以在 Gil Tene(Azul 的首席技术官和联合创始人)的精彩演讲中获得更多细节。因此,如果性能测试工具只提供这种静态数据,那么你可以立即把它丢掉。
衡量和比较性能的唯一有意义的指标是百分比,但在使用它们时要注意它们是如何实现的。通常,它们是基于算术平均值和标准偏差实现的,这导致它们变得不那么有用。
你可以从上面的演讲视频中学习如何验证百分比的正确性。
另一种方法是自己检查实现指标的源代码。但遗憾的是,大多数性能测试工具文档并没有涵盖如何计算百分比。即使有这样的文档,也很少有人会去阅读它,因此可能会掉入一些陷阱,例如Dropwizard框架指标的实现。
如果没有正确的数学/统计数据,我们在性能测试方面所做的工作都是毫无价值的,因为我们将无法理解单个测试的结果或结果之间的比较。
我在进行性能测试时通常会使用百分比可随着时间发生变化的图形,Gatling 和 JMeter 都提供了这些功能。我们因此能够判断被测试的系统在整个测试过程中是否存在性能问题。
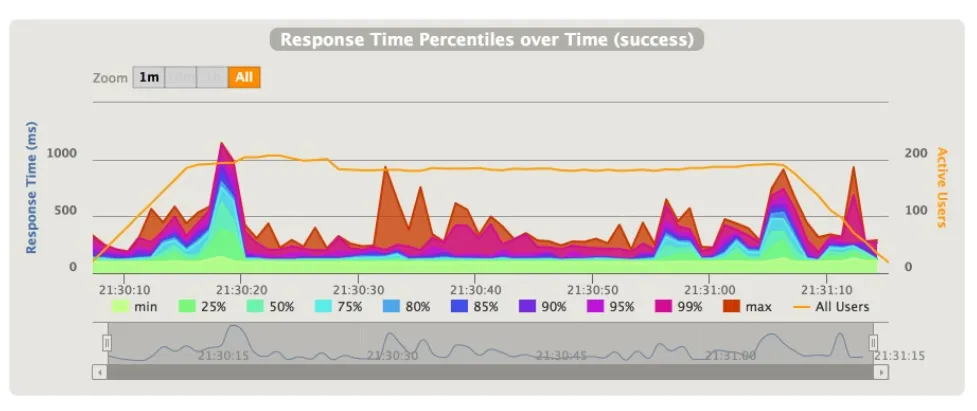
要比较各个测试的结果,你需要使用全局百分比(在两个工具中都可用)。但 JMeter 全局百分比的准确性可能是个问题。Gatling 使用HdrHistogram库来计算百分比,在准确性和内存需求之间做出了一个非常合理的折衷。
分布式测试
有一些文章讨论了测试工具本身的性能。这在一定程度上也很重要,因为我们需要生成巨大的流量给被测试的系统“施压”。问题在于,现在的应用程序很少是运行在单台机器上的单个实例。我们测试的是包含多个实例的分布式系统,这些实例运行在不同的机器上(通常是动态可伸缩的云解决方案)。单台机器的性能测试无法生成足够的负载来测试这样的环境。因此,我们不应该去关注哪个工具可以在一台机器上产生更多的流量,而是看看有没有可以同时从多台机器运行分布式测试的工具。
在这方面,这两个工具打成了平手。我们可以在 Gatling 和 JMeter 中进行手动的分布式测试。此外,我们可以使用现有的解决方案,如Flood或Gatling Enterprise,为我们自动完成分布式测试。我绝对推荐后者,因为它会为我们节省很多宝贵的时间。
总结
尽管本文的基调可能会被认为是在嘲讽 JMeter,但这并不是我的本意,因为这两种工具我都用过。我曾经以为 JMeter 是唯一合理的测试性能工具,但当我开始使用 Gatling 时,我看不到再回到 JMeter 的意义。
一个带有图形界面的工具在一开始可能会更容易使用,但对于我来说,将性能测试作为代码的想法更有吸引力。Gatling 的 DSL 使用起来非常方便,具有很强的可读性,维护起来也容易得多。
很多人对 Gatling 持怀疑态度,因为它要求学习一门新的编程语言——Scala,而 Scala 被认为是一门很难使用的编程语言。然而,事实并非如此。Scala 有其优点和缺点,要在 Gatling 中使用 Scala,只需要掌握基本的语法知识即可。另外,如果你一直希望在工作中使用 Scala,但由于各种原因无法实现,那么性能(和自动化)测试将是一个将这门语言引入你的生态系统的绝佳机会。需要注意的是,从 Gatling 3.7 开始,你可以使用 Java 了!这将是我下一篇文章的主题。请继续关注。
作者简介:
Andrzej Ludwikowski 是SoftwareMill的软件架构师,拥有超过 12 年的商业软件开发经验。他是技术会议发言人和博客作者,领域驱动开发、事件溯源和多语言持久化技术爱好者,喜欢研究系统性能瓶颈问题。他有一个不断追求完美软件架构的梦想,尽管这样的架构可能不存在,但追求梦想本身就是目标。他还是 SoftwareMill Academy 的培训师。
原文链接:
Gatling vs JMeter - What to Use for Performance Testing




