
最近,DoorDash 公布了他们是如何主动将隐私保护纳入其产品的。他们说明了隐私工程的重要性——这是一个经常被忽视的软件架构实践,并提供了一个例子,介绍如何隐蔽用户地址数据以更好地保护用户隐私。
DoorDash 软件工程师 Alex Dougherty 解释了实施隐私工程的动机:
为了方便送货,用户必须向我们提供一些个人信息,包括 […] 姓名、地址和电话号码 […]。Dasher 需要这些信息才能知道在哪里、向谁交付订单。由于这些信息可用于重新识别个人,所以可能被不良行为者利用并带来危害,包括身份盗窃和人肉搜索。
这就是为什么我们要确保在交付完成后的一个合理时间段内在我们的平台上削减(删除或混淆)这些个人数据。这样,即使不良行为者未经授权访问了我们的数据库,也获取不到个人数据,从而防止这些数据被滥用。
数据削减(data redaction)由 DoorDash 分布式系统中的异步作业触发。当用户的数据符合削减条件时,该作业会将消息推送到 Kafka 主题,发出清洗与该用户相关数据的信号。持有用户数据副本的服务会监听该主题,并根据请求削减数据。
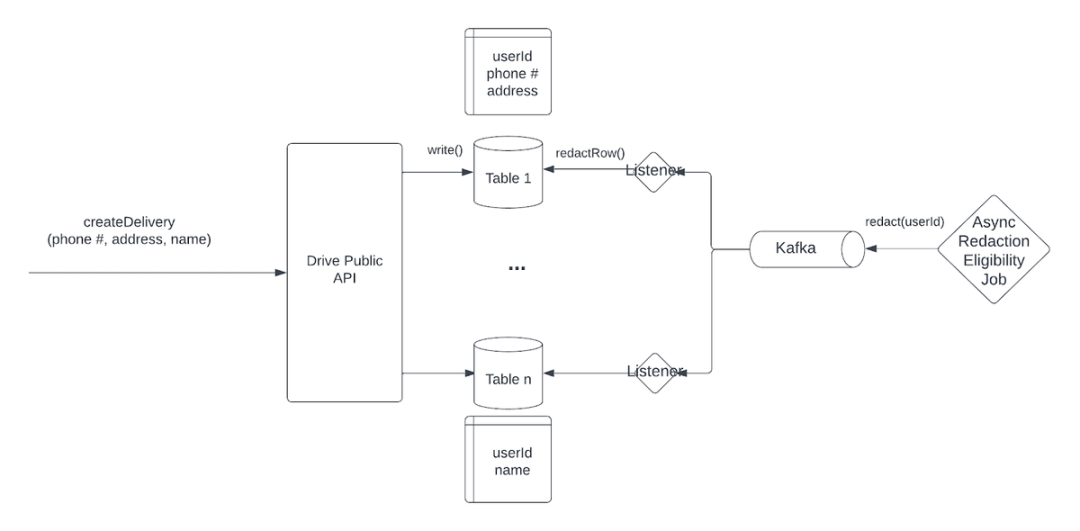
利用 Kafka 消息执行数据削减的异步过程(图片来源 :https://doordash.engineering/2023/11/14/privacy-engineering-at-doordash-drive/)
用户数据削减的一个例子是地址遮蔽(geomasking)。Dougherty 指出,在保护个人敏感信息和利用数据进行分析之间存在一个错误的二分法。
他进一步解释说,DoorDash 并没有完全删除地址数据,而是使用 高斯扰动 来偏移用户的位置。该过程可防止不良行为者重新识别用户,同时又让业务人员可以执行所需的分析和业务优化。
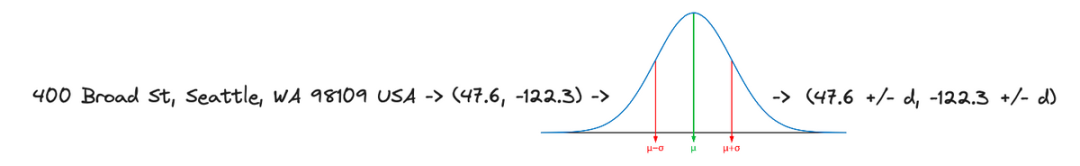
对用户地址进行地理编码并随机偏移其坐标
DoorDash 使用 Spatial k-anonymity 来评估地址遮蔽过程的有效性:
Spatial k-anonymity 会生成一个值“K”,它测量在地理遮蔽完成之后可以被识别为用户“真实位置”的潜在位置的数量。有了这个值我们就可以知道,坏人选择真实位置的概率是 1/K。K 值越大,表明地理遮蔽在保护用户实际位置方面越有效。
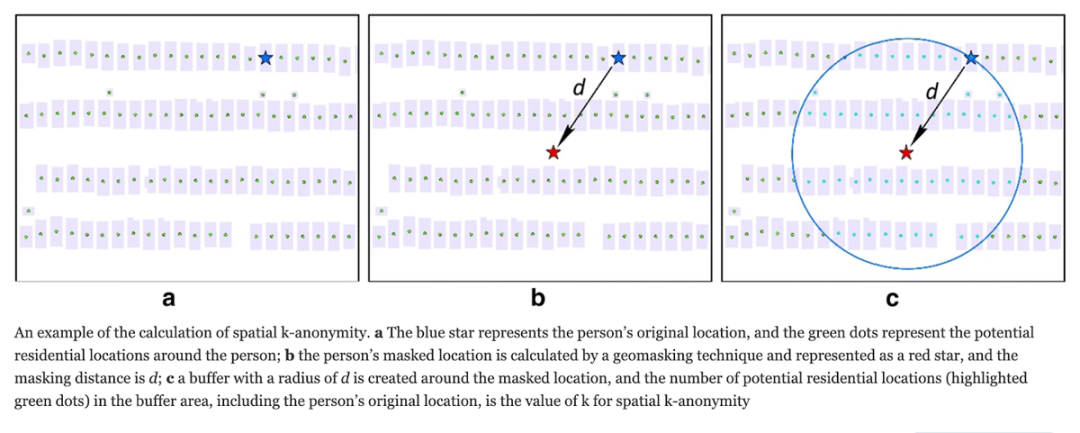
Spatial k-anonymity 示例
Dougherty 表示,用户所在地区的人口密度也会影响地理遮蔽的效果。在城市地区,会有许多其他的用户在实际用户附近的地方购物,这可以降低基于削减数据重新识别用户的几率。但是,在偏远地区,将位置坐标偏移相同的量可能并不足以防止用户的身份被重新识别。
Doordash 设法使 K 值保持在 5 到 20 之间。有了这个值和一个地区人口密度的近似值,他们就可以确定适当的标准偏差数,从而保证用户地址偏移可以成功地削减数据。
原文链接:
https://www.infoq.com/news/2023/12/doordash-privacy-engineering/




