
作者 | 华卫
在 6 月 21 日的华为开发者大会上,华为云盘古大模型 5.0 重磅亮相。此次,盘古 5.0 在全系列、多模态、强思维三个方面全新升级,并推出了适配不同业务场景的多种参数规格模型。

比如,手机和 PC 上的智能应用,可以基于 10 亿级参数的模型,在端侧完成绝大部分任务;少数复杂任务可以通过端云协同,使用云上的百亿甚至千亿模型进行处理。盘古 5.0 还进一步推出了云上 2300 亿的稠密模型和 2.6 万亿的 MOE 大模型,能够帮助企业更好处理复杂场景以及跨领域多任务场景。
除此之外,在现场,华为诺亚方舟实验室主任姚骏详细介绍了盘古 5.0 的重要训练环节,并透露了他们为使盘古 5.0 达到更多模态和更强思维能力所用到的一些“黑科技”,包括数据高效、参数高效和算力高效等方面。
同时,华为云还分享了盘古大模型在自动驾驶、具身智能、媒体生产和应用、气象、钢铁、高铁、工业设计、建筑设计、中医药等领域的创新应用和落地实践。
盘古 5.0 三大创新升级
据介绍,盘古 5.0 提供了全系列的大模型,其推出不同参数规格的模型,以适配不同的业务场景。
其中,十亿级参数的 Pangu E(Embeded)系列,有 15 亿、70 亿两种参数规格,无需联网就可以运行小的大模型,是嵌入到端侧的大模型,可支撑手机、PC、车等端侧的智能应用;百亿级参数的 Pangu P(Professional)系列,提供的参数在 100 亿到 900 亿之间,可以解决大部分 AI 的应用场景,拥有低时延、低成本的优势。适用于低时延、低成本的推理场景;
千亿级参数的 Pangu U(Ultra)系列,有 1350 亿、2300 亿两种参数规格,适用于处理复杂任务,可以成为企业通用大模型的底座;万亿级参数的 Pangu S(Super)系列超级大模型有 2.6 万亿参数,是处理跨领域多任务的超级大模型,能帮助企业更好的在全场景应用 AI 技术。
在多模态能力上,盘古 5.0 在理解和生成做了提升。盘古 5.0 能够精准的理解和重构物理世界,能够支持在 10K 超高分辨率的图片和视频中准确理解微小的细节内容;在生成方面,其采用了业界首创的 STCG(Spatio Temporal Controllable Generation,可控时空生成)技术,聚焦自动驾驶、工业制造、建筑等多个行业场景,可生成更加符合物理规律的多模态内容。
理解方面,除文本、图片、视频外,盘古 5.0 还增加了雷达、红外、遥感等更多模态。现场,华为常务董事、华为云 CEO 张平安分别展示了盘古在这些模态层面的理解和识别能力。

首先是卫星遥感图像,盘古大模型能够准确的分析出区域农作物的生长状况和收成状况,可以用于农作物的产链预估和整体病虫害的监测。其次是红外影像,当可见光没法看清的时候,盘古大模型可以通过红外影像准确识别车辆和人的运行轨迹,来进行交通管理和灾难防范。最后是雷达影像,盘古大模型能通过可见光和雷达的影像综合来判断植被的覆盖情况,让生态部门对于自然保护地进行监测。
思维能力上,盘古 5.0 将思维链技术与策略搜索技术深度结合,极大提升了数学能力、复杂任务规划能力以及工具调用能力。思维链帮助智能体(如机器人)更好地理解和预测环境变化,而"策略搜索"则是智能体用来适应这些变化并做出决策的过程。两者共同作用,使得智能体能够在复杂环境中进行有效的学习和决策。
值得一提的是,盘古 5.0 的多模态生成能力,还可以为自动驾驶领域提供更高质量的数据支持。张平安表示,盘古 5.0 通过 STC 技术,可以大规模生成和实际场景相一致的驾驶视频数据。
据介绍,其生成的视频不仅在视觉上逼真,更重要的是在车辆行为、环境互动等方面与现实情况保持高度同步。例如,车辆在不同摄像头视角间的平滑过渡,以及在不同天气和光照条件下行驶的自然表现,都显示了模型对空间和时间维度精准把握的能力。尤为特别的是,模型在生成雨天视频时,还能细腻地模拟出车辆尾灯因光线昏暗而开启的细节。
通过盘古大模型生成的六摄像头视角视频,自动驾驶系统可以直接获取到全方位、高仿真度的训练素材。张平安表示,未来盘古的多模态生成还会支持更多的自动驾驶场景。
盘古 5.0 是如何炼成的?
“盘古 5.0 如今具备的更多模态和更强思维能力,源于华为云 AI 算力平台对模型的高效使能训练,主要是数据高效、参数高效和算力高效三个方面。”

面向高阶能力的数据合成方法
据姚骏透露,华为云已经从盘古 3.0 时代的 3T Tokens 的数据,演进到了盘古 5.0 的 10T Tokens 的高质量数据,其中合成数据占比超过了 30%。其目的是提升数据的利用率,并且用更优质的数据来激活模型中更多的能力。
“未来合成数据会在更大规模的模型训练中占有一席之地,来弥补高质量自然数据增长不足的空缺。”姚骏认为,现在业界大模型训练数据的规模已经从万亿级 tokens 迈入十万亿 tokens,到这个量级以后,公开的高质量数据的增长就难以跟上模型的体量增长速度了。
据介绍,华为云探索了优质的、面向高阶能力的数据合成方法。简单来说,就是以弱模型辅助强模型的 weak2strong 方法,采用迭代式的合成高质量数据,保证其有不弱于真实数据的完整性、相关性和知识性。
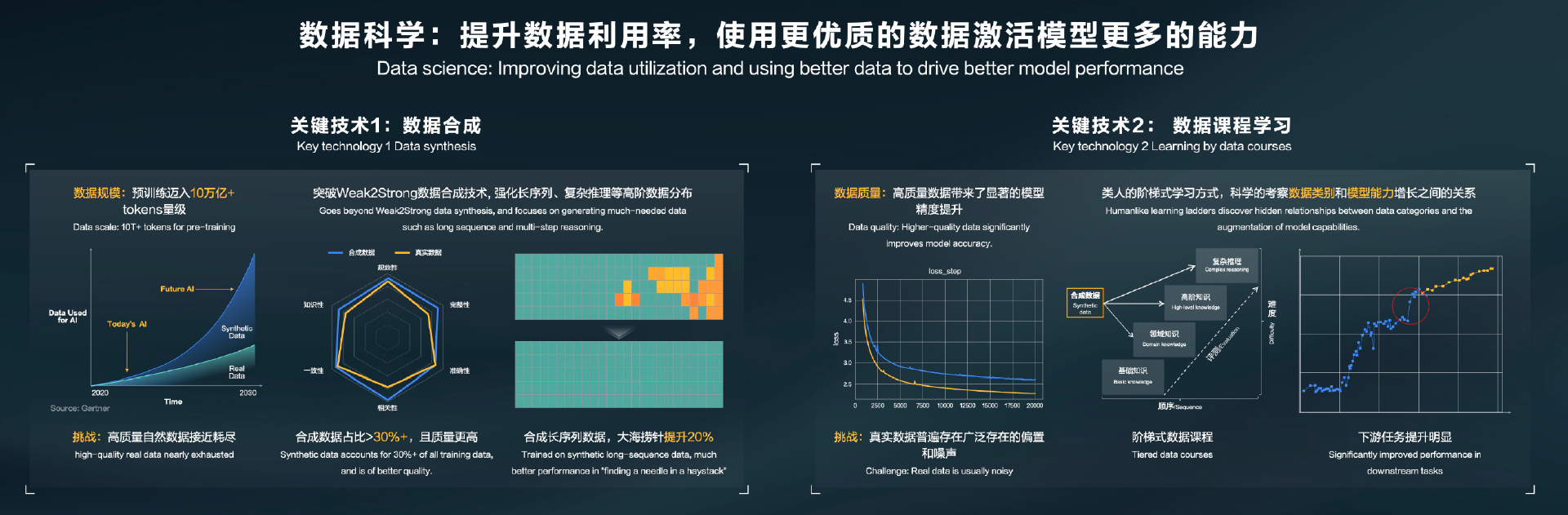
从姚骏展示的能力图中可以看到,合成数据的质量从各个维度都略强于真实数据,在质量上对真实数据形成了一个包络。并且,weak2strong 技术可以进一步加强合成数据中特定的数据,如自然数据中偏少的长序列、复杂知识推理等方面,并通过这些数据来加强模型的特定能力。
新的π架构
盘古 5.0 也演进了模型架构,提出了基于 Transformer 架构的新型大语言模型架构盘古π。
原始的 Transformer 架构和其它深度模型一样,存在一定的特征坍塌问题。华为云通过理论分析发现,Transformer 中的自注意力模块(也就是 Attention 模块)会进一步激化数据的特征消失。对此,业界通过为原始的 Transformer 增加一条残差连接,来略微缓解特征坍塌问题。
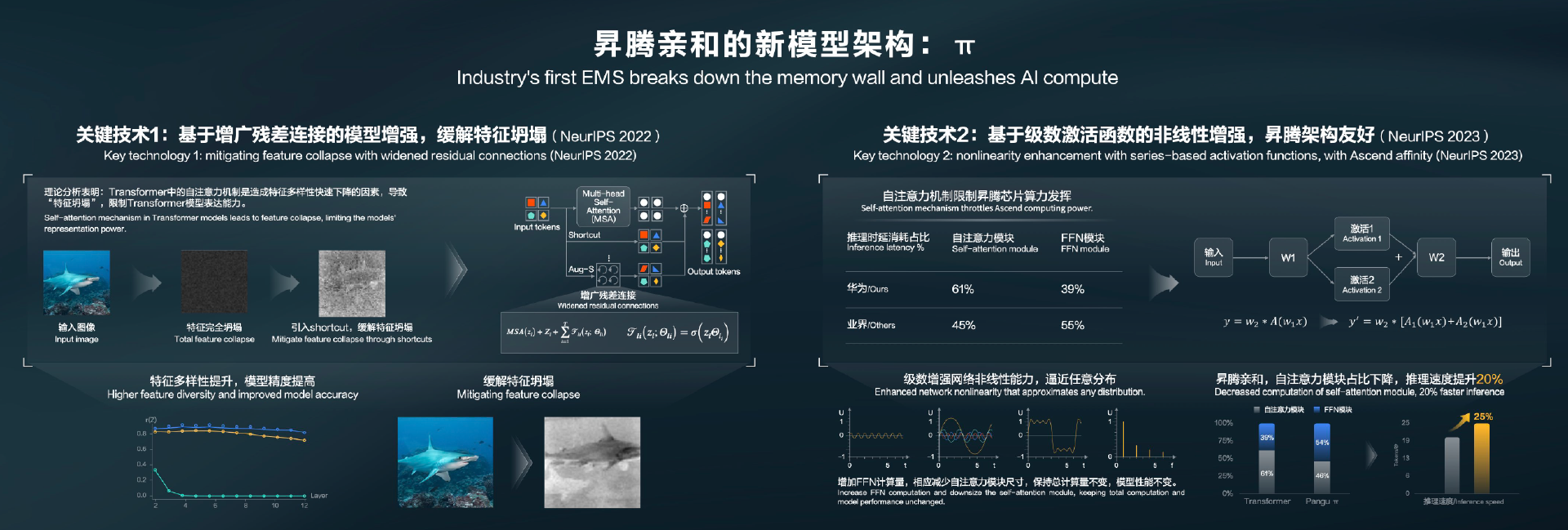
在π的新架构中,华为云进一步提出增广残差连接,通过引入非线性的额外残差,更进一步加大来自不同 Token 的特征,使数据的特征的多样性得以在深度的 Transformer 中得到维持,进而大幅提升模型的精度。
另外,Transformer 包含 FFN 和自注意力模块两个关键模块,华为自研的昇腾芯片更擅长于处理 Transformer 中的 FFN 模块,而对自注意力模块的效率不高。在新的π架构中,其改造了模型中 FFN 模块中的激活函数,用一种新的级数激活函方式来代替。这种新方式不仅增加了模型的非线性度和 FFN 的计算量,还可以在精度不变的情况下减少自注意力模块的大小,使得模型在昇腾芯片推理速度也由此提升了 25%。
扩展多模态能力的关键技术
一直以来,多个模态的高效对齐是训练多模态大模型的一大挑战。其中,视觉编码器是多模态大模型处理输入的第一步,用于将不同类别、大小的图像输入到同一个表征空间,相当于语言模型的 Tokenizer 。由于领域的不同,传统处理图像,视频,文本和图表时,需要用各自的独立的编码器各自接入多模态大模型,这造成了模型容量浪费和计算冗余。

为扩展多模态能力,盘古 5.0 采用了两个关键技术。第一个是统一的视觉编码器,在盘古 5.0 中,华为将不同的编码器能力蒸馏到一个统一视觉编码器中,可以大大提升编码效率。和同参数量业界 SOTA 模型相比,由于利用了不同领域之间内的共通知识,编码器在自然图像能力基本持平,文档理解能力上有显著提升。这种方案现在也成为了业界的主流编码范式。
另一个关键技术是动态分辨率。人看世界有不同的分辨率,但模型的输入一般是固定的,很难兼顾。华为提出了尺度泛化的训练范式,首先使用低分辨率图片和简单任务训练基础感知能力,然后使用中高分辨率训练 OCR 和图表理解等细粒度感知能力,第三阶段扩展到更高的分辨率和更多的任务类型,最后重点突破模型的高阶推理能力。
姚骏表示,这种动态递增的方式帮助盘古 5.0 在动态分辨率的表征上超过业界同等模型,并有效提升了模型在下游多模态任务的能力。
超 1 0 倍参数量加成的强思维方法
当前在单步任务和文本记忆类任务,如知识问答和考试,大模型已经展现出超过人类的卓越表现。而在多步推理和复杂任务的处理上还没有达到人类的平均水平,如代码生成、数学运算、逻辑推理等。前一种能力叫做记忆型能力,适合于大模型用一步的快速思考进行回答;后一种是复杂推理,模型需要像人一样,在这类问题上把快思考变成慢思考,一步一步的分解和完成对复杂问题的处理。
从这点出发,华为云提出基于多步生成和策略搜索的 MindStar 方法。该方法首先把复杂推理任务分解成多个子问题,每个子问题都会生成多个候选方案,通过搜索和过程反馈的奖励模型,来选择最优多步回答的路径。这样既兼顾了人类一步一步思考的形式,也兼顾了机器更擅长的策略搜索的形式。

据姚骏介绍,在华为自建的难例评测集中,MindStar 方法使模型的平均能力提升了 30 分,使用 MindStar 的百亿模型达到业界主流千亿模型的推理能力,相当于使用慢思考能带来 10 倍以上的参数量的加成。
“把 MindStar 这类强思维方法运用到更大尺度的模型上,就能逐步在复杂推理上也接近人和超越人的能力。”姚骏表示。
夸父机器人亮相展示
会上,华为云推出了盘古具身智能大模型,搭载盘古能力的人形机器人“夸父”也同步亮相。盘古大模型能够让机器人完成 10 步以上的复杂任务规划,并且在任务执行中实现多场景泛化和多任务处理。同时,盘古大模型还能生成机器人需要的训练视频,让机器人更快地学习各种复杂场景。

现场,夸父人形机器人通过识别物品、问答互动、击掌、递水等互动演示,直观展示了基于盘古大模型的能力成果。据悉,通过模仿学习策略,华为云与乐聚公司显著提升了人形机器人的双臂操作能力,实现了软硬件层面的协同优化,不仅增强了机器人综合性能,还克服了小样本数据训练的局限性,推动了泛化操作能力的边界。
“正如大家所期望的,让 AI 机器人帮助我们去洗衣、做饭、扫地,让我们有更多的时间去看书、写诗、作画。”张平安表示,除了人形机器人,盘古具身智能大模型还可以赋能多种形态的工业机器人和服务机器人,让它们帮助人类去从事危险和繁重的工作。
盘古媒体大模型推出
华为云推出了盘古媒体大模型,通过在语音生成、视频生成和 AI 翻译三方面的技术创新,重塑了内容生产和应用的新模式。
通过盘古,可以将实拍视频转换为不同风格的高清动漫。在现场演示的生成视频中,演员的舞蹈、武打等大运动轨迹能保持一致视觉效果,角色的面貌特征也保持前后一致。
在语音生成方面,盘古大模型通过 AI 原声译制与视频生成能力,实现了将原片译制成不同语言的视频,并保留原始角色的音色、情感和语气。更为重要的是,盘古还能同步生成新的口型,确保不同语言对应的口型一致,使得跨语言沟通更加自然流畅。
此外,在 AI 翻译方面,华为云盘古大模型也对云会议系统进行了升级。通过基于大模型的语音复刻、AI 文字翻译以及 TTS 技术,实现了语音的同声传译,这使得不同国家的人在云视频会议中可以畅快地使用母语交流。结合数字人技术,在不方便开摄像头时,用户还可以通过数字人参会,并通过口型驱动实现数字人以各种语言说话都能精准匹配口型,如同本人说话一般。
结语
过去一年中,盘古大模型已在 30 多个行业、400 多个场景中落地。现场,张平安还介绍了该模型在政务、金融、制造、医药研发、煤矿、钢铁、铁路、工业设计、建筑设计、气象等领域发挥的能力。
据悉,目前盘古大模型已经在宝武钢铁集团 1880 热轧生产线上线,将时序数据、表格数据、工艺参数、行业机理等 token 化,显著降低了热轧生产线调优时间,预测精度提高 5%以上,钢板成材率提升 0.5%,预计每年可以多产钢板 2 万余吨,年收益达 9000 余万元。华为云还与宝武钢铁集团在炼钢、表检、新钢种研发、排程优化等多个领域开展盘古大模型的应用研究。
此外,张平安宣布,盘古气象大模型再升级,推进至更高难度的公里级区域预报,实现了从全球 25 公里模型向 1 公里、3 公里、5 公里区域预报精度的跨越,包含气温、降雨、风速等气象要素。现在盘古气象大模型的应用范围已经延伸至行业服务,扩展到污染物预测、农业生产指导等多个领域。
特别是在环境治理方面,华为云与天融环境公司合作推出“环境大模型”,将污染六项的预测准确度全面提升 10%以上,并且将预测窗口从 3 天提前至 7 天,为环保部门提供了更长的预警时间,有助于更加高效地进行污染源的定位与治理。
除了盘古大模型的升级,华为云还对昇腾 AI 云服务进行了优化。昇腾 AI 云服务可实现万亿参数模型训练 40 天无中断;平均集群故障恢复时间 10 分钟,同时能将大模型的资源开通时间从月级缩短到天级。目前昇腾 AI 云服务已全面适配行业主流的 100 多个大模型,以云服务的方式协助开发、训练、托管和应用模型。




