本文翻译自一篇 Medium 反响热烈的文章,作者是 Martin Sandin,翻译已获得本人授权。
这篇文章介绍了四种组织代码的策略:元件组织法、工具箱组织法、层组织法、类别组织法。我认为这四种策略形成了一定的层次体系,每种策略各针对不同的代码内聚力类型。根据我个人的经验,这四种策略涵盖了实际组织代码时可能遇到的所有情况。组织代码的策略也许有无数种,但我从未见到有人根据创建日期来组织工程中的包,或是根据首字母顺序组织包中的类。
组织代码的原因和定义
关于如何开发程序,你所获得的大部分建议基本上都在教你如何组织代码,并不与计算机技术相关,这是很有趣的一件事。就计算机本身而言,耦合性与内聚力基本上与其无关。计算机并不关心你是否把所有代码都放在一个文件中编写,或是根据字母顺序对类进行排序,又或者将所有变量都以单字母命名。合理组织代码的目的并不是让计算机理解你的代码,而是让其他人能够很好地读懂你所编写的代码,进而在某种程度上高效而自信地维护代码并做二次开发。
代码的编写应当首先让其他人能够读懂,其次才是让机器能够执行。
——《计算机程序的结构和解释》(Abelson、Sussman 著)
当一段代码写得太长并且包含太多元素时,这段代码就会变得非常复杂,不容易让人定位信息、纵览概况,也就很难让人理解清楚代码各部分的功能。解决这个问题最好的方法就是“分而治之”——将复杂的大段代码分解为多个小部分,每个小部分可以分别独立地进行理解。对于类来说,这种方法可以帮助我们创建内聚力较强的逻辑对象,它也同时适用于域模型。对于分开编译的工程来说,我们必须消除循环依赖关系,确保工程间拥有逻辑合理而稳定的接口。在工程和类之间的层次(Java 中的包或 C#中的命名空间),代码的组织方法有很多变种。在我自己的经历中,许多开发者并没有经过太多的考虑就选择了某种组织代码的策略,然而他们并不了解为什么要使用他们所选的策略。
这篇文章介绍的前三种策略适用于类、包、工程等层次的代码组织,而最后一种类别组织策略则或多或少地专门针对包层次的代码组织。
策略一——元件组织法
元件组织法可以使代码的复杂程度最小化,它主要关心代码单元(比如包)外部的衔接性和内部的内聚力。外部衔接性是指包拥有最少的接口,接口的功能与元件提供的服务关联性很强;内聚力则是指包内部的代码拥有较强的内在关联性。
完全独立的电子元件
关于一份优秀的代码抽象应当包含怎样的内容,这个主题可以衍生出不少的文章,而且现在已经有很多文章介绍这个问题了。如果在这里我们也来讨论代码的抽象化原则,即使仅仅涉及问题的一小部分,也会使本文篇幅过长。可以这么说,代码抽象最好的入门方法是学习 SOLID 原则。在学习过程中,实践并思考每个流程的原理至关重要。而在这篇文章里,我只会介绍在我自己的实践经历中使代码库复杂度急剧增长的一个最普遍的原因。许多人也确实在代码库上尝试使用“分而治之”的方法进行过代码组织,但却最终没能成功将包分解为元件。
创建一个新的代码单元,通常的做法是识别一个或多个已有包中的一部分功能并生成一个新的抽象。这就意味着代码单元的总数变多了,相应地每个代码单元的体量变小了,代码更容易被理解消化。然而这还只是第一步,总体的复杂度还没有降低。接下来我们需要消除依赖关系。
我认为,含有相互依赖关系的包不能被视为独立的代码单元,这是因为单独只看一个包的内容并不能完全理解它的代码。在上面的例子中可以直观地看到,Graph 类与 GraphStorage 类关联,GraphStorage 类不允许被修改。不仅 graph_storage 包依赖着许多 graph 包的域模型,而且这些包相互间也有着依赖关系。最容易消除的依赖关系通常是新创建的包对旧包的依赖:

之所以认为这是一个提升,最重要的原因是当我们在阅读 storage 的代码时,我们可以确定代码功能所涉及的对象都包含在了 Storable 接口中。
客户端不应该依赖它不需要的接口。
——接口隔离原则
下一步则是消除 graph 包对 storage 包的直接关联。举例来说,一种消除关联的方法是在 graph 包中创建一个 GraphPersister 接口,让更高一层的包与 Graph 包对接。这样最大的好处又是使 graph 包所依赖的 storage 包的功能变得清晰明确了。
这个过程理论上听起来很简单,但实际上确定合适的元件和分离策略需要花费许多工夫。通常你会在过程中发现提取的抽象不正确,一切所做的更改又要推翻重来。然而,合理分离好元件的回报也是巨大的,你可以获得容易理解的代码,代码也能简单地升级、测试以及重复利用。
策略二——工具箱组织法
工具箱组织法主要关注外部衔接性,它提供了一种稳定的工具箱,使用者可以从工具箱中选取自己需要的东西。这个策略使用的前提是代码具有很强的内聚力。工具箱一般由接口的互补执行机制组成,使用者可以选取需要的执行机制或是将多个执行机制组合起来使用,但在一次执行时并不同时使用多个机制。

- 集合库的组织方法就是典型的工具箱组织法,涉及一系列集合接口的互补执行机制,这些集合接口的特性受到时间复杂度、内存占用率等因素的影响。工具箱也可能拥有一个统一的主题,比如只包含基于磁盘的数据结构。
- 日志库本身不一定是工具箱,但它通常包含一个日志写入器的工具箱。
正因为用户可以很方便地使用工具箱,并且工具箱中的每一个“工具”尽管各自独立但都不够大不足以授权自身的代码单元,所以工具箱得以发展完善。GUI 库中的每个元件可能拥有各自的包,但如果给每个元件都建一个工程就会造成不必要的浪费。相似地,每个集合实现可能都分别适用于一个单独的包,然而把它们分别放在不同的包中则会产生大量冗余。不过在这个例子中,为了符合外部一致性原则而保持简洁的外观,一个包含了若干类的集合实现则需要拥有其单独的包。
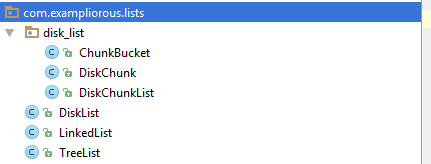
符合外部一致性原则的 DiskList 工具箱
策略三——层组织法
层组织法的重点主要是促进工作流的内聚力,而不是通过最小化跨单元的耦合项来降低代码的复杂程度。它根据部署方案等规则划分层的边界,进而将代码进行分割。这个策略与工具箱组织法不同,层与层之间并不存在一个最小的连贯接口。层接口的构成要素很多,它们可以被用户层中对应的构成要素分别访问。

跨层的元件耦合项
层组织法的典型特征是跨层逻辑元件间的逻辑耦合关联比同一层内的逻辑元件更强。这个策略失效最常见的情况是在实施代码组织时,需要跨所有层创建文件,这也就是教科书上定义的紧密耦合的实例。
给定两个代码单元 A、B,当 A 改变时 B 也必须跟着改变,则称 A 与 B 耦合。
—— C2 Wiki 中的定义
在这种情况下,逻辑元件内的依赖通常会使多个解耦后的层变成一个非常复杂的单元。
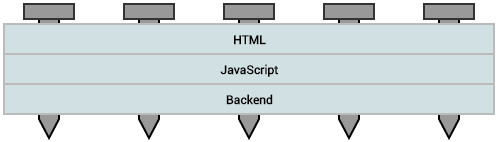
多个解耦后的层形成一个极为复杂的单元
实际中应当谨慎使用层组织法,因为层组织策略常常提高而非降低了系统总体的复杂度。不过在某些情况下,层组织法所带来的好处远远大于它的缺点。这时,将层的依赖隔离在用户代码中的一处就非常值得一试了。
策略四——类别组织法
类别组织法适合整理过于复杂的代码单元,它将不同的代码部分放在相应的基于类或接口类别的 bucket 储存单元中。在这一分类过程中,依赖关系、概念联系以及一些典型的生成包(名称通常为 exception、interface、manager、helper、entity 等)都被忽略了。
类别组织法也与工具箱组织法不同,它舍弃了一些表象的东西,比如包中互补、可互换的类可以组成一种合理的库。在我认识的人中,没有人主张用类别组织法在不同的类或工程中组织代码。
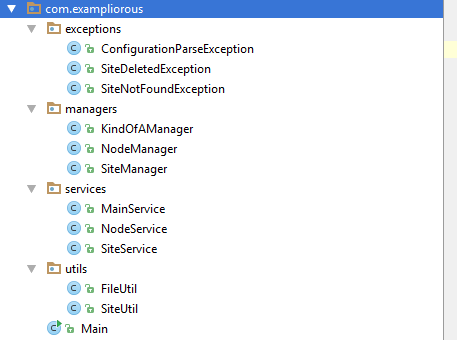
类别组织法组织的工程
我认为类别组织法不适合用来组织代码,因为它隐藏了复杂代码实际存在的问题,这样会误导开发者认为代码中的问题已得到修复,然而实质上问题并没有彻底解决,整体的复杂程度也没有降低。类别组织策略另一个比较大的缺点是,在极端情况下要求每一个类都可以划分入一个确切的类别。我曾遇到过这种极端的情况,就为了使所有代码都有一个匹配的包,整个代码库中创建了一些奇奇怪怪的东西,比如代码管理器、帮助器等。
我将类别组织法视为一种“代码味道”,不过从我个人的经验上来看,类别组织法广泛用于组织商业软件的代码(主要用 Java 或 C#编写)。类别组织法在分割大型包方面提供了简单的解决方案,而对于大多数人而言,包的大小并不是主要矛盾,类别组织法成功解决了代码各部分独立性的问题,因此它经常应用于商业性质的软件开发中。
总结
对于软件开发者来说,组织代码是一项核心技能。和其他技能一样,最快的提升方法是仔细思考一下为什么放弃先前的选择。组织代码有着许多不同的策略,而最重要的则是要学会辨别这些策略中哪些是有效的、哪些是会带来危险的。
查看原文链接: Four Strategies for Organizing Code
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




