
云应用程序让开发人员很容易就相信资源的位置不再那么重要,只要你需要的资源都在云端,这种观点在很大程度上是对的。
但如果是一个移动应用程序,特别是一个依赖了遗留数据存储中的数据的应用程序,那么资源(包括数据)的位置就会变得非常重要。
由于移动应用程序日益成为人们与软件系统交互的首选方式,因此资源的位置是开发人员必须时刻考虑的东西。
在本系列之前的文章中,我们介绍了最小可行架构(Minimum Viable Architecture,MVA)的概念,并描述了 MVA 如何改变你对使用架构框架、模式和策略的看法。
在本文中,我们将探讨与分布式计算工作负载及其相关数据有关的模式和策略,同时讨论涉及分布式时(几乎总会如此)MVA 必须考虑的问题。
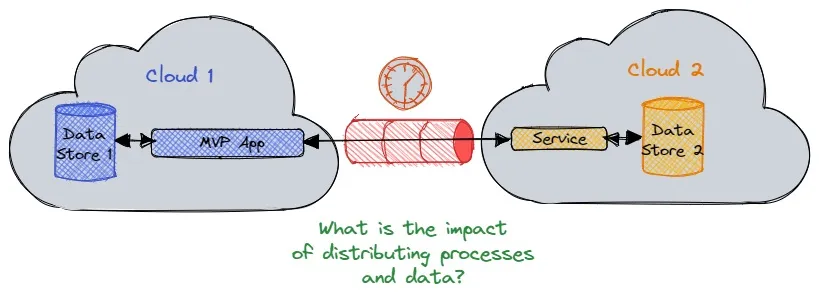
对于用户和开发人员来说,最令人沮丧的一个问题可以用一句话来概括:“它在我的机器上运行良好……”有时候,这些问题与机器配置有关,开发人员的硬件/软件配置与用户不一样。总的来说,这些问题相对容易诊断,因为配置是静态的,通过比较两个环境就可以很容易地找出问题所在。
与应用程序逻辑或数据分布相关的问题更为棘手,而且往往是间歇性的。原因分布式问题通常只在较高的负载下才会出现,所以除非开发人员能够在他们的环境中模拟真实的负载,否则他们很难发现问题。光纤网络的速度可以在很长一段时间内隐藏许多分布式问题,直到网络容量饱和,应用程序的性能开始对开发者所做的架构决策变得更加敏感(通常是隐式的)。在这种情况下,开发者很容易责怪网络,而不是他们自己对分布式问题的忽视。
分布式存在什么大问题
在这个光纤网络时代以及全球分布式云数据和云处理的背景下,我们还没有摆脱对应用程序在哪里运行和数据在哪里存储的担忧吗?简单地说,还没有。即使数据与应用程序存储在相同的数据中心里,也会出现分布式问题,而全球分布只会加剧这个问题。我们来看看影响应用程序架构的两种不同的分布方式:分布式应用程序逻辑(代码)和分布式数据。
分布式 MVA 应用程序逻辑
现今的应用程序是高度可移植的,这意味着它们可以相对容易地从一个计算环境转移到另一个计算环境,可以使用可移植语言,也可以使用虚拟机或容器。那么,为什么移动代码运行环境是架构需要关注的一个问题呢?
即使应用程序代码是可移植的,即使容器隐藏了底层的计算环境,底层物理机器仍然可能绊倒粗心的人。时间戳就是一个简单的例子。应用程序通常基于底层硬件的配置来设置时间戳。如果一个应用程序运行在亚洲,另一个在北美,那么亚洲应用程序可以从北美应用程序的角度来创建时间戳,因为亚洲应用程序和北美应用程序位于国际日期变更线的两侧。这可能会导致错误和失败,导致整个应用程序崩溃,或导致依赖时间的计算产生奇怪的结果,比如隔夜银行资金利息。当使用数据库服务器 DATE 函数设置时间戳,而这些服务器位于与应用程序不同的时区时,也会出现类似的问题,因为记录的日期将根据服务器的位置来确定。
如果应用程序是由在世界各地的服务器上运行的微服务所组成的,那么问题就更难被发现了。在这种情况下,时间戳中使用的时区难以预测。
解决这个问题的一个办法是使用一个全球一致的时间,无论在什么地方,对于所有人来说都是相同的(就像水手在导航中使用UTC一样)。是否创建和使用这样的服务是一个重要的架构决策。使用 UTC 并不能解决与公共日期/时间相关的所有问题,但这是一个良好的开端。剩下的一些问题,包括日期/时间戳是否真的需要时间组件(并不是所有的应用程序都需要时间组件,而且对某些应用程序来说,使用时间组件会让人感到困惑)、日期和时间应该如何显示在屏幕上和报告中(它应该是本地日期/时间还是 UTC 日期/时间?),等等。你仍然有一些重要的问题需要解决,但至少可以基于对记录日期/时间达成的共识来做出这些决定。
一个更微妙的问题来自服务间通信。当所有的服务都运行在相同的物理环境中,从运行时间来看,服务间通信的“成本”非常低,换句话说,通信延迟很低。如果这些服务被移动,不再位于同一台机器上,甚至很可能不在同一地方,那么通信延迟可能会出现不可预测的跳跃,因为服务调用可能需要穿越网络、桥接器和路由器,每一次穿越都增加了往返时间。与时间戳一样,当负载均衡器试图平衡计算负载并无意中增加通信延迟时,这个问题就会加剧。
分布式 MVA 数据
正如《InfoQ 2022 年趋势报告:架构与设计篇》所指出的那样:
数据+架构是指软件架构更多地适应数据……我们看到了一个变化,从只在系统存储或传输层考虑数据,到数据成为系统定义的一个元素。
数据的位置是大多数 MVA 的关键考虑因素。在采用分布式应用程序逻辑的同时保持数据集中,这可能是因为 MVP 所需的大多数数据位于集中的遗留数据存储中,这很可能会产生延迟和吞吐量问题,导致系统可能难以满足质量属性要求(QAR),比如性能或可伸缩性。
正如我们在前一篇文章中所说的,团队在开发阶段的 MVA 架构决策关注产品如何满足 QAR。数据持久化问题产生了许多最重要的 QAR,特别是那些与产品如何存储和查询数据相关的 QAR。
为了满足这些 QAR,团队必须对数据的特征(结构化或非结构化)做出决策。他们还需要选择合适的数据存储技术(如 SQL DBMS、NoSQL DBMS 等)。这些决策几乎总是涉及数据将位于何处,至少与应用程序代码的位置有关(例如,在同一台服务器上、在同一数据中心的另一台服务器上、在不同数据中心或在商业云平台上,因此没有固定或已知的位置)。
从很多方面来看,我们可以将分布式数据想象成分布式处理,但有一个重要的区别——如果远程服务调用返回的消息很大,我们需要特别加以考虑。我们以一个在远程服务器上查询数据库的应用程序为例,查询返回大量的数据行,需要在应用程序中进行进一步分析。通过网络传输大量数据,无论速度多快,都是低效的。更好的方法是使用位于与数据库相同机器上的视图、存储过程或远程服务,以便在数据相同的位置进行尽可能多的处理,从而减少由此产生的网络流量。这样做可以减少延迟和不必要的信息处理,大大提高性能。
消除不必要的数据传输对环境也有好处。通过消除不必要的处理过程,应用程序对应的碳排放将大大减少。绿色软件工程的一些原则会考虑数据和处理过程所处的位置,这不仅是为了提升应用程序的效率,减少碳排放,也是考虑到了数据中心有多环保。
在某些情况下,将数据存放在哪里可能不能完全由团队做出决定,因为有些数据可能已经存在于遗留的数据存储中,但对于新数据,他们仍然需要做出选择。他们还必须解决与跨不同来源的数据访问延迟相关的问题,因为他们需要在提供查询、分析和准备报告时聚合新数据和遗留数据。
基于微服务的架构还会产生一些与数据相关的问题。从最简单的角度来看,每个微服务都有自己的数据存储。如果微服务及其客户端和数据都是分布式的,那么由于存在网络延迟和带宽约束等因素,性能可能会受到影响。
我们以 SQL 中的连接操作为例,连接操作通常发生在单台服务器上,从一个或多个实体(表)返回一组数据。如果这些实体是微服务,那就意味着需要迭代多个微服务,以便将所有相关数据拉取到一起。如果这些微服务是分布式的,那么调用开销和延迟将比 SQL 数据库的情况严重得多。从解耦的角度来看,“一个微服务一个数据存储”的方法很好,但不幸的是,它失去了关系数据库的一些优势(关系数据库让数据聚合变成一项相对简单的任务)。与许多架构决策一样,我们需要在松耦合、性能和可集成性之间做出权衡。
例如,为了减少性能和数据集成问题,我们可以将具有相似职责的微服务分组在同一个有界域内,并将数据存储的所有权分配给每组微服务(有时称为“组件”)。此外,利用数据网格将数据视为随时可用的可靠产品,这是一种通过有界域组织数据的有效方法,确保数据和处理具有相同的分布方式。
另一种方法可能是为所有跨服务的报告使用单独的数据库,只为事务性工作负载使用服务独有的数据存储。首先是捕获数据,然后决定如何分析数据,有时这也叫作“读时 Schema 与写时 Schema”。如果系统的利益相关者可以接受营业结束后(Close-of-Business)报告而不是实时报告,则可以用异步的方式更新报告数据库。这比较适合不需要实时分析的软件系统,如商业保险系统,但不适合证券交易系统或银行收银台应用程序。
无论 MVA 数据存储的设计和分布是怎样的,我们都应该尽量将处理定位在尽可能接近数据的位置。出于类似的原因,经常被同时访问的数据应该放在同一位置,以避免网络流量和延迟开销。
例如,如果你使用多个托管在商业云平台上的无服务器函数作为移动应用程序 MVA 的一部分,那么你可能会面临满足性能 QAR 的挑战。需要频繁访问本地数据的无服务器函数需要在本地数据中心和托管无服务器函数的数据中心之间建立非常快速的网络连接,以便向移动用户提供快速响应——这几乎是不可能的。将无服务器函数转移到本地或将数据转移到商业云平台上会更有效。
MVA 应该考虑哪些分布式决策
我们提到的关注点可以归结为团队在考虑 MVA 时应该回答的几个关键问题。
应用程序或服务是否需要重新放置,或者它们必须在特定的环境中运行?
数据可以动态重新放置吗,还是必须驻留在特定的数据存储位置?例如,一些国家制定了法律要求,规定公民的数据不能存储在境外。或者,因为一些技术原因导致数据无法迁移,例如需要与应用程序同在一个位置。这些限制意味着你可能会被迫接受比理想情况更大程度的分布式。
某些服务或应用程序必须与其他服务或特定的数据存储放在同一个位置吗?
如果负载均衡器自动移动数据或处理过程,QAR 会受到影响吗?一般来说,负载均衡器的工作方式通常会影响应用程序满足 QAR 的方式,因此与负载均衡相关的决策往往在架构层面具有重要意义。
这并不是一个详尽的清单。通过分析数据和处理的交互方式,以及这些交互可能如何影响系统满足 QAR 的能力,团队可以提出更多的问题。
结论
我们会很容易地认为采用云技术可以避免处理和数据的分布式问题,但在某种程度上,它让问题变得更加困难,因为我们更难以看到在云端真正发生了什么。云计算让团队认为计算资源是由一个巨大的同质池组成的,但实际上,底层的物理硬件和软件就像隐藏的浅滩,而团队必须通过这些浅滩。认真思考数据和处理的分布式问题将帮助他们找到解决方法。
作者简介:
Kurt Bittner 拥有 30 多年在短时间反馈驱动周期内交付软件的经验。他帮助各种各样的组织采用了敏捷软件交付实践,包括大型银行、保险、制造和零售组织,以及大型政府机构。他曾为甲骨文、惠普、IBM 和微软等大型软件交付企业工作过或与之合作过,也是 Forrester Research 的前科技行业分析师。他的重点是帮助企业建立强大的、自组织的、高性能的团队,提供客户喜爱的解决方案。他是四本软件开发相关主题书籍的作者,其中包括《The Nexus Framework for Scaling Scrum》。他在科罗拉多州的博尔德市工作,目前担任 Scrum.org 的企业解决方案副总裁。
Pierre Pureur 是一名经验丰富的软件架构师,拥有广泛的创新和应用程序开发背景,浸淫于广泛的金融服务行业,拥有广泛的咨询经验和全面的技术基础设施知识。他过去的工作包括担任一家大型金融服务公司的首席企业架构师,领导大型架构团队,管理大型并发应用程序开发项目,指导创新计划,以及制定战略和业务计划。他是“Continuous Architecture in Practice: Scalable Software Architecture in the Age of Agility and DevOps”(2021 年出版)和“Continuous Architecture: Sustainable Architecture in an Agile and Cloud-Centric World”(2015 年出版)等书的合著者,并发表了许多关于该主题的文章,并在多个软件架构大会上发表了演讲。
原文链接:
Location, Location, Location: MVA Considerations for Distributed Processing and Data
相关阅读:




